前言:
本文是我看的Vue.js设计与实现这本书第二篇 响应系统 的第4章 响应系统的作用与实现的一些总结与收获。
第4章从宏观视角讲述了Vue.js 3.0中响应系统的实现机制。从副作用函数开始,逐步实现一个完善的响应系统,还讲述了计算属性和watch的实现原理,同时讨论了在实现响应系统的过程中所遇到的问题,以及响应的解决方案。
第4章 响应系统的作用与实现
响应系统也是Vue.js的重要组成部分。这章是先从什么是响应式数据和副作用函数开始讨论,然后尝试实现一个相对完整的响应系统。在过程中会遇到各种问题,像如何避免无限递归?为什么需要嵌套的副作用函数?两个副作用函数之间会产生哪些影响以及很多细节。
4.1 响应式数据与副作用函数
副作用函数是指会产生副作用的函数,如effect(),就是说:effect函数的执行会直接或间接影响其他函数的执行,就说effect函数产生了副作用。
响应式数据则是说,假设在一个副作用函数中读取到了某个对象的属性,当值变化后,副作用函数自动重新执行,如果能实现这个目标,那么这个对象obj就是响应式数据。
4.2 响应式数据的实现
那如何让数据变成响应式数据? =》 拦截一个对象的读取和设置操作 =》1.ES2015通过Obhect.defineProperty函数实现(Vue.js 2) 2.ES2015+使用代理对象Proxy来实现(Vue.js 3)
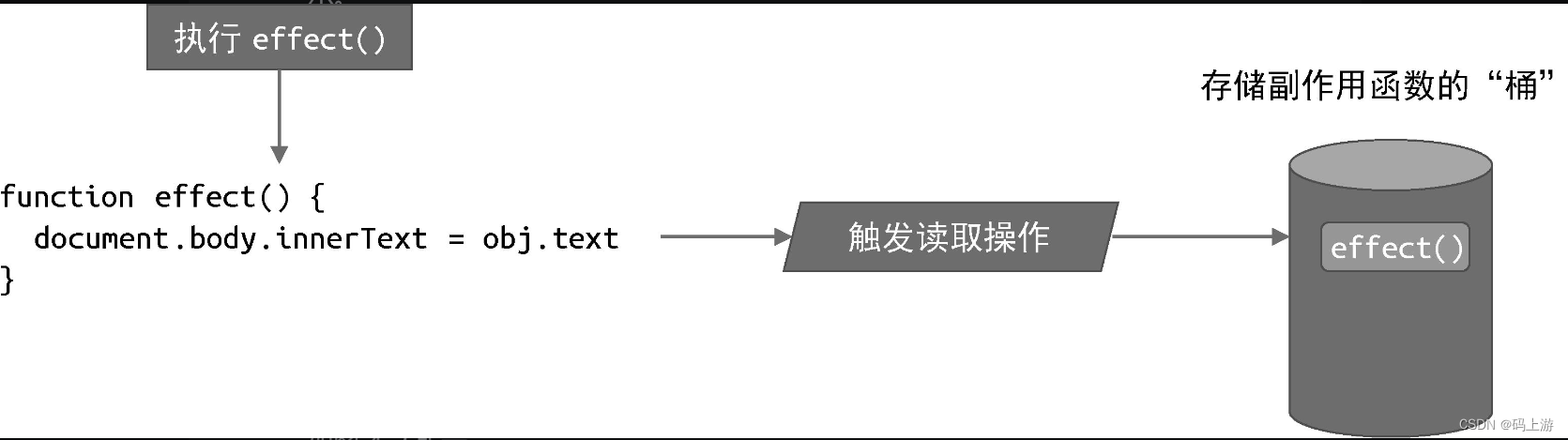
创建一个存储副作用函数的Set类型的桶,然后设置get和set拦截函数,用于拦截读取和设置操作。当读取属性时将副作用函数effect添加到桶里,即bucket.add(effect),然后返回属性值;当设置属性值时先更新原始数据,再将副作用函数从桶里取出并重新执行。
4.3 设计一个完善的响应系统
上面的实现只能算微型响应系统,因为非常不完善。上节可知一个响应系统的工作流程:当读取操作发生时,将副作用函数收集到“桶”中;当设置操作发生时,从“桶”中去除副作用函数并执行。
上面的桶结构没有在副作用函数与被操作的目标字段之间建立明确的联系,无脑从桶中放进取出,所以我们重新设计“桶”的数据结构,不能简单使用Set类型的数据作为“桶”,而是:
01 const obj = new Proxy(data, {
02 // 拦截读取操作
03 get(target, key) {
04 // 没有 activeEffect,直接 return
05 if (!activeEffect) return target[key]
06 // 根据 target 从“桶”中取得 depsMap,它也是一个 Map 类型:key --> effects
07 let depsMap = bucket.get(target)
08 // 如果不存在 depsMap,那么新建一个 Map 并与 target 关联
09 if (!depsMap) {
10 bucket.set(target, (depsMap = new Map()))
11 }
12 // 再根据 key 从 depsMap 中取得 deps,它是一个 Set 类型,
13 // 里面存储着所有与当前 key 相关联的副作用函数:effects
14 let deps = depsMap.get(key)
15 // 如果 deps 不存在,同样新建一个 Set 并与 key 关联
16 if (!deps) {
17 depsMap.set(key, (deps = new Set()))
18 }
19 // 最后将当前激活的副作用函数添加到“桶”里
20 deps.add(activeEffect)
21
22 // 返回属性值
23 return target[key]
24 },
25 // 拦截设置操作
26 set(target, key, newVal) {
27 // 设置属性值
28 target[key] = newVal
29 // 根据 target 从桶中取得 depsMap,它是 key --> effects
30 const depsMap = bucket.get(target)
31 if (!depsMap) return
32 // 根据 key 取得所有副作用函数 effects
33 const effects = depsMap.get(key)
34 // 执行副作用函数
35 effects && effects.forEach(fn => fn())
36 }
37 })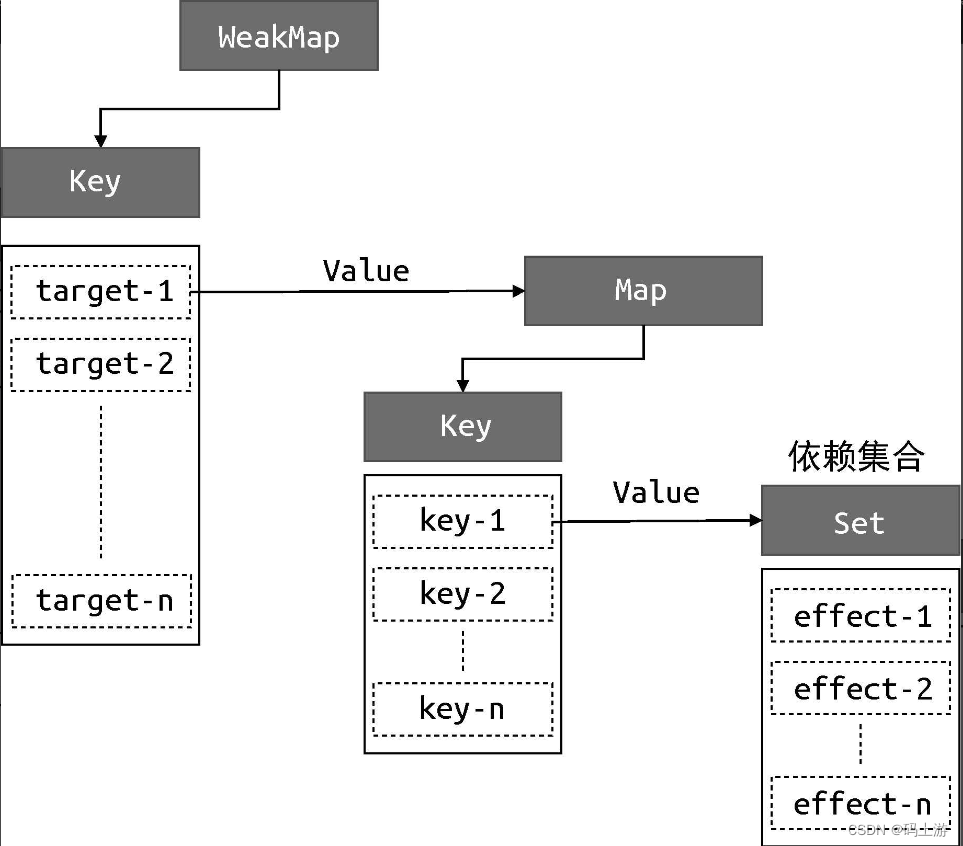
4.4 分支切换与cleanup
冗余副作用函数问题
响应系统的完善,分支切换会导致冗余副作用的问题,这个问题会导致副作用函数进行不必要的更新。比如副作用函数中内部存在一个三元表达式,两个分支分别读取了同一个对象的不同属性,而执行的时候只能用上其中一个,我们需要的是指在执行时用上的那个属性进行副作用函数依赖绑定,也就是修改了那个属性才会触发副作用函数执行而另一个属性修改了不执行,但是我们的代码不管是哪个属性修改了,副作用函数都会执行。
解决方法是在每次副作用函数重新执行之前,清除上一次建立的响应联系,而当副作用函数重新执行后,会再次建立新的响应练习,新的响应联系中不存在冗余副作用问题。
let activeEffect;
function effect(fn){
const effectFn=()=>{
//调用cleanup函数完成清除工作
cleanup(effectFn)
//当调用effect注册副作用函数时,将副作用函数fn赋值给activeEffect
activeEffect=effectFn
//执行副作用函数
fn()
}
//存储所有与该副作用函数有关的依赖集合
effectFn.deps=[]
effectFn()
}
const data={foo:true,bar:true}
let obj = new Proxy(data,{
//拦截读取操作
get(target,key){
//将副作用函数activeEffect添加到存储副作用函数的桶中
track(target,key)
//返回属性值
return target[key]
},
//拦截设置操作
set(target,key,newVal){
//设置属性值
target[key]=newVal
//把副作用函数从桶中取出来并执行
trigger(target,key)
//返回true代表设置操作成功
return true
}
})
//存储副作用函数的桶
const bucket = new WeakMap()
function track(target,key){
//没有activeEffect,直接return
if(!activeEffect) return
let depsMap=bucket.get(target)
if(!depsMap){
bucket.set(target,(depsMap=new Map()))
}
let deps=depsMap.get(key)
if(!deps){
depsMap.set(key,(deps=new Set()))
}
//最后将当前激活的副作用函数添加到桶中
deps.add(activeEffect)
//deps就是一个与当前副作用函数存在关联的依赖集合
activeEffect.deps.push(deps)
}
function trigger(target,key){
//target[key]=newVal
const depsMap=bucket.get(target)
if(!depsMap)return
const effects=depsMap.get(key)
const effectsToRun=new Set(effects)
effectsToRun.forEach(effectFn=>effectFn())
// effects&&effects.forEach(fn=>fn())
}
function cleanup(effectFn){
for(let i=0;i<effectFn.deps.length;i++){
const deps=effectFn.deps[i]
//将effectFn从依赖集合中移除
deps.delete(effectFn)
}
//最后需要重置effectFn.deps的值
effectFn.deps.length=0
}至此,我们的响应系统已经可以避免副作用函数产生遗留了。
无限循环问题
但此时又有一个问题:目前的实现会导致无限循环执行,
01 const set = new Set([1])
02
03 set.forEach(item => {
04 set.delete(1)
05 set.add(1)
06 console.log('遍历中')
07 })如果我们在浏览器中执行这段代码,就会发现它会无限执行下去。
语言规范中对此有明确的说明:在调用 forEach 遍历 Set 集合时,如果一个值已经被访问过了,但该值被删除并重新添加到集合,如果此时 forEach 遍历没有结束,那么该值会重新被访问。因此,上面的代码会无限执行。问题出在 trigger 函数中
01 function trigger(target, key) {
02 const depsMap = bucket.get(target)
03 if (!depsMap) return
04 const effects = depsMap.get(key)
05 effects && effects.forEach(fn => fn()) // 问题出在这句代码
06 }在 trigger 函数内部,我们遍历 effects 集合,它是一个 Set 集合,里面存储着副作用函数。当副作用函数执行时,会调用 cleanup 进行清除,实际上就是从effects 集合中将当前执行的副作用函数剔除,但是副作用函数的执行会导致其重新被收集到集合中,而此时对于 effects 集合的遍历仍在进行。
解决办法:
建立一个新的Set数据结构进行遍历。
01 const set = new Set([1])
02
03 const newSet = new Set(set)
04 newSet.forEach(item => {
05 set.delete(1)
06 set.add(1)
07 console.log('遍历中')
08 })这样就不会无限执行了。回到 trigger 函数,我们需要同样的手段来避免无限执行:
01 function trigger(target, key) {
02 const depsMap = bucket.get(target)
03 if (!depsMap) return
04 const effects = depsMap.get(key)
05
06 const effectsToRun = new Set(effects) // 新增
07 effectsToRun.forEach(effectFn => effectFn()) // 新增
08 // effects && effects.forEach(effectFn => effectFn()) // 删除
09 }4.5 嵌套的effect与effect栈
因为effect是可嵌套的,而activeEffects所存储的副作用函数只能有一个,而此时当副作用函数发生嵌套时,内层副作用函数的执行就会覆盖activeEffect的值。这时即使响应式数据在外层副作用函数读取,收集到的也会是内层副作用函数。这就是问题所在。
effect栈
为了解决这个问题,就需要effect栈了:
我们需要一个副作用函数栈 effectStack,在副作用函数执行时,将当前副作用函数压入栈中,待副作用函数执行完毕后将其从栈中弹出,并始终让 activeEffect 指向栈顶的副作用函数。这样就能做到一个响应式数据只会收集直接读取其值的副作用函数,而不会出现互相影响的情况
01 // 用一个全局变量存储当前激活的 effect 函数
02 let activeEffect
03 // effect 栈
04 const effectStack = [] // 新增
05
06 function effect(fn) {
07 const effectFn = () => {
08 cleanup(effectFn)
09 // 当调用 effect 注册副作用函数时,将副作用函数赋值给 activeEffect
10 activeEffect = effectFn
11 // 在调用副作用函数之前将当前副作用函数压入栈中
12 effectStack.push(effectFn) // 新增
13 fn()
14 // 在当前副作用函数执行完毕后,将当前副作用函数弹出栈,并把 activeEffect 还原为之前的值
15 effectStack.pop() // 新增
16 activeEffect = effectStack[effectStack.length - 1] // 新增
17 }
18 // activeEffect.deps 用来存储所有与该副作用函数相关的依赖集合
19 effectFn.deps = []
20 // 执行副作用函数
21 effectFn()
22 }4.6 避免无限递归循环
01 const data = { foo: 1 }
02 const obj = new Proxy(data, { /*...*/ })
03
04 effect(() => obj.foo++)上面effcet的自增操作会引发栈溢出。
01 effect(() => {
02 // 语句
03 obj.foo = obj.foo + 1
04 })读取和设置是在同一个副作用函数内进行的,此时无论是track时收集的副作用函数还是trigger时触发执行的副作用函数,都是activeEffect
因为在这个语句中,既会读取 obj.foo 的值,又会设置 obj.foo 的值,而这就是导致问题的根本原因。我们可以尝试推理一下代码的执行流程:首先读取 obj.foo 的值,这会触发 track 操作,将当前副作用函数收集到“桶”中,接着将其加 1 后再赋值给 obj.foo,此时会触发 trigger 操作,即把“桶”中的副作用函数取出并执行。但问题是该副作用函数正在执行中,还没有执行完毕,就要开始下一次的执行。这样会导致无限递归地调用自己,于是就产生了栈溢出。
无限递归循环解决办法:
在 trigger 动作发生时增加守卫条件:如果 trigger 触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行。
01 function trigger(target, key) {
02 const depsMap = bucket.get(target)
03 if (!depsMap) return
04 const effects = depsMap.get(key)
05
06 const effectsToRun = new Set()
07 effects && effects.forEach(effectFn => {
08 // 如果 trigger 触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行
09 if (effectFn !== activeEffect) { // 新增
10 effectsToRun.add(effectFn)
11 }
12 })
13 effectsToRun.forEach(effectFn => effectFn())
14 // effects && effects.forEach(effectFn => effectFn())
15 }4.7 调度执行
可调度,指的是当trigger动作触发副作用函数重新执行时,有能力决定副作用函数执行的时机、次数以及方式。为了实现调度能力,为effect函数添加了第二个选项参数,可以通过scheduler选项指定调用器,这样用户可以通过调度其自行完成任务的调度。
为 effect 函数设计一个选项参数 options,允许用户指定调度器
01 effect(
02 () => {
03 console.log(obj.foo)
04 },
05 // options
06 {
07 // 调度器 scheduler 是一个函数
08 scheduler(fn) {
09 // ...
10 }
11 }
12 )01 function trigger(target, key) {
02 const depsMap = bucket.get(target)
03 if (!depsMap) return
04 const effects = depsMap.get(key)
05
06 const effectsToRun = new Set()
07 effects && effects.forEach(effectFn => {
08 if (effectFn !== activeEffect) {
09 effectsToRun.add(effectFn)
10 }
11 })
12 effectsToRun.forEach(effectFn => {
13 // 如果一个副作用函数存在调度器,则调用该调度器,并将副作用函数作为参数传递
14 if (effectFn.options.scheduler) { // 新增
15 effectFn.options.scheduler(effectFn) // 新增
16 } else {
17 // 否则直接执行副作用函数(之前的默认行为)
18 effectFn() // 新增
19 }
20 })
21 }4.8 计算属性computed与lazy
讲解了计算属性,computed。计算属性实际上是一个懒执行的副作用函数,我们通过lazy选项使得副作用函数可以懒执行。