一、哈希的应用(位图和布隆过滤器)
1、位图(bitset)
(1)位图概念
【题目】
给 40亿 个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这 40亿 个数中。
- 遍历 40亿 个数,时间复杂度为:O(N)。
- 先排序,快排:O(NlogN),再利用二分查找:O(logN)。
- 将 40亿 个数放进 set / unordered_set 中,然后再查找 key 在不在。
- 位图解决。
前面三种解法看似可行,实际上有很大的问题:内存消耗太大。
40亿 个整数要占用多少空间?大约是 16GB。
- 1GB = 1024 * 1024 * 1024 = 210 * 210 * 210 = 230 (大约是 10 亿 byte)
- 4GB = 4 * 230 = 232 byte(大约是42亿9九千多万byte)
- 40亿 个 unsigned int 整数 = 40亿 * 4字节 = 160亿字节 = 16 * 10亿字节 ≈ 16GB
(a)这 40亿 个数据是放在文件中的,要对这 40亿 个整数进行排序:
难道在内存中开一个 16GB 空间的数组存放这些数据吗?显然不太现实,内存消耗太大了。
(b)虽然归并排序可以对文件中的数据做外排序,但是效率很低,磁盘读写速度是很慢的,即使在文件中对 40亿 个数据排完了序,但是很难去算出数据的下标位置,不能进行二分查找,那意义也不大。
(c)把数据放进 set / unordered_set 中,因为其底层是链式结构,除了存数据,还要存指针,所以附带的内存消耗更大,需要的空间比 16GB 还要大很多,更不可行。
所以我们一定要从节省内存的角度出发去思考,才能更好的解决问题。同时题目要求是:快速判断。
这里是判断一个数在不在数据集中,仔细想一想,也并不需要把这个数存起来,只需要有个标记去 标记某个数在不在就行了。(就好比统计数组中数字的出现次数,我们用数的数值作为下标,在该下标处存储出现的次数,也并没有把数存下来)。标记一个数在不在,最小的标记单位是比特位(0 / 1),我们用一个比特位标记一个数,这样就节省空间了。
这里我们将采用第四种解法:位图。
某个数是否在给定的数据集中,有两种结果:存在 / 不存在,刚好是两种状态,那么可以使用一个二进制比特位来代表某个数是否存在的信息,比如二进制比特位为 1 代表存在,为 0 代表不存在。
我们把数据集的所有数用直接定址法映射到一张二进制表中,并用二进制值(1 / 0)标记其是否存在,这样每个数都有唯一的映射位置,不会出现哈希冲突。如果要判断某个数在不在数据集中时,只需要找到这个数映射到表中的位置,然后查看该位置的比特位为 1 还是 0。
我们是用每个无符号整数 unsigned int 的值来映射其哈希位置(比如 25,就映射到第 25 个二进制位):
- 因为 unsigned int 的 取值范围 是 0 ~ 2³²-1,所以一个无符号整数最小值为 0,最大值为 2³² - 1(4,294,967,295,42亿9千多万)。
- 所以我们要开有 232 个二进制位的表,才能映射完所有的无符号整数,但实际上只能开到有 2³²-1 个二进制位的表(因为 size_t 最大为 0xffffffff),也就是开 ( 2³²-1 ) / 8 个字节 ≈ 5亿多个字节 ≈ 0.5GB = 512MB 的内存空间。
一个 bit 位标记一个 unsigned int 值,512GB 的内存就可以标记完 42亿9千多万个整数的存在状态了,极大的节省了内存。
注意:位图并没有把整个数据集存储起来,而是将所有数映射到哈希表中,在映射的哈希位置上标记这个数在不在。
【位图概念】
面对判断一个数在不在海量数据中的问题,红黑树和哈希表查找效率是挺高的,但是我们光把海量数据存起来够呛,同时红黑树和哈希表附带的内存消耗,所需空间更大,基于这样的原因,提出了位图这种数据结构。
所谓位图(bitset),就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。在索引、数据压缩方面有很大的应用。
template <size_t N> class bitset;位图是用数组实现的,数组的每一个元素的每一个二进制位都表示一个数据,0 表示该数据不存在,1 表示该数据存在。
位图最大的特点就是:快、节省空间,因为它不需要存储数据集,只是标记某个数在不在这个数据集中。
(2)位图的实现
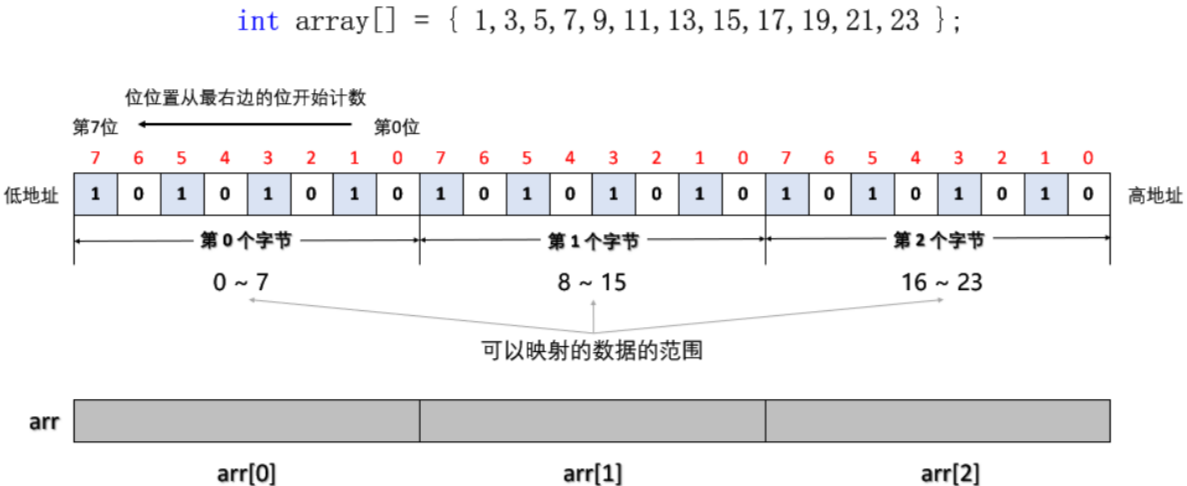
a. 位图的底层结构
如图,我们开一个数组,数组的每个元素是一个 char(8个 bit 位)。如果是一个 int (32 个 bit 位)也可以,只是计算数据映射的比特位的方法略有差别。
这里的 0 ~ 7 是比特位的编号,从右到左依次编号。
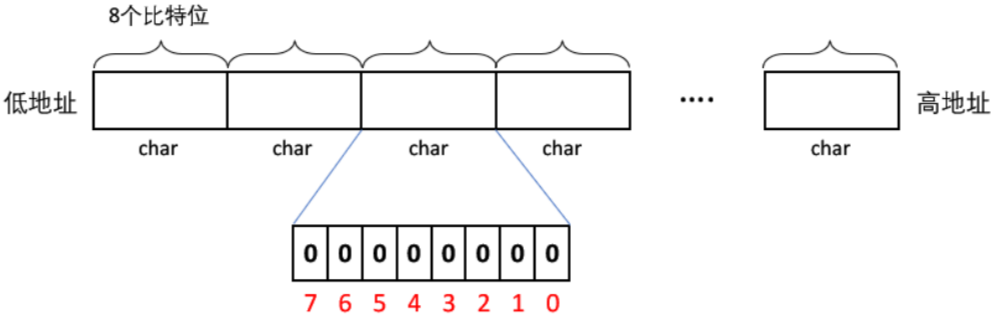
问:如何计算这个数据映射在数组中第几个 char(字节) 中的第几个比特位上?
- 字节位置 = 数据 / 8,得出 x 映射在第几个 char 中。
- 位位置 = 数据 % 8,得出 x 映射在这个 char 中的第几个比特位上。
- 注意:如果数组的每个元素是一个 int,改成除以 32 就好了。
比如数据 x = 10,则:
- 字节位置 = 10 / 8 = 1,说明 10 映射在第 1 个 char(字节)中。
- 位位置 = 10 % 8 = 2,说明 10 映射在第 1 个 char(字节)中的第 2 个比特位上。
// 位图的结构
namespace xyl
{
template<size_t N> // N: 非类型模板参数,表示至少需要开N个比特位的存储空间
class bitset
{
public:
// 构造有N个比特位的位图,等价于要开N/8个字节(char)的空间
// 为了防止N不是8的整数倍,所以要+1,多开1个字节(char)的空间
bitset() { _bits.resize(N / 8 + 1, 0); }
// 把数据x映射的比特位设置成1,表示数据x存在
void set(size_t x);
// 把数据x映射的比特位设置成0,表示数据x不存在
void reset(size_t x);
// 检测数据x映射的比特位是否为1(即数据x是否存在)
bool test(size_t x) const;
private:
vector<char> _bits; // 位数组
};
}b. 位图的一些成员函数
① 位图的构造
默认构造函数:
构造至少有 N 个比特位的位图,等价于开 N / 8个字节(char)的空间
为了防止 N 不是 8 的整数倍,所以要 +1,多开1个字节(char)的空间
bitset()
{
_bits.resize(N / 8 + 1, 0);
}② 位图的插入:set
set 函数:修改数据映射的比特位位置。位位置从最右边的位开始计数,即从 0 位置开始计数。
// 把数据 x 映射的比特位设置成1,表示数据x存在
void set(size_t x)
{
// 计算出这个数据映射在数组中第几个char(字节)中的第几个比特位上
size_t i = x / 8; // 计算出x映射在第i个char(字节)中
size_t j = x % 8; // 计算出x映射在第i个char(字节)中的第j个比特位上
// 把数组中第i个char的第j位设置成1,其它位不受影响
_bits[i] |= (1 << j);
}
// 分析:
// 比如: 数据5映射在第0个char的第5个比特位
// 现在要用set函数把数据5映射的第0个char的第5个比特位设置成1
0000 1111 -> _bits[0] // 第0个char
0010 0000 -> 1 << 5 // 将1左移5位
// 将1左移5位后的结果按位或上 _bits[0]
0010 0000 -> 1 << 5
| 0000 1111 -> _bits[0]
-----------------------
0010 1111 -> _bits[0] // 此时第0个char的第5个比特位已经被设置成1了③ 位图的删除:reset
reset 函数:修改数据映射的比特位位置。位位置从最右边的位开始计数,即从 0 位置开始计数。
// 把数据x映射的比特位设置成0,表示数据x不存在
void reset(size_t x)
{
size_t i = x / 8; // 映射在第i个char中
size_t j = x % 8; // 映射在第i个char中的第j个比特位上
// 把数组中第i个char的第j位设置成0,其它位不受影响
_bits[i] &= (~(1 << j));
}
// 这里需要注意:
_bits[i] ^= (1 << j); // 不能用异或,如果第 j 个比特位本身就是 0,异或之后就变成 1 了。
// 比如: 数据5映射在第0个char的第5个比特位
// 现在要用reset函数把数据5映射的第0个char的第5个比特位设置成0
0010 1111 -> _bits[0] // 第0个char
0010 0000 -> 1 << 5 // 将1左移5位
// 将1左移5位后的结果按位取反,然后按位与上 _bits[0]
1101 1111 -> ~(1 << 5)
& 0010 1111 -> _bits[0]
-----------------------
0000 1111 -> _bits[0] // 此时第0个char的第5个比特位已经被设置成0了④ 位图的查找:test
test 函数:检测数据 x 映射的比特位是否为 1,即数据 x 是否存在。
// 检测数据 x 映射的比特位是否为1(即数据x是否存在)
// 是1返回true,是0返回false
bool test(size_t x) const
{
size_t i = x / 8; // 映射在第i个char中
size_t j = x % 8; // 映射在第i个char中的第j个比特位上
return _bits[i] & (1 << j);
// 0000 1111 -> _bits[0]
// & 0010 0000 -> 1 << 5
// ----------------------
// 0000 0000 -> 说明第0个char的第5个比特位是0,数据x不存在
}c. 如何开出有42亿9千多万个比特位的位图呢?
来映射42亿9千多万个无符号整型数,标记其存在状态。
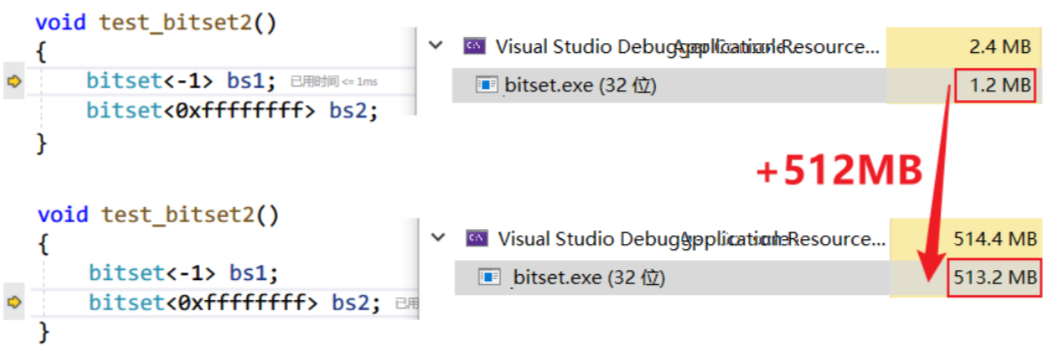
void test_bitset()
{
// (size_t)4,294,967,295U
bitset<-1> bs1; // 方式一
bitset<0xffffffff> bs2; // 方式二
}通过调试可以看到,开了 512MB 的空间(即 4,294,967,295U 个比特位)
(3)位图的应用
- 快速查找某个数据是否在一个集合中。
- 排序+去重。
- 求两个集合的交集、并集等。
- 操作系统中磁盘块标记。
2、布隆过滤器(bloomfilter)
(1)布隆过滤器提出
我们在使用新闻客户端看新闻时,它会不停地给我们推荐新的内容,每次推荐时都要去重,去掉那些我们已经看过的内容。那么问题来了,新闻客户端推荐系统是如何实现推送去重的?用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。如何快速查找呢?
- 用哈希表存储用户记录,缺点:浪费空间。
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了。
- 将哈希与位图结合,即布隆过滤器。
【场景一】
现在有 1亿个 IP 地址(字符串),给你一个 IP,需要快速判断这个 IP 在不在其中,如何处理?
- (1)哈希切分。太慢了。
- (2)用一个字符串哈希算法,把 IP 地址转换成可以取模的整型(size_t),然后映射到位图的某一个比特位中,进行标记,0 表示这个 IP 不存在,1 表示这个 IP 存在。
问题是:如果不同的 IP 地址映射的是同一个比特位,会发生哈希冲突,可能会存在误判:
- 判断一个值是否在,就是判断其映射的比特位是否为 1。判断结果是不准确的,可能存在误判。
- 判断一个值是否不在,就是判断其映射的比特位是否为 0。判断结果一定是准确的。(因为如果这个值在,其映射的比特位一定是 1)。
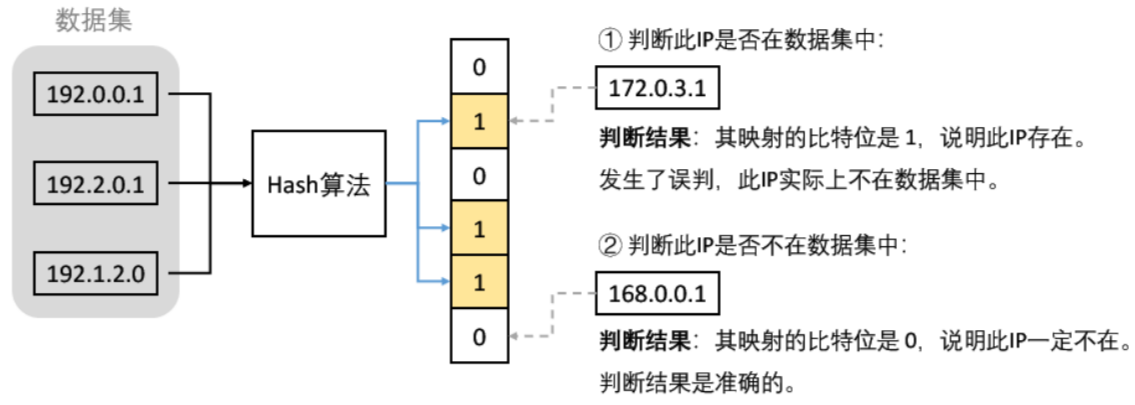
那该怎么办呢?布隆发现想要判断一个值是否在,变得一定是准确的,几乎是不可能的。因为总会存在哈希冲突。虽然无法解决冲突,但是可以缓解冲突。
对(2)的改进:
一个 IP 映射位图中的一个比特位,冲突概率大,误判概率大。
那么我们对同一个 IP 使用不同的哈希算法,让其映射多个比特位,缓解冲突,降低误判的概率。
虽然还是存在一定的误判,但至少节省了空间。
【场景二】
判断一个人是不是这个学校的学生:
- (1)用姓名作为标识,来表示一个人,万一同姓名的人比较多,就会导致误判。
- (2)用姓名、性别、出生年月作为标识,来表示一个人,同姓名的人比较多容易导致误判,而同姓名同性别同出生年月的人,可能有,但是数量没有那么多,这样就缓解了冲突,降低误判概率。
核心思想:一个值映射多个位。
(2)布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在 1970 年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,它的实现是一个很长的二进制向量(位数组)和一系列哈希函数。可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。

优点:是空间效率和查询时间 O(1) 都比一般的算法要好的多。
缺点:是有一定的误识别率和删除困难。
核心思想:一个值映射多个位。
问:哈希函数的个数需要权衡一下,映射的位越多,冲突的概率也越低,但是消耗的空间的也越大;但是映射的位少,误判率就会变高,那映射多少位是合理的呢?
问:布隆过滤器的底层就是一个位数组,一次性开 0xffffffff 个位空间也没必要,很浪费,那如何控制开多少个位是合理的呢?
如何选择哈希函数个数和布隆过滤器的长度(并非官方测试结果):

比如,规定哈希函数个数 k = 3,布隆过滤器长度 m = ( k / ln2 ) * n ≈ 4.2 * n(大约是插入元素个数的 4.2 倍) 。
(3)布隆过滤器的插入
向布隆过滤器中插入:"baidu"
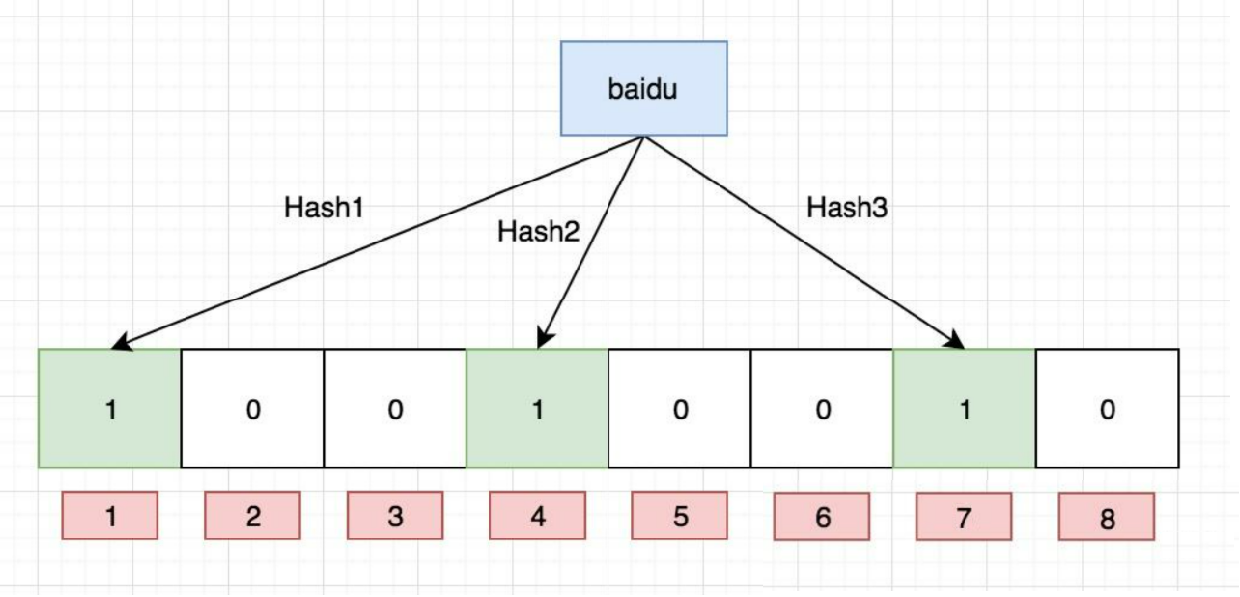

void set(const K& key) // 把键值key映射的几个比特位设置成 1
{
// 对键值 Key 使用不同的哈希算法,得到其映射的三个比特位的位置
// 注意:计算的比特位的位置可能超过了布隆过滤器的长度,需要对长度 len 取模
size_t index1 = Hash1()(key) % len;
size_t index2 = Hash2()(key) % len;
size_t index3 = Hash3()(key) % len;
// 把键值 key 映射的三个比特位设置成 1
_bs.set(index1);
_bs.set(index2);
_bs.set(index3);
}(4)布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为 1。
所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找 "alibaba" 时,假设 3 个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
bool test(const K& key) // 检查键值key映射的几个比特位的值,判断键值key在不在
{
// 对键值 Key 使用不同的哈希算法,得到其映射的三个比特位的位置
// 注意:计算的比特位的位置可能超过了布隆过滤器的长度,需要对长度len取模
size_t index1 = Hash1()(key) % len;
if (_bs.test(index1) == false)
{
return false; // 检测该比特位的值是否为0,若为0,说明不在,直接返回false
}
size_t index2 = Hash2()(key) % len;
if (_bs.test(index2) == false)
{
return false;
}
size_t index3 = Hash3()(key) % len;
if (_bs.test(index3) == false)
{
return false;
}
return true; // 注意:当三个比特位的值都为1时,可能存在误判
}
void test_bloomfilter1()
{
BloomFilter<100> bf; // 最多向布隆过滤器中插入100个元素
bf.set("alibaba");
cout << bf.test("alibaba") << endl; // 输出1
cout << bf.test("alibaba") << endl; // 输出0
}【拓展】测试布隆过滤器的误判率
相似字符串的误判率:测试发现,哈希函数个数和插入元素个数确定情况下,布隆过滤器长度越长,误判率越低。
void test_bloomfilter()
{
BloomFilter<100> bf; // 最多向布隆过滤器中插入100个元素
// 1、构造100个不同的字符串,存放到 v1 中
vector<string> v1;
for (size_t i = 0; i < 100; i++)
{
string url = "https://www.bilibili.com/";
url += std::to_string(123 + i); // 构造出100个不同的字符串
v1.push_back(url);
}
// 把100个不同的字符串插入到布隆过滤器中
for (const auto& e : v1) bf.set(e);
// 2、构造100个不同的相似字符串,存放到 v2 中
vector<string> v2;
for (size_t i = 0; i < 100; i++)
{
string url = "https://www.bilibili.com/"; // 用了相同的网址
url += std::to_string(456 + i); // 构造出100个不同的相似字符串
v2.push_back(url);
}
// 检测这100个不同的相似字符串是否在布隆过滤器中(按理来说应该不在)
size_t count1 = 0;
for (const auto& e : v2)
{
if (bf.test(e)) count1++; // 如果判断在,说明误判了
// 统计出有多少个字符串误判了
}
cout << "相似字符串的误判率:" << (double)count1 / (double)100 << endl;
}(5)布隆过滤器删除
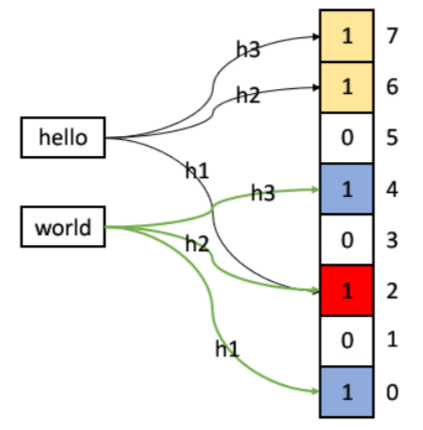
一般情况下,布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中 "hello" 元素,如果直接将该元素所对应的二进制比特位置 0,"world" 元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,记录有多少个值映射到这个位了(比如使用两个比特位来记录,最多可以记录 3 个值),插入元素时给 k 个计数器(k 个哈希函数计算出的哈希地址)加一,删除元素时,给 k 个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
(6)布隆过滤器优点
- 增加和查询元素的时间复杂度为:O(K),(K 为哈希函数的个数,一般比较小),与数据量大小无关。
- 哈希函数相互之间没有关系,方便硬件并行运算。
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势。
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势。
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能。
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算。
(7)布隆过滤器缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)。
- 不能获取元素本身。
- 一般情况下不能从布隆过滤器中删除元素。
- 如果采用计数方式删除,可能会存在计数回绕问题。
(8)BloomFilter 的应用场景
布隆过滤器的应用场景:在一些允许误判的地方。
【场景一】
假设这里有一个网站,注册的时候需要每个用户取一个昵称,要求昵称不能重复。用户在注册的时候,输入一个昵称,系统需要判断一下这个昵称是否已被注册。用户输入昵称点击提交后,先到后台数据库中去查,再返回判断这个昵称是否存在的结果。这种方式就太麻烦了。
问:那能否当用户刚输入完昵称后,还没有点提交,切换到下一个输入框,这个时候就会提示用户,该昵称是否被占用呢?
我们可以使用一个布隆过滤器,标记所有使用过的昵称,就能快速判断一个昵称是否被使用过。这里虽然会存在误判,但在这种场景下,误判的影响并不大(因为判断一个昵称没被使用过,一定是准确的。判断一个昵称被使用过,可能存在误判,但没什么影响,大不了换一个昵称)。
【场景二】
问:如果要求判断在或不在的结果都要是准确的,能否使用布隆过滤器呢?
也是可以的,比如验证一个手机号是否在系统中注册过,要求验证结果是准确的。使用一个布隆过滤器,标记所有注册过的手机号,判断这个手机号在不在布隆过滤器中:
- 如果不在,直接返回结果:未注册。
- 如果在,因为可能存在误判,所以再去服务器的数据库中查询,然后返回查询结果:未注册 / 已注册。
虽然查询效率降低了,但比起每次判断都去访问数据库,还是要高效不少。有些服务器就会采用这种方式,来提高效率。
【场景三】
比如判断垃圾邮件,垃圾邮件的地址都会被标记映射到一个黑名单(布隆过滤器)中,当有人给你发邮件时,系统会快速判断出这个是否是垃圾邮件,然后进行拦截或分类。
- 系统判断这个邮件不在黑名单中,一定不会被拦截。
- 系统判断这个邮件在黑名单中,但这个邮件实际上可能不在黑名单中,误判了,把正常邮件拦截了,但影响不大,在垃圾箱还是能够找到这封正常邮件。
二、海量数据题目
海量数据处理,一般不能用我们常见的数据结构去处理,考验当常见数据结构都失效时该如何处理。
1、哈希切割
给一个超过 100G 大小的 log file(日志文件),log 中存着 IP 地址, 设计算法找到出现次数最多的 IP 地址?与上面讲到的条件相同,如何找到 top K 的 IP?如何直接用 Linux 系统命令实现?
此题不能用位图来处理了,因为位图处理的是整数,而 IP 地址是字符串(比如:192.0.0.1)。这里就需要用到哈希切分,大文件我们处理不了,就想办法把它切分小文件处理。假设我们有 4G 内存,我们就把这个大文件平均切分成 100 份小文件,每一份 1G,但这种平均切分实际上是不行的,因为同一个 IP 可能进入了多份小文件中,想要统计出每个 IP 最终出现的次数都是非常麻烦的,更别说找到出现次数最多的那个 IP 地址了。那该怎么办呢?
使用哈希切分。
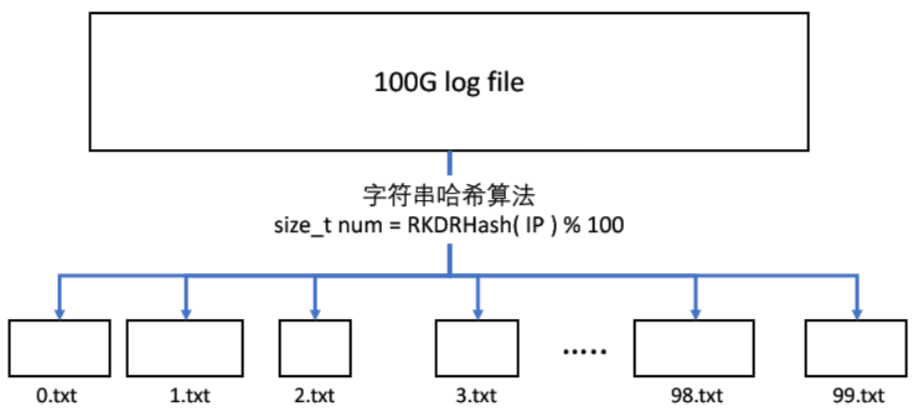
切分操作:
- 先创建 100 个小文件,分别叫 0.txt、1.txt、2.txt、… 99.txt。
- 然后读取 100G log file,依次获取每个 IP 地址,用字符串哈希算法,把 IP 地址转换成可以取模的整型(size_t),比如使用 BKDR 算法:size_t num = BKDRHash(IP) % 100,然后这个 IP 地址就放入(映射到)第 num.txt 号小文件。依次对所有 IP 进行处理,进入(映射到)对应的小文件。
- 如果运气好一点,平均下来差不多每个小文件就是 1G 左右;如果运气不好,可能有些小文件是 512MB,有些小文件是 2G,但至少是相对可控的。
问:如果最小的小文件 num.txt 还是过大该怎么办呢?
我们可以限制一个大小,在处理操作之前,先检测一下当前小文件的大小,如果超过 2G,就换一个哈希算法把当前小文件再切小一些。
我们要找到出现次数最多的 IP 地址,在最开始记录下当前小文件中出现次数最多的 IP 地址,然后再读取后面小文件的过程中,不断更新这个 IP 地址,当最后一个小文件读取完,就找到出现次数最多的 IP 地址了。
处理操作:
依次读取每个小文件,比如先读取 0.txt 中所有的 IP,用 map<string, int> 统计所有 IP 出现的次数,这里统计的 IP 出现次数,就是这个 IP 最终出现的次数。我们记录下 0.txt 中出现次数最多的 IP。
问:这里为什么用了 map 呢?
因为是小文件,内存消耗不大。然后再 clear() 掉 map 中的元素,再读取 1.txt 中所有的 IP,继续统计所有 IP 出现的次数,不断走下去。
如果要找到 topK 的 IP 地址,建立 K 个数的小堆即可。
这里采用哈希切分的关键是:
- 相同的 IP 地址,一定会进入编号相同的小文件。
- 因为用字符串哈希算法,同一个 IP 地址转换出来的哈希位置一定是相同的。
可以理解为这里就是 100 个存着文件指针的哈希桶。
2、位图应用(只能处理整数)
(1)给定 100 亿个整数,设计算法找到只出现一次的整数?
前面的题目是:在没排过序的海量数据中快速判断一个数在不在其中,是一个典型的 key 模型。
所以我们只需要用位图标记 2 种状态:存在 / 不存在,用一个比特位 1 / 0 来标记。
而这里是:在海量数据中找到只出现一次的数,不仅要判断这个数在不在,还要知道这个数的出现次数。
错误思路:
- 显然是不能把这 100亿 个整数存储在 map/unordered_map(红黑树/哈希表) 中。
正确思路:
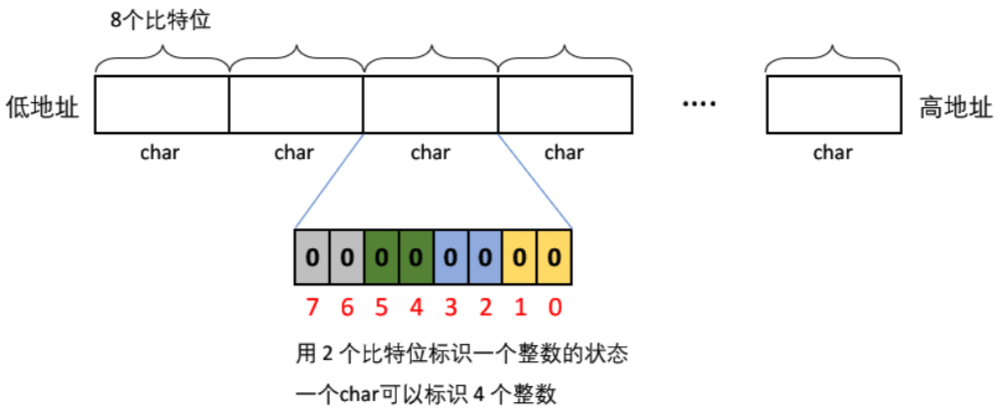
- 我们需要标记 3 种状态:不存在 / 出现一次 / 出现多次,则要用两个比特位来标记。
- 因为两个比特位有 4 种表现形式 00 / 01 / 10 / 11。00:表示这个数不存在,01:表示这个数只出现一次,10:表示这个数出现多次
- 然后遍历位图,找到所有 01 标记的位置,此位置映射的就是只出现一次的整数。
问:那这里需要消耗多少空间呢?
这里要注意:虽然有100亿个整数,但并不是开 100亿 个比特位的表。这 100亿 个 unsigned int 整数的取值范围都是 0 ~ 2³²-1(大约是42亿9千多万个整数),如果每个整数映射一个比特位,需要消耗 ( 2³²-1 ) / 8 个字节 ≈ 5亿多个字节 ≈ 0.5GB 的空间,则每个整数映射两个比特位,需要消耗 1GB 的空间。
具体做法:
方法一:用一个位图,用 2 个连续的比特位标识一个数。需要修改 2 个不同位置的比特位的值,不方便。
方法二:封装两个位图,用两个位图的同一个位置的 2 个比特位来标识一个数。
所以修改两个位图的同一个位置的比特位的值就好了,还可以复用之前写的位图代码。
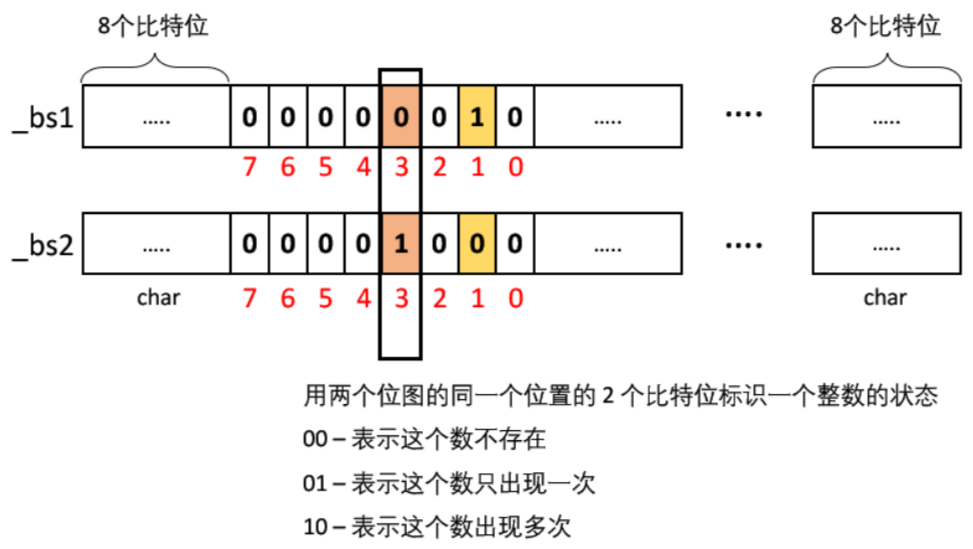
封装了两个位图,找只出现一次的整数
N:非类型模板参数,表示至少要开 N 个比特位的存储空间。
template<size_t N>
class FindOnceValSet
{
public:
void set(size_t x) // 把数据 x 映射的比特位设置成 01,表示数据 x 出现一次
{
bool flag1 = _bs1.test(x); // 检测数据 x 在第1个位图中映射的比特位是否为 1
bool flag2 = _bs2.test(x); // 检测数据 x 在第2个位图中映射的比特位是否为 1
// 两个比特位分别为 00,说明数据 x 之前不存在
if (flag1 == false && flag2 == false)
{
// 00 -> 01,标识成出现一次
_bs2.set(x);
}
// 两个比特位分别为 01,说明数据 x 之前已经出现一次
else if (flag1 == false && flag2 == true)
{
// 01 -> 10,标识成出现多次
_bs1.set(x); // 1
_bs2.reset(x); // 0
}
// 两个比特位分别为 10,说明数据 x 之前已经出现多次了,不用处理
// 10 -> 10
}
void print_once_num() // 输出所有只出现一次的数据
{
// 遍历位图中的 N 个比特位
for (size_t i = 0; i < N; i++)
{
// 检测两个位图的同一个位置的比特位是否分别为 0、1
if (_bs1.test(i) == false && _bs2.test(i) == true)
{
cout << i << endl; // 输出此位置映射的数据 i
}
}
}
private:
bitset<N> _bs1; // 位图1
bitset<N> _bs2; // 位图2
};
void testFindOnceValSet()
{
int a[] = { 1,20,23,23,20,5,20,7,3,7 }; // 测试数据
FindOnceValSet<100> bs; // 开至少有100个比特位的位数组
for (const auto& e : a)
{
bs.set(e); // 把数组a的每个元素的出现次数映射到位图bs中
}
bs.print_once_num(); // 输出所有只出现一次的数据
}运行结果:1 3 5
(2)给两个文件,分别有 100 亿个整数,我们只有 1G 内存,如何找到两个文件交集?
分析问题:找到两个文件的交集,只需要判断这个数是否分别在两个文件中,是一个典型的 key 模型。
解决思路:定义两个位图。
- 位图 1 标识第一个文件中所有数的存在状态(1 存在、0 不存在)。
- 位图 2 标识第二个文件中所有数的存在状态(1 存在、0 不存在)。
- 遍历位图中的 N 个比特位,检测两个位图的同一个位置的比特位的值是否都为 1,如果都为 1,说明此位置映射的这个数就是交集。
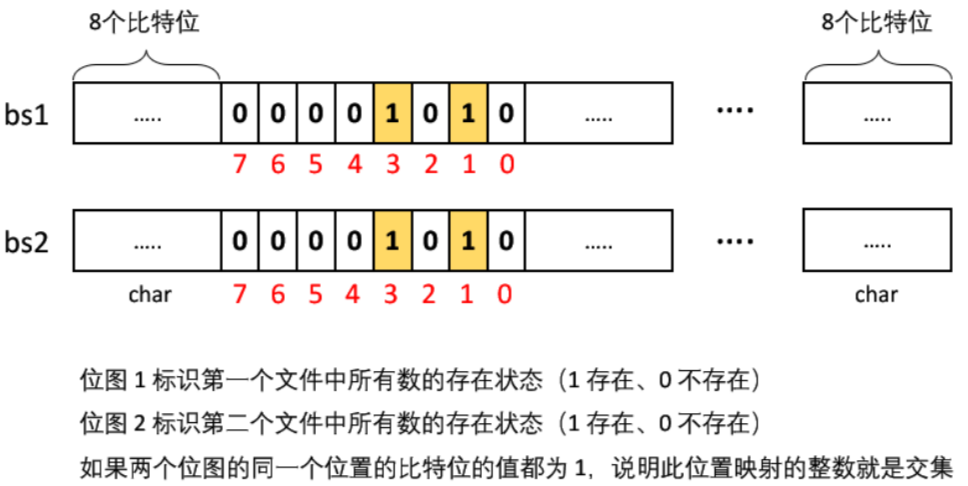
需要消耗的内存:
因为 unsigned int 整数的取值范围是 0 ~ 2³²-1(大约是42亿9千多万个整数),每个整数映射一个比特位,需要消耗 ( 2³²-1 ) / 8 个字节 ≈ 5亿多个字节 ≈ 0.5GB 的空间,这里开了两个位图,需要消耗 1GB 的空间。
(3)位图应用变形:1 个文件有 100 亿个 int,1G 内存,设计算法找到出现次数不超过 2 次的所有整数
和(1)类似。
解决思路:封装两个位图,用两个位图的同一个位置的 2 个比特位来标识一个数。
我们需要标记 4 种状态:不存在 / 出现一次 / 出现两次 / 出现多次。
因为两个比特位有 4 种表现形式 00 / 01 / 10 / 11,
所以:
- 00 - 表示这个数不存在
- 01 - 表示这个数只出现 1 次
- 10 - 表示这个数出现 2 次
- 11 - 表示这个数出现 2 次及以上
然后遍历位图,找到所有不是 11 标记的位置,此位置映射的就是出现次数不超过2次的整数。
(4)这里的位图问题也可以用哈希切分的思路来解决。但我们还是优先选择位图,更优一些
3、布隆过滤器
(1)给两个文件,分别有 100 亿个 query(查询),我们只有 1G 内存,如何找到两个文件交集?分别给出精确算法和近似算法
- 近似算法:把第一个文件中的100亿个查询插入布隆过滤器,再读取第二个文件,看当前查询在不在布隆过滤器中。如果不在,说明一定不是交集;如果在,说明可能是交集(因为存在误判)。
- 精确算法:哈希切分。
假设一个 query 平均 20 字节,则 100 亿个 query 大约是 2000 亿字节,则文件大约是 200 G。
第一步:
先创建 200 个小文件,分别叫 A0.txt、A1.txt、A2.txt、… A199.txt。
先创建 200 个小文件,分别叫 B0.txt、B1.txt、B2.txt、… B199.txt。
第二步:
依次读取 A 文件中的 query,使用字符串哈希算法转成可以取模的整型:
- size_t i = Hash( query ) % 200,把这个 query 放入到(映射到)第 Ai.txt 号小文件中。
依次读取 B 文件中的 query,使用字符串哈希算法转成可以取模的整型:
- size_t i = Hash( query ) % 200,把这个 query 放入到(映射到)第 Bi.txt 号小文件中。
注意:平均下来,每个小文件是 1G 左右(可能有些文件大,有些文件小)。
第二步结束后,文件中相同的 query 会分别进入编号相同的小文件,只需要去编号相同的小文件中找交集即可。
第三步:
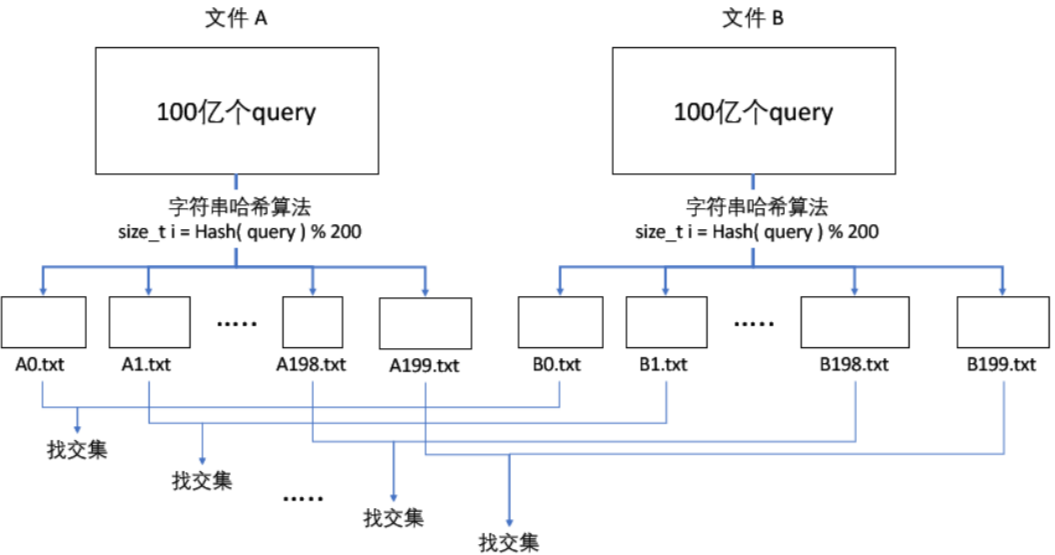
第四步:
i = [0, 199],把 Ai.txt 读进 setA 中,Bi.txt 读进 setB 中,setA 和 setB 相同的 query 就是交集。
核心思想:
原文件太大,存在磁盘中,直接读取去找交集效率太低,先切分成一个一个的小文件,然后再去读取小文件找交集。
(2)如何扩展 BloomFilter 使得它支持删除元素的操作。
一般情况下,布隆过滤器不支持删除 reset 接口,因为多个值可能会映射到同一个位,有哈希冲突,把该位置 0 可能会影响到其它值的状态。
如果想要支持删除 reset 接口呢?
可以弄一个计数器记录有多少个值映射到这个位了(比如使用两个比特位来记录,最多可以记录 3 个值),但是会付出更多空间消耗的代价。
4、其他
(1)哈希在加密中的应用
(2)哈希在存储中的应用:
- 当我们存储量超级大的时候,比如日常生活中使用的 QQ,我们要把每个用户的用户数据、QQ 空间中相册等数据存储起来,这是非常庞大的数据量,需要用服务器存储起来,一台服务器存不下,就弄多台服务器,每个服务器上存一部分,这就是分布式,然后对服务器进行集群管理(通过监控程序监控所有服务器的状态)。
- 问题:假设我有个好友发了一个朋友圈,数据提交到某台服务器上,我刷新朋友圈,会显示他发的朋友圈,但是怎么知道朋友圈数据是存在哪一台服务器上的呢?
- 每个用户都会有一个唯一 ID(比如手机号,身份证)标识该用户,一个用户的数据要存在哪台服务器上,就可以使用哈希映射,比如:Hash( ID ) % 服务器台数。所以这种分布式存储是一定要用哈希的。
- 但实际上远远比这复杂的多,比如万一某台服务器坏了呢?所以数据一般不会只存在一台服务器上,而是建立多副本,如果一台服务器坏了,就会重新建立映射,在其它服务器上建立新的副本。副本越多,越稳定,但空间消耗越大。还有比如新增或者减少了一些新服务器,那原先用户数据映射的位置也会发生改变,该如何解决呢?这就需要用到一致性哈希了。