七、Shell Here String(内嵌字符串,嵌入式字符串)
Here String 是《六、Shell Here Document(内嵌文档/立即文档)》的一个变种,它的用法如下:
command <<< string
command 是 Shell 命令,string 是字符串(它只是一个普通的字符串,并没有什么特别之处)。
这种写法告诉 Shell 把 string 部分作为命令需要处理的数据。例如,将小写字符串转换为大写:
[mozhiyan@localhost ~]$ tr a-z A-Z <<< one
ONE
Here String 对于这种发送较短的数据到进程是非常方便的,它比 Here Document 更加简洁。
1、双引号和单引号
一个单词不需要使用引号包围,但如果 string 中带有空格,则必须使用双引号或者单引号包围,如下所示:
[mozhiyan@localhost ~]$ tr a-z A-Z <<< "one two three"
ONE TWO THREE
双引号和单引号是有区别的,双引号会解析其中的变量(当然不写引号也会解析),单引号不会,请看下面的代码:
[mozhiyan@localhost ~]$ var=two
[mozhiyan@localhost ~]$ tr a-z A-Z <<<"one $var there"
ONE TWO THERE
[mozhiyan@localhost ~]$ tr a-z A-Z <<<'one $var there'
ONE $VAR THERE
[mozhiyan@localhost ~]$ tr a-z A-Z <<<one${var}there
ONETWOTHERE
有了引号的包围,Here String 还可以接收多行字符串作为命令的输入,如下所示:
[mozhiyan@localhost ~]$ tr a-z A-Z <<<"one two there
> four five six
> seven eight"
ONE TWO THERE
FOUR FIVE SIX
SEVEN EIGHT
2、总结
与 Here Document 相比,Here String 通常是相当方便的,特别是发送变量内容(而不是文件)到像 grep 或者 sed 这样的过滤程序时。
八、Shell组命令(把多条命令看做一个整体)
所谓组命令,就是将多个命令划分为一组,或者看成一个整体。
Shell 组命令的写法有两种:
{ command1; command2; command3; . . . }
(command1; command2; command3;. . . )
两种写法的区别在于:由花括号{}包围起来的组命名在当前 Shell 进程中执行,而由小括号()包围起来的组命令会创建一个子 Shell,所有命令都在子 Shell 中执行。
对于第一种写法,花括号和命令之间必须有一个空格,并且最后一个命令必须用一个分号或者一个换行符结束。
子 Shell 就是一个子进程,是通过当前 Shell 进程创建的一个新进程。但是子 Shell 和一般的子进程(比如bash ./test.sh创建的子进程)还是有差别的,我们将在《十二、子Shell和子进程到底有什么区别?》一节中深入讲解,读者暂时把子 Shell 和子进程等价起来就行。
组命令可以将多条命令的输出结果合并在一起,在使用重定向和管道时会特别方便。
例如,下面的代码将多个命令的输出重定向到 out.txt:
ls -l > out.txt #>表示覆盖
echo "http://c.biancheng.net/shell/" >> out.txt #>>表示追加
cat readme.txt >> out.txt
本段代码共使用了三次重定向。
借助组命令,我们可以将以上三条命令合并在一起,简化成一次重定向:
{ ls -l; echo "http://c.biancheng.net/shell/"; cat readme.txt; } > out.txt
或者写作:
(ls -l; echo "http://c.biancheng.net/shell/"; cat readme.txt) > out.txt
使用组命令技术,我们节省了一些打字时间。
类似的道理,我们也可以将组命令和管道结合起来:
{ ls -l; echo "http://c.biancheng.net/shell/"; cat readme.txt; } | lpr
这里我们把三个命令的输出结果合并在一起,并把它们用管道输送给命令 lpr 的输入,以便产生一个打印报告。
两种组命令形式的对比
虽然两种 Shell 组命令形式看起来相似,它们都能用在重定向中合并输出结果,但两者之间有一个很重要的不同:由{}包围的组命令在当前 Shell 进程中执行,由()包围的组命令会创建一个子Shell,所有命令都会在这个子 Shell 中执行。
在子 Shell 中执行意味着,运行环境被复制给了一个新的 shell 进程,当这个子 Shell 退出时,新的进程也会被销毁,环境副本也会消失,所以在子 Shell 环境中的任何更改都会消失(包括给变量赋值)。因此,在大多数情况下,除非脚本要求一个子 Shell,否则使用
{}比使用()更受欢迎,并且{}的进行速度更快,占用的内存更少。
九、Shell进程替换(把一个命令的输出传递给另一个命令)
进程替换和命令替换非常相似。《Shell编程 三、Shell命令替换:将命令的输出结果赋值给变量》是把一个命令的输出结果赋值给另一个变量,例如dir_files=`ls -l`或date_time=$(date);而进程替换则是把一个命令的输出结果传递给另一个(组)命令。
为了说明进程替换的必要性,我们先来看一个使用管道的例子:
echo "http://c.biancheng.net/shell/" | read
echo $REPLY
以上代码输出结果总是为空,因为 echo 命令在父 Shell 中执行,而 read 命令在子 Shell 中执行,当 read 执行结束时,子 Shell 被销毁,REPLY 变量也就消失了。管道中的命令总是在子 Shell 中执行的,任何给变量赋值的命令都会遭遇到这个问题。
使用 read 读取数据时,如果没有提供变量名,那么读取到的数据将存放到环境变量 REPLY 中,这一点已在《Shell编程 十九、、Shell read命令:读取从键盘输入的数据》中讲到。
幸运的是,Shell 提供了一种“特异功能”,叫做进程替换,它可以用来解决这种麻烦。
Shell 进程替换有两种写法,一种用来产生标准输出,借助输入重定向,它的输出结果可以作为另一个命令的输入:
<(commands)
另一种用来接受标准输入,借助输出重定向,它可以接收另一个命令的输出结果:
>(commands)
commands 是一组命令列表,多个命令之间以分号;分隔。注意,<或>与圆括号之间是没有空格的。
例如,为了解决上面遇到的问题,我们可以像下面这样使用进程替换:
read < <(echo "http://c.biancheng.net/shell/")
echo $REPLY
输出结果:
http://c.biancheng.net/shell/
整体上来看,Shell 把echo "http://c.biancheng.net/shell/"的输出结果作为 read 的输入。<()用来捕获 echo 命令的输出结果,<用来将该结果重定向到 read。
注意,两个<之间是有空格的,第一个<表示输入重定向,第二个<和()连在一起表示进程替换。
本例中的 read 命令和第二个 echo 命令都在当前 Shell 进程中运行,读取的数据也会保存到当前进程的 REPLY 变量,大家都在一个进程中,所以使用 echo 能够成功输出。
而在前面的例子中我们使用了管道,echo 命令在父进程中运行,read 命令在子进程中运行,读取的数据也保存在子进程的 REPLY 变量中,echo 命令和 REPLY 变量不在一个进程中,而子进程的环境变量对父进程是不可见的,所以读取失败。
再来看一个进程替换用作「接受标准输入」的例子:
echo "C语言中文网" > >(read; echo "你好,$REPLY")
运行结果:
你好,C语言中文网
因为使用了重定向,read 命令从echo "C语言中文网"的输出结果中读取数据。
Shell进程替换的本质
为了能够在不同进程之间传递数据,实际上进程替换会跟系统中的文件关联起来,这个文件的名字为/dev/fd/n(n 是一个整数)。该文件会作为参数传递给()中的命令,()中的命令对该文件是读取还是写入取决于进程替换格式是<还是>:
- 如果是
>(),那么该文件会给()中的命令提供输入;借助输出重定向,要输入的内容可以从其它命令而来。 - 如果是
<(),那么该文件会接收()中命令的输出结果;借助输入重定向,可以将该文件的内容作为其它命令的输入。
使用 echo 命令可以查看进程替换对应的文件名:
[c.biancheng.net]$ echo >(true)
/dev/fd/63
[c.biancheng.net]$ echo <(true)
/dev/fd/63
[c.biancheng.net]$ echo >(true) <(true)
/dev/fd/63 /dev/fd/62
/dev/fd/目录下有很多序号文件,进程替换一般用的是 63 号文件,该文件是系统内部文件,我们一般查看不到。
我们通过下面的语句进行实例分析:
echo "shellscript" > >(read; echo "hello, $REPLY")
第一个>表示输出重定向,它把第一个 echo 命令的输出结果重定向到/dev/fd/63文件中。>()中的第一个命令是 read,它需要从标准输入中读取数据,此时就用/dev/fd/63作为输入文件,把该文件的内容交给 read 命令,接着使用 echo 命令输出 read 读取到的内容。
可以看到,
/dev/fd/63文件起到了数据中转或者数据桥梁的作用,借助重定向,它将>()内部的命令和外部的命令联系起来,使得数据能够在这些命令之间流通。
十、Linux Shell管道详解
通过前面的学习,我们已经知道了怎样从文件重定向输入,以及重定向输出到文件。Shell 还有一种功能,就是可以将两个或者多个命令(程序或者进程)连接到一起,把一个命令的输出作为下一个命令的输入,以这种方式连接的两个或者多个命令就形成了管道(pipe)。
Linux 管道使用竖线|连接多个命令,这被称为管道符。Linux 管道的具体语法格式如下:
command1 | command2
command1 | command2 [ | commandN... ]
当在两个命令之间设置管道时,管道符|左边命令的输出就变成了右边命令的输入。只要第一个命令向标准输出写入,而第二个命令是从标准输入读取,那么这两个命令就可以形成一个管道。大部分的 Linux 命令都可以用来形成管道。
这里需要注意,command1 必须有正确输出,而 command2 必须可以处理 command2 的输出结果;而且 command2 只能处理 command1 的正确输出结果,不能处理 command1 的错误信息。
1、为什么使用管道?
我们先看下面一组命令,使用 mysqldump(一个数据库备份程序)来备份一个叫做 wiki 的数据库:
mysqldump -u root -p '123456' wiki > /tmp/wikidb.backup
gzip -9 /tmp/wikidb.backup
scp /tmp/wikidb.backup username@remote_ip:/backup/mysql/
上述这组命令主要做了如下任务:
- mysqldump 命令用于将名为 wike 的数据库备份到文件 /tmp/wikidb.backup;其中
-u和-p选项分别指出数据库的用户名和密码。 - gzip 命令用于压缩较大的数据库文件以节省磁盘空间;其中
-9表示最慢的压缩速度最好的压缩效果。 - scp 命令(secure copy,安全拷贝)用于将数据库备份文件复制到 IP 地址为 remote_ip 的备份服务器的 /backup/mysql/ 目录下。其中
username是登录远程服务器的用户名,命令执行后需要输入密码。
上述三个命令依次执行。然而,如果使用管道的话,你就可以将 mysqldump、gzip、ssh 命令相连接,这样就避免了创建临时文件 /tmp/wikidb.backup,而且可以同时执行这些命令并达到相同的效果。
使用管道后的命令如下所示:
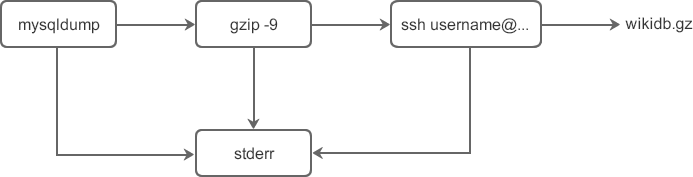
mysqldump -u root -p '123456' wiki | gzip -9 | ssh username@remote_ip "cat > /backup/wikidb.gz"
这些使用了管道的命令有如下特点:
- 命令的语法紧凑并且使用简单。
- 通过使用管道,将三个命令串联到一起就完成了远程 mysql 备份的复杂任务。
- 从管道输出的标准错误会混合到一起。
上述命令的数据流如下图所示:
2、重定向和管道的区别
乍看起来,管道也有重定向的作用,它也改变了数据输入输出的方向,那么,管道和重定向之间到底有什么不同呢?
简单地说,重定向操作符>将命令与文件连接起来,用文件来接收命令的输出;而管道符|将命令与命令连接起来,用第二个命令来接收第一个命令的输出。如下所示:
command > file
command1 | command1
有些读者在学习管道时会尝试如下的命令,我们来看一下会发生什么:
command1 > command2
答案是,有时尝试的结果将会很糟糕。这是一个实际的例子,一个 Linux 系统管理员以超级用户(root 用户)的身份执行了如下命令:
cd /usr/bin
ls > less
第一条命令将当前目录切换到了大多数程序所存放的目录,第二条命令是告诉 Shell 用 ls 命令的输出重写文件 less。因为 /usr/bin 目录已经包含了名称为 less(less 程序)的文件,第二条命令用 ls 输出的文本重写了 less 程序,因此破坏了文件系统中的 less 程序。
这是使用重定向操作符错误重写文件的一个教训,所以在使用它时要谨慎。
3、Linux管道实例
【实例1】将 ls 命令的输出发送到 grep 命令:
[c.biancheng.net]$ ls | grep log.txt
log.txt
上述命令是查看文件 log.txt 是否存在于当前目录下。
我们可以在命令的后面使用选项,例如使用-al选项:
[c.biancheng.net]$ ls -al | grep log.txt
-rw-rw-r--. 1 mozhiyan mozhiyan 0 4月 15 17:26 log.txt
管道符|与两侧的命令之间也可以不存在空格,例如将上述命令写作ls -al|grep log.txt;然而我还是推荐在管道符|和两侧的命令之间使用空格,以增加代码的可读性。
我们也可以重定向管道的输出到一个文件,比如将上述管道命令的输出结果发送到文件 output.txt 中:
[c.biancheng.net]$ ls -al | grep log.txt >output.txt
[c.biancheng.net]$ cat output.txt
-rw-rw-r--. 1 mozhiyan mozhiyan 0 4月 15 17:26 log.txt
【实例2】使用管道将 cat 命令的输出作为 less 命令的输入,这样就可以将 cat 命令的输出每次按照一个屏幕的长度显示,这对于查看长度大于一个屏幕的文件内容很有帮助。
cat /var/log/message | less
【实例3】查看指定程序的进程运行状态,并将输出重定向到文件中。
[c.biancheng.net]$ ps aux | grep httpd > /tmp/ps.output
[c.biancheng.net]$ cat /tem/ps.output
mozhiyan 4101 13776 0 10:11 pts/3 00:00:00 grep httpd
root 4578 1 0 Dec09 ? 00:00:00 /usr/sbin/httpd
apache 19984 4578 0 Dec29 ? 00:00:00 /usr/sbin/httpd
apache 19985 4578 0 Dec29? 00:00:00 /usr/sbin/httpd
apache 19986 4578 0 Dec29 ? 00:00:00 /usr/sbin/httpd
apache 19987 4578 0 Dec29 ? 00:00:00 /usr/sbin/httpd
apach 19988 4578 0 Dec29 ? 00:00:00 /usr/sbin/httpd
apach 19989 4578 0 Dec29 ? 00:00:00 /usr/sbin/httpd
apache 19990 4578 0 Dec29 ? 00:00:00 /usr/sbin/httpd
apache 19991 4578 0 Dec29 ? 00:00:00 /usr/sbin/httpd
【实例4】显示按用户名排序后的当前登录系统的用户的信息。
[c.biancheng.net]$ who | sort
mozhiyan :0 2019-04-16 12:55 (:0)
mozhiyan pts/0 2019-04-16 13:16 (:0)
who 命令的输出将作为 sort 命令的输入,所以这两个命令通过管道连接后会显示按照用户名排序的已登录用户的信息。
【实例5】统计系统中当前登录的用户数。
[c.biancheng.net]$ who | wc -l
5
4、管道与输入重定向
输入重定向操作符<可以在管道中使用,以用来从文件中获取输入,其语法类似下面这样:
command1 < input.txt | command2
command1 < input.txt | command2 -option | command3
例如,使用 tr 命令从 os.txt 文件中获取输入,然后通过管道将输出发送给 sort 或 uniq 等命令:
[c.biancheng.net]$ cat os.txt
redhat
suse
centos
ubuntu
solaris
hp-ux
fedora
centos
redhat
hp-ux
[c.biancheng.net]$ tr a-z A-Z <os.txt | sort
CENTOS
CENTOS
FEDORA
HP-UX
HP-UX
REDHAT
REDHAT
SOLARIS
SUSE
UBUNTU
[c.biancheng.net]$ tr a-z A-Z <os.txt | sort | uniq
CENTOS
FEDORA
HP-UX
REDHAT
SOLARIS
SUSE
UBUNTU
5、管道与输出重定向
你也可以使用重定向操作符>或>>将管道中的最后一个命令的标准输出进行重定向,其语法如下所示:
command1 | command2 | ... | commandN > output.txt
command1 < input.txt | command2 | ... | commandN > output.txt
【实例1】使用 mount 命令显示当前挂载的文件系统的信息,并使用 column 命令格式化列的输出,最后将输出结果保存到一个文件中。
[c.biancheng.net]$ mount | column -t >mounted.txt
[c.biancheng.net]$ cat mounted.txt
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel)
devtmpfs on /dev type devtmpfs (rw,nosuid,seclabel,size=496136k,nr_inodes=124034,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev,seclabel)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,seclabel,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,seclabel,mode=755)
tmpfs on /sys/fs/cgroup type tmpfs (rw,nosuid,nodev,noexec,seclabel,mode=755)
#####此处省略部分内容#####
【实例2】使用 tr 命令将 os.txt 文件中的内容转化为大写,并使用 sort 命令将内容排序,使用 uniq 命令去除重复的行,最后将输出重定向到文件 ox.txt.new。
[c.biancheng.net]$ cat os.txt
redhat
suse
centos
ubuntu
solaris
hp-ux
fedora
centos
redhat
hp-ux
[c.biancheng.net]$ tr a-z A-Z <os.txt | sort | uniq >os.txt.new
[c.biancheng.net]$ cat os.txt.new
CENTOS
FEDORA
HP-UX
REDHAT
SOLARIS
SUSE
UBUNTU
十一、Shell过滤器
我们己经知道,将几个命令通过管道符组合在一起就形成一个管道。通常,通过这种方式使用的命令就被称为过滤器。过滤器会获取输入,通过某种方式修改其内容,然后将其输出。
简单地说,过滤器可以概括为以下两点:
- 如果一个 Linux 命令是从标准输入接收它的输入数据,并在标准输出上产生它的输出数据(结果),那么这个命令就被称为过滤器。
- 过滤器通常与 Linux 管道一起使用。
常用的被作为过滤器使用的命令如下所示:
| 命令 | 说明 |
|---|---|
| awk | 用于文本处理的解释性程序设计语言,通常被作为数据提取和报告的工具。 |
| cut | 用于将每个输入文件(如果没有指定文件则为标准输入)的每行的指定部分输出到标准输出。 |
| grep | 用于搜索一个或多个文件中匹配指定模式的行。 |
| tar | 用于归档文件的应用程序。 |
| head | 用于读取文件的开头部分(默认是 10 行)。如果没有指定文件,则从标准输入读取。 |
| paste | 用于合并文件的行。 |
| sed | 用于过滤和转换文本的流编辑器。 |
| sort | 用于对文本文件的行进行排序。 |
| split | 用于将文件分割成块。 |
| strings | 用于打印文件中可打印的字符串。 |
| tac | 与 cat 命令的功能相反,用于倒序地显示文件或连接文件。 |
| tail | 用于显示文件的结尾部分。 |
| tee | 用于从标准输入读取内容并写入到标准输出和文件。 |
| tr | 用于转换或删除字符。 |
| uniq | 用于报告或忽略重复的行。 |
| wc | 用于打印文件中的总行数、单词数或字节数。 |
接下来,我们通过几个实例来演示一下过滤器的使用。
1、在管道中使用 awk 命令
关于 awk 命令的具体用法,请大家自行学习,本节我们我们仅通过几个简单的实例来了解一下 awk 命令在管道中的使用。
(1)实例1
查看系统中的所有的账号名称,并按名称的字母顺序排序。
[c.biancheng.net]$ awk -F: '{print $1}' /etc/passwd | sort
adm
apache
avahi
avahi-autoipd
bin
daemon
dbus
ftp
games ...
在上例中,使用冒号:作为列分隔符,将文件 /etc/passwd 的内容分为了多列,并打印了第一列的信息(即用户名),然后将输出通过管道发送到了 sort 命令。
(2)实例2
列出当前账号最常使用的 10 个命令。
[c.biancheng.net]$ history | awk '{print $2}' | sort | uniq -c | sort -rn | head
140 echo
75 man
71 cat
63 su
53 ls
50 vi
47 cd
40 date
26 let
25 paste
在上例中,history 命令将输出通过管道发送到 awk 命令,awk 命令默认使用空格作为列分隔符,将 history 的输出分为了两列,并把第二列内容作为输出通过管道发送到了 sort 命令,使用 sort 命令进行排序后,再将输出通过管道发送到了 uniq 命令,使用 uniq 命令 统计了历史命令重复出现的次数,再用 sort 命令将 uniq 命令的输出按照重复次数从高到低排序,最后使用 head 命令默认列出前 10 个的信息。
(3)实例3
显示当前系统的总内存大小,单位为 KB。
[c.biancheng.net]$ free | grep Mem | awk '{print $2}'
2029860
2、在管道中使用 cut 命令
cut 命令被用于文本处理。你可以使用这个命令来提取文件中指定列的内容。
(1)实例1
查看系统中登录 Shell 是“/bin/bash”的用户名和对应的用户主目录的信息:
[c.biancheng.net]$ grep "bin/bash" /etc/passwd | cut -d: -f1,6
root:/root
mozhiyan:/home/mozhiyan
如果你对 Linux 系统有所了解,你会知道,/ctc/passwd 文件被用来存放用户账号的信息,此文件中的每一行会记录一个账号的信息,每个字段之间用冒号分隔,第一个字段即是账号的账户名,而第六个字段就是账号的主目录的路径。
(2)实例2
查看当前机器的CPU类型。
[c.biancheng.net]$ cat /proc/cpuinfo | grep name | cut -d: -f2 | uniq
Intel(R) Core(TM) i5-2520M CPU @ 2.50GHz
上例中,执行命令cat /proc/cpuinfo | grep name得到的内容如下所示:
[c.biancheng.net]$ cat /proc/cpuinfo | grep name
model name : Intel(R) Core(TM) i5-2520M CPU @ 2.50GHz
model name : Intel(R) Core(TM) i5-2520M CPU @ 2.50GHz
model name : Intel(R) Core(TM) i5-2520M CPU @ 2.50GHz
model name : Intel(R) Core(TM) i5-2520M CPU 0 2.50GHz
然后,我们使用 cut 命令将上述输出内容以冒号作为分隔符,将内容分为了两列, 并显示第二列的内容,最后使用 uniq 命令去掉了重复的行。
(3)实例3
查看当前目录下的子目录数。
[c.biancheng.net]$ ls -l | cut -c 1 | grep d | wc -l
5
上述管道命令主要做了如下操作:
- 命令
ls -l输出的内容中,每行的第一个字符表示文件的类型,如果第一个字符是d,就表示文件的类型是目录。 - 命令
cut -c 1是截取每行的第一个字符。 - 命令
grep d来获取文件类型是目录的行。 - 命令
wc -l用来获得 grep 命令输出结果的行数,即目录个数。
3、在管道中使用grep命令
grep 命令是在管道中比较常用的一个命令。
(1)实例1
查看系统日志文件中的错误信息。
[c.biancheng.net]$ grep -i "error:" /var/log/messages | less
(2)实例2
查看系统中 HTTP 服务的进程信息。
[c.biancheng.net]$ ps auxwww | grep httpd
apache 18968 0.0 0.0 26472 10404 ? S Dec15 0:01 /usr/sbin/httpd
apache 18969 0.0 0.0 25528 8308 ? S Dec15 0:01 /usr/sbin/httpd
apache 18970 0.0 0.0 26596 10524 ? S Dec15 0:01 /usr/sbin/httpd
(3)实例3
查找我们的程序列表中所有命令名中包含关键字 zip 的命令。
[c.biancheng.net]$ ls /bin /usr/bin | sort | uniq | grep zip
bunzip2
bzip2 bzip2recover
gunzip
gzip
(4)实例4
查看系统安装的 kernel 版本及相关的 kernel 软件包。
[c.biancheng.net]$ rpm -qa | grep kernel
kernel-2.6.18-92.e15
kernel-debuginfo-2.6.18-92.e15
kernel-debuginfo-common-2.6.18-92.e15
kernel-devel-2.6.18-92.e15
(5)实例5
查找 /etc 目录下所有包含 IP 地址的文件。
[c.biancheng.net]$ find /etc -type f -exec grep '[0-9][0-9]*[.][0-9][0-9]*[.][0-9][0-9]*[.][0-9][0-9]*' {} \;
4、在管道中使用 tar 命令
tar 命令是 Linux 系统中最常用的打包文件的程序。
(1)实例1
你可以使用 tar 命令复制一个目录的整体结构。
[c.biancheng.net]$ tar cf - /home/mozhiyan | ( cd /backup/; tar xf - )
(2)实例2
跨网络地复制一个目录的整体结构。
[c.biancheng.net]$ tar cf - /home/mozhiyan | ssh remote_host "( cd /backup/; tar xf - )"
(3)实例3
跨网络地压缩复制一个目录的整体结构。
[c.biancheng.net]$ tar czf - /home/mozhiyan | ssh remote_host "( cd /backup/; tar xzf - )"
(4)实例4
检査 tar 归档文件的大小,单位为字节。
[c.biancheng.net]$ cd /; tar cf - etc | wc -c
215040
(5)实例5
检查 tar 归档文件压缩为 tar.gz 归裆文件后所占的大小。
[c.biancheng.net]$ tar czf - etc.tar | wc -c
58006
(6)实例6
检查 tar 归档文件压缩为 tar.bz2 归裆文件后所占的大小。
[c.biancheng.net]$ tar cjf - etc.tar | wc -c
50708
5、在管道中使用 head 命令
有时,你不需要一个命令的全部输出,可能只需要命令的前几行输出。这时,就可以使用 head 命令,它只打印命令的前几行输出。默认的输出行数为 10 行。
(1)实例1
显示 ls 命令的前 10 行输出。
[c.biancheng.net]$ ls /usr/bin | head
addftinfo
afmtodit
apropos
arch
ash
awk
base64
basename
bash
bashbug
(2)实例2
显示 ls 命令的前 5 行内容。
[c.biancheng.net]$ ls / | head -n 5
bincygdrive
Cygwin.bat
Cygwin.ico
Cygwin-Terminal.ico
6、在管道中使用 uniq 命令
uniq 命令用于报告或删除重复的行。我们将使用一个测试文件进行管道中使用 uniq 命令的实例讲解,其内容如下所示:
[c.biancheng.net]$ cat testfile This line occurs only once.
This line occurs twice.
This line occurs twice.
This line occurs three times.
This line occurs three times.
This line occurs three times.
(1)实例1
去掉输出中重复的行。
[c.biancheng.net]$ sort testfile | uniq
This line occurs only once.
This line occurs three times.
This line occurs twice.
(2)实例2
显示输出中各重复的行出现的次数,并按次数多少倒序显示。
[c.biancheng.net]$ sort testfile | uniq -c | sort -nr
3 This line occurs three times.
2 This line occurs twice.
1 This line occurs only once.
7、在管道中使用 wc 命令
wc 命令用于统计包含在文本流中的字符数、单同数和行数。
(1)实例1
统计当前登录到系统的用户数。
[c.biancheng.net]$ who | wc -l
(2)实例2
统计当前的 Linux 系统中的进程数。
[c.biancheng.net]$ ps -ef | wc -l
十二、子Shell和子进程到底有什么区别?
Shell 中有很多方法产生子进程,比如以新进程的方式运行 Shell 脚本,使用组命令、管道、命令替换等,但是这些子进程是有区别的。
子进程的概念是由父进程的概念引申而来的。在 Linux 系统中,系统运行的应用程序几乎都是从 init(pid为 1 的进程)进程派生而来的,所有这些应用程序都可以视为 init 进程的子进程,而 init 则为它们的父进程。
使用pstree -p命令就可以看到 init 及系统中其他进程的进程树信息(包括 pid):
systemd(1)─┬─ModemManager(796)─┬─{ModemManager}(821)
│ └─{ModemManager}(882)
├─NetworkManager(975)─┬─{NetworkManager}(1061)
│ └─{NetworkManager}(1077)
├─abrt-watch-log(774)
├─abrt-watch-log(776)
├─abrtd(773)
├─accounts-daemon(806)─┬─{accounts-daemon}(839)
│ └─{accounts-daemon}(883)
├─alsactl(768)
├─at-spi-bus-laun(1954)─┬─dbus-daemon(1958)───{dbus-daemon}(1960)
│ ├─{at-spi-bus-laun}(1955)
│ ├─{at-spi-bus-laun}(1957)
│ └─{at-spi-bus-laun}(1959)
├─at-spi2-registr(1962)───{at-spi2-registr}(1965)
├─atd(842)
├─auditd(739)─┬─audispd(753)─┬─sedispatch(757)
│ │ └─{audispd}(759)
│ └─{auditd}(752)
本教程基于 CentOS 7 编写,CentOS 7 为了提高启动速度使用 systemd 替代了 init。CentOS 7 之前的版本依然使用 init。
Shell 脚本是从上至下、从左至右依次执行的,即执行完一个命令之后再执行下一个。如果在 Shell 脚本中遇到子脚本(即脚本嵌套,但是必须以新进程的方式运行)或者外部命令,就会向系统内核申请创建一个新的进程,以便在该进程中执行子脚本或者外部命令,这个新的进程就是子进程。子进程执行完毕后才能回到父进程,才能继续执行父脚本中后续的命令及语句。
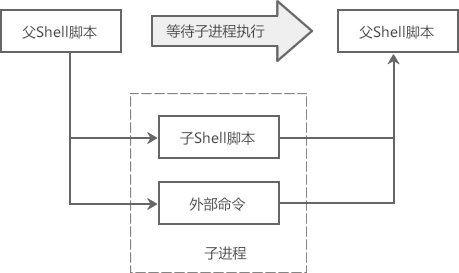
1、子进程的创建
了解 Linux 编程的读者应该知道,使用 fork() 函数可以创建一个子进程;除了 PID(进程ID)等极少的参数不同外,子进程的一切都来自父进程,包括代码、数据、堆栈、打开的文件等,就连代码的执行位置(状态)都是一样的。
也就是说,fork() 克隆了一个一模一样的自己,身高、体重、颜值、嗓音、年龄等各种属性都相同。当然,后期随着各自的发展轨迹不同,两者会变得不一样,比如 A 好吃懒做越来越肥,B 经常健身成了一个肌肉男;但是在 fork() 出来的那一刻,两者都是一样的。
Linux 还有一种创建子进程的方式,就是子进程被 fork() 出来以后立即调用 exec() 函数加载新的可执行文件,而不使用从父进程继承来的一切。什么意思呢?
比如在 ~/bin 目录下有两个可执行文件分别叫 a.out 和 b.out。现在我运行 a.out,就会产生一个进程,比如叫做 A。在进程 A 中我又调用 fork() 函数创建了一个进程 B,那么 B 就是 A 的子进程,此时它们是一模一样的。但是,我调用 fork() 后立即又调用 exec() 去加载 b.out,这可就坏事了,B 进程中的一切(包括代码、数据、堆栈等)都会被销毁,然后再根据 b.out 重建建立一切。这样一折腾,B 进程除了 ID 没有变,其它的都变了,再也没有属于 A 的东西了。
你看,同样是创建子进程,但是结果却大相径庭:
- 第一种只使用 fork() 函数,子进程和父进程几乎是一模一样的,父进程中的函数、变量、别名等在子进程中仍然有效。
- 第二种使用 fork() 和 exec() 函数,子进程和父进程之间除了硬生生地维持一种“父子关系”外,再也没有任何联系了,它们就是两个完全不同的程序。
对于 Shell 来说,以新进程的方式运行脚本文件,比如bash ./test.sh、chmod +x ./test.sh; ./test.sh,或者在当前 Shell 中使用 bash 命令启动新的 Shell,它们都属于第二种创建子进程的方式,所以子进程除了能继承父进程的环境变量外,基本上也不能使用父进程的什么东西了,比如,父进程的全局变量、局部变量、文件描述符、别名等在子进程中都无效。
但是,组命令、命令替换、管道这几种语法都使用第一种方式创建进程,所以子进程可以使用父进程的一切,包括全局变量、局部变量、别名等。我们将这种子进程称为子 Shell(sub shell)。
子 Shell 虽然能使用父 Shell 的的一切,但是如果子 Shell 对数据做了修改,比如修改了全局变量,那么这种修改只能停留在子 Shell,无法传递给父 Shell。不管是子进程还是子 Shell,都是“传子不传父”。
2、总结
子 Shell 才是真正继承了父进程的一切,这才像“一个模子刻出来的”;普通子进程和父进程是完全不同的两个程序,只是维持着父子关系而已。
三十号上午