Hi,你好。我是茶桁。
咱们经过前一轮的学习,已经完成了一个小型的神经网络框架。但是这也只是个开始而已,在之后的课程中,针对深度学习我们需要进阶学习。
我们要学到超参数,优化器,卷积神经网络等等。看起来,任务还是蛮重的。
行吧,让我们开始。
矩阵运算的维度
首先,我们之前写了一份拓朴排序的代码。那我们是否了解在神经网络中拓朴排序的作用。我们前面讲过的内容大家可以回忆一下,拓朴排序在咱们的神经网络中的作用不是为了计算方便,是为了能计算。
换句话说,没有拓朴排序的话,根本就没法计算了。Tensorflow和PyTourh最大的区别就是,Tensorflow在运行之前必须得把拓朴排序建好,PyTorch是在运行的过程中自己根据我们的连接状况一边运行一边建立。但是它们都有拓朴排序。
拓朴排序后要进行计算,那就要提到维度问题,在进行机器学习的时候一定要确保我们矩阵运算的维度正确。我们来看一下示例就明白我要说的了。
x = torch.from_numpy(np.random.random(size=(4, 10)))
print(x.shape)
---
torch.Size([4, 10])
假如说,现在我们生成了一个4,10的矩阵,也就是4行10列。
from torch import nn
linear = nn.Linear(in_features=10, out_features=5).double()
print(linear(x).shape)
---
torch.Size([4, 5])
然后我们来给他定义一个线性变化,in_features=10,这个就是必须的, 然后,out_features=5,假如把它分成5类。
这个时候,你看他就变成一个四行五列的一个东西了。
刚才我们说了,in_features=10是必须的,如果这个值我们设置成其他的,比如说8,那就不行了,运行不了。会收到警告:mat1 and mat2 shapes cannot be multiplied (4x10 and 8x5)
我们再给它来一个Softmax
nonlinear = nn.Softmax()
print(nonlinear(linear(x)))
这样,我们就得到了一个4*5的概率分布。
我们把这个非线性函数换一下,换成Sigmoid, 之前的Softmax赋值给yhat, 咱们做一个多层的:
yhat = nn.Softmax()
nonlinear = nn.Sigmoid()
linear2 = nn.linear(in_features=n, out_features=8).double()
print(yhat(linear2(nonlinear(linear(x)))))
好,这个时候,我还并没有给in_features赋值,我们来想想,这个时候应该赋值是多少?也就是说,我们现在的linear2到底传入的特征是多少?
我们这里定义的linear和linear2其实就是w*x+b。
那这里我们来推一下,第一次使用linear的时候,我们得到了4*5的矩阵对吧?nonlinear并没有改变矩阵的维度。现在linear2中,那我们in_features赋值就得是5对吧?
yhat = nn.Softmax()
nonlinear = nn.Sigmoid()
linear2 = nn.linear(in_features=5, out_features=8).double()
print(yhat(linear2(nonlinear(linear(x)))).shape)
---
torch.Size([4, 8])
然后我们就得到了一个4*8的维度的矩阵。
那其实在PyTorch里提供了一种比较简单的方法,就叫做Sequential:
model = nn.Sequential(
nn.Linear(in_features=10, out_features=5).double(),
nn.Sigmoid(),
nn.Linear(in_features=5, out_features=8).double(),
nn.Softmax(),
)
print(model(x).shape)
---
torch.Size([4, 8])
这样,我们就把刚才几个函数方法按顺序都一个一个的写在Sequential里,那其实刚才的过程,也就是解释了这个方法的原理。
接着,我们来写一个ytrue:
ytrue = torch.randint(8, (4, ))
loss_fn = nn.CrossEntropyLoss()
print(model(x).shape)
print(ytrue.shape)
---
torch.Size([4, 8])
torch.Size([4])
现在ytrue就是CrossEntropyLoss输入的一个label值。
然后我们就可以进行反向传播了:
loss.backward()
for p in model.parameters():
print(p, p.grad)
---
Parameter containing:
tensor([...])
...
求解反向传播之后就可以得到它的梯度了。然后再经过一轮一轮的训练,就可以把梯度稳定在某个值,这就是神经网络进行学习的一个过程。那主要是在这个过程中,一定要注意矩阵前后的大小。
激活函数
然后我们来看看激活函数的重要性。
在我们之前的课程中,我们提到过一个概念「激活函数」,不知道大家还有没有印象。那么激活函数的作用是什么呢? 是实现非线性拟合对吧?
打比方来说,如果我们现在要拟合一个函数f(x) = w*x+b, 你把它再给送到一个g(x), 再比如g(x)=w2*x+b,我们来做一个拟合,那么g(f(x)), 那是不是还是一样,g(f(x)) = w2*(w*x+b)+b, 然后就变成w2*w*x + w2*b + b, 那其实这个就还是一个线性函数。
我们每一段都给它进行一个线性变化,再进行一个非线性变化,再进行一个线性变化,一段一段这样折起来,理论上它可以拟合任何函数。
这个怎么理解?其实我们如何用已知的函数去拟合函数在高等数学里边是一个一直在学习,一直在研究的东西。学高数的同学应该知道,高数里面有一个著名的东西叫做傅立叶变化,这是一种线性积分变换,用于函数在时域和频域之间的变换。
我们给定任意一个复杂的函数,都可以通过sin和cos来把它拟合出来,其关键思想是任何连续、周期或非周期的函数都可以表示为正弦和余弦函数的组合。通过计算不同频率的正弦和余弦成分的系数an和bn, 我们可以了解一个函数的频谱特性,即它包含那些频率成分。
f ( x ) = a 0 + ∑ n = 1 0 ( a n c o s ( 2 π n f x ) + b n s i n ( 2 π n f x ) ) \begin{align*} f(x) = a_0 + \sum_{n=1}^0(a_n cos(2\pi nfx) + b_n sin(2\pi n fx)) \end{align*} f(x)=a0+n=1∑0(ancos(2πnfx)+bnsin(2πnfx))
除此之外,我们还有一个泰勒展开。我在数学篇的时候有仔细讲解过这个部分,大家可以回头去读一下我那篇文章,应该是数学篇第13节课,在那里我曾说过,所有的复杂函数都是用泰勒展开转换成多项式函数计算的。
之前有同学给我私信,也有同学在我文章下留言,说到某个位置看不懂了,还是数学拖了后腿。但是其实只是应用的话无所谓,但是如果想在这个方面有所建树,想要做些不一样的东西出来,还是要把数学的东西好好补一下的。
OK,那其实呢,我们的深度学习本质上其实就是在做这么一件事情,就是来自动拟合,到底是由什么构成的。
大家再来想一下,一个比较重要的,就是反向传播和前向传播。这个我们前面的课程里有详细的讲过,就是,我们的前向传播和反向传播的作用是什么。
那现在我们学完前几节了,回过头来我们想想,前向传播的作用是什么?反向传播的这个作用呢?
现在,假如说我已经训练出来了一个模型,我要用这个模型去预测。那么第一个问题是,预测的时候需不需要求loss?第二个是我需不需要做反向传播?
然后我们再来思考一个问题,如果我们需要求loss对于某个参数wi的偏导 ∂ l o s s ∂ w i \frac{\partial loss}{\partial w_i} ∂wi∂loss,那么我们首先需要进行反向传播对吧?那我们在进行反向传播之前,能不能不进行前向传播?
也就是说,我们把这个模型放在这里,一个x,然后输入进去得到一个loss。那么咱们训练了一轮之后,我们能不能在求解的时候不进行前向传播,直接进行反向传播?
我们只要知道,求loss值需要预测值就明白了。
那我们继续来思考,loss值和precision、recall等等的关系是什么?这些是什么?我们之前学习过,这些是评测指标对吧?也就是再问,loss和评测指标的关系是什么?
也就是说,我们能不能用precision,能不能用precision来做我们的loss函数?不能对吧,无法求导。
所以在整个机器学习的过程中,如果要有反向传播、梯度下降,必须得是可导的。像我们所说的MSE是可导的,cross-entropy也是可以求导的。
那如果上过我之前课程的同学应该记得,可求导的的函数需要满足什么条件?光滑性和连续性对吧?连续性呢,是可求导的一个必要条件,但不是充分条件,还必须在某个点附近足够光滑,以使得导数存在。
对于loss函数的设定,第一点,一定是要能求偏导的。第二呢,就是它一定得是一个凸函数:Convex functions。
那什么叫做凸函数呢?如果一个函数上的任意两点连线上的函数值都不低于这两点的函数值的线段,就称为凸函数。常见的比如线性函数,指数函数,幂函数,绝对值函数等都是凸函数。
想象一下,有一辆车,从a点开到b点,如果这个车在a点到b点的时候方向盘始终是打在一个方向的,那我们就说它是凸函数。
不过在一些情况下有些函数它不是凸函数,就在数学上专门有一个研究领域,Convex optimization,凸优化其实就是解决对于这种函数怎么样快速的求出他的基值,另外一个就是对于这种非凸函数怎么把它变成凸函数。
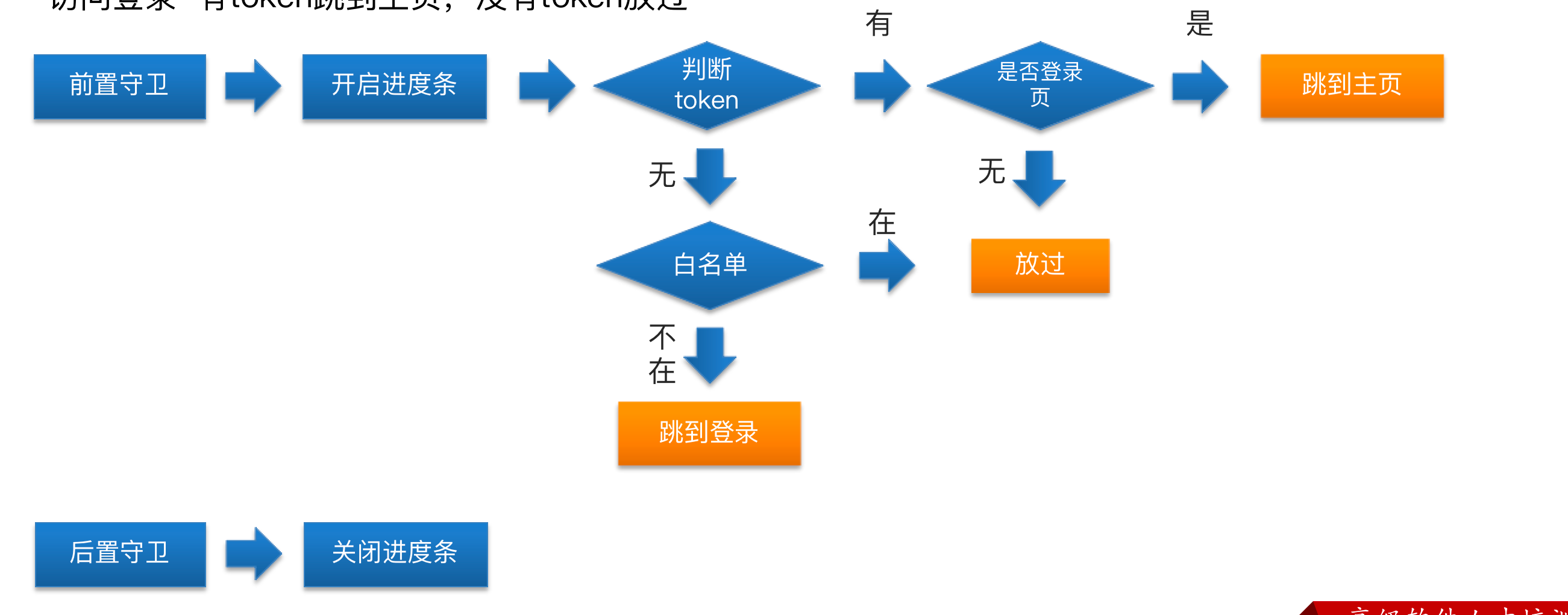
不同的激活函数它有什么区别呢?在最早的时候,大家用的是Sigmoid:
σ ( z ) = 1 1 + e − z \begin{align*} \sigma(z)=\frac{1}{1+e^{-z}} \end{align*} σ(z)=1+e−z1
为什么最早用Sigmoid,这是因为Sigmoid有个天然的优势,就是它输出是0-1,而且它处处可导。
但是后来Sigmoid的结果有个e^x,指数运算就比较费时,这是第一个问题。第二个问题是Sigmoid的输出虽然是在0~1之间,但是平均值是0.5,对于程序来说,我们希望获得均值等于0,STD等于1。我们往往希望把它变成这样的一种函数,这样的话做梯度下降的时候比较好做。
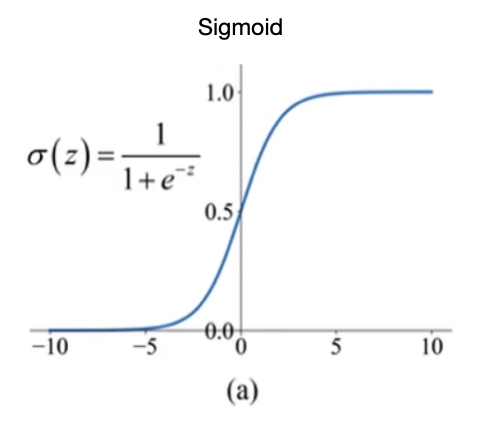
于是就又提出来了一个更简单的方法,就是反正切函数:Tanh。
σ ( z ) = e z − e − z e z + e − z \sigma(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}} σ(z)=ez+e−zez−e−z
它的形式和Sigmoid很像,不同的是平均值,它的平均值是0。现在这个用的也挺多。
但是Tanh和sigmoid一样都有一个小问题,就是它的绝大多数地方loss都等于0, 那么wi大部分时候就没有办法学习,也就不会更新。
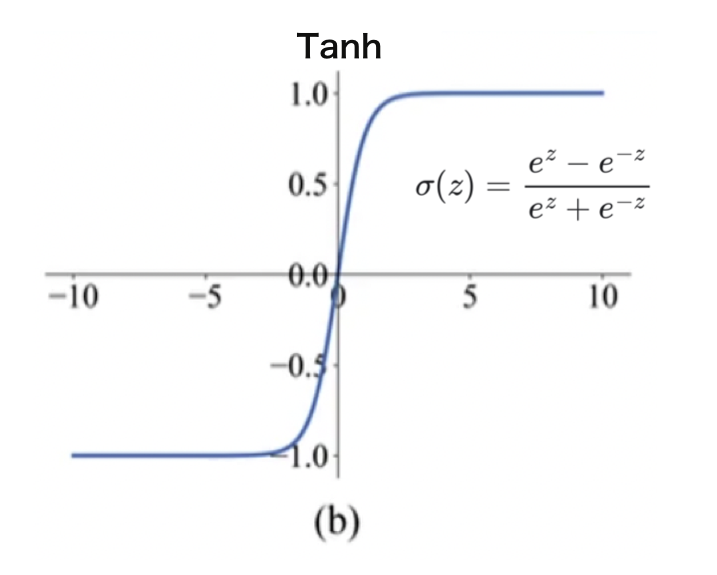
为了解决这个问题,就是有人提出来了一种非常简单的方法,就是ReLU:
R e L U ( z ) = { z , z > 0 0 , o t h e r w i s e \begin{align*} ReLU(z) = \begin{cases} z, z>0 \\ 0, otherwise \end{cases} \end{align*} ReLU(z)={z,z>00,otherwise
这种方法看似非常简单,但其实非常好用。它就是当一个x值经过ReLU的时候,如果它大于0就还保持原来的值,如果不大于0就直接把它变成0。
这样大家可能会觉得x<0时有这么多值没有办法求导,但其实比起sigmoid来说可求导的范围其实已经变多了。而且你会发现要对他x大于0的地方求偏导非常的简单,就直接等于1。
可以保证它肯定是可以做更新的,而且ReLU这种函数它是大量的被应用在卷积神经网络里边。
在咱们后面的课程中,会讲到卷积,它是有一个卷积核,[F1,F2,F3,F4]然后把它经过ReLU之后,可能会变成[F1,0,F3,0]。那我们只要更新F1,F3就可以了,下一次再经过某种方式,在重新把F2和F4我们重新计算一下。
也就是说现在的wx+b不像以前一样,只有一个w,如果x值等于0,那整个都等于0. 而是我们会有一个矩阵,它部分等于0也没关系。而且它的求导会变得非常的快,比求指数的导数快多了。
那其实这里还有一个小问题,面试的时候可能会问到,就是ReLU其实在0点的时候不可导,怎么办?
这个很简单,可以在函数里边直接设置一下,直接给他一个0的值就可以了,就是在代码里面加一句话。
再后来,又有人提出了一种方法:LeakyRelU:
L e a k y R e L U ( z ) = { z , z > 0 a z , o t h e r w i s e LeakyReLU(z) = \begin{cases} z, z>0 \\ az, otherwise \end{cases} LeakyReLU(z)={z,z>0az,otherwise
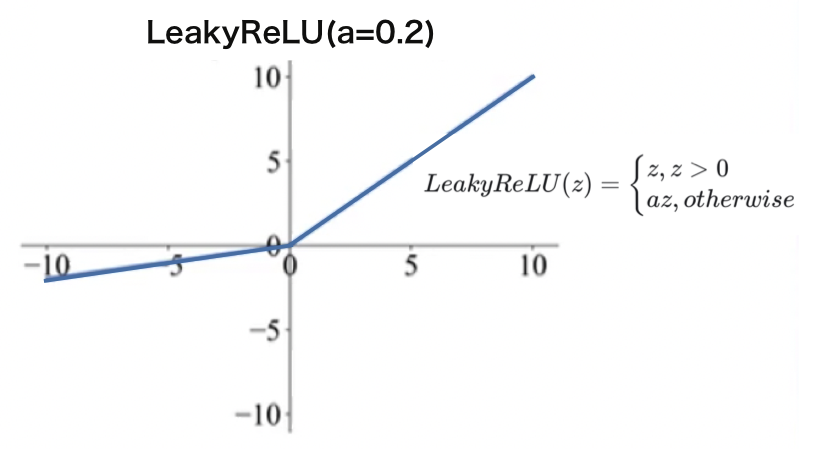
它把小于0的这些地方,也加了一个很小的梯度,这样的话大于0的时候partial就恒等于1,小于的时候partial也恒等于一个值,比如定一个a=0.2, 都可以。那这样就可以实现处处有导数。
但是其实用的也不太多,因为我们事实上发现在这种卷积神经网络里边,我们每一次把部分的权重设置成0不更新,反而可以提升它的训练效率,我们反而可以每次把训练focus on在几个参数上。
好,下节课,咱们来看看初始化的内容。



![[Linux]进程创建➕进程终止](https://img-blog.csdnimg.cn/b96918294d0b4237b8ec37402859baef.png)