文章目录
- 1.再谈fork()函数
- 1.1fork()创建子进程 OS都做了哪些工作?
- 1.2对上述问题的理解
- 1.3写时拷贝进行父子进程分离的优势
- 1.4了解eip寄存器和pc
- 1.5了解进程的上下文数据
- 1.6对计算机组成的理解
- 1.7fork常规用法
- 1.8fork调用失败的原因
- 2.进程终止
- 2.1进程终止时操作系统要做的工作
- 2.2进程终止的常见方式
- 1.main函数的返回值
- 2.查看错误码对应的错误信息
- 2.3如何用代码终止一个进程
1.再谈fork()函数
fork()函数
1.1fork()创建子进程 OS都做了哪些工作?
- 进程 = 内核数据结构 + 进程代码和数据 内核数据结构包括task_struct(进程控制块)和mm_struct(进程地址空间)和页表和映射关系 进程代码和数据是进程加载到内存时形成的
- 所以他做的工作有 以父进程task_struct为模板创建子进程的task_struct(对于PID进程状态优先级等自己重写)
- 创建进程地址空间 创建页表 创建映射关系 将代码和数据加载到内存
- 这里要注意 代码是共享父进程的 数据是写时拷贝
1.2对上述问题的理解
- fork()函数创建子进程 进程 = 内核数据结构 + 进程代码和数据 内核数据结构包括task_struct(进程控制块)和mm_struct(进程地址空间)和页表和映射关系 进程代码和数据是进程加载到内存时形成的
- 由于进程的独立性 子进程也要有自己的内核数据结构和进程代码和数据
内核数据结构: 前面我们已经讲到子进程的task_struct是按照父进程的task_struct为模板创建的 大部分相同 少部分如PID自己创建
代码: 实际上代码都是只读的 不可写/修改 所以代码是父子共享的
数据: 像申请的堆空间 局部变量 等可能被修改 需要各自独有
现在来考虑数据的问题 创建子进程时并不是一开始就把父进程的数据拿来拷贝一份 原因:
- 子进程被创建不一定立即运行 立即运行也不一定立马访问数据空间 即便访问也不一定会修改/写入
- 所以不需要对不会被访问的/不会写入的数据进行拷贝 但是OS无法提前知道哪些空间不会被访问/或者被写 所以他不知道什么空间要拷贝 什么空间不要拷贝 对于要拷贝的空间(会写入/修改的空间) 即便你提前拷贝了 也不是立即写入/修改
- 综上 OS选择写时拷贝 即子进程要对某一空间修改/写入 才把父进程的对应空间拷贝(之前提到过)
1.3写时拷贝进行父子进程分离的优势
- 需要写入/修改 再分配空间拷贝内容 高效使用内存
- OS无法提前知道哪些空间不会写入/修改 哪些空间会提前写入/修改 即便知道了 对会写入/修改的空间提前拷贝了 子进程也不一定立即就写入/修改
- 抛开写时拷贝 对于C语言常量字符串 如
const char* str0 = "hello";const char* str1 = "hello";这里str0和str1实际上执行同一块空间 因为那个字符串压根不会被修改只会读 也就完全没必要搞两份 话说到这了 编译器都知道在为代码分配虚拟地址时节省空间 对于直接在物理内存上的操作更要空间节省内存空间 在C++专栏string类模拟实现也讲到了写时拷贝 - 父子进程的数据需要分离以保证进程独立性 写时拷贝使得这个操作更为优雅的完成(延时申请空间 提高整机效率)
上述提到 fork()函数之后 父子进程代码共享 是fork()之后共享 还是所有共享 答案是所有共享 那么子进程为什么不从main()函数开头执行而是从fork()函数之后执行
- 代码汇编后 代码行数大大增多 每一行代码有自己编译器分配的内部虚拟地址(对于函数调用 A函数结束要调用B函数 那么A函数内部还要记录B函数的虚拟地址) 也有加载到内存时的外部物理地址
- 进程未结束前随时会被中断 如阻塞/挂起 当满足某种条件再次得到调度时 并不是再从第一行代码开始 而是从上一次结束开始 进程执行的位置是CPU负责记录的 CPU内有对应的寄存器 记录当前进程得到执行位置 寄存器在CPU内 只有一份 寄存器内的数据可以有多份
- 寄存器内的数据等 这些进程的上下文数据在子进程创建时 也要给子进程 子进程认为自己的eip初始值是fork()之后的代码
- 所以子进程可以看到所有的代码 但是它是从fork()之后执行的
1.4了解eip寄存器和pc
EIP和PC都是指令指针寄存器,用于存储下一条要执行的指令的地址。它们的区别在于它们所处的体系结构和操作系统环境不同。
PC指针是指程序计数器(Program Counter),也称为指令指针(Instruction Pointer),是一种寄存器,用于存储计算机正在执行的指令的地址。在CPU执行程序时,PC指针会不断地更新,以指向下一条要执行的指令的地址。在程序执行过程中,PC指针的值决定了程序的执行顺序。
EIP是指扩展指令指针(Extended Instruction Pointer),是x86架构中的一个寄存器,用于存储下一条要执行的指令的地址。与PC指针不同的是,EIP寄存器是在保护模式下使用的,而PC指针则是在实模式下使用的。此外,EIP寄存器还可以存储一些特殊的指令,如中断指令和异常指令的返回地址等。
在x86体系结构中,EIP是指扩展指令指针(Extended Instruction Pointer),而PC是指程序计数器(Program Counter)。在Linux 0.11的代码中,EIP和PC都被用来存储下一条要执行的指令的地址,但是它们的值是由不同的寄存器来维护的。在Linux 0.11中,EIP是由CPU自动维护的,而PC是由操作系统维护的。
1.5了解进程的上下文数据
进程上下文实际上是进程执行活动全过程的静态描述。具体的说,进程上下文包括计算机系统中与执行该进程有关的各种寄存器(例如通用寄存器,程序计数器PC,程序状态字寄存器PS等)的值,程序段在经过编译过后形成的机器指令代码集,数据集及各种堆栈值PCB结构。这里,有关寄存器和栈区的内容是重要的,例如没有程序计数器PC和程序状态寄存器PS,CPU将无法知道下一条待执行指令的地址和控制有关操作。
进程上下文是可以按照层次规则组合起来的。例如在UNIX System V中,进程上下文由用户级上下文,寄存器上下文以及系统级上下文组成。用户级上下文由进程的用户程序段部分编译而成的用户正文段,用户数据,用户栈组成。
1.6对计算机组成的理解
硬件只是一个机械设备 没有软件的交互 它就跟个铁疙瘩一样 但是并不是说他不重要 他是一系列指令的最终执行者 内存随时可以被读写 有页表的存在使得它不那么随意 硬件傻傻呼呼 有软件的配合使得它能做各种各样的工作 CPU傻傻呼呼(只会获取指令分析指令执行指令[CPU需要认识各种指令集]) 有寄存器的存在 使得CPU知道从哪获取怎么分析从哪执行
1.7fork常规用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子
进程来处理请求。
一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
1.8fork调用失败的原因
系统中有太多的进程
实际用户的进程数超过了限制
2.进程终止
2.1进程终止时操作系统要做的工作
- 释放进程申请的相关内核数据结构
- 释放进程对应的代码和数据
- 本质是释放系统资源
2.2进程终止的常见方式
a. 代码跑完,结果正确
b.代码跑完,结果不正确
c.代码没有跑完,程序崩溃时 退出码无意义 退出码对应的return语句没有被执行 比如对空指针赋值会直接崩溃而没有执行return语句 此时不再关注退出码 而是关注程序崩溃的原因
1.main函数的返回值
- 返回0: 运行结果正确
- 返回非0: 运行结果错误
- 返回给上一级进程 用来评判该进程执行结果是否正确 (返回给系统/父进程)
echo $?: 获取最近一个进程执行完毕的退出码(main()函数的返回值–进程退出码)- 非0值有无数个 不同的非零值标识不同的错误原因 当程序运行结束 结果不正确 根据退出码定位错误原因
有什么意义?
int main()
{
int ret = 0;
int sum = ADD(100);
if(sum != expected)
{
ret = 1;
}
return ret;
}
通过main()函数的返回值和查看进程的退出码 可以判断代码运行结果是否正确
2.查看错误码对应的错误信息

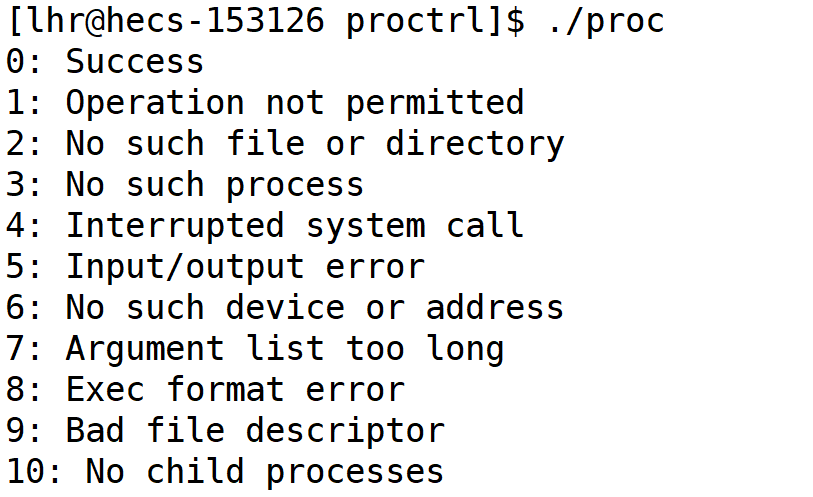

ls进程的退出码和main的一样

kill进程的退出码和main的不一样

即可以使用这些退出码和含义 也可以自己设计一套退出方案
2.3如何用代码终止一个进程
- main()函数 return语句
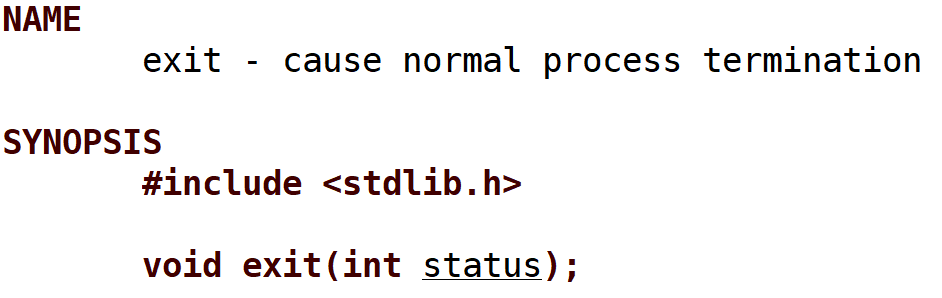
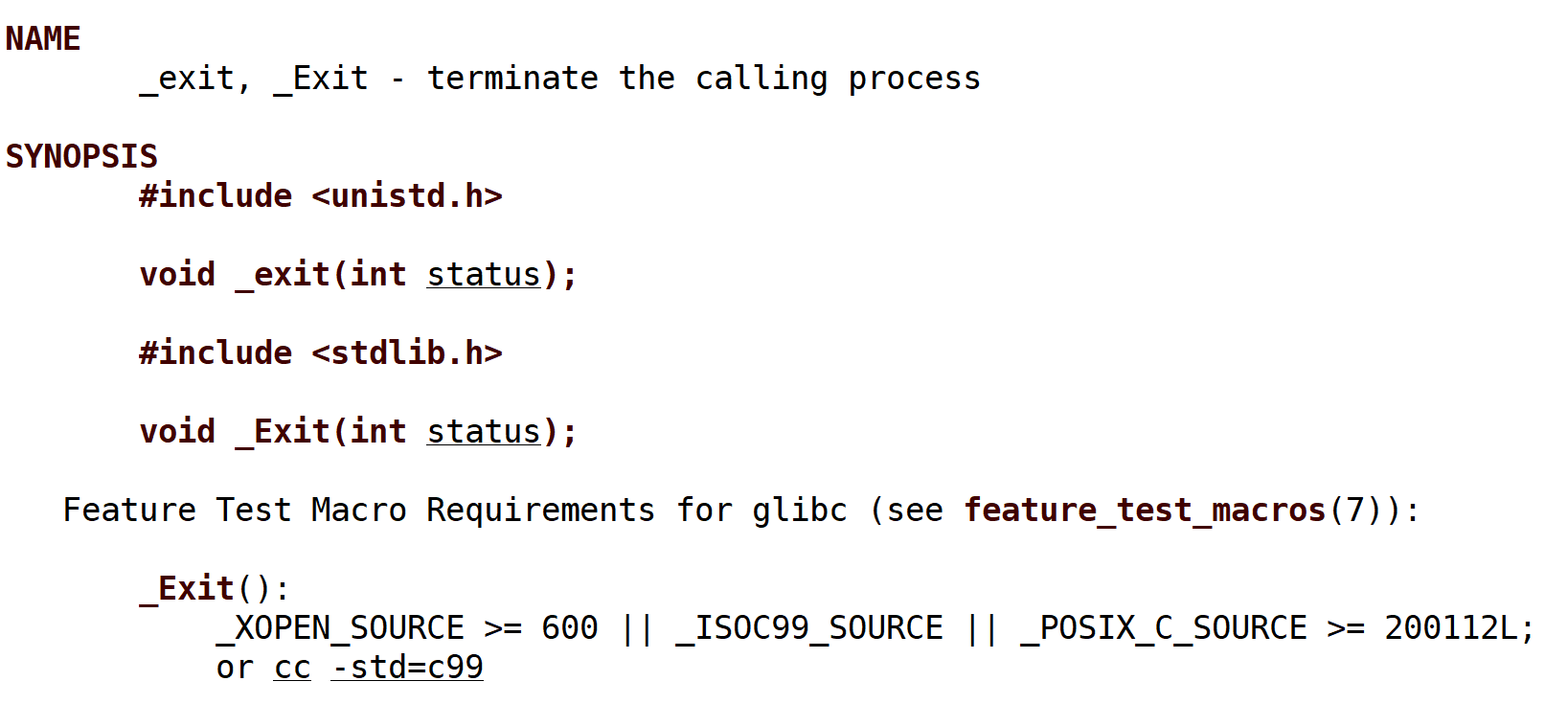
return 退出码其他函数内部的return是结束了这个函数 exit()/_exit()在代码任何地方调用都直接终止进程
- exit()是个C语言库函数 _exit()是个系统调用接口
- exit()使得程序结束时进程终止前会执行用户定义的清理函数 会冲刷缓冲区/关闭流 但是 _exit()直接终止进程
- OS为了让外来者易于操作/访问 设计了一系列调用接口 由于这些接口含不够简便 大佬有对这些接口进行封装形成库函数 实际上exit()底层调用的就是_exit()
-
printf("hello"\n)数据保存在缓冲区 这个缓冲区一定不在OS内部 如果是OS维护的 那么_exit()终止进程时也可以刷新缓冲区 这个缓冲区是C标准库维护的