简介与解读基本概念
学习率对于模型训练效果来说相当重要。
学习率过低会导致学习速度太慢,学习率过高又容易导致难以收敛。
因此,很多炼丹师都会采用动态调整学习率的方法。刚开始训练时,学习率大一点,以加快学习速度;之后逐渐减小来寻找最优解。
那么在Pytorch中,如何在训练过程里动态调整学习率呢?本文将带你深入理解优化器和学习率调整策略。
一、优化器
1. Optimizer机制
在介绍学习率调整方法之前,先带你了解一下Pytorch中的优化器Optimizer机制,模型训练时的固定搭配如下:
loss.backward()
optimizer.step()
optimizer.zero_grad()
简单来说,loss.backward()就是反向计算出各参数的梯度,然后optimizer.step()更新网络中的参数,optimizer.zero_grad()将这一轮的梯度清零,防止其影响下一轮的更新。
常用优化器都在torch.optim包中,因此需要先导入包:
import torch.optim.Adamimport torch.optim.SGD
这里以Adam和SGD优化器为例,介绍一下Pytorch中的优化器使用方法。假设我们有一个网络,下面的例子都以此网络展开:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer1 = nn.Linear(10, 2)
self.layer2 = nn.Linear(2, 10)
def forward(self, input):
return self.layer1(input)
2. Optimizer基本属性
所有Optimizer公有的一些基本属性:
- lr: learning rate,学习率
- eps: 学习率最小值,在动态更新学习率时,学习率最小不会小于该值。
- weight_decay: 权值衰减。相当于对参数进行L2正则化(使模型复杂度尽可能低,防止过拟合),该值可以理解为正则化项的系数。
- betas: (待研究)
- amsgrad: (bool)(待研究)
每个Optimizer都维护一个param_groups的list,该list中维护需要优化的参数以及对应的属性设置。
3. Optimizer基本方法
- **add_param_group(param_group):**为optimizer的param_groups增加一个参数组。这在微调预训练的网络时非常有用,因为冻结层可以训练并随着训练的进行添加到优化器中。
- **load_state_dict(state_dict):**加载optimizer state。参数必须是optimizer.state_dict()返回的对象。
- **state_dict():**返回一个dict,包含optimizer的状态:state和param_groups。
- step(closure): 执行一次参数更新过程。
- zero_grad(): 清除所有已经更新的参数的梯度。
我们在构造优化器时,最简单的方法通常如下:
model = Net()
optimizer_Adam = torch.optim.Adam(model.parameters(), lr=0.1)
**model.parameters()**返回模型的全部参数,并将它们传入Adam函数构造出一个Adam优化器,并设置 learning rate=0.1。
因此该 Adam 优化器的 param_groups 维护的就是模型 model 的全部参数,并且学习率为0.1,这样在调用optimizer_Adam.step()时,就会对model的全部参数进行更新。
4. param_groups
Optimizer的param_groups是一个list,其中的每个元素都是一组独立的参数,以dict的方式存储。结构如下:
-param_groups
-0(dict) # 第一组参数
params: # 维护要更新的参数
lr: # 该组参数的学习率
betas:
eps: # 该组参数的学习率最小值
weight_decay: # 该组参数的权重衰减系数
amsgrad:
-1(dict) # 第二组参数
-2(dict) # 第三组参数
...
这样可以实现很多灵活的操作,比如:
1)只训练模型的一部分参数
例如,只想训练上面的model中的layer1参数,而保持layer2的参数不动。可以如下设置Optimizer:
model = Net()
# 只传入layer层的参数,就可以只更新layer层的参数而不影响其他参数。
optimizer_Adam = torch.optim.Adam(model.layer1.parameters(), lr=0.1)
2)不同部分的参数设置不同的学习率
例如,要想使model的layer1参数学习率为0.1,layer2的参数学习率为0.2,可以如下设置Optimizer:
model = Net()
params_dict = [{'params': model.layer.parameters(), 'lr': 0.1},
{'params': model.layer2.parameters(), 'lr': 0.2}]
optimizer_Adam = torch.optim.Adam(params_dict)
这种方法更为灵活,手动构造一个params_dict列表来初始化Optimizer。注意,字典中的参数部分的 key 必须为**‘params’**。
二、动态更新学习率
了解了Optimizer的基本结构和使用方法,接下来将向你介绍如何在训练过程中动态更新 learning rate。
1. 手动修改学习率
前文提到Optimizer的每一组参数维护一个lr,因此最直接的方法就是在训练过程中手动修改Optimizer中对应的lr值。
model = Net() # 生成网络
optimizer_Adam = torch.optim.Adam(model.parameters(), lr=0.1) # 生成优化器
for epoch in range(100): # 假设迭代100个epoch
if epoch % 5 == 0: # 每迭代5次,更新一次学习率
for params in optimizer_Adam.param_groups:
# 遍历Optimizer中的每一组参数,将该组参数的学习率 * 0.9
params['lr'] *= 0.9
# params['weight_decay'] = 0.5 # 当然也可以修改其他属性
2. torch.optim.lr_scheduler
torch.optim.lr_scheduler包中提供了一些类,用于动态修改lr。
- torch.optim.lr_scheduler.LambdaLr
- torch.optim.lr_scheduler.StepLR
- torch.optim.lr_scheduler.MultiStepLR
- torch.optim.lr_scheduler.ExponentialLR
- torch.optim.lr_sheduler.CosineAnneaingLR
- torch.optim.lr_scheduler.ReduceLROnPlateau
pytorch 1.1.0版本之后,在创建了lr_scheduler对象之后,会自动执行第一次lr更新(可以理解为执行一次scheduler.step())。
因此在使用的时候,需要先调用optimizer.step(),再调用scheduler.step()。
如果创建了lr_scheduler对象之后,先调用scheduler.step(),再调用optimizer.step(),则会跳过了第一个学习率的值。
# 调用顺序
loss.backward()
optimizer.step()
scheduler.step()...
具体使用方法由于篇幅有限不在此阐述了,感兴趣的伙伴可以去torch官网查看文档。
三、小结
学习率对于深度学习炼丹来说尤为重要,一个合适的学习率不仅能加速训练的拟合,还能更好地逼近最优解。
固定的学习率随着深度学习模型逐渐上升的复杂性已不太适用,动态调整学习率或者对模型不同部分设置不同的学习率已成为一种炼丹趋势。
深入解读与各种动态学习率
0 为什么引入学习率衰减?
我们都知道几乎所有的神经网络采取的是梯度下降法来对模型进行最优化,其中标准的权重更新公式:
W
+
=
α
∗
g
r
a
d
i
e
n
t
W
+
=
α
∗
gradient
W
+
=
α
∗
g
r
a
d
i
e
n
t
W + = α ∗ gradient W+=\alpha * \text { gradient } W+=α∗ gradient
W+=α∗gradientW+=α∗ gradient W+=α∗gradient
- 学习率 α \alpha α 控制着梯度更新的步长(step), α \alpha α 越大,意味着下降的越快,到达最优点的速度也越快,如果为 0 0 0,则网络就会停止更新
- 学习率过大,在算法优化的前期会加速学习,使得模型更容易接近局部或全局最优解。但是在后期会有较大波动,甚至出现损失函数的值围绕最小值徘徊,波动很大,始终难以达到最优。
所以引入学习率衰减的概念,直白点说,就是在模型训练初期,会使用较大的学习率进行模型优化,随着迭代次数增加,学习率会逐渐进行减小,保证模型在训练后期不会有太大的波动,从而更加接近最优解。
1 查看学习率
print("Lr:{}".format(optimizer.state_dict()['param_groups'][0]['lr']))
之后我会用类似于如下的代码进行学习率的测试输出
def train():
traindataset = TrainDataset()
traindataloader = DataLoader(dataset = traindataset,batch_size=100,shuffle=False)
net = Net().cuda()
myloss = nn.MSELoss().cuda()
optimizer = optim.SGD(net.parameters(), lr=0.001 )
for epoch in range(100):
print("Epoch:{} Lr:{:.2E}".format(epoch,optimizer.state_dict()['param_groups'][0]['lr']))
for data,label in traindataloader :
data = data.cuda()
label = label.cuda()
output = testnet(data)
loss = myloss(output,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
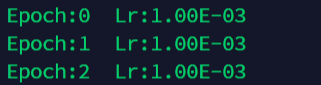
2 最常用的针对全局的学习率设置
需要根据你选择的优化器的种类把具体你想要的lr作为可选参数的一部分传入到新建的优化器类初始化中

optimizer = optim.SGD(net.parameters(), lr=0.001 )
3 针对不同层设置不一样的学习率
当我们在使用预训练的模型时,需要对分类层进行单独修改并进行初始化,其他层的参数采用预训练的模型参数进行初始化,这个时候我们希望在进行训练过程中,除分类层以外的层只进行微调,不需要过多改变参数,因此需要设置较小的学习率。而改正后的分类层则需要以较大的步子去收敛,学习率往往要设置大一点
以一个简单的网络为例
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net1 = nn.Linear(2,10)
self.net2 = nn.Linear(10,1)
def forward(self, x):
x = self.net1(x)
x = self.net2(x)
return x
net = Net()
optimizer = optim.SGD([
{"params":model.net1.parameters()},
{"params":model.net2.parameters(),"lr":1e-5},],
lr=1e-2, #默认参数
)
for epoch in range(100):
print("Epoch:{} Lr:{:.2E}".format(epoch,optimizer.state_dict()['param_groups'][0]['lr']))
print("Epoch:{} Lr:{:.2E}".format(epoch,optimizer.state_dict()['param_groups'][1]['lr']))
optimizer.step()

以resnet101为例,分层设置学习率。
model = torchvision.models.resnet101(pretrained=True)
large_lr_layers = list(map(id,model.fc.parameters()))
small_lr_layers = filter(lambda p:id(p) not in large_lr_layers,model.parameters())
optimizer = torch.optim.SGD([
{"params":large_lr_layers},
{"params":small_lr_layers,"lr":1e-4}
],lr = 1e-2,momenum=0.9)
注:large_lr_layers学习率为 1e-2,small_lr_layers学习率为 1e-4,两部分参数共用一个momenum
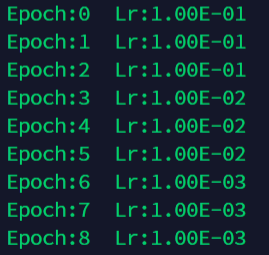
4 手动设置自动衰减的学习率
def adjust_learning_rate(optimizer, epoch, start_lr):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = start_lr * (0.1 ** (epoch // 3))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
注释:在调用此函数时需要输入所用已经初始化完毕的optimizer以及对应的epoch,并且start_lr作为初始化的学习率也需要给出。
optimizer = torch.optim.SGD(net.parameters(),lr = start_lr)
for epoch in range(100):
adjust_learning_rate(optimizer,epoch,start_lr)
print("Epoch:{} Lr:{:.2E}".format(epoch,optimizer.state_dict()['param_groups'][0]['lr']))
for data,label in traindataloader :
data = data.cuda()
label = label.cuda()
output = net(data)
loss = myloss(output,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
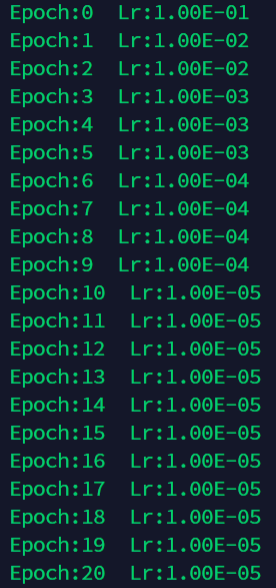
5 手动根据自定义列表进行学习率指定
def adjust_learning_rate_list(optimizer, epoch):
lr_set_list = [[1,1e-1],[2,1e-2],[3,1e-3],[4,1e-4],[5,1e-5]]# 执行此学习率的epoch数
lr_list = []
for i in lr_set_list:
for j in range(i[0]):
lr_list.append(i[1])
for param_group in optimizer.param_groups:
if epoch < len(lr_list)-1:
param_group['lr'] = lr_list[epoch]
else:
param_group['lr'] = lr_list[-1]
6 使用pytorch提供的学习率
在torch.optim.lr_scheduler内部,基于当前epoch的数值,封装了几种相应的动态学习率调整方法,该部分的官方手册传送门——optim.lr_scheduler官方文档。需要注意的是学习率的调整需要应用在优化器参数更新之后,也就是说:
optimizer = torch.optim.XXXXXXX()#具体optimizer的初始化
scheduler = torch.optim.lr_scheduler.XXXXXXXXXX()#具体学习率变更策略的初始化
for i in range(epoch):
for data,label in dataloader:
out = net(data)
output_loss = loss(out,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
其具体的学习率策略应用的简要代码示例如下:
6.1 lr_scheduler.LambdaLR
更新策略:
将每一个参数组的学习率调整为初始化学习率lr的给定函数倍(lr_lambda),在fine-tune中十分有用,我们不仅可以为不同的层设定不同的学习率,还可以为其设定不同的学习率调整策略。
初始化方法:
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
几个最常用的函数:
# 旷世shuffleNet系列中使用的学习率变化策略
lr_lambda = lambda step : (1.0-step/args.total_iters) if step <= args.total_iters else 0
# CCNet官方源码中改变学习率的方法。这个学习率衰减策略是最常用的,被称作多项式衰减法。
def lr_poly(base_lr, iter, max_iter, power):
return base_lr*((1-float(iter)/max_iter)**(power))
def adjust_learning_rate(optimizer, learning_rate, i_iter, max_iter, power):
"""Sets the learning rate to the initial LR divided by 5 at 60th, 120th and 160th epochs"""
lr = lr_poly(learning_rate, i_iter, max_iter, power)
optimizer.param_groups[0]['lr'] = lr
return lr
参数
optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名lr_lambda(function or list):可以是function或是function list,给定整数参数epoch计算乘数的函数,或者是list形式的函数,分别计算各个parameter groups的学习率更新用到的学习率。一般是一个关于epoch数目的函数,从而计算出一个乘数因子,并根据该乘数因子调整初始学习率。last_epoch(int):默认为-1,它一般不用设置,为-1时的作用是将人为设置的学习率设定为调整学习率的基础值lr。这里需要注意的是,last_epoch默认为-1只能保证第一次调整学习率时,原始待调整的值为人工设定的初始学习率,而第二次调整学习率时,调整的基值就变成了第一次调整后的学习率。如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始verbose(bool):True的话为每次更新打印一个stdout,默认为False
注意:
在将optimizer传给scheduler后,在shcduler类的__init__方法中会给optimizer.param_groups列表中的那个元素(字典)增加一个key = "initial_lr"的元素表示初始学习率,等于optimizer.defaults['lr']。
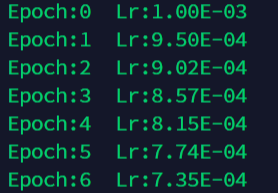
举例:
lambda1 = lambda epoch: 0.95 ** epoch # 第二组参数的调整方法
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) # 选定调整方法
6.2 torch.optim.lr_scheduler.StepLR
更新策略:
这是比较常用的等间隔动态调整方法,每经过step_size个epoch,做一次学习率decay,以gamma值为缩小倍数。
初始化方法:
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
参数:
optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名step_size(int):是学习率衰减的周期,每经过step_size 个epoch,做一次学习率decaygamma(float):学习率衰减的乘法因子。Default:0.1last_epoch(int):默认为-1,它一般不用设置,为-1时的作用是将人为设置的学习率设定为调整学习率的基础值lr。这里需要注意的是,last_epoch默认为-1只能保证第一次调整学习率时,原始待调整的值为人工设定的初始学习率,而第二次调整学习率时,调整的基值就变成了第一次调整后的学习率。如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始verbose(bool):如果为True,每一次更新都会打印一个标准的输出信息 ,Default:False
注意:
此函数产生的decay效果,可能与函数外部的对于学习率的更改同时发生,当last_epoch = -1时,将初始lr设置为Ir。
举例:
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
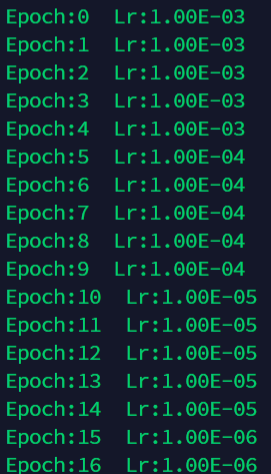
6.3 lr_scheduler.MultiStepLR
更新策略:
一旦达到某一阶段(milestones)时,就可以通过gamma系数降低每个参数组的学习率。
可以按照milestones列表中给定的学习率,进行分阶段式调整学习率。
初始化方法:
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
参数:
optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名milestones(list):是一个关于epoch数值的list,表示在达到哪个epoch范围内开始变化,必须是升序排列gamma(float):学习率衰减的乘法因子。Default:0.1last_epoch(int):默认为-1,它一般不用设置,为-1时的作用是将人为设置的学习率设定为调整学习率的基础值lr。这里需要注意的是,last_epoch默认为-1只能保证第一次调整学习率时,原始待调整的值为人工设定的初始学习率,而第二次调整学习率时,调整的基值就变成了第一次调整后的学习率。如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始verbose(bool):如果为True,每一次更新都会打印一个标准的输出信息 ,Default:False
注意:
此函数产生的decay效果,可能与函数外部的对于学习率的更改同时发生,当last_epoch = -1时,将初始lr设置为lr。
举例:
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[2,6,15], gamma=0.1)
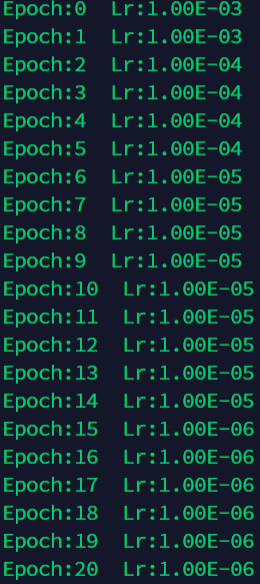
6.4 lr_scheduler.ExponentialLR
更新策略:
每一次epoch,lr都乘gamma
初始化方法:
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
参数:
optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名gamma(float):学习率衰减的乘法因子。Default:0.1last_epoch(int):默认为-1,它一般不用设置,为-1时的作用是将人为设置的学习率设定为调整学习率的基础值lr。这里需要注意的是,last_epoch默认为-1只能保证第一次调整学习率时,原始待调整的值为人工设定的初始学习率,而第二次调整学习率时,调整的基值就变成了第一次调整后的学习率。如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始verbose(bool):如果为True,每一次更新都会打印一个标准的输出信息 ,Default:False
举例:
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.1)
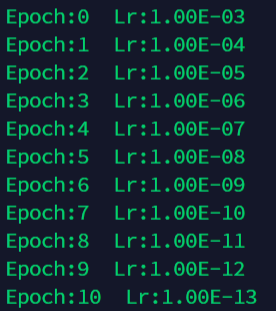
6.5 lr_scheduler.CosineAnnealingLR
更新策略:
按照余弦波形的衰减周期来更新学习率,前半个周期从最大值降到最小值,后半个周期从最小值升到最大值
初始化方法:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
参数:
optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名T_max (int): 余弦波形周期的一半,比如T_max=10,则学习率衰减周期为20,其中前半段即前10个周期学习率从最大值降到最小值,后10个周期从最小值升到最大值eta_min(float):学习率衰减的最小值,Default:0last_epoch(int):默认为-1,它一般不用设置,为-1时的作用是将人为设置的学习率设定为调整学习率的基础值lr。这里需要注意的是,last_epoch默认为-1只能保证第一次调整学习率时,原始待调整的值为人工设定的初始学习率,而第二次调整学习率时,调整的基值就变成了第一次调整后的学习率。如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始verbose(bool):如果为True,每一次更新都会打印一个标准的输出信息 ,Default:False
举例:
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max = 10)
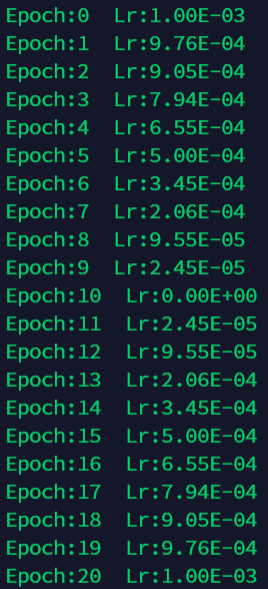
6.6 lr_scheduler.ReduceLROnPlateau
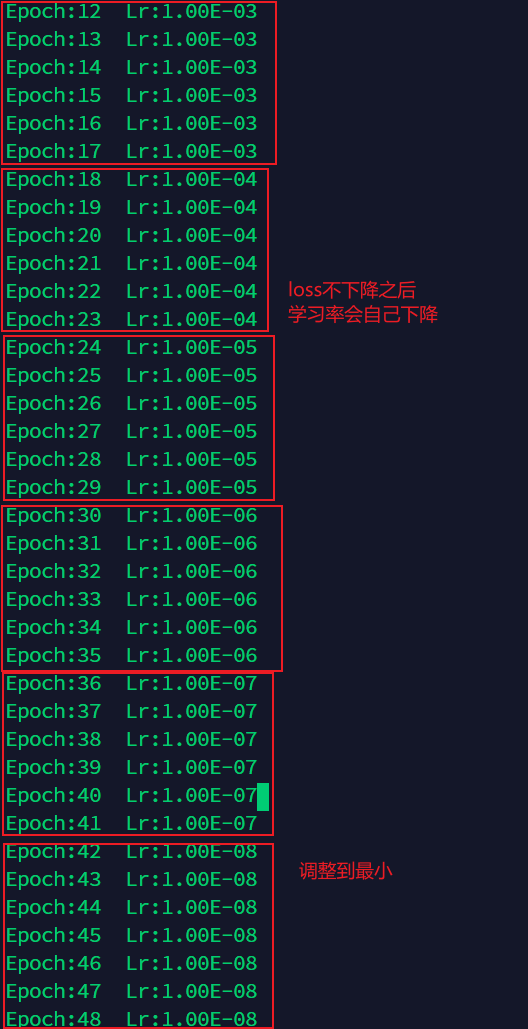
更新策略:
与上述基于epoch数目调整学习率的方法不同,该方法是PyTorch提供的一种基于验证指标的调整方法。它的原理是:当指标停止改善时,降低学习率。当模型的学习停滞时,训练过程通常会受益于将学习率降低2~10倍。该种调整方法读取一个度量指标,如果在“耐心”期间内没有发现它有所改善,那么就会降低学习率。
初始化方法:
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode= 'rel', cooldown=0, min_1r=0, eps=1e-08)
step()方法:
scheduler.step(loss)
参数:
optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名mode:可选str字符串数据,为min或max。当选择min时,代表当度量指标停止下降时,开始减小学习率;当选择max时,代表当度量指标停止上升时,开始减小学习率。factor:float类型数据,学习率调整的乘法因子,默认值为0.1。patience:int类型数据,可容忍的度量指标没有提升的epoch数目,默认为10。举例说明,当其设置为10时,我们可以容忍10个epoch内没有提升,如果在第11个epoch依然没有提升,那么就开始降低学习率。verbose:bool数据,如果设置为True,输出每一次更新的信息,默认为False。threshold:float类型数据,衡量新的最佳阈值,仅关注重大变化,默认为0.0001。threshold_mode:可选str字符串数据,为rel或abs,默认为rel。在rel模式下,如果mode参数为max,则动态阈值(dynamic_threshold)为best*(1+threshold),如果mode参数为min,则动态阈值为best+threshold,如果mode参数为min,则动态阈值为best-threshold。cooldown:int类型数据,减少lr后恢复正常操作之前要等待的epoch数,默认为0。min_lr:float或list类型数据,学习率的下界,默认为0。eps:float类型数据,学习率的最小变化值。如果调整后的学习率和调整前的差距小于eps的话,那么就不做任何调整,默认为1e-8。
举例:
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min',patience=5)
scheduler.step(loss)