文章目录
- 什么是 B-tree 和 B+tree ?
- B-Tree 和 B+Tree的区别?
- MySQL 联合唯一索引是B+Tree,会带来什么原则?
- 主键索引和单字段唯一索引有什么区别吗
- 什么是 聚簇索引和非聚簇索引 ?
- 创建一个三百万数据量的表格,方便测试索引
什么是 B-tree 和 B+tree ?
MySQL索引是一种用于加快数据库查询速度的数据结构。B-tree(B树)和B+tree(B+树)是两种常见的索引结构,用于组织和管理索引数据。
B+树(B+ tree)和B树(B-tree)是常用的数据结构,用于在数据库和文件系统中进行索引和存储数据。
B树和B+树都是平衡二叉树,它们都用于数据库索引。
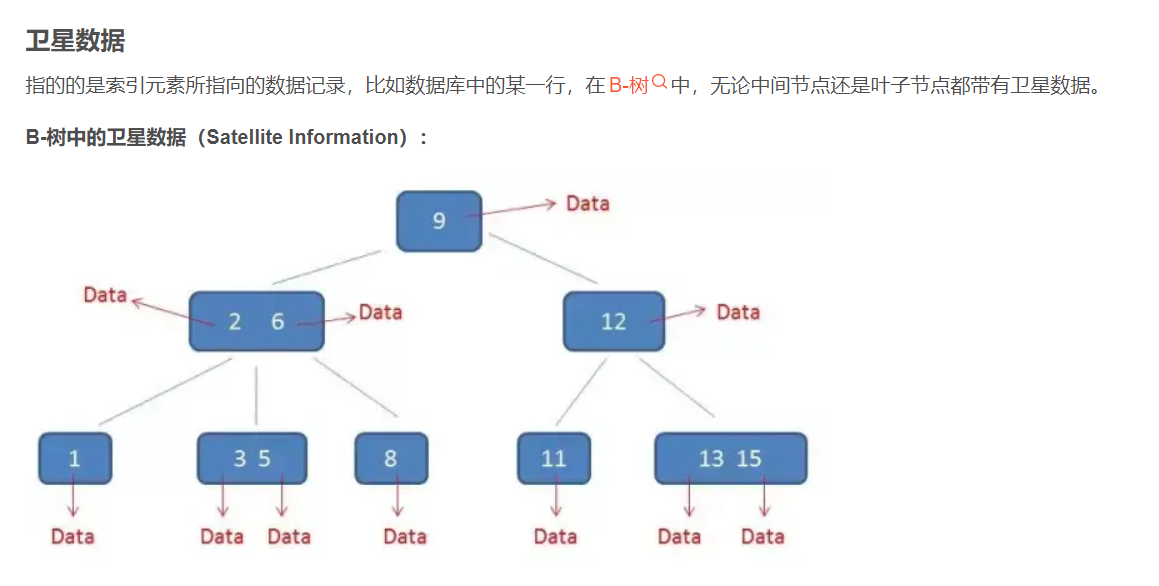
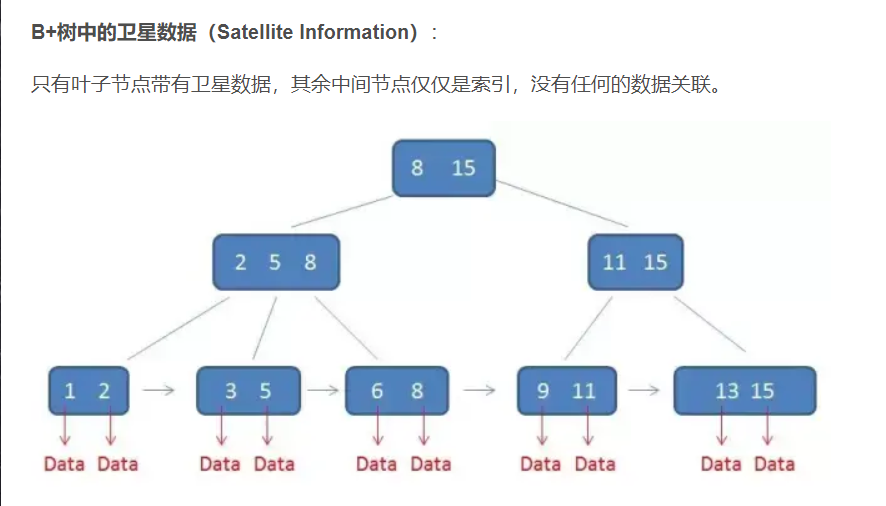
需要补充的是,在数据库的聚集索引(Clustered Index)中,叶子节点直接包含卫星数据。在非聚集索引(NonClustered Index)中,叶子节点带有指向卫星数据的指针。
总体而言,B+树比B树更适合用于数据库索引。MySQL的索引就是基于B+树的。
B-Tree 和 B+Tree的区别?
B 树& B+树两者有何异同呢?
- B 树的所有节点既存放键(key) 也存放数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+树的范围查询,只需要对链表进行遍历即可。
综上,B+树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
MySQL 联合唯一索引是B+Tree,会带来什么原则?
组合索引 和 B+Tree =》 最左匹配原则
MySQL的最左匹配原则是指在使用组合索引时,MySQL会优先使用索引中的最左边的列进行匹配,然后再逐渐向右匹配其他列。这个原则对于查询的索引选择和效率有重要影响,需要注意以下几点:
- 最左前缀匹配:MySQL只能使用索引中的最左前缀进行匹配。也就是说,如果一个查询只使用了组合索引中的一部分列,那么只有这部分列的索引会被使用,而后面的列不会被利用到。因此,在设计组合索引时,需要根据查询的常见模式和条件,将最常用的列放在索引的最左边。
- 索引顺序:
组合索引的列顺序非常重要。如果查询中的列不是按照索引的顺序进行匹配,那么MySQL将无法使用索引,而是进行全表扫描。因此,需要根据查询的条件和排序方式,将最常用的列放在索引的最左边。 - 范围查询:如果查询中包含范围查询(例如大于、小于、区间等),那么只有范围查询之前的列才能被索引使用。范围查询之后的列将无法使用索引,因此需要根据查询的范围条件,将最常用的列放在范围查询之前。
- 索引覆盖:如果查询只需要使用组合索引中的列,而不需要访问主索引或数据页,那么可以避免额外的IO操作,提高查询效率。因此,在设计组合索引时,可以考虑将常用的查询列放在索引的最左边,以实现索引覆盖。
需要注意的是,最左匹配原则只适用于组合索引,而不适用于单列索引。在实际使用中,需要根据具体的查询模式和数据特点,合理设计索引,以提高查询效率和性能。
主键索引和单字段唯一索引有什么区别吗
主键索引和单字段唯一索引在功能和使用上有一些区别,下面是它们的主要区别:
- 主键索引(Primary Key Index):
- 主键索引是用于
唯一标识表中每一行数据的索引,每个表只能有一个主键索引。 - 主键索引可以由
一个或多个列组成,但通常是由单个列组成。 - 主键索引的值
不能为NULL,且必须是唯一的。 - 主键索引在数据库中自动创建,可以加速数据的查找和连接操作。
- 主键索引通常是
聚簇索引,即数据按照主键的顺序存储在磁盘上。
- 主键索引是用于
- 单字段唯一索引(Unique Index):
- 单字段唯一索引是
用于确保表中某个列的值是唯一的索引。 - 单字段唯一索引
可以由一个或多个列组成,但通常是由单个列组成。 - 单字段唯一索引的
值可以为NULL,但是如果有多行数据的索引列的值为NULL,则不会违反唯一性约束。 - 单字段唯一索引在数据库中需要显式创建。
- 单字段唯一索引可以加速数据的查找和连接操作,同时确保索引列的值是唯一的。
- 单字段唯一索引是
什么是 聚簇索引和非聚簇索引 ?
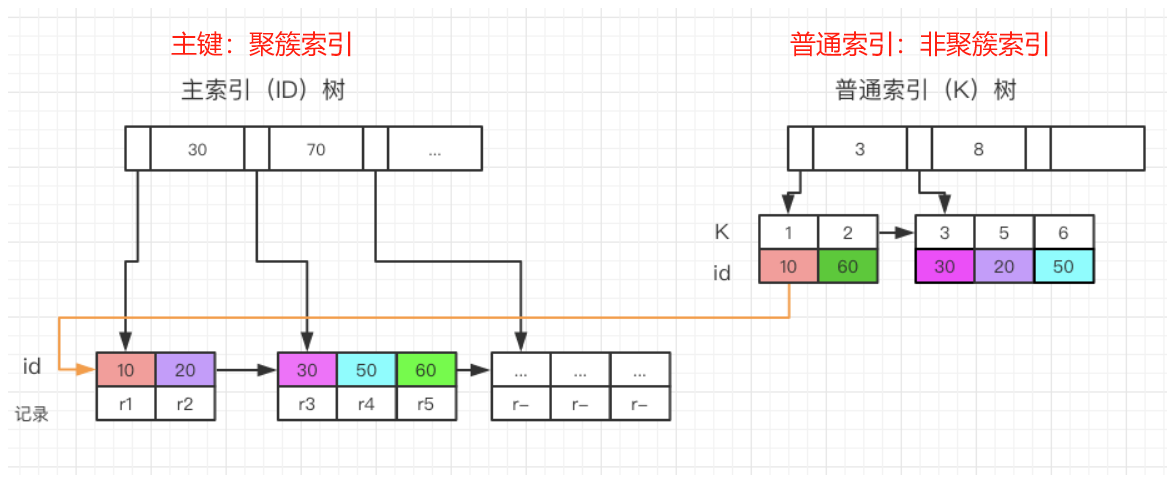
聚簇索引和非聚簇索引的主要区别在于它们的数据存储方式。
聚簇索引是将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。这意味着聚簇索引的叶子节点就是数据节点,每个叶子节点包含了行的全部信息。使用聚簇索引查询数据时,只需要查找索引就可以找到数据,因为数据和索引是在同一个物理结构中。
非聚簇索引则将数据与索引分开存储。索引结构的叶子节点指向了数据对应的位置。这意味着非聚簇索引的叶子节点不包含行的全部信息,而是包含了数据的位置信息。使用非聚簇索引查询数据时,需要先查找索引找到数据的位置,然后再通过位置信息找到实际的数据。
创建一个三百万数据量的表格,方便测试索引
假设,有一个订单表格,2023.11.25 这一天有300w数据量存储到表格,内容可以如下:
# 创建一个简单的订单表
drop table if exists `co_order`;
CREATE TABLE `co_order` (
`co_num` varchar(100) NOT NULL COMMENT '订单ID',
`status` char(2) NOT NULL DEFAULT '10' COMMENT '订单状态:10新建,15取消,20已支付,30已完成',
`crt_date` char(8) DEFAULT NULL COMMENT '创建日期',
`crt_user_id` varchar(50) DEFAULT NULL COMMENT '用户名ID',
`crt_user_name` varchar(50) DEFAULT NULL COMMENT '用户名',
`product_id` varchar(50) COMMENT '商品ID',
`product_name` varchar(50) COMMENT '商品名称',
`amt_sum` decimal(18,2) DEFAULT '0.00' COMMENT '金额',
PRIMARY KEY (`co_num`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 查看 函数是否打开,OFF代表关闭,ON代表已打开
show variables like '%func%';
# 如果是OFF,则输入:
set global log_bin_trust_function_creators=1;
# 删除已经存在的函数
drop function if exists add_order_num;
# 向co_order添加三百万条数据
DELIMITER ;;
CREATE FUNCTION add_order_num() RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTO co_order (`co_num`,`status`,`crt_date`,`crt_user_id`,`crt_user_name`,`product_id`,`product_name`,`amt_sum`) VALUES
(UUID(),'10','20231125',CONCAT('zhangsan',i),CONCAT('张三',i),CONCAT('zhangsanproduct',i),CONCAT('张三商品',i),FLOOR(RAND()*100)),
(UUID(),'20','20231125',CONCAT('lisi',i),CONCAT('李四',i),CONCAT('lisiproduct',i),CONCAT('李四商品',i),FLOOR(RAND()*100)),
(UUID(),'30','20231125',CONCAT('wangwu',i),CONCAT('王五',i), CONCAT('wangwuproduct',i),CONCAT('王五商品',i),FLOOR(RAND()*100));
SET i = i+1;
END WHILE;
RETURN i;
END;
DELIMITER ;
# 执行add_order_num函数
select add_order_num();
# 查看数据信息
select * from co_order;
# 查看数量
select count(*) from co_order;
💡Tips:这样就有了一个存储百万级别量的表格,方便复习测试索引相关的内容知识。
根据自己对比参考一下,加索引 以及 不加索引 效率提升,以及索引个别失效情况等等。