bop数据合并到COCO
- JSON转TXT
- 重命名
- txt文件中类别信息的转换
JSON转TXT
import json
import os,glob
categories = [
{
"id": 12,
"name": "OREO",
"supercategory": "icbin"
},
{
"id": 16,
"name": "Paper Cup",
"supercategory": "icbin"
},
{
"id": 4,
"name": "School Glue",
"supercategory": "icbin"
},
{
"id": 7,
"name": "Straw Cups",
"supercategory": "icbin"
},
{
"id": 9,
"name": "Highland",
"supercategory": "icbin"
},
{
"id": 10,
"name": "Soueakair",
"supercategory": "icbin"
},
{
"id": 2,
"name": "Cheez-it",
"supercategory": "icbin"
},
{
"id": 1,
"name": "Copper Plus",
"supercategory": "icbin"
},
{
"id": 8,
"name": "Stir Stick",
"supercategory": "icbin"
},
{
"id": 14,
"name": "Stanley",
"supercategory": "icbin"
},
{
"id": 3,
"name": "Crayola",
"supercategory": "icbin"
},
{
"id": 13,
"name": "Mirado",
"supercategory": "icbin"
},
{
"id": 11,
"name": "Munchkin",
"supercategory": "icbin"
},
{
"id": 6,
"name": "Greenies",
"supercategory": "icbin"
},
{
"id": 5,
"name": "White Board Cake",
"supercategory": "icbin"
},
{
"id": 15,
"name": "Main Arm",
"supercategory": "icbin"
}
]
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def to_yolo(data_path):
json_path=data_path+'/scene_gt_coco.json'
save_path = data_path+ '/labels/'
json_file = json_path # COCO Object Instance 类型的标注
ana_txt_save_path = save_path # 保存的路径
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
id_map = {} # coco数据集的id不连续!重新映射一下再输出!
print(data['categories'])
# # categories = sorted(data['categories'], key=lambda x: x['id'])
for i, category in enumerate(categories):
# id_map[category['id']] = int(category['id'])
id_map[category['id']] = i
# 通过事先建表来降低时间复杂度
max_id = 0
for img in data['images']:
max_id = max(max_id, img['id'])
# 注意这里不能写作 [[]]*(max_id+1),否则列表内的空列表共享地址
img_ann_dict = [[] for i in range(max_id+1)]
for i, ann in enumerate(data['annotations']):
img_ann_dict[ann['image_id']].append(i)
for img in data['images']:
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head.split('/')[-1] + ".txt" # 对应的txt名字,与jpg一致
f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')
'''for ann in data['annotations']:
if ann['image_id'] == img_id:
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))'''
# 这里可以直接查表而无需重复遍历
for ann_id in img_ann_dict[img_id]:
ann = data['annotations'][ann_id]
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))
f_txt.close()
print(f'==> coco to yolo images:{len(data["images"])}, save path: {save_path}')
def train_val_test(data_path):
sets = ['train','val','test']#生成txt的文件名称
image_ids = glob.glob(os.path.join(data_path, 'images', '*.jpg'))
train_ratio = 0.7 # 训练集比例
val_ratio = 0.2 # 验证集比例
test_ratio = 0.1 # 测试集比例
train_size = int(len(image_ids) * train_ratio)
val_size = int(len(image_ids) * val_ratio)
test_size = len(image_ids) - train_size - val_size
data = [image_ids[:train_size], image_ids[train_size:train_size + val_size], image_ids[train_size + val_size:]]
for i, image_set in enumerate(sets):
image_ids = data[i]
list_file = open(data_path+'/%s.txt' % (image_set), 'w')
for image_id in image_ids:
image_id = image_id.replace('/rgb','/images')
list_file.write(image_id + "\n")
# convert_annotation(image_id)
# 关闭文件
list_file.close()
print(f'==> train image: {train_size}')
print(f'==> valid image: {val_size}')
print(f'==> test image: {test_size}')
if __name__ == '__main__':
data_path = 'H:/Dataset/COCO/train_pbr/000002'
to_yolo(data_path)
train_val_test(data_path)
# print([cat['name'] for cat in categories])
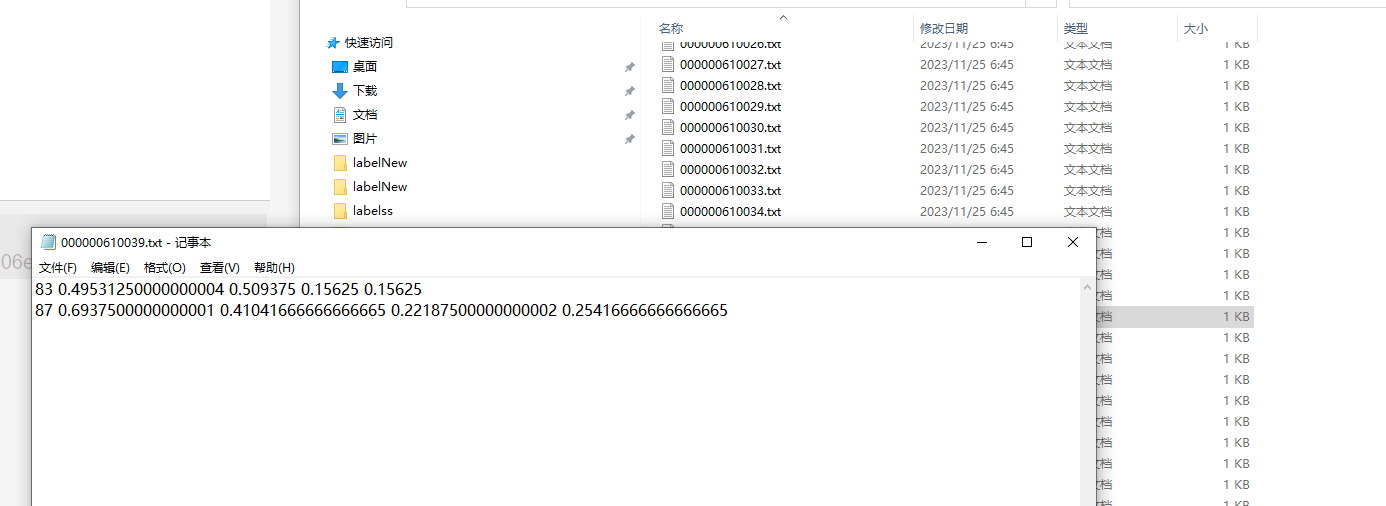
重命名
以00000061*开头
txt文件中类别信息的转换
加79(从0开始,80类的COCO)
import codecs
import os
path = 'H:/Dataset/COCO/train_pbr/000002/labelNew/' # 标签文件train路径
m = os.listdir(path)
# 读取路径下的txt文件
for n in range(0, len(m)):
t = codecs.open('H:/Dataset/COCO/train_pbr/000002/labelNew/' + m[n], mode='r', encoding='utf-8')
line = t.readline() # 以行的形式进行读取文件
list1 = []
while line:
a = line.split()
list1.append(a)
line = t.readline()
t.close()
lt = open('H:/Dataset/COCO/train_pbr/000002/labelNew/' + m[n], "w")
for num in range(0, len(list1)):
list1[num][0] = str(int(list1[num][0])+79) # 第一列为0时,将0改为1
lt.writelines(' '.join(list1[num]) + '\n') # 每个元素以空格间隔,一行元素写完并换行
lt.close()
print(m[n] + " 修改完成")