背景:
昨天我们讲了讲关于seleium的一些基础操作,今天讲讲如何将seleium和爬虫结合起来,可以使用selenium获取网页的动态加载数据,可以使用selenium获得cookie,这两个是比较常用的。我将一一展开。
实战案例:
获取XHR动态加载数据:
思考:在爬虫中为什么需要使用selenium?selenium和爬虫之间的关联是什么?
- 便捷的爬取动态加载数据(可见即可得)
我发现大家对动态加载数据和请求包中的数据没有一个特别清晰的认识。
selenium获得网页数据是经过多个数据包发送请求共同渲染后的数据,上图片:
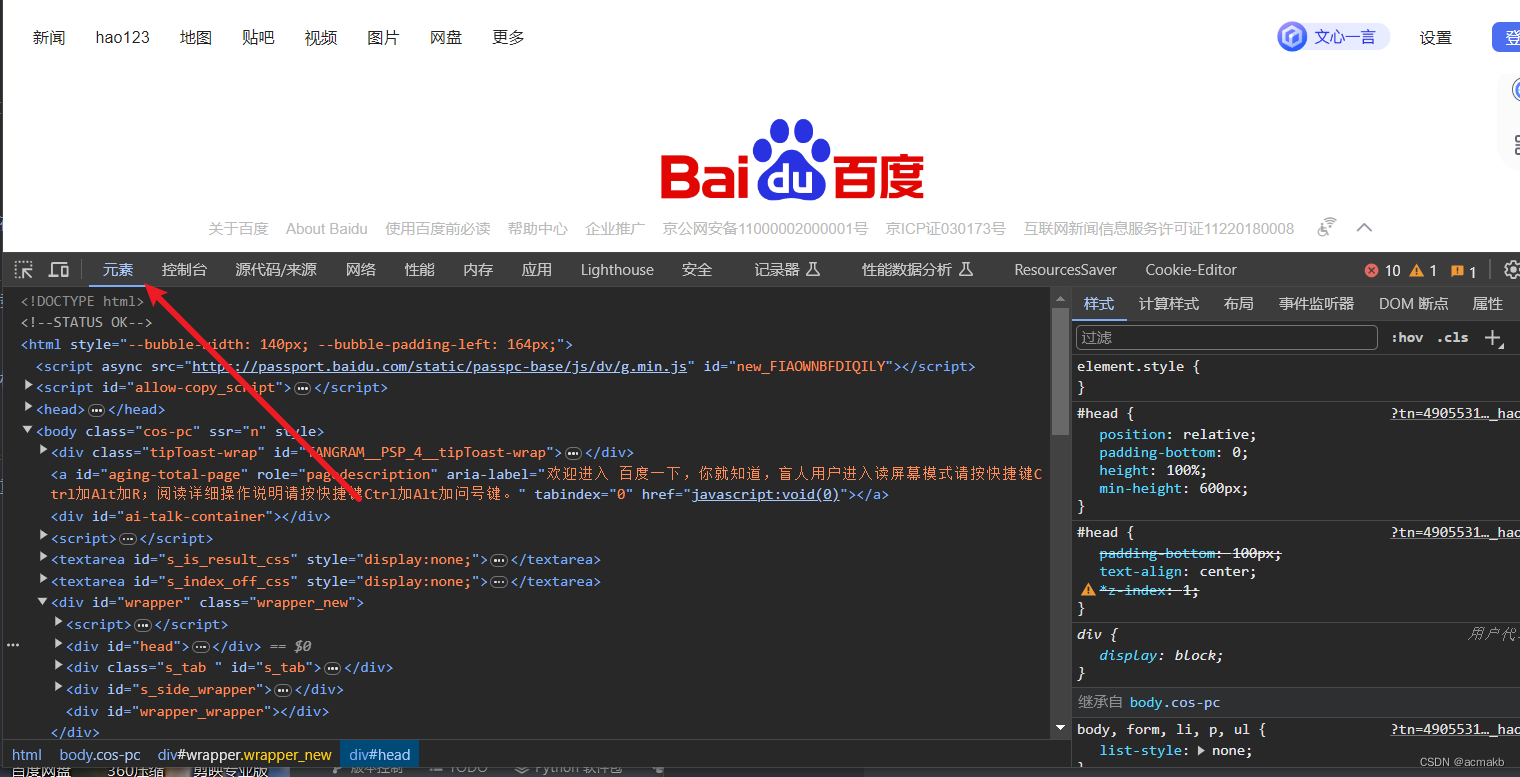
记住这个元素页面是有多个网络请求共同整合出来的数据,即下面网络请求数据包加载渲染后的:

要求:https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action= 解析其相关数据,电影名等等。
from selenium import webdriver
from time import sleep
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
path = r'D:\Downloads\xx\chromedriver-win64\chromedriver.exe'
url='https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action='
driver = webdriver.Chrome(executable_path=path)
driver.get(url)
sleep(5)
print(driver.page_source)
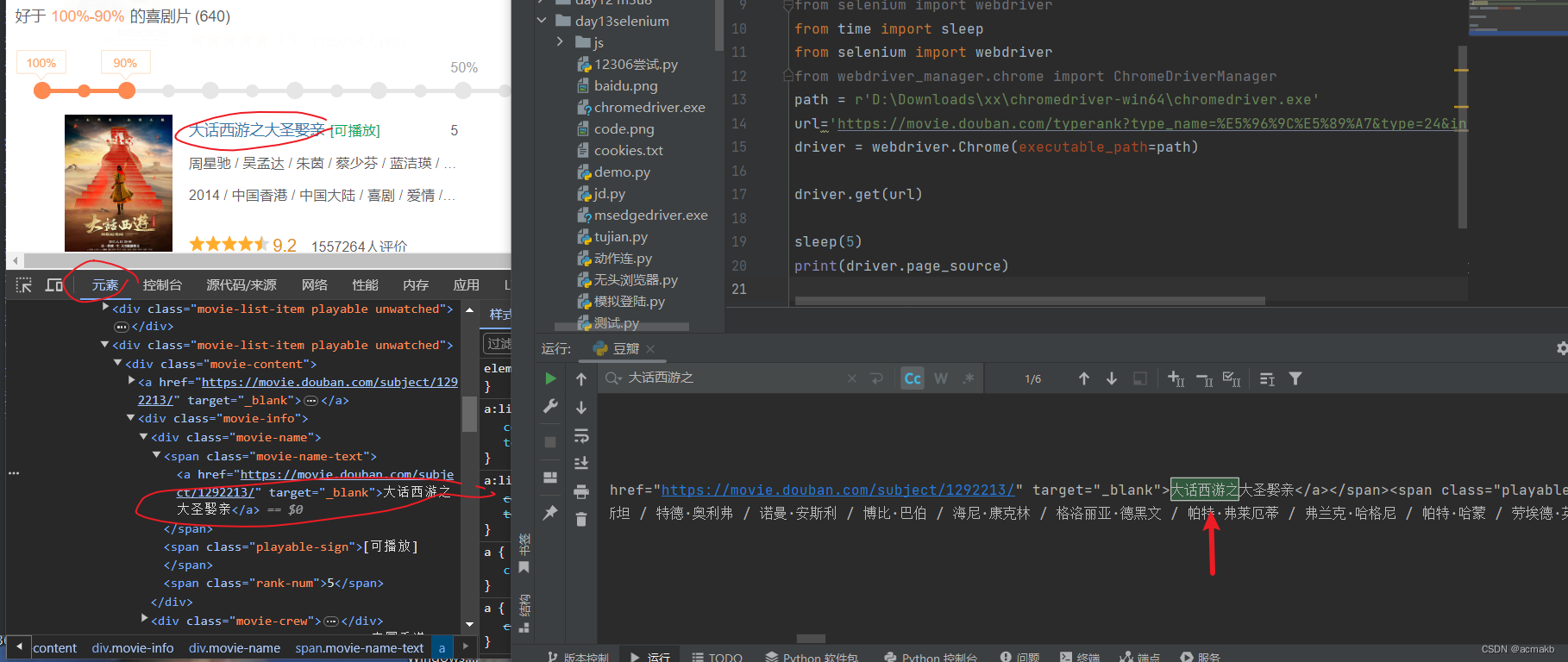
如上图,我们获取的一定是渲染加载完成后的数据,接下来对网页源码数据进行解析即可。如果想获取全部,大家就注入js脚本使用selenium让其不断向下滑动即可。
获取分页数据:
这个案例是之前写的,可能代码以已经失效了,但是爬虫学习学的一定是思路,不是代码,在当前这个大时代,会用chatgpt的程序员才不会被淘汰。
要求:获取前5页的企业名称
实现思路:将每一页源码数据存到一个列表中,最后对列表中的每一项进行数据解析即可,获得首页源码数据后,使用selenium对下一页进行点击,然后不断循环。
#获取前5页的企业名称
from selenium import webdriver
import time
from lxml import etree
bro = webdriver.Chrome(executable_path='./chromedriver')
url = 'http://scxk.nmpa.gov.cn:81/xk/'
bro.get(url=url)
time.sleep(2)
#获取页面源码数据(page_source)
page_text = bro.page_source
#将前5页的页面源码数据存储到该列表中
all_page_text_list = [page_text]
for i in range(4):
#找到下一页标签
next_page_btn = bro.find_element_by_xpath('//*[@id="pageIto_next"]')
# 点击
next_page_btn.click()
#等待几秒 使得网站数据能够加载出来
time.sleep(2)
#将当前页源码数据放入总列表
all_page_text_list.append(bro.page_source)
for page_text in all_page_text_list:
#解析数据
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="gzlist"]/li')
for li in li_list:
# 这里得到 ./ .代表在上面的路径的基础上
title = li.xpath('./dl/@title')[0]
print(title)
time.sleep(2)
bro.quit()
Cookie:
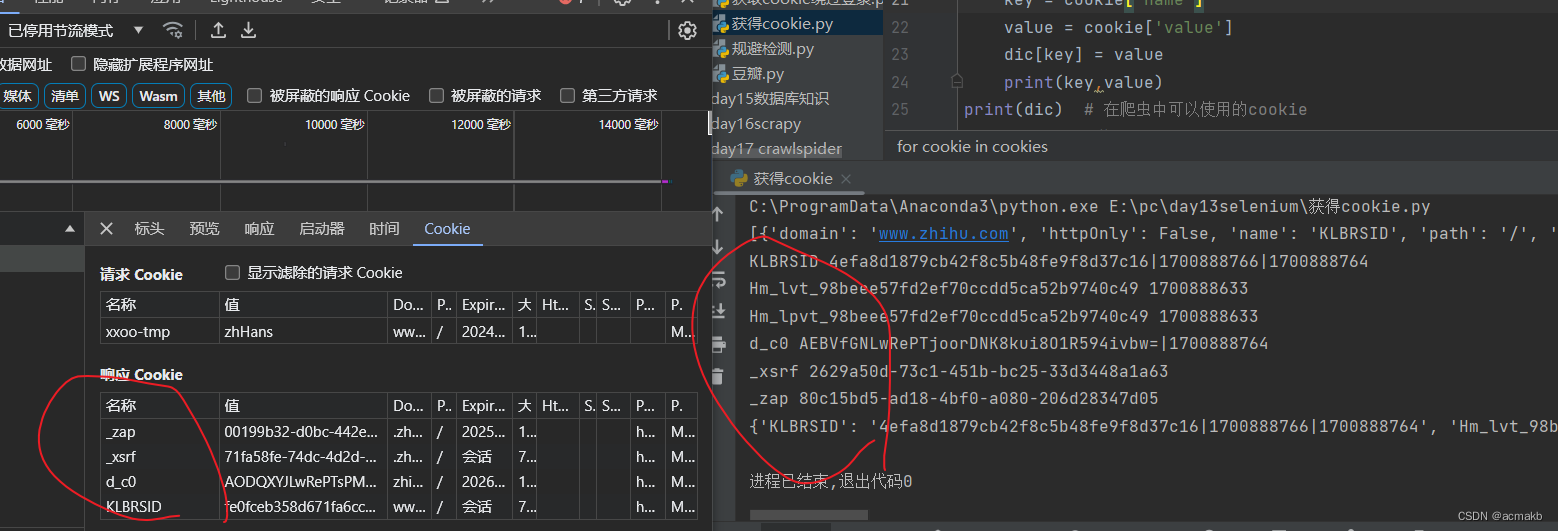
使用Selenium,还可以方便地对Cookies进行操作,例如常见的获取Cookies,示例如下:
- get_cookies()返回值是由字典组成的列表,叫做jsonCookies。
- 需要将jsonCookies解析成浏览器携带的cookie形式
- 这个返回的是相应请求相应回来的cookie
path = r'D:\Downloads\xx\chromedriver-win64\chromedriver.exe'
browser = webdriver.Chrome(executable_path=path)
browser.get('https://www.zhihu.com/explore')
# 获取cookie jsonhuke
cookies = browser.get_cookies()# 返回的是一个列表
print(cookies,type(cookies))
# 解析cookie
dic = {}
for cookie in cookies:
key = cookie['name']
value = cookie['value']
dic[key] = value
print(key,value)
print(dic) # 在爬虫中可以使用的cookie
browser.close()