随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)+知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以很好的弥补通用大语言模型的一些短板,解决通用大语言模型在专业领域回答缺乏依据、存在幻觉等问题。其基本思路是把私域知识文档进行切片,然后向量化后续通过向量数据库检索进行召回,再作为上下文输入到大语言模型进行归纳总结。
在这个技术方向的具体实践中,知识库可以采取基于倒排和基于向量的向量数据库两种索引方式进行构建,它对于知识问答流程中的知识召回这步起关键作用,和普通的文档索引或日志索引不同,知识的向量化需要借助深度模型的语义化能力、存在文档切分、向量数据模型部署&推理等额外步骤。知识向量化建库即向量数据库过程中,不仅仅需要考虑原始的文档量级,还需要考虑切分粒度,向量维度等因素,最终被向量数据库索引的知识条数可能达到一个非常大的量级,可能由以下两方面的原因引起:
1.各个行业的既有文档量很高,如金融、医药、法律领域等,新增量也很大。
2.为了召回效果的追求,对文档的切分常常会采用按句或者按段进行多粒度的冗余存贮。
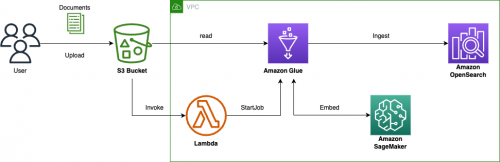
这些细节对知识向量数据库的写入和查询性能带来一定的挑战,为了优化向量化知识库的构建和管理,本文基于亚马逊云科技的服务,构建了如下图的知识库构建流程:
1.通过 S3 Bucket 的 Handler 实时触发 Amazon Lambda 启动对应知识文件入库的 Amazon Glue job;
2.Glue Job 中会进行文档解析和拆分,并调用 Amazon Sagemaker 的 Embedding 模型进行向量化;
3.通过 Bulk 方式注入到 Amazon OpenSearch 中去。

并对整个流程中涉及的多个方面,包括如何进行知识向量化、向量数据库调优总结了一些最佳实践和心得。
知识向量化(即向量数据库的原始步骤)的前置步骤是进行知识的拆分,语义完整性的保持是最重要的考量。分两个方面展开讨论。该如何选用以下两个关注点分别总结了一些经验:
a. 拆分片段的方法
关于这部分的工作,Langchain 作为一种流行的大语言模型集成框架,提供了非常多的 Document Loader 和 Text Spiltters,其中的一些实现具有借鉴意义,但也有不少实现效果是重复的。
目前使用较多的基础方式是采用 Langchain 中的 RecursiveCharacterTextSplitter,属于是 Langchain 的默认拆分器。它采用这个多级分隔字符列表 – [“\n\n”, “\n”, ” “, “”] 来进行拆分,默认先按照段落做拆分,如果拆分结果的 chunk_size 超出,再继续利用下一级分隔字符继续拆分,直到满足 chunk_size 的要求。
但这种做法相对来说还是比较粗糙,还是可能会造成一些关键内容会被拆开。对于一些其他的文档格式可以有一些更细致的做法。
FAQ 文件,必须按照一问一答粒度拆分,后续向量化的输入可以仅仅使用问题,也可以使用问题+答案(本系列 blog 的后续文章会进一步讨论)
Markdown 文件,”#”是用于标识标题的特殊字符,可以采用 MarkdownHeaderTextSplitter 作为分割器,它能更好的保证内容和标题对应的被提取出来。
PDF 文件,会包含更丰富的格式信息。Langchain 里面提供了非常多的 Loader,但 Langchain 中的 PDFMinerPDFasHTMLLoader 的切分效果上会更好,它把 PDF 转换成 HTML,通过 HTML 的 <div> 块进行切分,这种方式能保留每个块的字号信息,从而可以推导出每块内容的隶属关系,把一个段落的标题和上一级父标题关联上,使得信息更加完整。类似下面这种效果。
b. 模型对片段长度的支持
由于拆分的片段后续需要通过向量化模型进行推理,所以必须考虑向量化模型的 Max_seq_length 的限制,超出这个限制可能会导致出现截断,导致语义不完整。从支持的 Max_seq_length 来划分,目前主要有两类 Embedding 模型,如下表所示(这四个是有过实践经验的模型)。
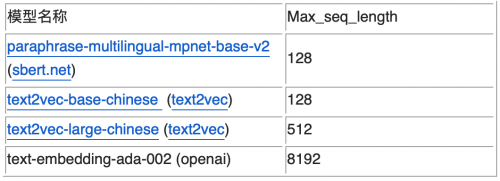
这里的 Max_seq_length 是指 Token 数,和字符数并不等价。依据之前的测试经验,前三个模型一个 token 约为 1.5 个汉字字符左右。而对于大语言模型,如 chatglm,一个 token 一般为 2 个字符左右。如果在切分时不方便计算 token 数,也可以简单按照这个比例来简单换算,保证不出现截断的情况。
前三个模型属于基于 Bert 的 Embedding 模型,OpenAI 的 text-embedding-ada-002 模型是基于 GPT3 的模型。前者适合句或者短段落的向量化,后者 OpenAI 的 SAAS 化接口,适合长文本的向量化,但不能私有化部署。
可以根据召回效果进行验证选择。从目前的实践经验上看 text-embedding-ada-002 对于中文的相似性打分排序性可以,但区分度不够(集中 0.7 左右),不太利于直接通过阈值判断是否有相似知识召回。
另外,对于长度限制的问题也有另外一种改善方法,可以对拆分的片段进行编号,相邻的片段编号也临近,当召回其中一个片段时,可以通过向量数据库的 range search 把附近的片段也召回回来,也能保证召回内容的语意完整性。
我们上面提到四个向量数据库模型只是提到了模型对于文本长度的支持差异,效果方面目前并没有非常权威的结论。可以通过 leaderboard 来了解各个模型的性能,榜上的大多数的模型的评测还是基于公开数据集的 benchmark,对于真实生产中的场景 benchmark 结论是否成立还需要 case by case 地来看。但原则上有以下几方面的经验可以分享:
经过垂直领域 Finetune 的模型比原始向量模型有明显优势;
目前的向量化模型分为两类,对称和非对称。未进行微调的情况下,对于 FAQ 建议走对称召回,也就是 Query 到 Question 的召回。对于文档片段知识,建议使用非对称召回模型,也就是 Query 到 Answer(文档片段)的召回;
没有效果上的明显的差异的情况下,尽量选择向量维度短的模型,高维向量(如 openai 的 text-embedding-ada-002)会给向量数据库造成检索性能和成本两方面的压力。
更多的内容会在本系列的召回优化部分进行深入讨论。
真实的业务场景中,文档的规模在百到百万这个数量级之间。按照冗余的多级召回方式,对应的知识条目最高可能达到亿的规模。由于整个离线计算的规模很大,所以必须并发进行,否则无法满足知识新增和向量检索效果迭代的要求。步骤上主要分为以下三个计算阶段。

文档切分并行
计算的并发粒度是文件级别的,处理的文件格式也是多样的,如 TXT 纯文本、Markdown、PDF 等,其对应的切分逻辑也有差异。而使用 Spark 这种大数据框架来并行处理过重,并不合适。使用多核实例进行多进程并发处理则过于原始,任务的观测追踪上不太方便。所以可以选用 Amazon Glue 的 Python shell 引擎进行处理。主要有如下好处:
1.方便的按照文件粒度进行并发,并发度简单可控。具有重试、超时等机制,方便任务的追踪和观察,日志直接对接到 Amazon CloudWatch;
2.方便的构建运行依赖包,通过参数–additional-python-modules 指定即可,同时 Glue Python 的运行环境中已经自带了 opensearch_py 等依赖。
可参考如下代码:
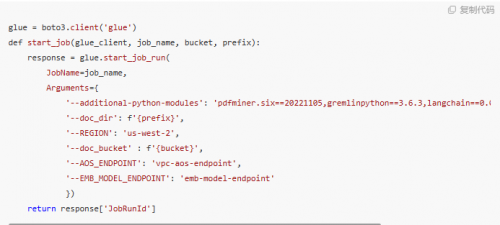
注意:Amazon Glue 每个账户默认的最大并发运行的 Job 数为 200 个,如果需要更大的并发数,需要申请提高对应的 Service Quota,可以通过后台或联系客户经理。
向量化推理并行
由于切分的段落和句子相对于文档数量也膨胀了很多倍,向量数据库模型的推理吞吐能力决定了整个流程的吞吐能力。这里采用 SageMaker Endpoint 来部署向量化模型,一般来说为了提供模型的吞吐能力,可以采用 GPU 实例推理,以及多节点 Endpoint/Endpoint 弹性伸缩能力,Server-Side/Client-Side Batch 推理能力这些都是一些有效措施。具体到离线向量知识库构建这个场景,可以采用如下几种策略:
GPU 实例部署
向量化模型 CPU 实例是可以推理的。但离线场景下,推理并发度高,GPU 相对于 CPU 可以达到 20 倍左右的吞吐量提升。所以离线场景可以采用 GPU 推理,在线场景 CPU 推理的策略。
多节点 Endpoint
对于临时的大并发向量生成,通过部署多节点 Endpoint 进行处理,处理完毕后可以关闭*(注意:离线生成的请求量是突然增加的,Auto Scaling 冷启动时间 5-6 分钟,会导致前期的请求出现错误)*
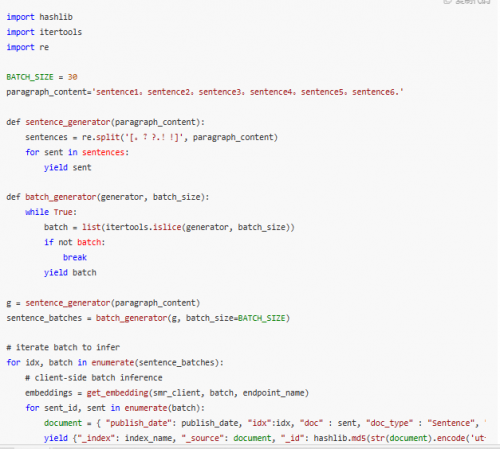
利用 Client-Side Batch 推理
离线推理时,Client-side batch 构造十分容易。无需开启 Server-side Batch 推理,一般来说 Sever-side batch 都会有个等待时间,如 50ms 或 100ms,对于推理延迟比较高的大语言模型比较有效,对于向量化推理则不太适用。可以参考如下代码:
OpenSearch 批量注入
Amazon OpenSearch 的写入操作,在实现上可以通过 bulk 批量进行,比单条写入有很大优势。参考如下代码:

![[HCIE] IPSec-VPN (手工模式)](https://img-blog.csdnimg.cn/6be76ad4c18848b0ad48afd0635349ab.png)