文章目录
- 2.3 TCP协议
- 2.3.10 拥塞控制
- 2.3.11 延迟应答
- 2.3.12 捎带应答
- 2.3.13 面向字节流
- 2.3.14 粘包问题
- 2.3.15 TCP异常情况
- 2.3.16 TCP小结
- 2.3.17 基于TCP应用层协议
2.3 TCP协议
2.3.10 拥塞控制
虽然TCP有了滑动窗口这个大杀器, 能够高效可靠的发送大量的数据. 但是如果在刚开始阶段就发送大量的数据, 仍然可能引发问题.
因为网络上有很多的计算机, 可能当前的网络状态就已经比较拥堵. 在不清楚当前网络状态下, 贸然发送大量的数据,是很有可能引起雪上加霜的.
TCP引入 慢启动 机制, 先发少量的数据, 探探路, 摸清当前的网络拥堵状态, 再决定按照多大的速度传输数据;
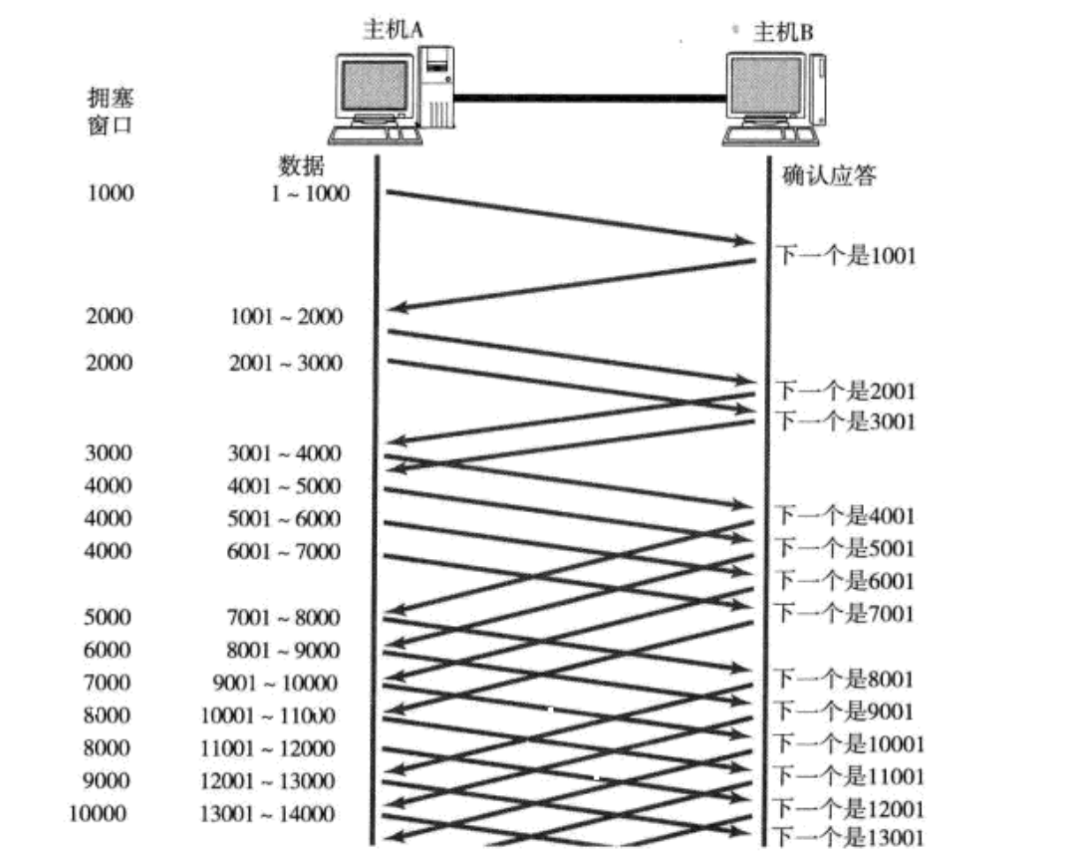
- 此处引入一个概念程为拥塞窗口
- 发送开始的时候, 定义拥塞窗口大小为1;
- 每次收到一个ACK应答, 拥塞窗口加1;
- 每次发送数据包的时候, 将拥塞窗口和接收端主机反馈的窗口大小做比较, 取较小的值作为实际发送的窗口;
像上面这样的拥塞窗口增长速度, 是指数级别的. “慢启动” 只是指初使时慢, 但是增长速度非常快.
为了不增长的那么快, 因此不能使拥塞窗口单纯的加倍.
此处引入一个叫做慢启动的阈值
当拥塞窗口超过这个阈值的时候, 不再按照指数方式增长, 而是按照线性方式增长
当TCP开始启动的时候, 慢启动阈值等于窗口最大值;
在每次超时重发的时候, 慢启动阈值会变成原来的一半, 同时拥塞窗口置回1;
少量的丢包, 我们仅仅是触发超时重传; 大量的丢包, 我们就认为网络拥塞;
当TCP通信开始后, 网络吞吐量会逐渐上升; 随着网络发生拥堵, 吞吐量会立刻下降;
拥塞控制, 归根结底是TCP协议想尽可能快的把数据传输给对方, 但是又要避免给网络造成太大压力的折中方案.
TCP拥塞控制这样的过程, 就好像 热恋的感觉
2.3.11 延迟应答
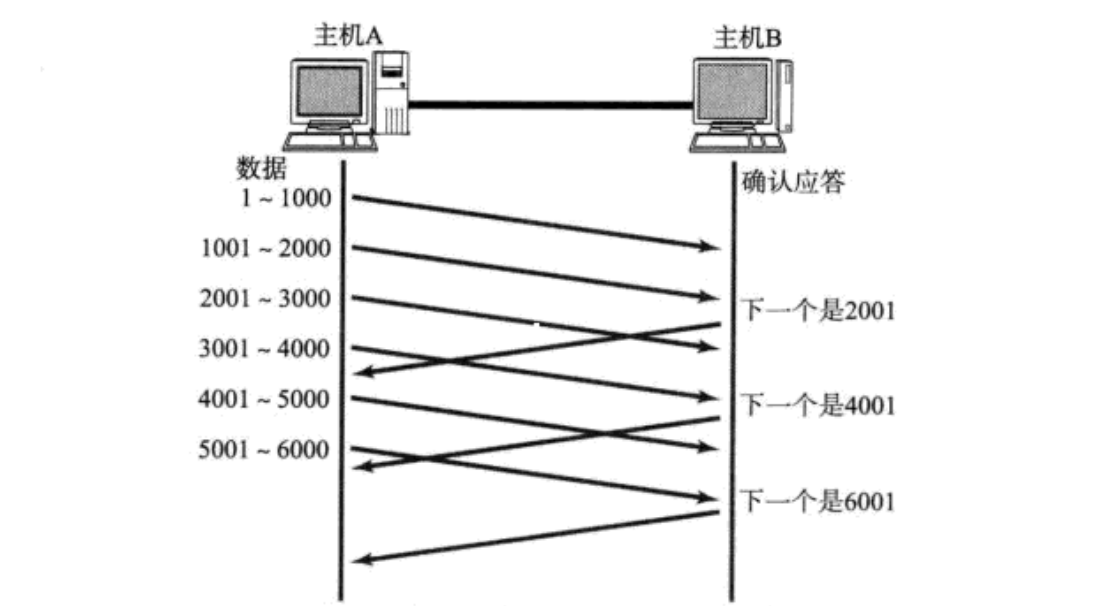
如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小.
- 假设接收端缓冲区为1M. 一次收到了500K的数据; 如果立刻应答, 返回的窗口就是500K;
- 但实际上可能处理端处理的速度很快, 10ms之内就把500K数据从缓冲区消费掉了;
- 在这种情况下, 接收端处理还远没有达到自己的极限, 即使窗口再放大一些, 也能处理过来;
- 如果接收端稍微等一会再应答, 比如等待200ms再应答, 那么这个时候返回的窗口大小就是1M;
一定要记得, 窗口越大, 网络吞吐量就越大, 传输效率就越高. 我们的目标是在保证网络不拥塞的情况下尽量提高传输效率;
那么所有的包都可以延迟应答么? 肯定也不是;
- 数量限制: 每隔N个包就应答一次;
- 时间限制: 超过最大延迟时间就应答一次;
具体的数量和超时时间, 依操作系统不同也有差异; 一般N取2, 超时时间取200ms;
2.3.12 捎带应答
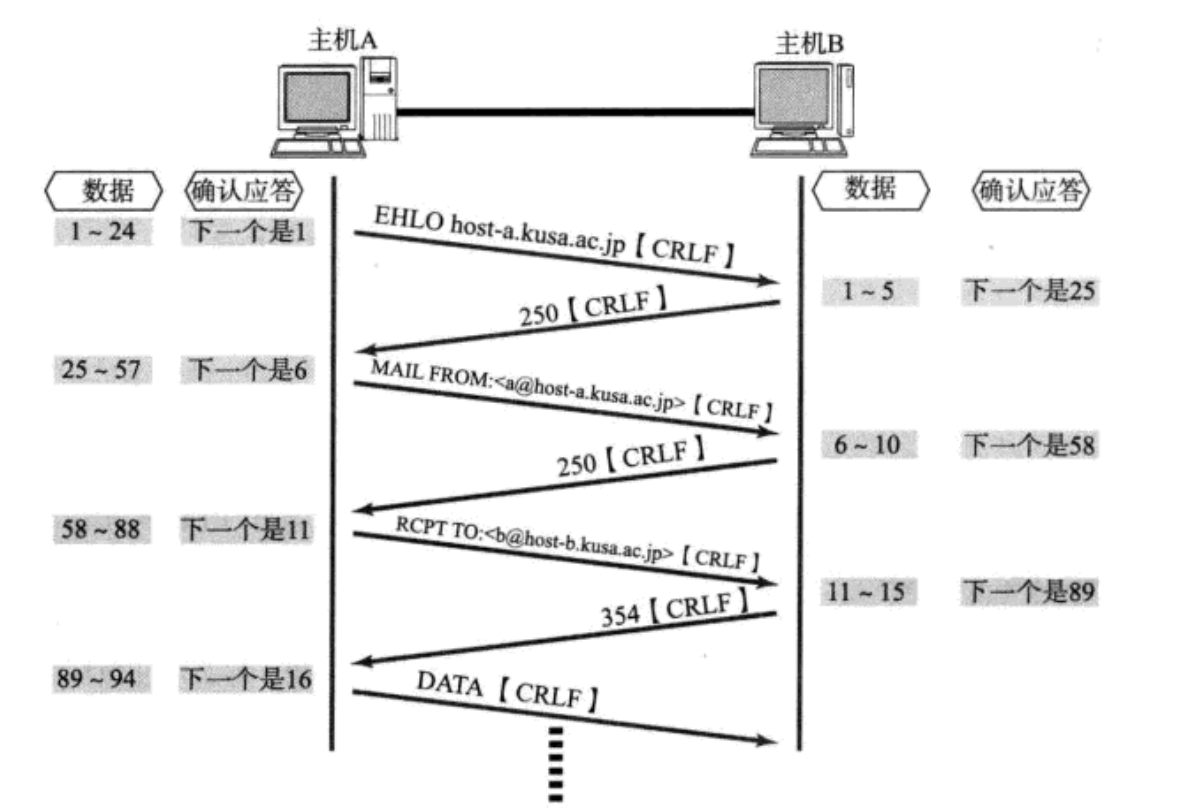
在延迟应答的基础上, 我们发现, 很多情况下, 客户端服务器在应用层也是 “一发一收” 的. 意味着客户端给服务器说了 “How are you”, 服务器也会给客户端回一个 “Fine, thank you”;
那么这个时候ACK就可以搭顺风车, 和服务器回应的 “Fine, thank you” 一起回给客户端
2.3.13 面向字节流
创建一个TCP的socket, 同时在内核中创建一个 发送缓冲区 和一个 接收缓冲区;
- 调用write时, 数据会先写入发送缓冲区中;
- 如果发送的字节数太长, 会被拆分成多个TCP的数据包发出;
- 如果发送的字节数太短, 就会先在缓冲区里等待, 等到缓冲区长度差不多了, 或者其他合适的时机发送出去;
- 接收数据的时候, 数据也是从网卡驱动程序到达内核的接收缓冲区;
- 然后应用程序可以调用read从接收缓冲区拿数据;
- 另一方面, TCP的一个连接, 既有发送缓冲区, 也有接收缓冲区, 那么对于这一个连接, 既可以读数据, 也可以写数据. 这个概念叫做 全双工
由于缓冲区的存在, TCP程序的读和写不需要一一匹配, 例如:
- 写100个字节数据时, 可以调用一次write写100个字节, 也可以调用100次write, 每次写一个字节;
- 读100个字节数据时, 也完全不需要考虑写的时候是怎么写的, 既可以一次read 100个字节, 也可以一次read一个字节, 重复100次;
2.3.14 粘包问题
[八戒吃馒头例子]
- 首先要明确, 粘包问题中的 “包” , 是指的应用层的数据包.
- 在TCP的协议头中, 没有如同UDP一样的 “报文长度” 这样的字段, 但是有一个序号这样的字段.
- 站在传输层的角度, TCP是一个一个报文过来的. 按照序号排好序放在缓冲区中.
- 站在应用层的角度, 看到的只是一串连续的字节数据.
- 那么应用程序看到了这么一连串的字节数据, 就不知道从哪个部分开始到哪个部分, 是一个完整的应用层数据包.
那么如何避免粘包问题呢? 归根结底就是一句话, 明确两个包之间的边界.
- 对于定长的包, 保证每次都按固定大小读取即可; 例如上面的Request结构, 是固定大小的, 那么就从缓冲区从头开始按sizeof(Request)依次读取即可;
- 对于变长的包, 可以在包头的位置, 约定一个包总长度的字段, 从而就知道了包的结束位置;
- 对于变长的包, 还可以在包和包之间使用明确的分隔符(应用层协议, 是程序猿自己来定的, 只要保证分隔符不和正文冲突即可);
思考: 对于UDP协议来说, 是否也存在 “粘包问题” 呢?
- 对于UDP, 如果还没有上层交付数据, UDP的报文长度仍然在. 同时, UDP是一个一个把数据交付给应用层. 就有很明确的数据边界.
- 站在应用层的站在应用层的角度, 使用UDP的时候, 要么收到完整的UDP报文, 要么不收. 不会出现"半个"的情况.
2.3.15 TCP异常情况
- 进程终止: 进程终止会释放文件描述符, 仍然可以发送FIN. 和正常关闭没有什么区别.
- 机器重启: 和进程终止的情况相同.
- 机器掉电/网线断开: 接收端认为连接还在, 一旦接收端有写入操作, 接收端发现连接已经不在了, 就会进行reset. 即, 会定期询问对方是否还在 使没有写入操作 . 如果对方不在 , TCP自己也内置了一个保活定时器 , 也会把连接释放.
- 另外, 应用层的某些协议, 也有一些这样的检测机制. 例如HTTP长连接中, 也会定期检测对方的状态. 例如QQ, 在QQ断线之后, 也会定期尝试重新连接.
2.3.16 TCP小结
为什么TCP这么复杂? 因为要保证可靠性, 同时又尽可能的提高性能.
可靠性:
- 校验和
- 序列号(按序到达)
- 确认应答
- 超时重发
- 连接管理
- 流量控制
- 拥塞控制
提高性能:
- 滑动窗口
- 快速重传
- 延迟应答
- 捎带应答
其他:
- 定时器(超时重传定时器, 保活定时器, TIME_WAIT定时器等)
2.3.17 基于TCP应用层协议
- HTTP
- HTTPS
- SSH
- Telnet
- FTP
- SMTP









![[NOIP 2003 普及组] 栈 Java](https://i-blog.csdnimg.cn/direct/07c35fd8e1314b9593b56802d8d6f3ed.png)