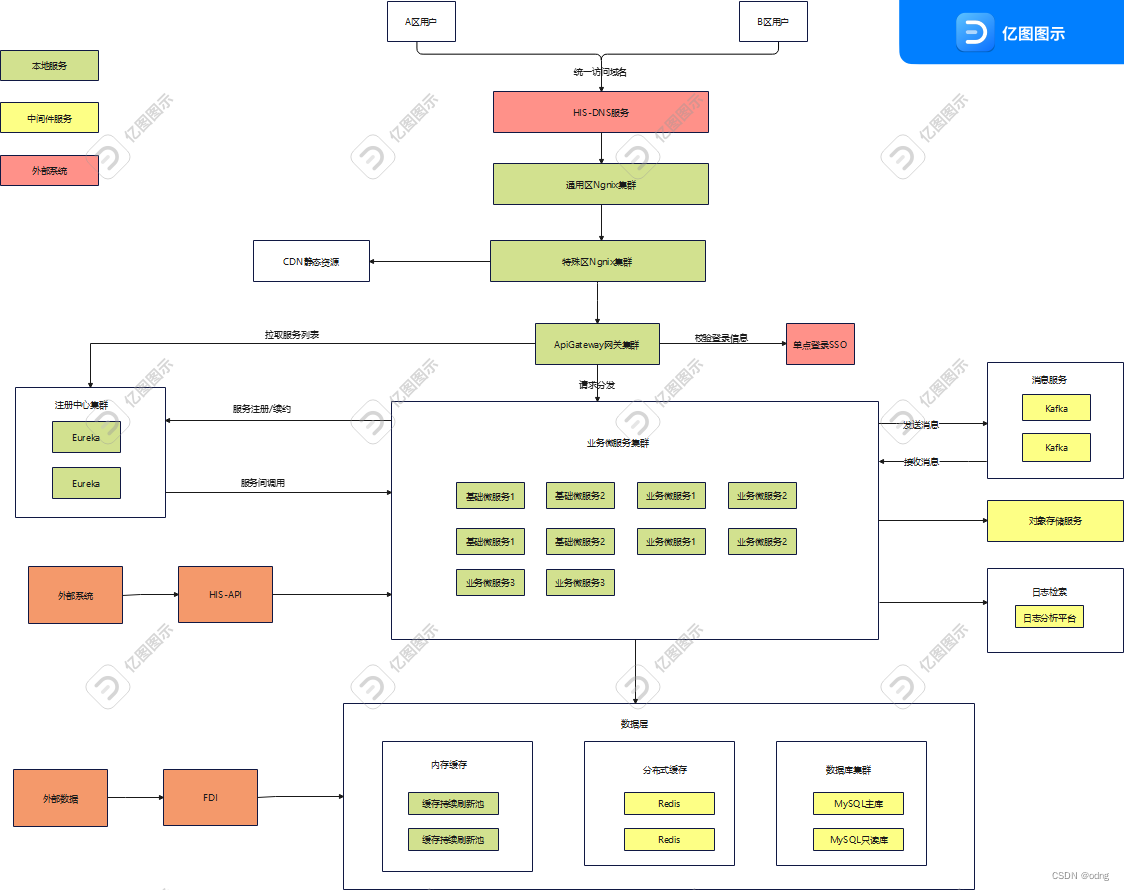
两个重要的函数
-
dir(): 一个内置函数,用于列出对象的所有属性和方法

-
help():一个内置函数,用于获取关于Python对象、模块、函数、类等的详细信息

Dateset类
- Dataset:pytorch中的一个类,开发者在训练和测试时,用一个子类去继承Dataset类,继承和重写Dataset类中方法和属性,以加载数据集。
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
- def getitem(self, index):必须重写,用于以加载数据集。
- def len(self):可不重写,用于计算数据集中样本个数。

TensorBoard
- TensorBoard 是pytorch中一组用于数据可视化的工具,包含在TensorFlow库。
- SummaryWriter类:用于在给定目录中创建事件文件,在训练时,将数据添加到文件中,用于显示。使用SummaryWriter类创建对象时,若没有给出事件文件名,则默认的事件文件名为run。
损失函数
- torch.nn.loss():PyTorch 中的一个类,用于计算L1 损失函数,即计算了预测值与实际值之间的L1范数(即绝对差值)。
- 在创建torch.nn.L1Loss(reduction)对象时,可以传入一个可选的参数reduction,它决定了如何从每个样本的损失中聚合得到最终的损失。
1. reduction=‘mean’:计算所有样本损失的平均值作为最终损失。默认情况下,reduction参数的值为’mean’,即计算所有样本损失的平均值作为最终损失。
2. reduction=‘none’:不进行任何聚合操作,直接返回每个样本的损失。
3. reduction=‘sum’:计算所有样本损失的总和作为最终损失。
4. reduction= ‘mean_none’: 计算所有样本损失的平均值,但是不除以样本数,即不进行归一化。
5. reduction=‘sum_none’:计算所有样本损失的总和,但是不乘以样本数,即不进行归一化。 - 在调用torch.nn.L1Loss()对象时,要传入预测值和实际值。

- torch.nn.MSELoss():PyTorch库中的一个类,用于计算均方误差。MSE损失函数的计算方式是:对于每个样本,计算预测值与真实值之间的平方差,然后取这些平方差的平均值。具体公式为:loss = 1/n Σ (y_pred - y_true)^2,其中n是样本数量。

- torch.nn.CrossEntropyLoss:是PyTorch库中的一个类,用于计算交叉熵损失。
- 在创建对象时,torch.nn.CrossEntropyLoss()参数:
- weight: 类别权重。这是一个一维的tensor,用于为每个类别指定不同的权重。默认值是None,这时所有的类别权重都相等。如果指定了类别权重,那么在计算损失时,每个类别的损失将会根据其对应的权重进行加权平均。
- reduction: 损失的归约方式。这个参数决定了如何将交叉熵损失的值从样本级别降低到批次级别。可能的值有:‘none’(不进行归约,返回每个样本的交叉熵损失),‘mean’(对所有样本的交叉熵损失取平均),‘sum’(将所有样本的交叉熵损失相加)。默认值是’mean’。
- ignore_index: 被忽略的类别索引。如果设置了该参数,那么在计算交叉熵损失时,该类别对应的损失将被忽略。这个参数主要用于处理数据集中的无效类别或不需要分类的类别。默认值是-100。
- 在调用torch.nn.CrossEntropyLoss的对象时,需要传入两个参数:
- input:这是一个一维或二维张量,表示模型的输出。对于每个输入样本,输出应该是一个长度为类别数量的向量,每个元素表示该类别与输入样本的相似度。
- target:这是一个一维张量,表示每个输入样本的正确类别标签。

优化器(参数更新)
- torch.optim.SGD:PyTorch 中的一个类,它实现了随机梯度下降(Stochastic Gradient Descent)算法。
- 创建类对象时,torch.optim.SGD(params,lr,momentum,dampening,weight_decay,nesterov)的参数:
- params:要优化的参数,通常是模型中的参数。
- lr:学习率。控制参数更新的步长。默认值是0.01。
- momentum:动量。这个参数会考虑之前梯度的方向,使得优化器具有一定的"惯性",有助于加速训练。默认值是0。
- dampening:阻尼。这个参数可以防止动量过大导致震荡。默认值是0。
- weight_decay:权重衰减。可以防止过拟合,通过对参数本身进行惩罚来控制模型的复杂度。默认值是0,表示不进行权重衰减。
- nesterov:是否使用 Nesterov 动量。如果为 True,会使用 Nesterov 动量,否则使用标准 momentum。默认值是False
- 创建优化器后,我们可以通过调用 optimizer.zero_grad() 清除之前的梯度,然后通过反向传播计算新的梯度,最后使用 optimizer.step() 更新模型的参数。
import torch
from torch import nn
from torch.nn import Sequential,Conv2d,MaxPool2d,Flatten
from torch.nn import Linear
from torch.utils.tensorboard import SummaryWriter
import torchvision
import torchvision.transforms
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
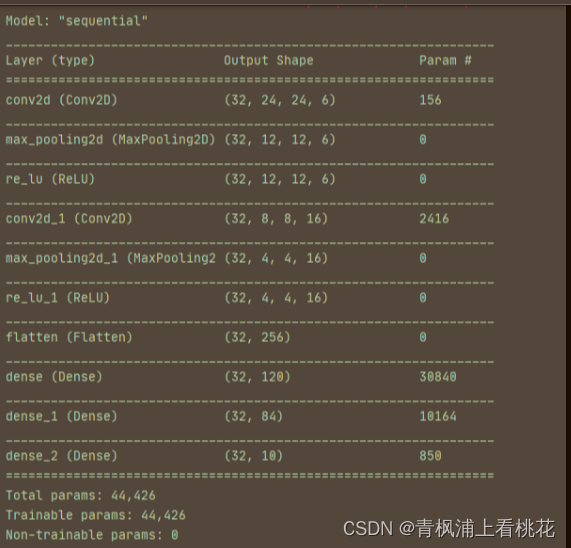
class MY_Dodule(nn.Module):
def __init__(self):
super(MY_Dodule,self).__init__()
self.model = Sequential(
Conv2d(3, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,input):
output = self.model(input)
return output
my_module = MY_Dodule()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(my_module.parameters(),lr=0.1)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
images,targets = data
input = images
output = my_module(input) # 前向转播
result_loss = loss(output,targets) # 计算损失
optim.zero_grad() # 清除之前的梯度
result_loss.backward() # 反向转播
optim.step() #梯度更新
running_loss += result_loss
pass
print(running_loss)
pass
网络模型的使用和修改
-
torchvision.models.vgg16(pretrained,progress):PyTorch 中的一个类,是用来加载预训练的 VGG-16 模型的函数。
- pretrained:布尔型,决定是否从 PyTorch 的预训练模型库中加载训练好的权重。如果设为 True,则返回的模型会包含在大规模图像分类任务上训练得到的权重。如果设为 False,则模型不包含预训练的权重,你需要自己训练模型。默认为False。
- progress:布尔型,决定是否显示下载预训练模型过程的进度条。如果设为 True,则在下载预训练模型时会显示进度条。默认为True。
-
在 VGG-16 模型中添加层:model是torchvision.models.vgg16()示例化对象,model.classifier.add_module(str,nn.Module)这个函数接受两个参数。
- 模块名称(str):这是你想要添加的模块的名称。你可以自己定义一个有意义的名称,以便在后续的代码中引用这个模块。
- 模块对象(nn.Module):这是你想要添加的模块本身。这个模块可以是任何PyTorch定义的神经网络层或者你自己定义的层。
-
在 VGG-16 模型中修改层:model是torchvision.models.vgg16()示例化对象,model.classifier[n] = nn.Module
- n:VGG-16 模型中修改层的层号
- nn.Module:修改后的模块本身。这个模块可以是任何PyTorch定义的神经网络层或者你自己定义的层。

网络模型的保存与读取
- torch.save(model, ‘model.pth’):PyTorch 中的一个函数,模型model的权重和参数,保存在指定文件model.pth中。
- model = torch.load(‘model.pth’):PyTorch 中的一个函数,根据model.pth文件,加载保存的模型并返回给变量 model
- torch.save(model.state_dict(), ‘model.pth’): 将模型model参数(权重和偏置等,不包括模型的结构),以字典的形式保存到指定的文件 ‘model.pth’ 中。
- model.load_state_dict(torch.load(‘model.pth’)):torch.load()函数读取文件中模型的参数信息,加载到model模型中。请注意,这种方式要求你在加载模型时已经知道模型model的结构。
模型训练流程(以CIFAR10为例)
- 第一步:准备数据集,包括训练集和测试集
import torchvision
# 准备训练集
train_data = torchvision.datasets.CIFAR10("dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
# 准备测试集
test_data = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
- 第二步:计算数据长度
# 计算数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
- 第三步:用dataloader()加载数据集,将数据集划分为批量子集
# dataloader()加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
- 第四步:搭建神经网络,一般用一个单独python文件保存
import torch
from torch import nn
class My_Module(nn.Module):
def __init__(self):
super(My_Module,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32 ,32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10),
)
def forward(self,input):
output = self.model(input)
return output
if __name__ == '__main__':
my_module = My_Module()
input = torch.ones((64, 3, 32, 32))
output = my_module(input)
print(output.shape)
- 第五步:创建网络模型
# 创建网络模型
my_module = My_Module()
- 第六步:定义损失函数
loss_f = nn.CrossEntropyLoss()
- 第七步:定义优化器,进行梯度下降
# 定义优化器,进行梯度下降
learning_rate = 0.01 # 学习效率
optimizer = torch.optim.SGD(my_module, lr=learning_rate)
- 第八步:设置训练网络模型的一些参数
# 设置训练网络模型的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练的轮次
writer = SummaryWriter("P27") # 添加tensorboard
- 第九步:训练网络模型
# 训练网络模型
for i in range(epoch):
print("------第{}轮训练开始------".format(i + 1))
# 训练步骤开始
for data in train_dataloader:
images ,targets = data
input = images
output = my_module(input) # 前向传播
loss = loss_f(output, targets) # 计算损失
loss.backward() # 反向转播
optimizer.zero_grad() #
optimizer.step() # 梯度下降
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_data:
images, targets = data
inputs = images
outputs = my_module(inputs)
loss = loss_f(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy / test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(my_module,"my_mudule_{}.pth".format(i))
writer.close()