前引:前面我们通过层层学习,了解了Hoare大佬的排序精髓,今天我们学习的东西可能稍微有点难度,因此我们必须学会思想,我很受感慨,借此分享一下:【用1520分钟去调试】,如果我们遇到了任何问题,必须先学会自己能不能解决,调试是每次代码找错的一个途径。通过每次调试,看它的数据变化是否达到了目前应该的预期,然后我们找到了错误,应该如何改进!下面小编通过拆分思想,一步步带你深解这些算法思想的奥妙!
目录
快排(双指针·递归)
算法思想:
实现步骤:
复杂度分析:
代码实现:
单趟实现:
递归实现:
代码优化:
优缺点分析:
快排(双指针·非递归)
算法思想:
实现步骤:
代码实现:
左区间:
右区间:
整体代码展示:
优缺点分析:
小编寄语
快排(双指针·递归)
大家在写部分题目的时候,是否有在评论区看见这样的评论:“双指针秒了”,小编当时见的很多,当时我不知道双指针是哈,但是现在领悟了!双指针是通过两个指针完成!这里的“指针”并非真正是指针,也可以是下标,因为arr【i】=*(p+i),它们都是指元素,下面我们看看哈是双指针!
算法思想:
双指针排序是利用两个指针协助操作来完成排序的任务,它们通常同向移动或者相向移动,典型的运用场景如下面两方面:
(1)快速排序:通过分区操作将数组分为小于/大于基准值的两部分进行递归(当前主讲)
(2)归并排序:合并两个有序子数组时,通过双指针比较元素大小
为了方便接下来思路拆分比较好理解,我先总结2个指针的原理(cur是前指针,prev是后指针):
(1)cur找小,找到小之后,prev再找大,然后二者交换对应的元素,cur再向前移动
(2)prev找大,找到大之后,与cur所指的值进行交换
实现步骤:
在进行正式的学习之前,我们先来看一下它的动图,好好感悟一下,然后我们进行思路拆分讲解:

1:老套路,我们先来实现单趟。我们发现,在开始前,数据的初始化是如下图这样的:
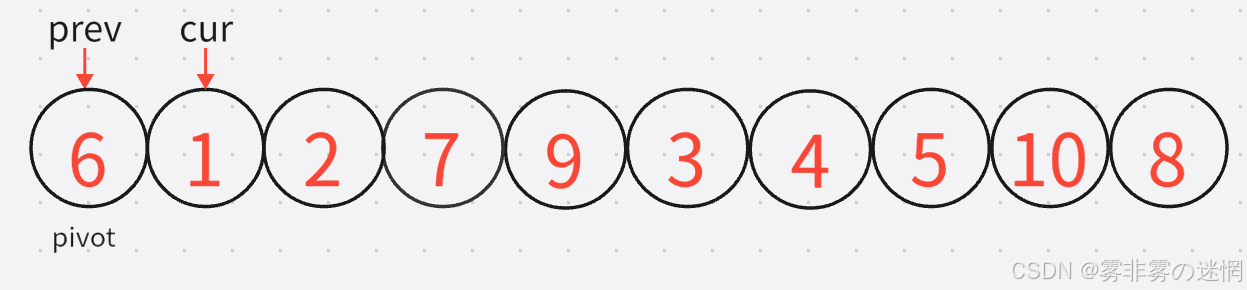
2:然后重点来了!为了清晰对比,我对这两个指针功能进行了拆分,为什么找小、找大?
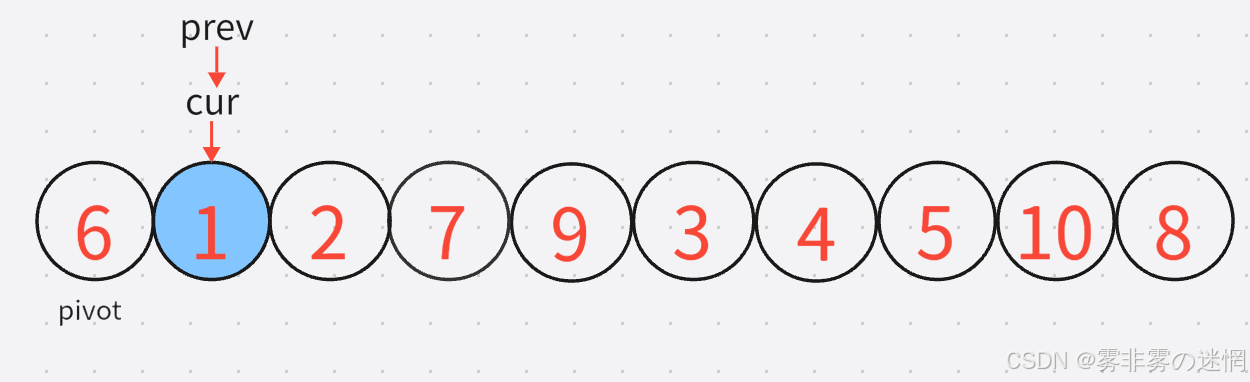
cur :找小(对于基准值而言),因为我们需要与prev所指向的进行交换,小的交换到左边去
prev :找大(对于基准值而言)因为我们需要将其与cur所指的内容进行交换,大的要到右边去
3:既然是前后指针法,cur是要先动,cur找到小之后,prev再动,直到找到较大的元素:【注意:prev不能跑到cur的前面去】
这里cur所指的元素刚好就是满足条件的,因此再移动prev就行了,如图:
此时prev与cur重合了, 那么就进行交换,交换之后1还是在原来的地方,交换完之后cur再加加,进入新一轮的判断,这是第一轮结束的情况:
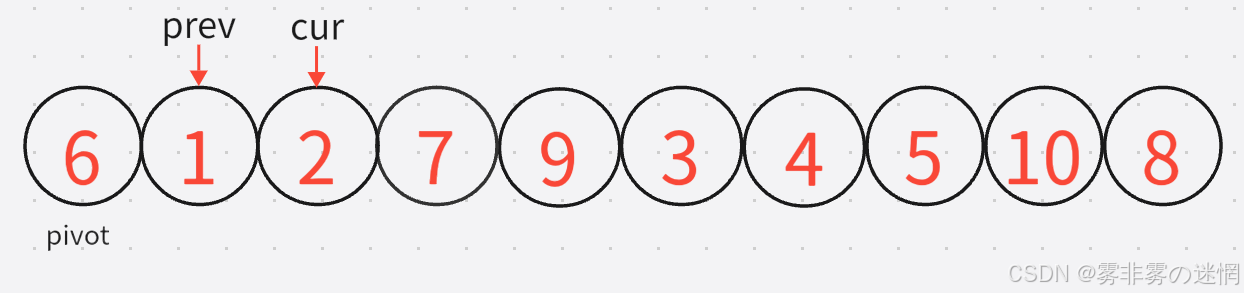
4:下面进行第二轮 。这里还是跟刚才情况一样,cur刚好满足情况,二者重合了,所以第二轮结尾的状况就是:
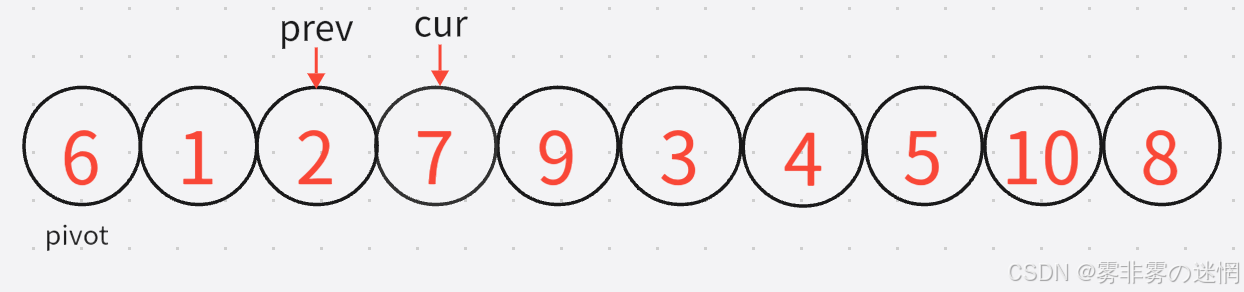
5: 第三轮:cur所指的元素是较大的,因此经过几轮循环加加,直到找到小于基准值所指的元素
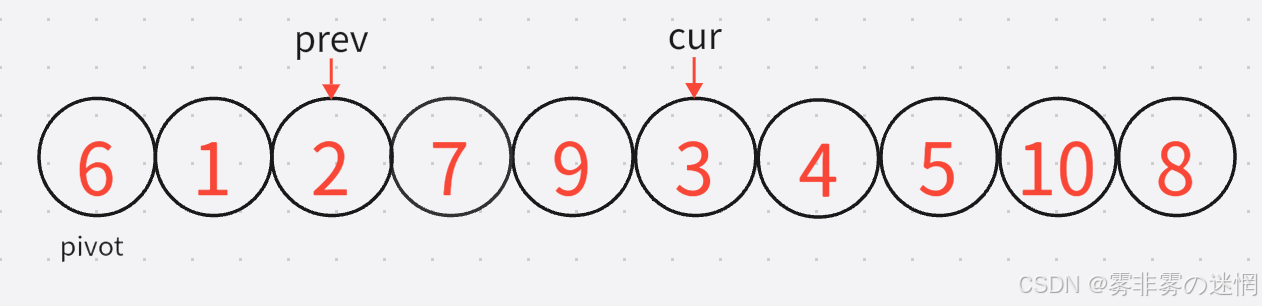
现在找到了较小的元素3,然后prev加加,直到找到较大的元素,二者再进行交换:
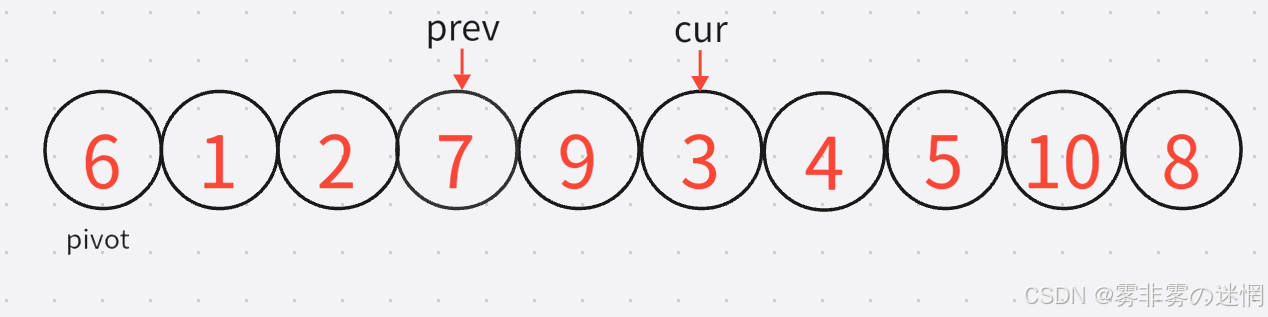
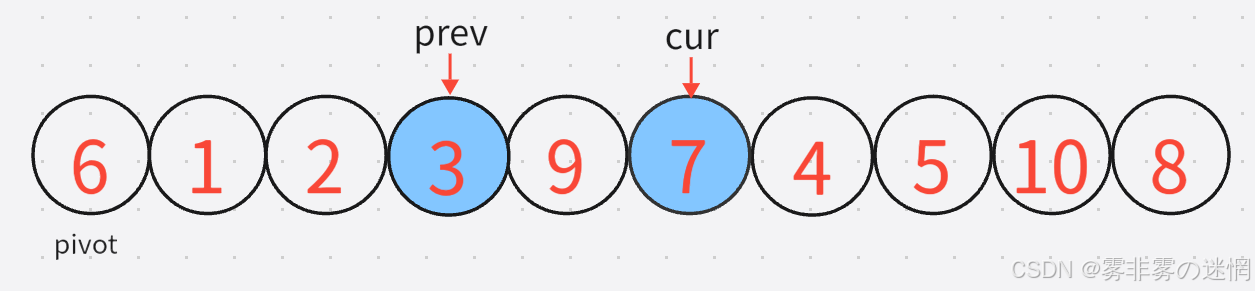
6:然后按照cur再加加,直到找到较小的元素,prev再找到较大的元素,进行交换:
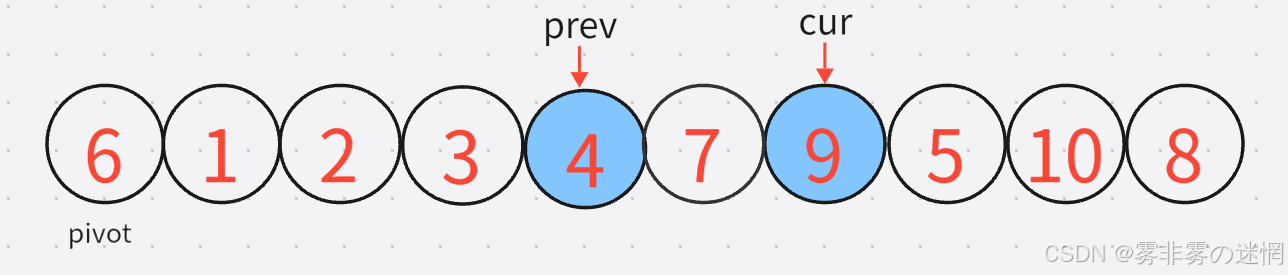
7:下一轮还是同理,先找小,再找大,再交换:
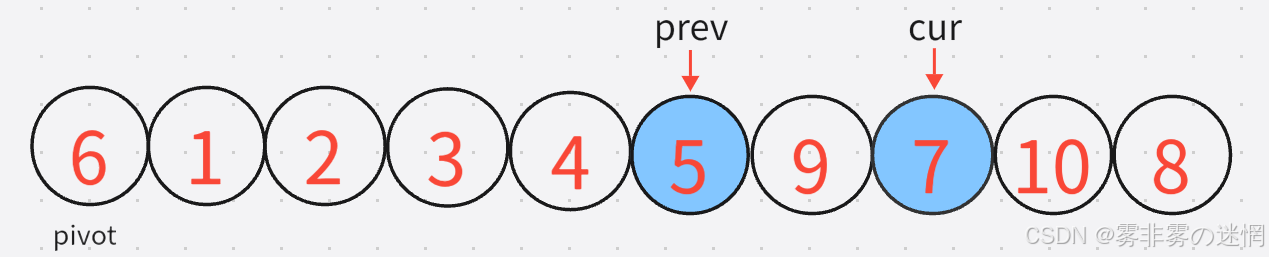
那么cur再出了数组界限,最后再将prev所指的与pivot位置进行交换,更新pivot,单趟就结束了

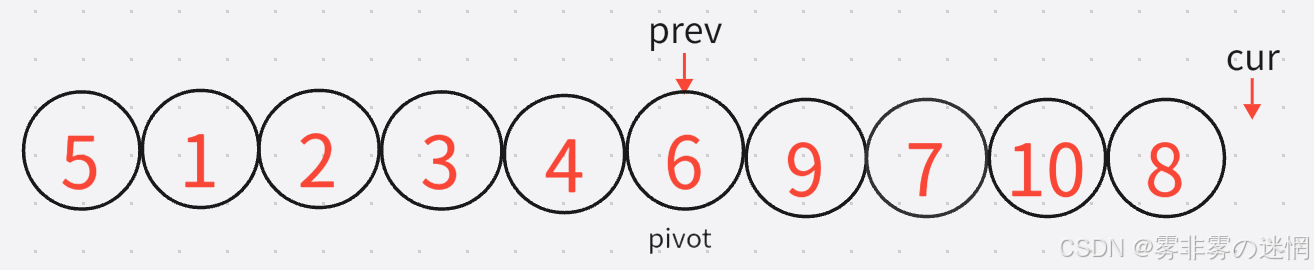
接下来这么将基准值为界限,分为左右2组进行递归就可以了!
复杂度分析:
最好时间复杂度、平均时间复杂度:
每次分区操作的时间复杂度为O(n),递归树的深度为 log n,总操作次数为O(n logn)
最坏时间复杂度:
每次分区之后,一个子数组为空,另一个子数组包含剩余的所有元素,时间复杂度为O(n^2)
空间复杂度:
递归树的深度为log n
代码实现:
单趟实现:
按照上面的原理,我们先实现单趟:
cur找小,找到之后prev再找大【prev不能超过cur】,交换之后,cur++
prev找大,找到之后交换
while (cur <= right)
{
//找小
if (arr[cur] < arr[pivot])
{
prev++;
//交换
Exchange(&arr[prev], &arr[cur]);
cur++;
}
if (arr[cur] > arr[pivot])
{
cur++;
}
}
//此时right=size,交换left与pivot下标的元素
Exchange(&arr[pivot], &arr[prev]);
//更改pivot的位置
pivot = prev;如果单趟有问题的小伙伴们可以去看看实现步骤,这里是重点讲解了单趟的实现的!
递归实现:
对于递归,我觉得很有必要强调一下思路,下面我们借助代码来分析:
int left = 0;
int right = size-1;void QuickSort(int* arr, int left, int right)
{
//递归结束条件
if(left >= right)
{
return;
}
//找基准值
int pivot= Pointer(arr, left, right);
//左区间
QuickSort(arr, left, pivot - 1);
//右区间
QuickSort(arr, pivot + 1, right);
}首先咱们的left初始位置是数组下标为0的位置,right是数组下标末尾的位置,不满足递归结束条件。我们第一次找基准值得到6,通过基准值来划分区间,也就是这里的单趟,如图划分区间:
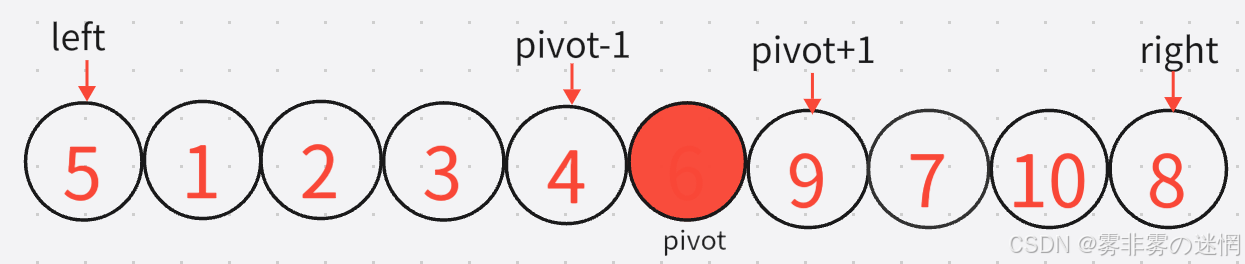
这里以左区间为例,QuickSort函数拿到的区间是【arr,left,pivot-1】 现在进入了单趟函数:
进入单趟函数Pointer之后,此时单趟函数的参数也就是【arr,left,pivot-1】,这里为什么要设置这么多的参数呢?如下面的代码
//设置基准值
int pivot = left;
//记录参数
int prev = left;
int cur = left + 1;因为我们拿到的是区间,只有左右两个端点,首先cur prev是必须要设置的,因为是新变量。
既然传过来的只是形参,我为什么要设置一个一模一样的变量prev去代替left,这是为了方便统一,避免混淆,其实不换也是可以的, 大家可以看演示效果(标红点的地方是把prev->left的):
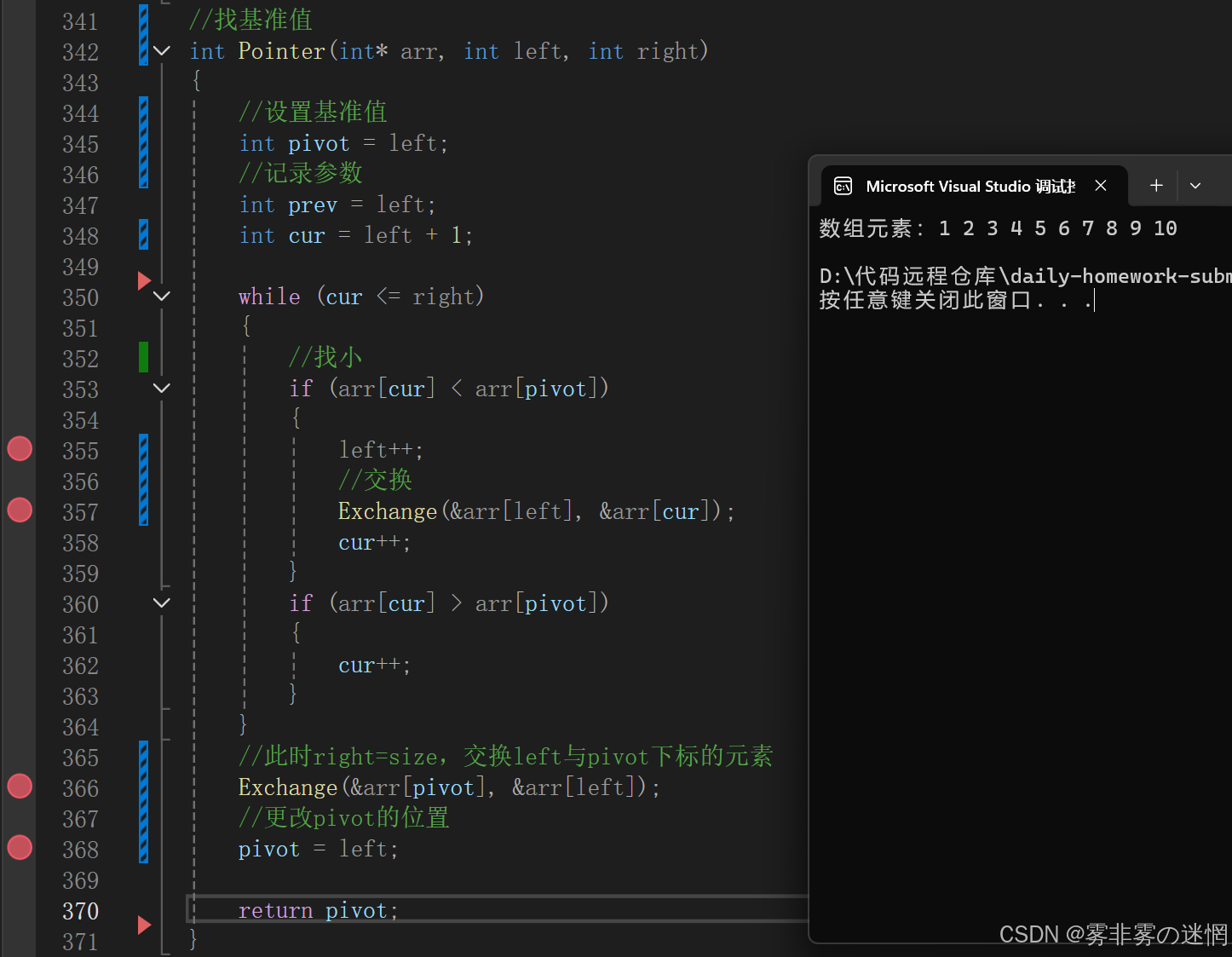
经过这个函数我们得到了新的基准值5,然后再次调用递归函数,得到新的区间是【left,pivot-1】
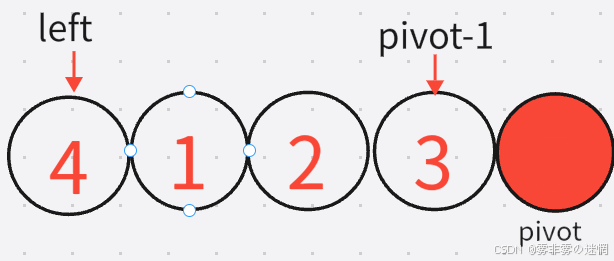
再就这样一直循环找基准值进行排序就可以了,递归结束的条件又是如何更改left 、right的?
这是第一次进入递归函数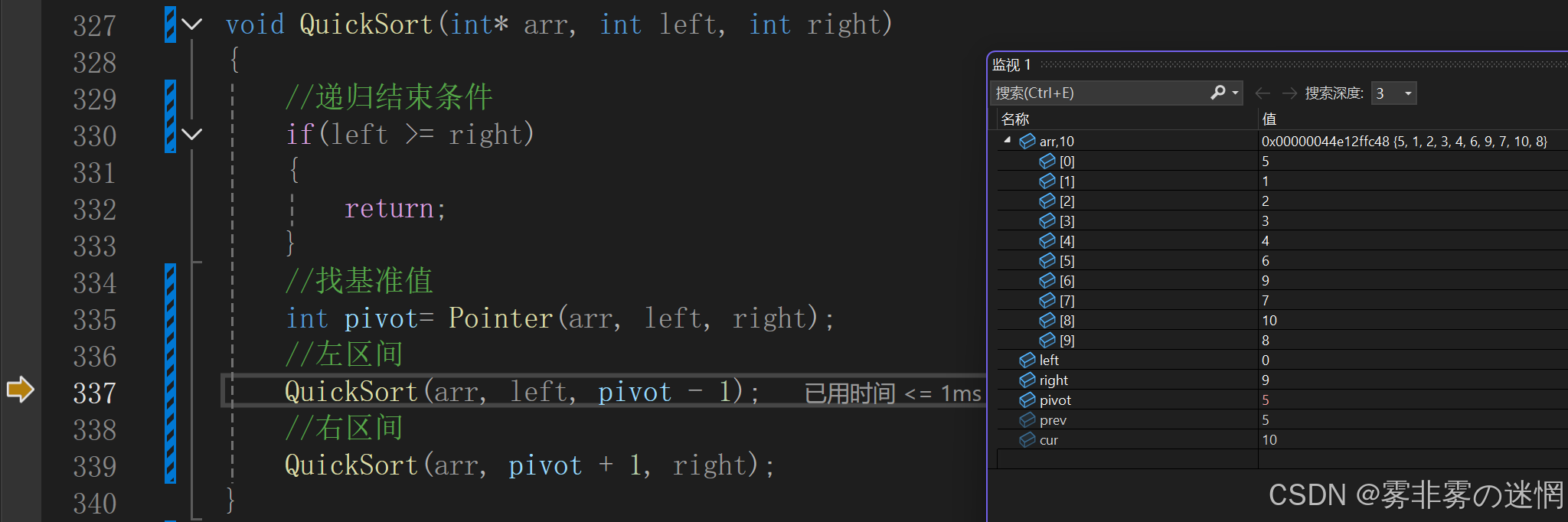
这是第二次进行递归函数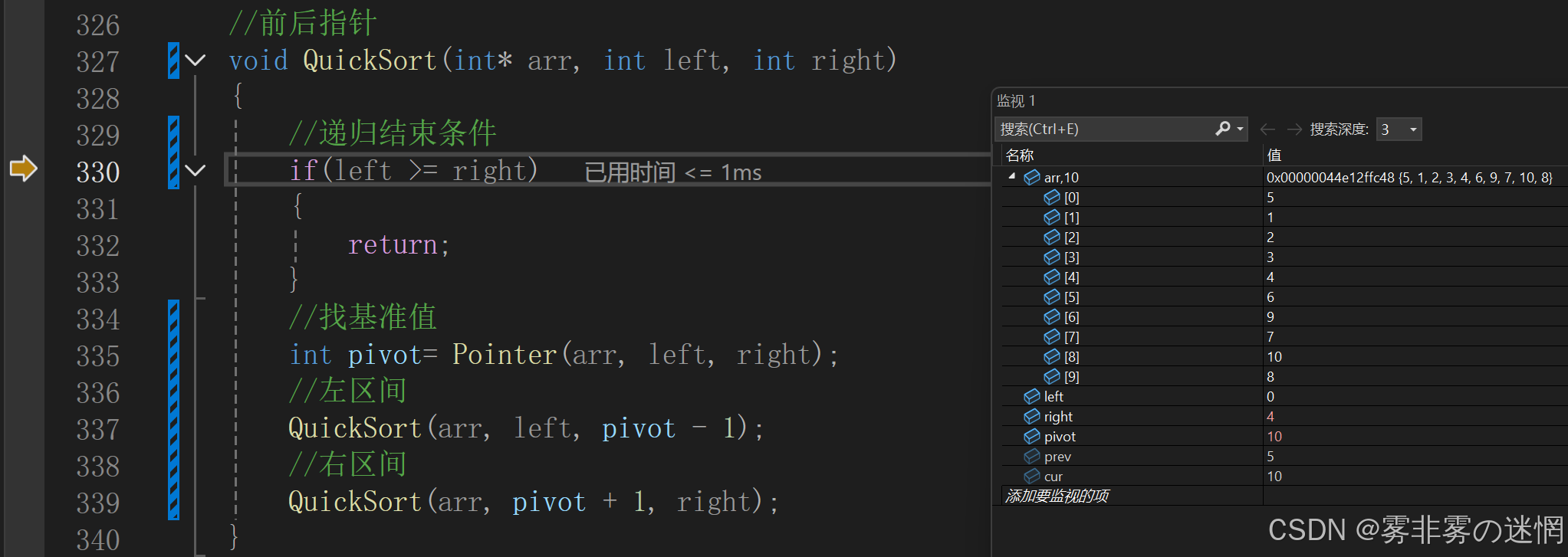
我们很明显的看到right的值发生了变化,请看下面这幅图,你就明白了,右区间递归函数同理:
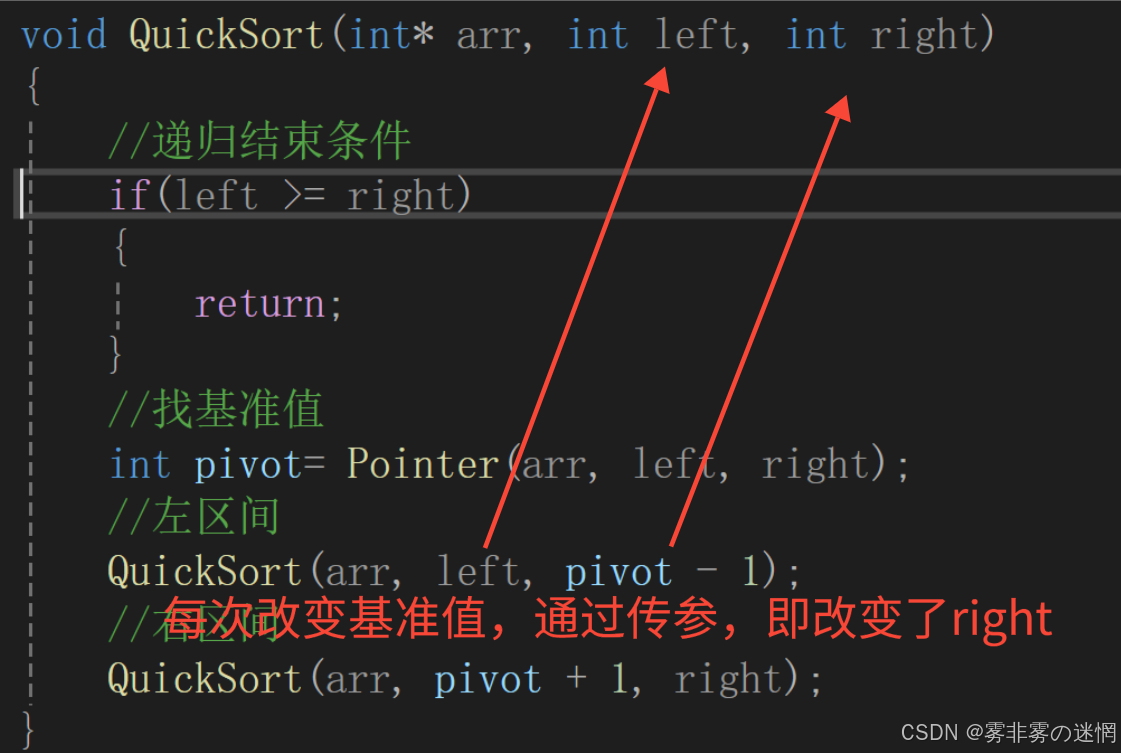
代码优化:
双指针:我们知道分组递归可以想象成【树】那样,一组变两组,两组变四组,这么循环下去,当最后一层时,它的分组是相当多的,双指针排序虽然平均时间复杂度达到O(n logn),但是它主要的开销还是在后面的分组,越往后分的越多。
插入排序:而插入排序虽然整体来说时间复杂度达到O(n^2),但是它对几乎有序的子数组来说效率很高,所以我们如果将二者结合,取一个界线,当剩余的元素到达某个阈值时,切换为插入排序,这是很常见的一种优化。
我们一般取10左右的数字为阈值。这里只需要看剩余数组元素个数即可,用分支判断:
我们总共的数组元素个数是right+1,那么剩余的元素个数不就是right+1-left吗!(如下图)
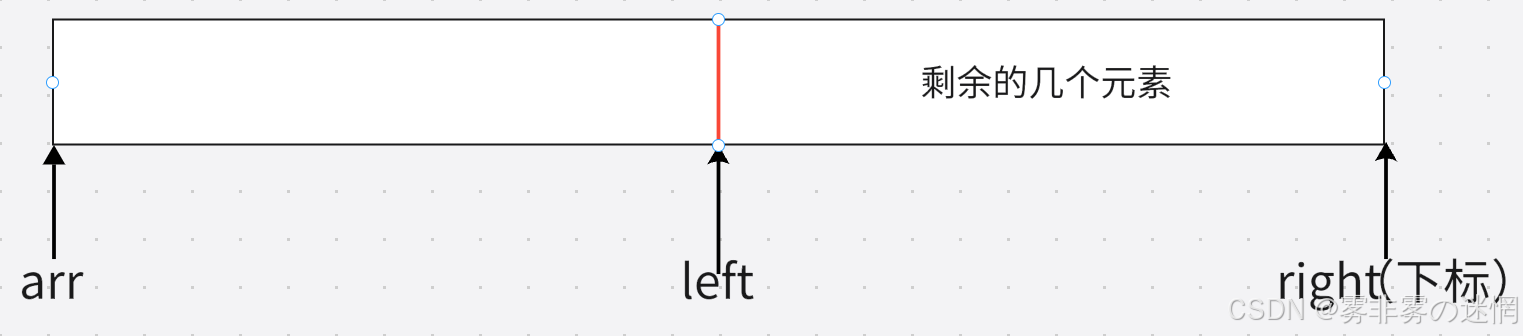
下面我来解释这个区间的开始位置应该如何表示:
首先我们的arr是数组名,如果我们直接传数组名过去是错误的,因为我们不能保证剩余的元素一定是从数组的起始位置开始的,如下图我们得到剩余元素的开始应该是arr+left
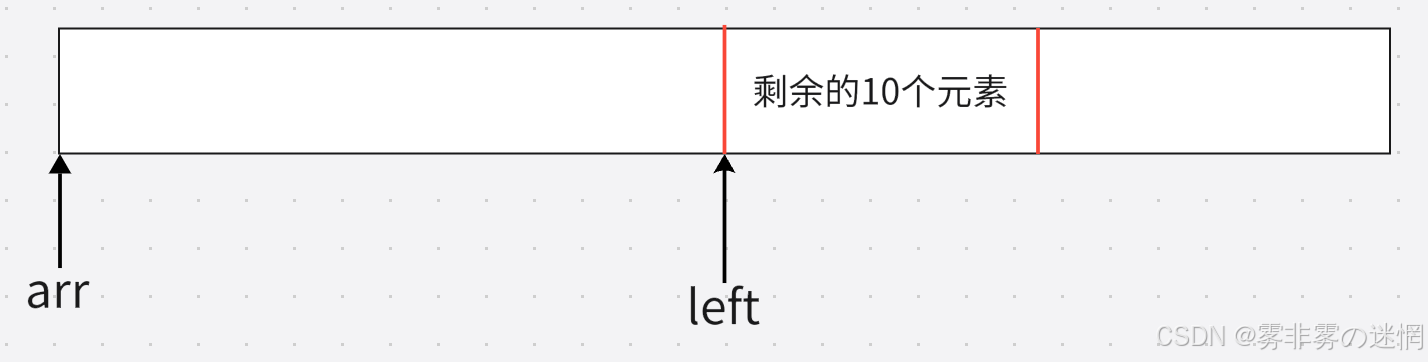
下面是优化代码
void QuickSort(int* arr, int left, int right)
{
//递归结束条件
if(left >= right)
{
return;
}
if ((right - left + 1) > 10)
{
//找基准值
int pivot = Pointer(arr, left, right);
//左区间
QuickSort(arr, left, pivot - 1);
//右区间
QuickSort(arr, pivot + 1, right);
}
else
//到达阈值时选用直接插入排序
Insert(arr+left, right - left + 1);
}
优缺点分析:
首先是时间复杂度,双指针排序的时间复杂度均为O(n logn),这是一个很大的优化,双指针可以在单次遍历中实现快速排序,减少了冗杂的操作,适用范围广,是比较推荐的一种快排方法,当然需要先理解哈。并且双指针还可以应用在两数之和、去重、合并区间等不同的其它问题,点赞!
快排(双指针·非递归)
首先我们已经学会了递归的形式去走快排,为什么还要去学习非递归?
我们平时写递归代码,数据还比较少,如果我们将递归放在几百万、上千万的数据里面呢?在上面我们只用了10个数据去走递归,每一层是上一层的两倍,呈现倍数的增长,那么它在实际应用中是不推荐的,数据如果太多太多,递归深度也就越深,容易发生栈溢出,因此递归方式我们能不用就不要用,在以后工作时,一般递归的代码会让我们改成非递归的,这也是在避免以后出现隐患
算法思想:
我们知道快排双指针的方式是通过 基准值 来实现对数组的分组,通过递归一步步调用函数来完成分组排序,那么它的本质是什么?
我们每次调用函数,改变的是它的参数,也就是改变它的区间,每个组一直通过基准值分下去:
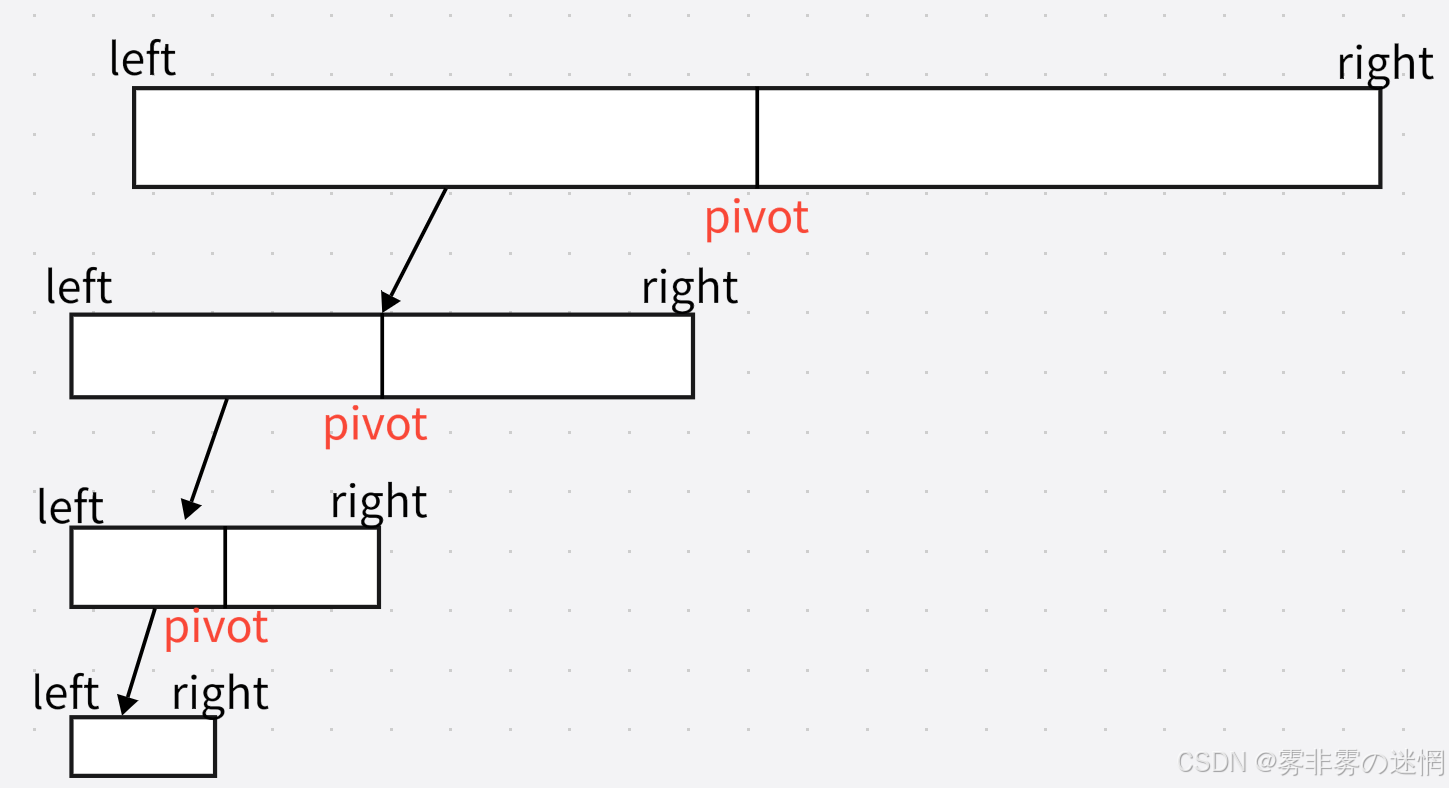
我们把它的区间存起来,每次改变获取不一样的区间,再传参给排序函数就达到了非递归的效果!
我们可以通过栈和队列来存储分组的区间,每次调用栈和队列的元素来进行传参给排序函数
在这里我推荐栈来实现,原因:
首先用队列也是可以的,这样就是一层一层的去排序了(层序遍历),如果我们换栈去实现,就是先将左边的分组分完了,再去分组右边(前序遍历),且栈的应用比较广泛,因此我们在这里选择栈去存储分组区间
实现步骤:
栈的存储特点:先进后出,就像将数据一个个放进容器
按照上面的思路,我们先从左边的分组开始:

我们发现左区间的left是不变的,变的只有pivot-1,也就是基准值在不断变化,因此我们可以通过每计算一个基准值,就存入栈里面,再拿出来,然后再通过出栈的值去做左区间的参数
右边的区间是只改变left,即右边区间是将基准值pivot+1作为每次参数的改变,如图:

代码实现:
左区间:
按照原理,先找基准值,再来实现对基准值的入栈,再出栈作为参数:
//找基准值
int pivot = Pointer(arr, left, cur);
//左区间的基准值入栈
Enter(s, pivot);
//再出栈,cur作为右边不断变化的区间
cur = Out(s);
//出栈元素作为左区间参数
Pointer(arr, left, cur - 1);需要注意:我们此时已经获得了基准值,就不需要递归函数了,注意切换函数。这样我们就完成了单趟,我们外面再套一个循环,就完成了左边分组的排序,循环的条件就是当区间剩余一个元素时就停下【因为一个元素表示它已经是正确位置了】即right-left+1==0 注意:左边排序我们需要记录right,因为我们的参数是不断变化的,需要用一个变量去代替right,效果展示如下:
//标记
int cur = right;
while ( ( cur - left + 1) > 1 )
{
//找基准值
int pivot = Pointer(arr, left, cur);
//左区间的基准值入栈
Enter(s, pivot);
//再出栈,cur作为右边不断变化的区间
cur = Out(s);
//出栈元素作为左区间参数
Pointer(arr, left, cur - 1);
}
此时数组左边的数据通过非递归的方式已经完成排序了,如下图展示: 
右区间:
完成了左边,我们直接复制一下代码,稍微改动就行了【注意右边是改变left】,如下代码展示:
//标记
int prev = left;
while ((right - prev + 1) > 1)
{
//找基准值
int pivot = Pointer(arr, prev, right);
//左区间的基准值入栈
Enter(s, pivot);
//再出栈
prev = Out(s);
//出栈元素作为左区间参数
Pointer(arr, prev + 1, right);
}
整体代码展示:
void QuickSort(int* arr, Stack* s, int left, int right)
{
//标记
int cur = right;
while ( ( cur - left + 1) > 1 )
{
//找基准值
int pivot = Pointer(arr, left, cur);
//左区间的基准值入栈
Enter(s, pivot);
//再出栈
cur = Out(s);
//出栈元素作为左区间参数
Pointer(arr, left, cur - 1);
}
//标记
int prev = left;
while ((right - prev + 1) > 1)
{
//找基准值
int pivot = Pointer(arr, prev, right);
//左区间的基准值入栈
Enter(s, pivot);
//再出栈
prev = Out(s);
//出栈元素作为左区间参数
Pointer(arr, prev + 1, right);
}
}int Pointer(int* arr, int left, int right)
{
//设置基准值
int pivot = left;
//记录参数
int prev = left;
int cur = left + 1;
while (cur <= right)
{
//找小
if (arr[cur] < arr[pivot])
{
prev++;
//交换
Exchange(&arr[prev], &arr[cur]);
cur++;
}
if (arr[cur] > arr[pivot])
{
cur++;
}
}
//此时right=size,交换left与pivot下标的元素
Exchange(&arr[pivot], &arr[prev]);
//更改pivot的位置
pivot = prev;
return pivot;
}优缺点分析:
我们最大的成功就是将递归改成了非递归,通过循环去实现整体的排序,这里避免了栈溢出,在未来我们去工作时,能不写递归就尽量不要写递归,出现递归能改则改。对于数据大的环境下,递归的深度很可怕的!而循环则不同,它不会出现栈溢出,只需要控制循环的条件即可
小编寄语
见证了Hoare大佬的排序思想,又衍生出了双指针的方式,感叹如此精妙的改进!排序的道路没有结束,此篇是难点的第一篇,领教双指针的魅力,快排和归并作为效率很高的两种排序,能够随时手撕代码是对这些思想的真正领悟,让排序算法成为技术世界里不停歇的实验场,预知归并如何,详见下篇!