Prometheus 环境搭建
1.prometheus 简介
Prometheus是基于go语言开发的一套开源的监控、报警和时间序列数据库的组合,是由SoundCloud公司开发的开源监控系统,Prometheus于2016年加入CNCF(Cloud Native Computing Foundation,云原生计算基金会),2018年8月9日prometheus成为CNCF继kubernetes 之后毕业的第二个项目,prometheus在容器和微服务领域中得到了广泛的应用,其特点主要如下:
使用key-value的多维度(多个角度,多个层面,多个方面)格式保存数据
数据不使用MySQL这样的传统数据库,而是使用时序数据库,目前是使用的TSDB
支持第三方dashboard实现更绚丽的图形界面,如grafana(Grafana 2.5.0版本及以上)
组件模块化
不需要依赖存储,数据可以本地保存也可以远程保存
平均每个采样点仅占3.5 bytes,且一个Prometheus server可以处理数百万级别的的metrics指标数据。
支持服务自动化发现(基于consul等方式动态发现被监控的目标服务)
强大的数据查询语句功(PromQL,Prometheus Query Language)
数据可以直接进行算术运算
易于横向伸缩
众多官方和第三方的exporter(“数据”导出器)实现不同的指标数据收集
1.1 为什么使用Prometheus
容器监控的实现方对比虚拟机或者物理机来说比大的区别,比如容器在k8s环境中可以任意横向扩容与缩容,那么就需要监控服务能够自动对新创建的容器进行监控,当容器删除后又能够及时的从监控服务中删除,而传统的zabbix的监控方式需要在每一个容器中安装启动agent,并且在容器自动发现注册及模板关联方面并没有比较好的实现方式。
1.2 Prometheus 架构图
prometheus server:主服务,接受外部http请求,收集、存储与查询数据等
prometheus targets: 静态收集的目标服务数据
service discovery:动态发现服务
prometheus alerting:报警通知
push gateway:数据收集代理服务器(类似于zabbix proxy)
data visualization and export: 数据可视化与数据导出(访问客户端)
2. 部署Prometheus
2.1 docker-compose 部署
# 创建prometheus目录
mkdir prometheus && chmod 777 prometheus
# 创建数据挂载目录
cd prometheus && mkdir grafana_data prometheus_data && chmod 777 grafana_data prometheus_data
version: "3.7"
services:
node-exporter:
image: prom/node-exporter:latest
container_name: "node-exporter"
ports:
- "9100:9100"
restart: always
prometheus:
image: prom/prometheus:latest
container_name: "prometheus"
restart: always
ports:
- "9090:9090"
volumes:
- "./prometheus.yml:/etc/prometheus/prometheus.yml"
- "./prometheus_data:/prometheus"
grafana:
image: grafana/grafana:7.3.6
container_name: "grafana"
ports:
- "3000:3000"
restart: always
volumes:
- "./grafana_data:/var/lib/grafana"
创建prometheus.yml
root@promethues(192.168.1.20)/data/prometheus>ls
docker-compose.yml grafana_data prometheus_data prometheus.yml
root@promethues(192.168.1.20)/data/prometheus>cat prometheus.yml
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'node-exporter'
scrape_interval: 5s
metrics_path: /metrics
static_configs:
- targets: ['192.168.1.10:9100','192.168.1.11:9100']
root@promethues(192.168.1.20)/data/prometheus>
2.2 运行docker-compsoe
root@promethues(192.168.1.20)/data/prometheus>docker-compose up -d
[+] Running 3/0
✔ Container node-exporter Running 0.0s
✔ Container grafana Running 0.0s
✔ Container prometheus Running 0.0s
root@promethues(192.168.1.20)/data/prometheus>
2.3 部署node_exporter
安装 Node Exporter 用于收集各 node 主机节点上的监控指标数据,监听端口为9100
二进制安装最为方便,要是部署在docker里也很方便,前提是安装docker
所以在node节点我采用的是二进制安装,并整理成脚本,一键安装
root@k8s-master(192.168.1.10)~/node_export>ls
install.sh node_exporter.service* node_exporter.tar.gz
root@k8s-master(192.168.1.10)~/node_export>netstat -tnlp |grep 9100
tcp6 0 0 :::9100 :::* LISTEN 972/node_exporter
root@k8s-master(192.168.1.10)~/node_export>
#安装链接
链接:https://pan.baidu.com/s/1wLVWxOhhEUz0q8vekH4e5g?pwd=7rp8
提取码:7rp8
2.4 grafana插件管理
#在线安装 进入容器
bash-5.0$ grafana-cli plugins list-remote # 查看插件目录
bash-5.0$ grafana-cli plugins install grafana-piechart-panel # 安装饼图插件
installing grafana-piechart-panel @ 1.6.4
from: https://grafana.com/api/plugins/grafana-piechart-panel/versions/1.6.4/download
into: /var/lib/grafana/plugins
✔ Installed grafana-piechart-panel successfully
Restart grafana after installing plugins . <service grafana-server restart>
bash-5.0$
# 离线安装
# 饼图插件未安装,需要提前安装
https://grafana.com/grafana/plugins/grafana-piechart-panel
#将下载下来的挂载到/var/lib/grafana/plugins目录中就行
# unzip grafana-piechart-panel-v1.3.8-0-g4f34110.zip
# mv grafana-piechart-panel-4f34110 grafana-piechart-panel
root@promethues(192.168.1.20)/data/prometheus/grafana_data/plugins>pwd
/data/prometheus/grafana_data/plugins
3. 访问web界面

3.1 dashboard 菜单说明
#一级目录解析
Alerts #Prometheus的告警信息菜单
Graph #Prometheus的图形展示界面,这是prometheus默认访问的界面
Status #Prometheus的状态数据界面
Help #Prometheus的帮助信息界面
#Status子菜单,在Status菜单下存在很多的子选项,其名称和功能效果如下:
Runtime & Build Information 服务主机的运行状态信息及内部的监控项基本信息
Command-Line Flags 启动时候从配置文件中加载的属性信息
Configuration 配置文件的具体内容(yaml格式)
Rules 查询、告警、可视化等数据分析动作的规则记录
Targets 监控的目标对象,包括主机、服务等以endpoint形式存在
Service Discovery 自动发现的各种Targets对象列表

3.2 验证node exporter web界面


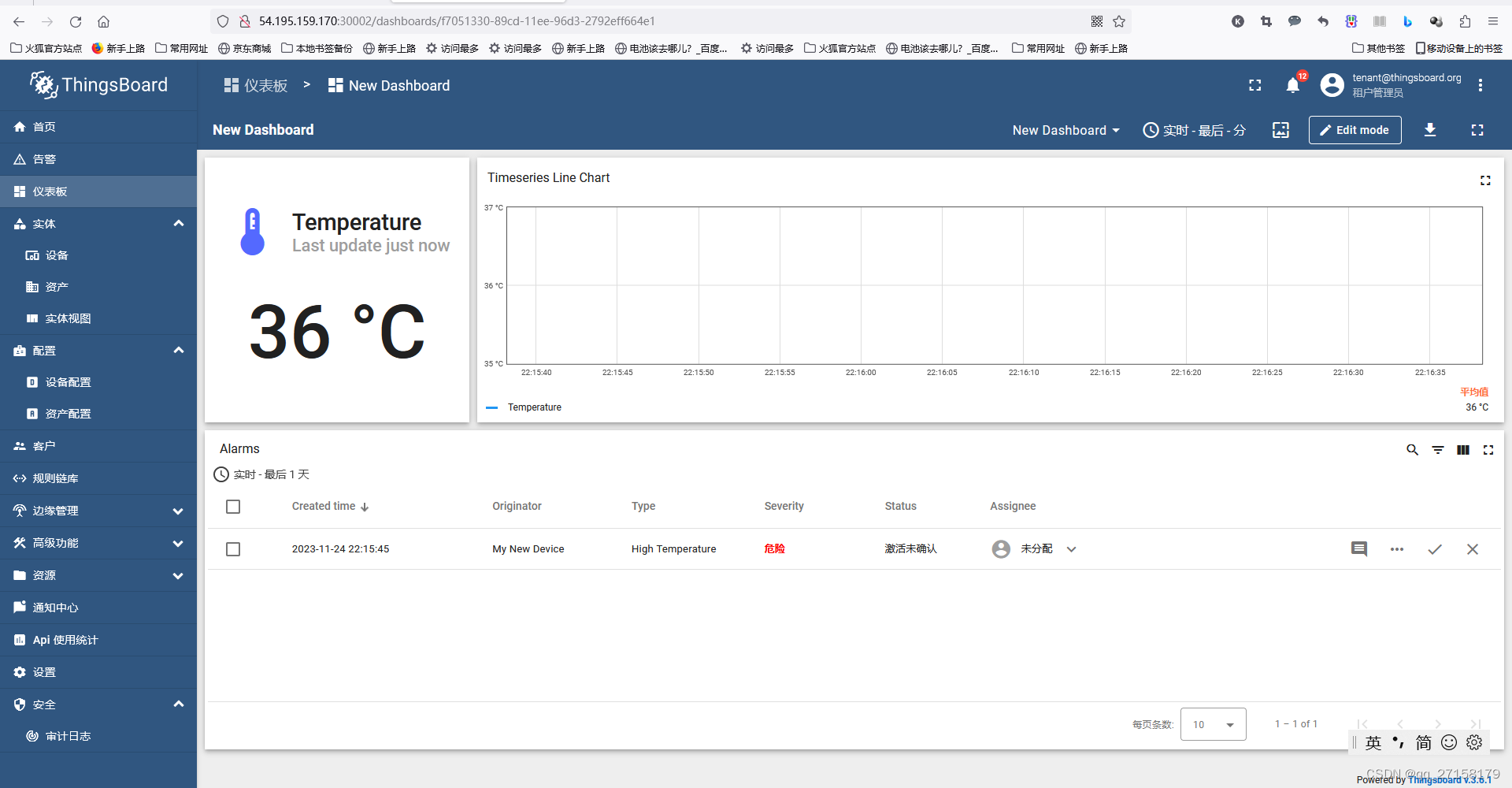
3.3 grafana图形化界面

登录用户和密码都为admin
登录成功后会立即修改密码
4. Exporters
4.1 Node Exporter 的指标
- 常用的各指标
- node_cpu_seconds_total
- node_memory_MemTotal_bytes
- node_filesystem_size_bytems{mount_point=PATH}
- node_system_unit_state{name=}
- node_vmstat_pswpin: 系统每秒从磁盘读到内存的字节数
- node_vmstat_pswpout: 系统每秒钟从内存写到磁盘的总字节数
4.2 适用于主机监控的USE方法
- USE是使用率(Utilization)、饱和度(Saturation) 和错误 (Error)的缩写,由Netflix的内核和性能工程师Brendan Gregg开发;
- USE方法可以概括为:针对每个资源,检查使用率、饱和度和错误;
- 资源:系统的一个组件,在USE中,它指的是一个传统意义上的物理服务器组件,如CPU、内存和磁盘等;
- 使用率:资源忙于工作的平均时间,它通常用随时间变化的百分比进行表示;
- 饱和度:资源排队工作的指标,无法再处理额外的工作;通常用队列长度表示错误:资源错误事件的计数;
- 对CPU来说,USE通常意味着如下概念
- CPU使用率随时间的百分比;
- CPU饱和度,等待CPU的进程数;
- 错误,通常对CPU不太有影响;
- 对内存来说,USE的意义相似
- 内存使用率随时间的百分比;
- 内存饱和度,可通过监控swap进行测量;
- 错误,通常不太关键;
- USE方法可以概括为:针对每个资源,检查使用率、饱和度和错误;
4.3 简单实例
每台主机CPU在5分钟内的平均使用率
(1-avg(irate(node_cpu_seconds_total{mode=‘idle’}[5m])) by(instance)) * 100

#单位换算
node_memory_MemFree_bytes / (1024 * 1024)
#可用内存占用率
node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes * 100
#内存使用率
(node_memory_MemTotal_bytes - node_memory_MemFree_bytes) /
node_memory_MemTotal_bytes * 100
#磁盘使用率
(node_filesystem_size_bytes{mountpoint="/"} -
node_filesystem_free_bytes{mountpoint="/"})
/node_filesystem_size_bytes{mountpoint="/"} * 100
#阈值判断
(node_memory_MemTotal_bytes - node_memory_MemFree_bytes) /
node_memory_MemTotal_bytes > 0.95
#内存利用率是否超过80
( 1 - node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes ) * 100 > bool
80
prometheus_http_requests_total > bool 1000 #布尔值,当超过1000为1,否则为0
#注意:
对于比较运算符来说,条件成立有结果输出,否则没有结果输出
使用bool修改符后,布尔运算不会对时间序列进行过滤,而是直接依次瞬时向量中的各个样本数据与标量的比
较结果0或者1。从而形成一条新的时间序列。