前言
以前我曾疑惑,对于非结构化的内容,如一张图片或一段视频,如何实现搜索呢?图片或视频作为二进制文件,我们如何将其转化为可搜索的数据并存储起来,然后在搜索时将其还原呢?
后来我发现,实际上我们可以将非结构化的内容转化为结构化的内容,然后进行存储。这样,我们就可以对其进行搜索了。如何实现这一转化呢?向量化是非结构化内容转化为结构化内容的关键。
向量在数学和物理中表示大小和方向。它由一组有序的数值组成,比如[0.2123, 0.23, 0.213]。这些数值代表了向量在每个坐标轴上的分量。在AI中,向量可以用来表示任何事物,如图像、视频、音频、文本等。向量是数据科学中最重要的概念之一,它帮助我们将非结构化数据转换为结构化数据,以便进行分析和处理。
我们可以使用多维度向量来表述某个对象或事物的属性或特征,然后再借助一些向量检索的方法,如内积(IP),欧式距离(L2)或者余弦相似度(COSINE)算法来进行搜索。常用的图片搜索、短视频搜索以及推荐系统都是基于向量进行的。那么这些向量是如何存储的呢?存储向量的数据库与传统的数据库有什么区别呢?今天我要给大家介绍的是一款存储向量的数据库——腾讯云向量数据库(Tencent Cloud VectorDB)。
向量数据库
向量数据库是一种专门用于存储和检索高维向量的数据库,适用于处理图像、视频、音频、文本等非结构化数据。随着非结构化数据搜索需求的不断增长,向量数据库在近年来得到了广泛应用。腾讯云向量数据库(Tencent Cloud VectorDB)是一种全托管的自研企业级分布式数据库服务,专为存储、检索、分析多维向量数据而设计。
与传统数据库不同,向量数据库借助向量检索技术,通过计算向量间的相似度来进行数据检索。这种检索方式在处理非结构化数据时具有显著的优势,可以更加准确地匹配用户的查询需求。腾讯云向量数据库(Tencent Cloud VectorDB)采用了先进的向量检索技术,并针对多维向量数据进行了优化,以提供高效、准确的检索服务。下面让我们详细了解一下它的组成和特征。
逻辑层级
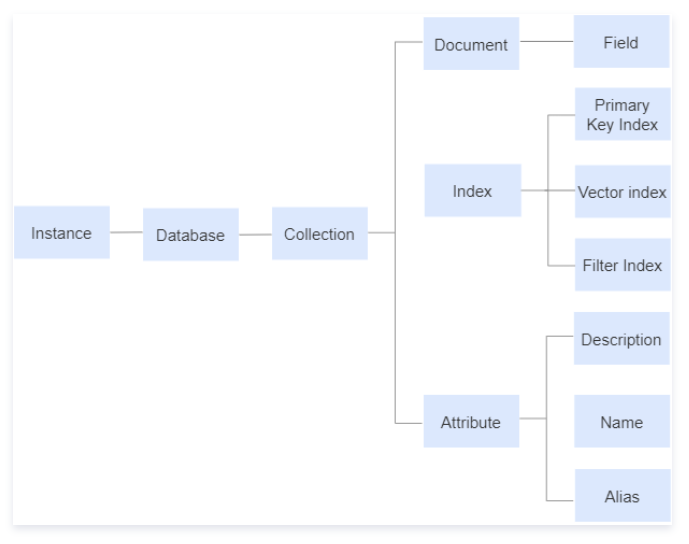
要了解Tencent Cloud VectorDB,就要先了解它的逻辑层级,逻辑层级代表了它存储数据的结构,它具有三个逻辑层级,分别是Database、Collection、Document。一个数据库实例可以存在多个database,这一点与传统的数据库一致,一个database可以存在多个collection, 这里的collection你可以简单理解为mysql中的中一张表,由于向量数据库不属于SQL数据库,在创建表时,自然也与传统SQL数据库不一样,下面会讲解如何创建collection。 一个collection可以存在多个document,document就类似是一张表的多条记录,行。
下面的图片解释了Tencent Cloud VectorDB的逻辑层级。
索引
逻辑层级代表了数据的层级结构,而向量索引则是用于快速搜索的基础。
Tencent Cloud VectorDB目前支持多种索引类型,分别是用于快速查找特定行的主键索引Primary Key Index,和用于快速查找相似向量的向量索引Vector Index(向量索引又分为FLAT,HNSW,IVF 系列,详情描述可以查阅官方文档),以及建立在标量字段的Filter索引 Filter Index。
基于向量的相似度算法
逻辑层级是数据的存储层级,而索引是为了加快数据的搜索,那么对于向量的搜索Tencent Cloud VectorDB又支持那些算法那?
目前支持了比较主流的三种算法分别是内积(IP),欧式距离(L2),余弦相似度(COSINE)
(注意:在创建 Collection 时,就需指定向量的索引类型(如 HNSW 等)与 相似度计算方法,而不是搜索时。)
内积(IP):
全称为 Inner Product,内积也称点积,计算结果是一个数。它计算两个向量之间的点积(内积),其计算公式如下所示:
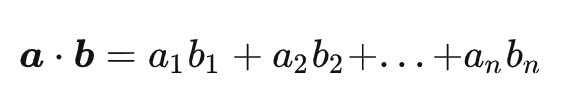
欧式距离(L2):
欧式距离(L2)全称为 Euclidean distance,指欧几里得距离。它计算两个向量点在空间中的直线距离。其计算公式如下所示:
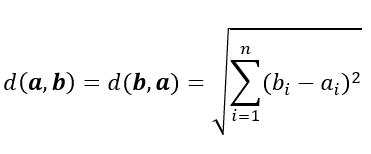
余弦相似度(COSINE):
余弦相似度(Cosine Similarity)算法,是一种常用的文本相似度计算方法。它通过计算两个向量在多维空间中的夹角余弦值来衡量它们的相似程度。其计算公式如下所示:
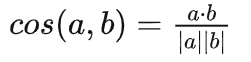
需要注意的是 向量索引与相似算法是 影响搜索结果的准确性的两大因素,我们在Collection时要根据具体的数据和业务选择合适的索引和算法。
腾讯云向量数据库的申请,实例管理
通过上面的概念介绍和名称解释,你是不是已经迫不及待地想要体验一下Tencent Cloud VectorDB。那么下面就跟着我一起来体验一下Tencent Cloud VectorDB的功能吧。
申请使用
你可以官方的内测申请,来申请使用Tencent Cloud VectorDB。试用期间费用都是免费的,包括数据存储,Embedding Token的消耗,外网访问。内测期间,免费试用时长1个月。
内测资格发放后,登录腾讯云控制台,进入向量数据库实例列表
你会看到有一条实例已经创建。
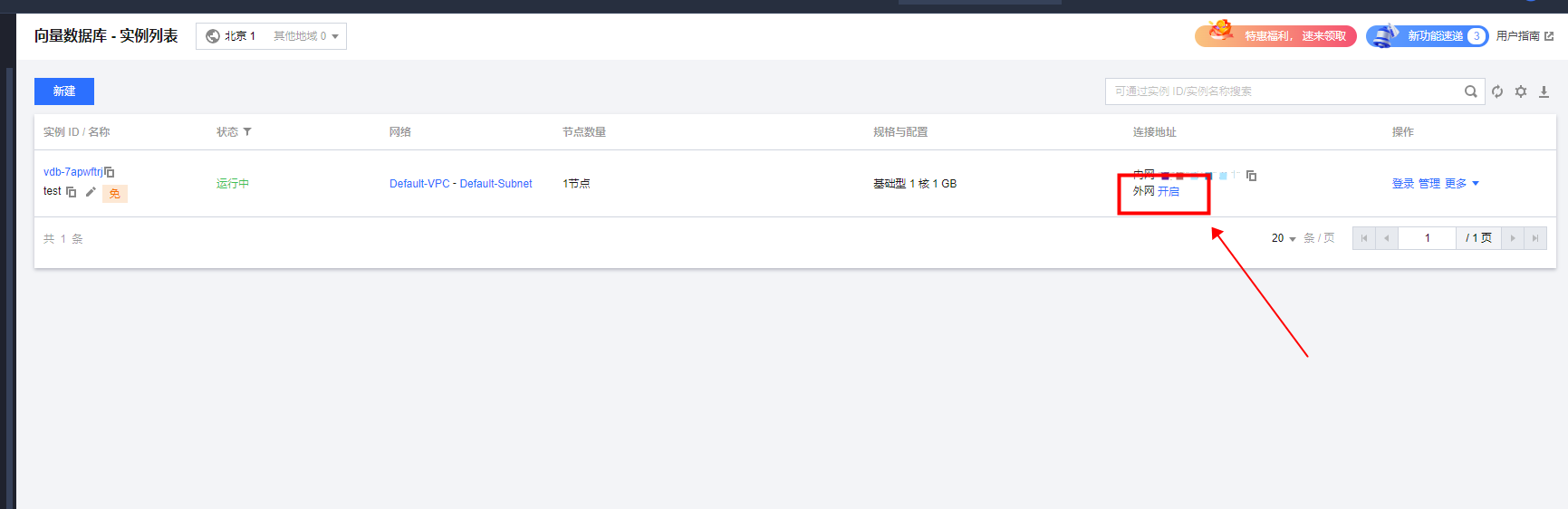
如果没有的话,尝试切换其他区域。
使用的实例,规格是:基础型 1 核 1 GB,总磁盘容量20GB。默认不开启外网。
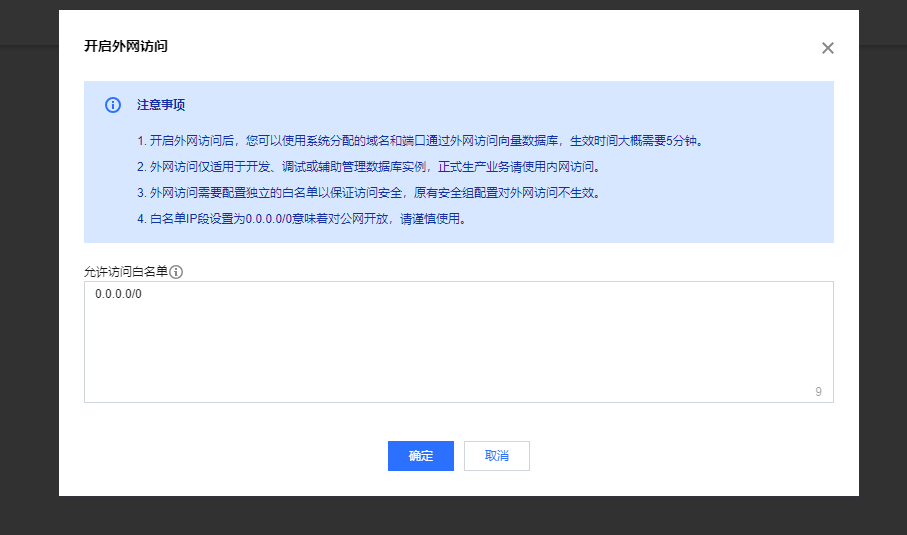
如要开启外网功能,点击实例列表中的 外网:开启按钮。然后填入0.0.0.0/0。注意生产环境不建议这样填。
实例监控
点击实例ID或者名,除了可以查看实例的详情,还会看到实例的实时监控。
如下: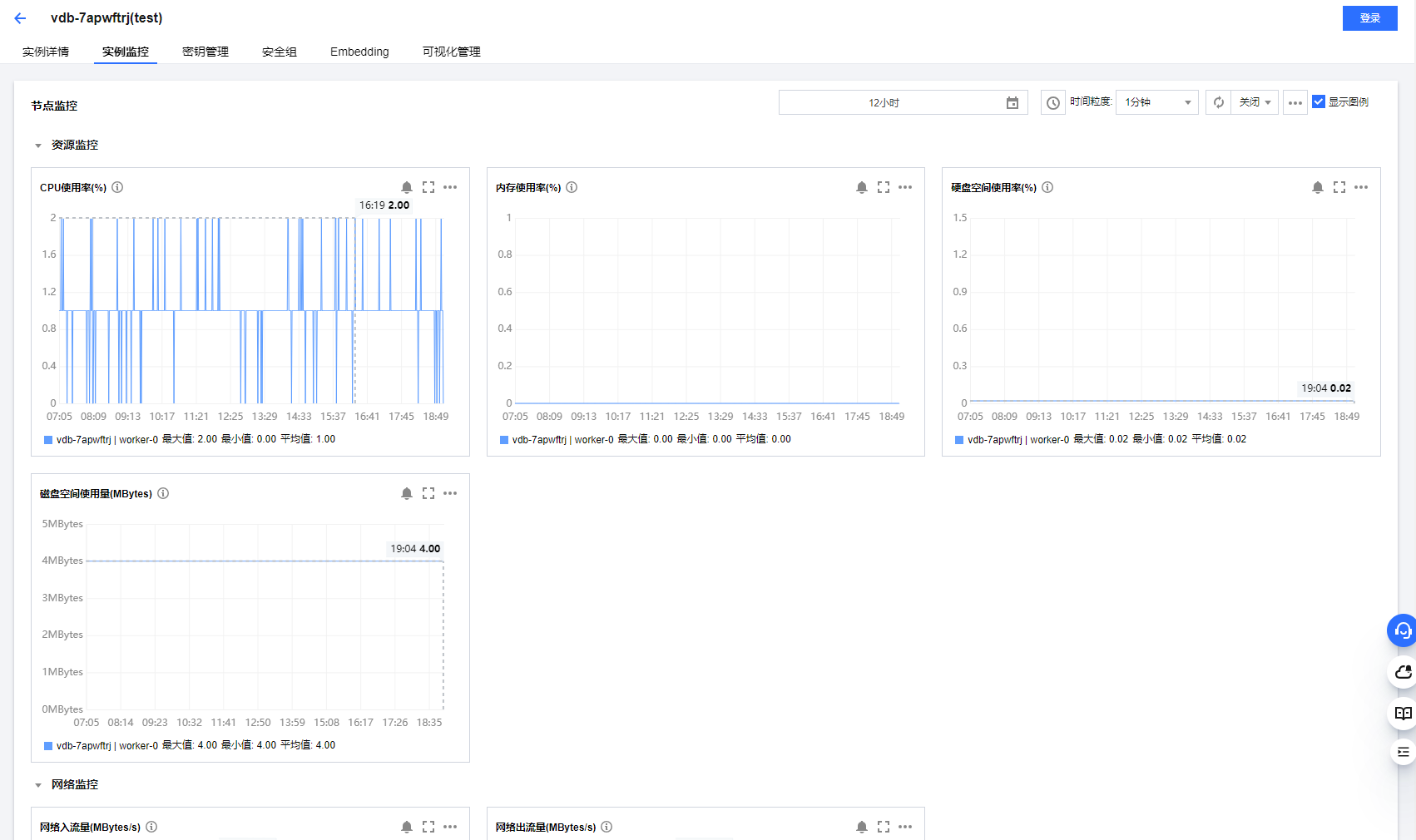
监控的类型有很多,CPU使用率,内存使用率,硬盘空间使用率,磁盘空间使用量,
网络监控包括网络流入浏览,网络流出流量。
请求监控,响应监控。
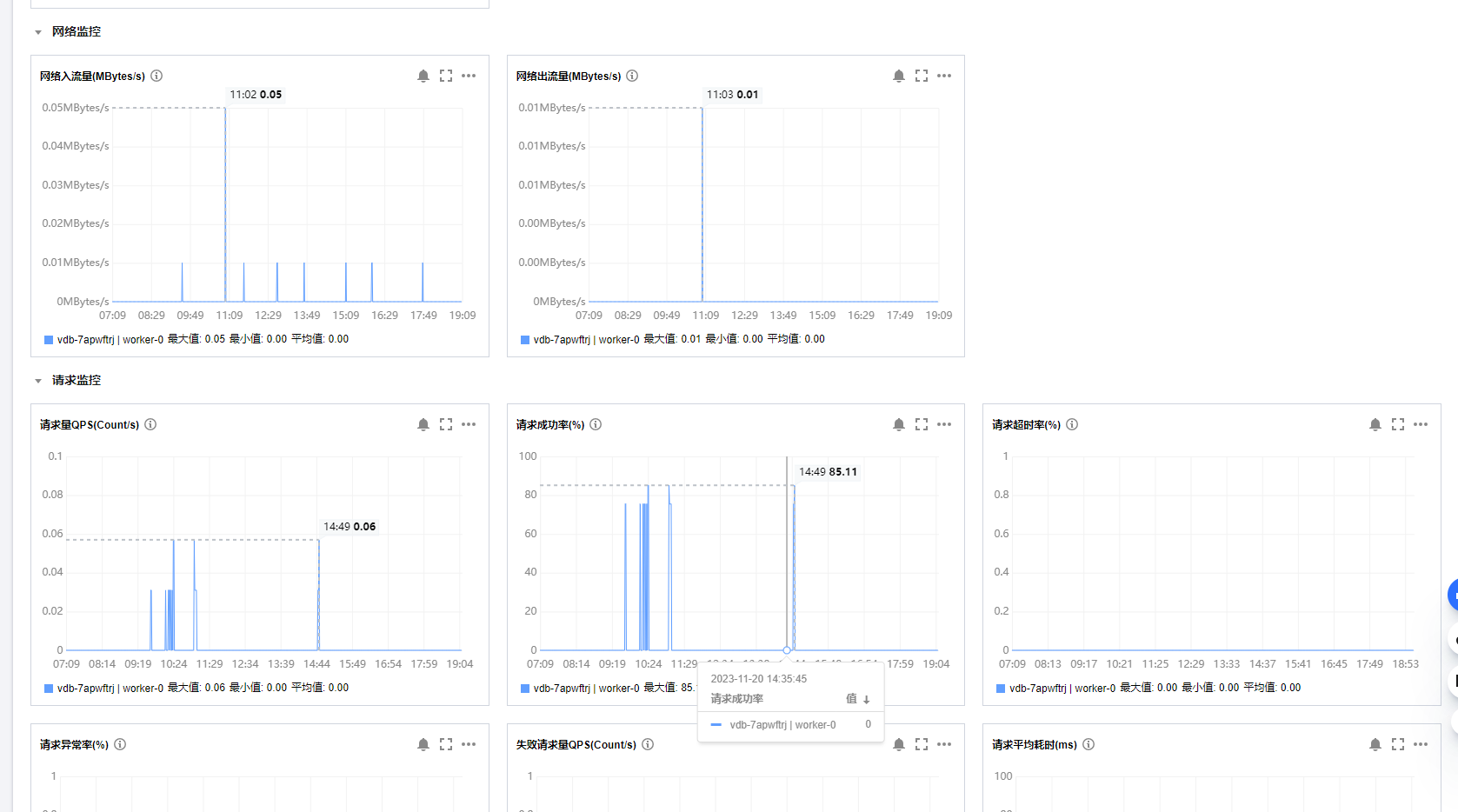
监控的还是比较全面的。
数据库可视化管理,DMC的使用
Tencent Cloud VectorDB是使用DMC 向量数据库客户端进行可视化管理,它提供链接数据库实例,创建Database,创建Collection,以及增删改查Document等一系列常规操作。
你可以实例详情的 登录按钮进入到DMC的登录页面
进入登录页面后,你需要正确选择数据库实例所在的区域,并填入账号和密码。
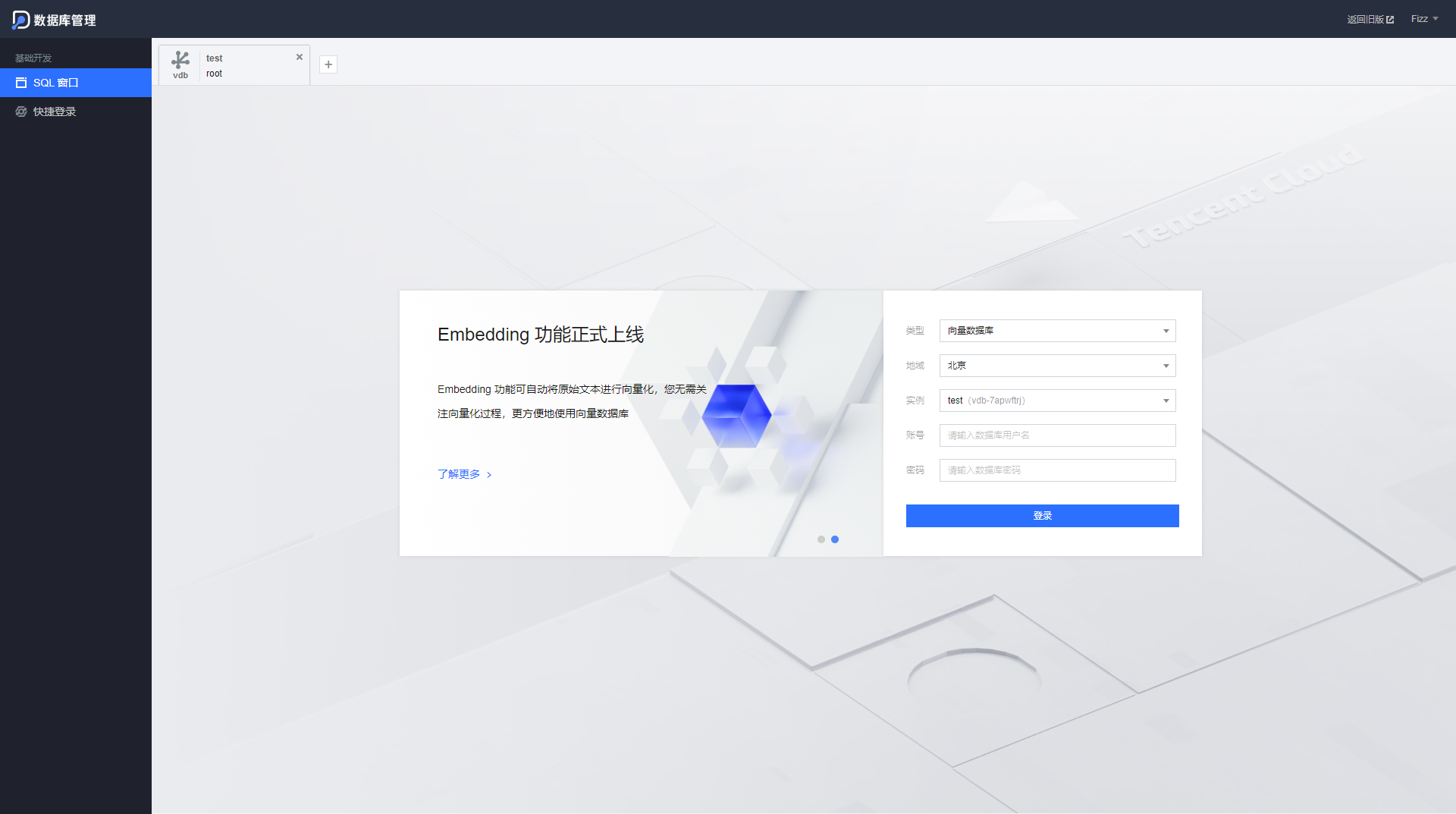
账号与密码从 秘钥管理 处可以获取。如下图:使用API时也需要使用这两个参数,请妥善保管,谨防泄露。
登录DMC可以查看到数据库实例下的 Database与Collection,如下图:(默认是空的)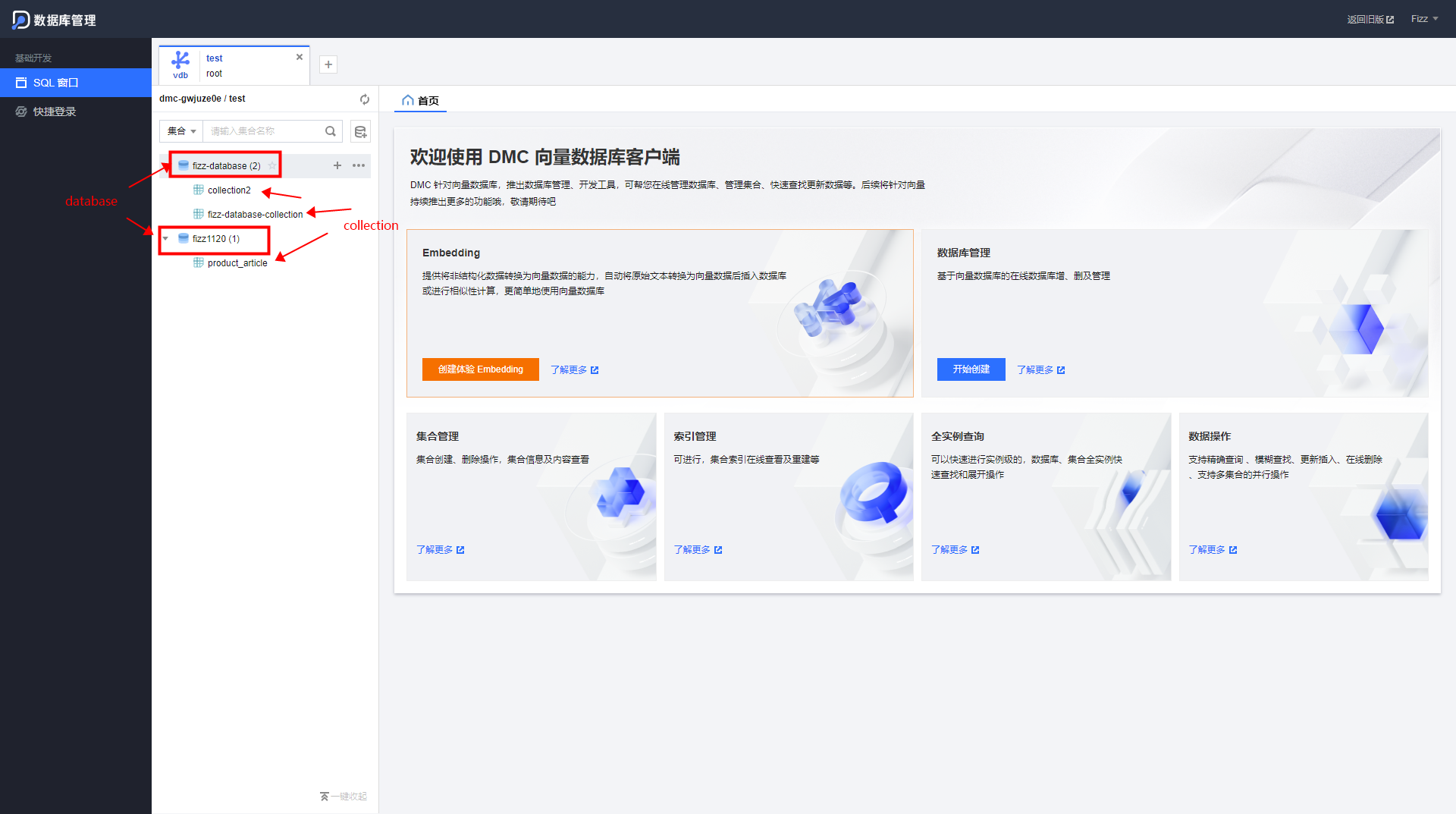
点击以下图标可以进行新建database。
在新建database时,需要输入database的名称。
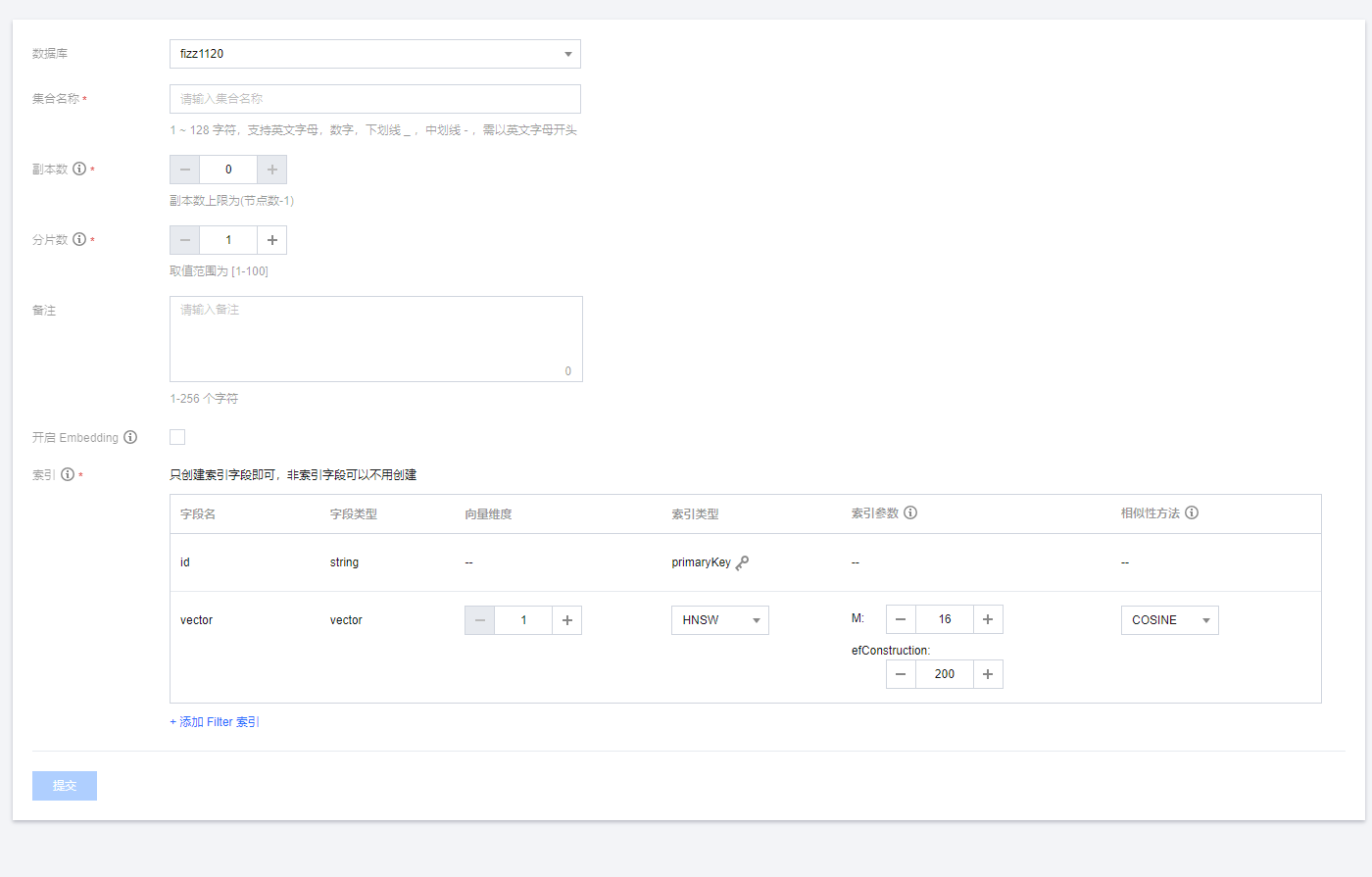
点击database旁边的加号,进行新建集合
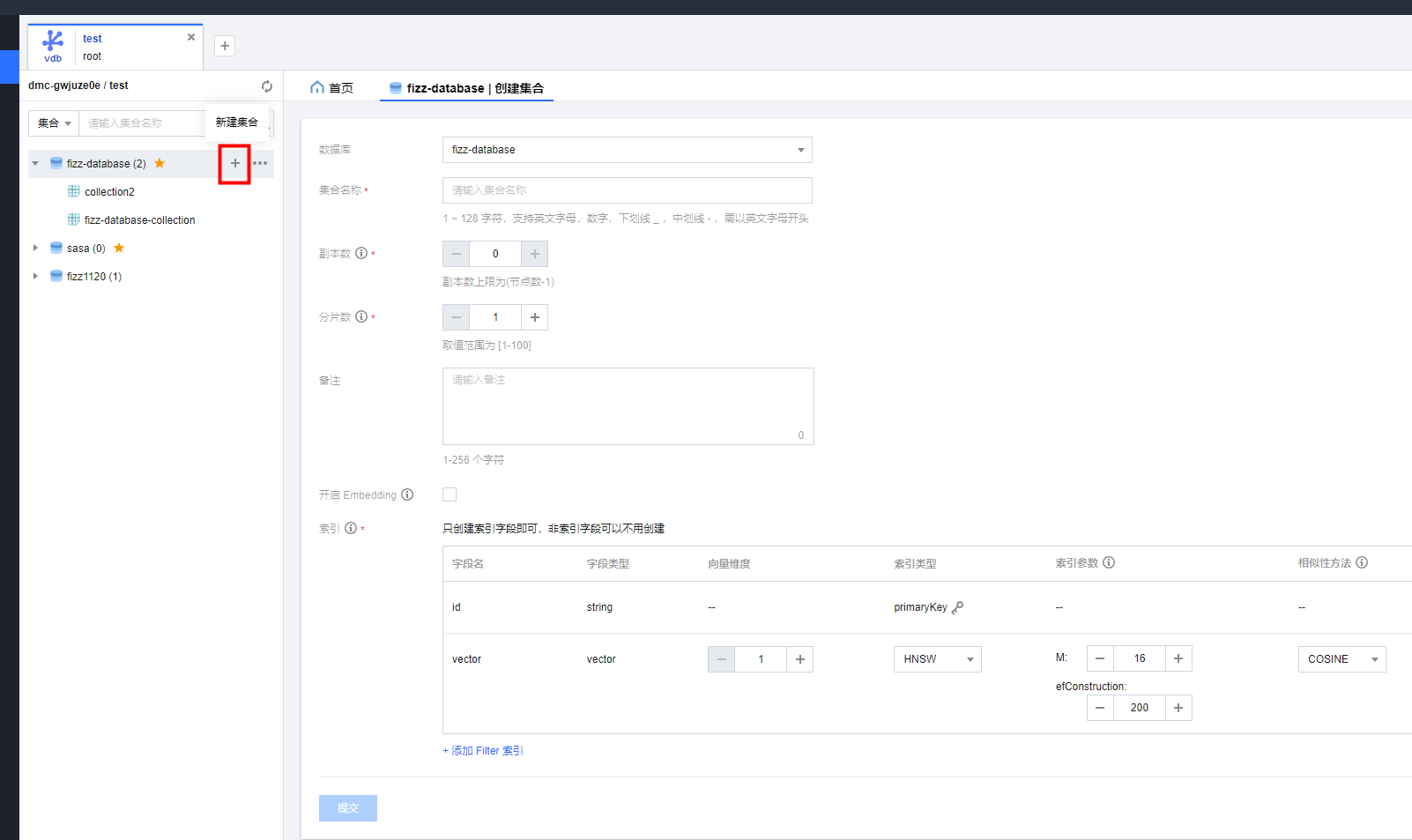
在新建集合时,需要特别注意是的开启Embedding选项,在开启Embedding选项后,会必须填入一个原始文本字段,该字段在存入数据时会使用用户选择的Embedding 模型进行向量化(但用户看到的还是原始文本)。如下图:

由于Collection相当于一张表,那么这个代表着一张表,只有一个字段可以使用Embedding 模型进行向量化。
另外值得注意的是,在创建索引时,向量索引只能创建一个,而且默认已经创建好,用户可以修改索引类型,相似性方法。
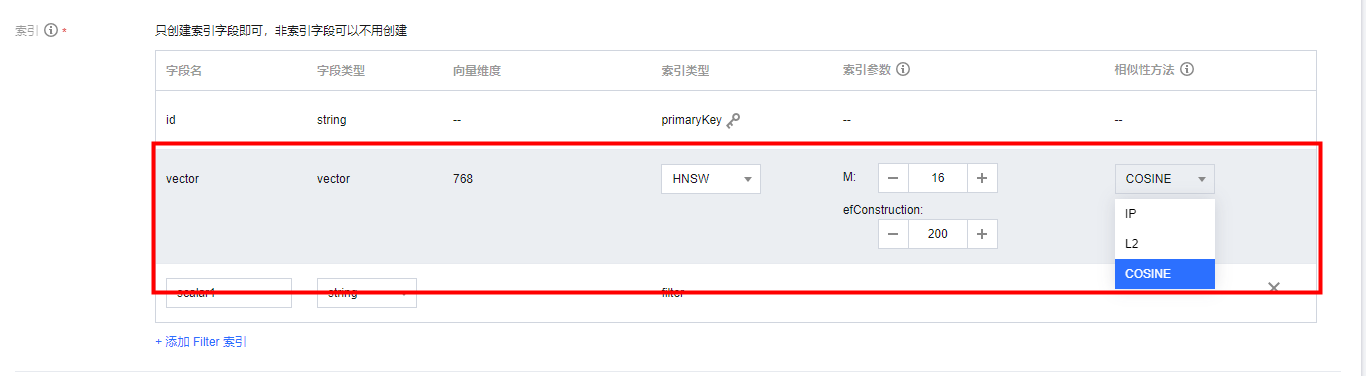
在创建Collection时,只需要创建索引字段即可,非索引字段可以不用创建。类mysql的数据库,在创建表时,需要定义表中存在的字段和类型。但是Tencent Cloud VectorDB不需要,
向量数据库字段(Field)具备 Schemaless 特性。即不需要预先定义模式,便可以将任意数量和类型的字段添加到Document 中。使用时,仅需关注需要构建索引的字段。字段的类型也有随意变更。
执行查询任务时,直接点击某一个Collection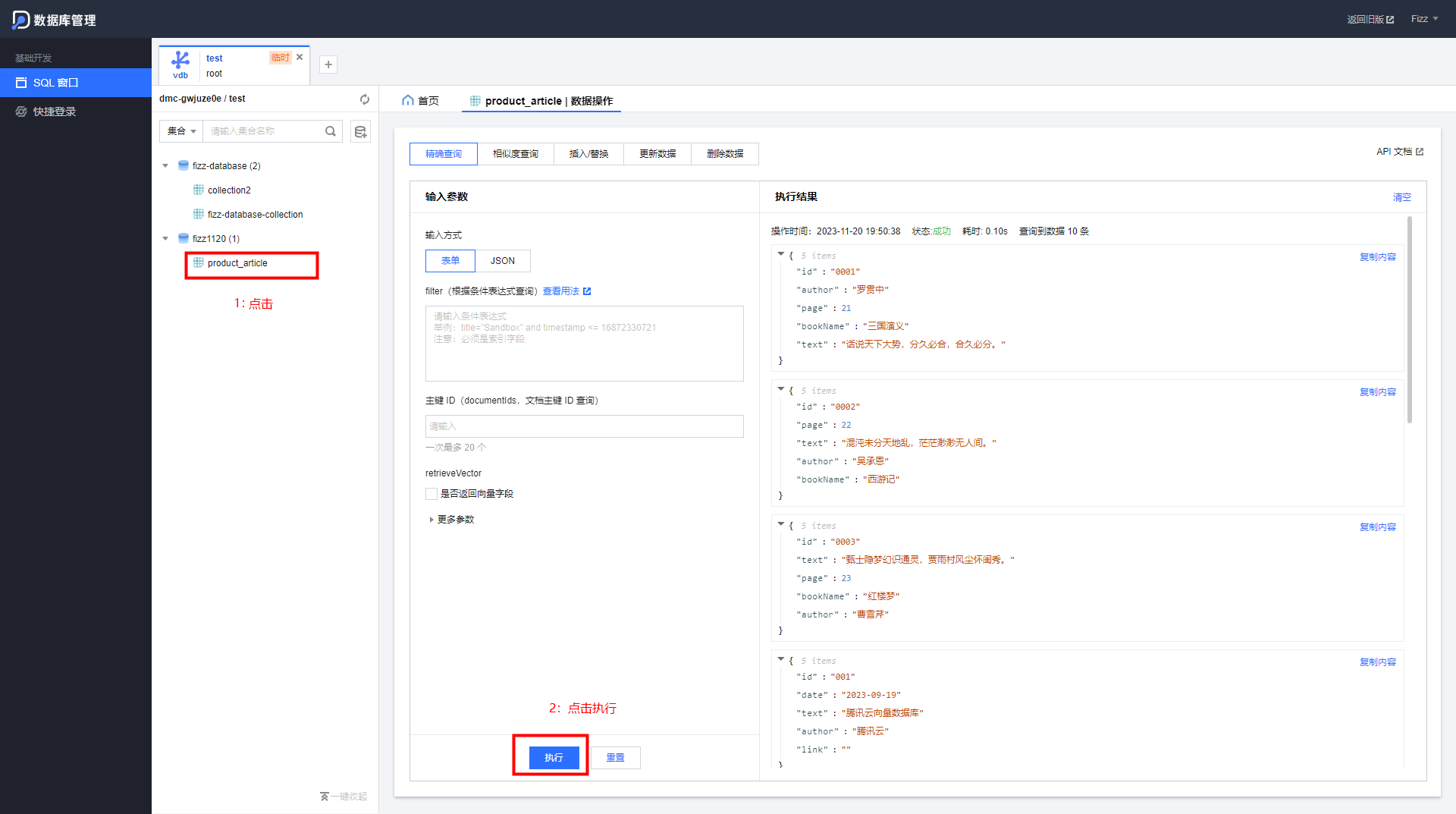
在精确查询时,直接点击执行,可以查询出10条记录。
要使用相似度查询的话,需要输如一个文本,该文本将从被Embedding 的字段中搜索。使用匹配的相似度算法。
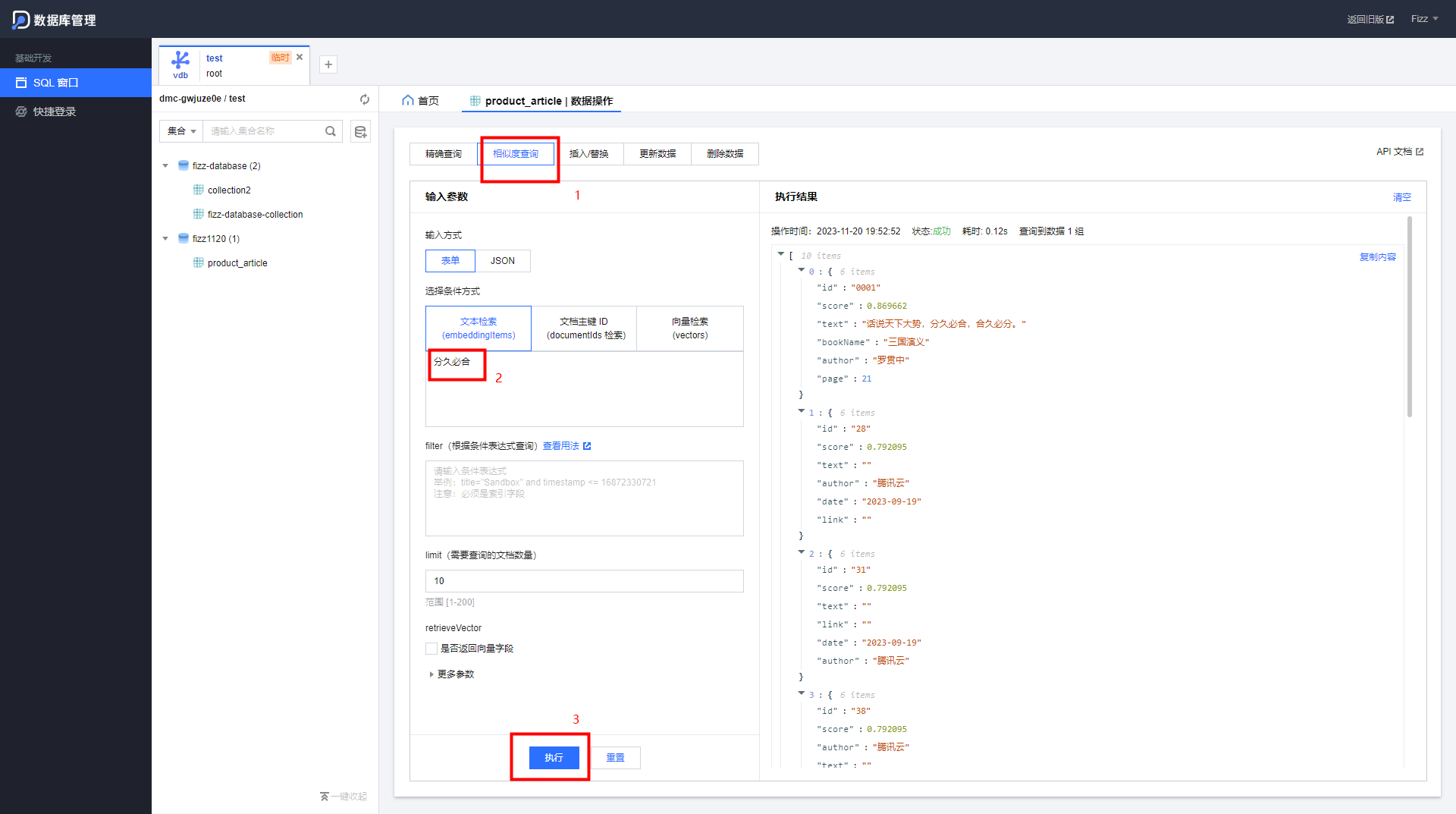
数据的插入和更新
在DMC中插入数据需要点击某个集合,打开操作窗,并选中插入/替换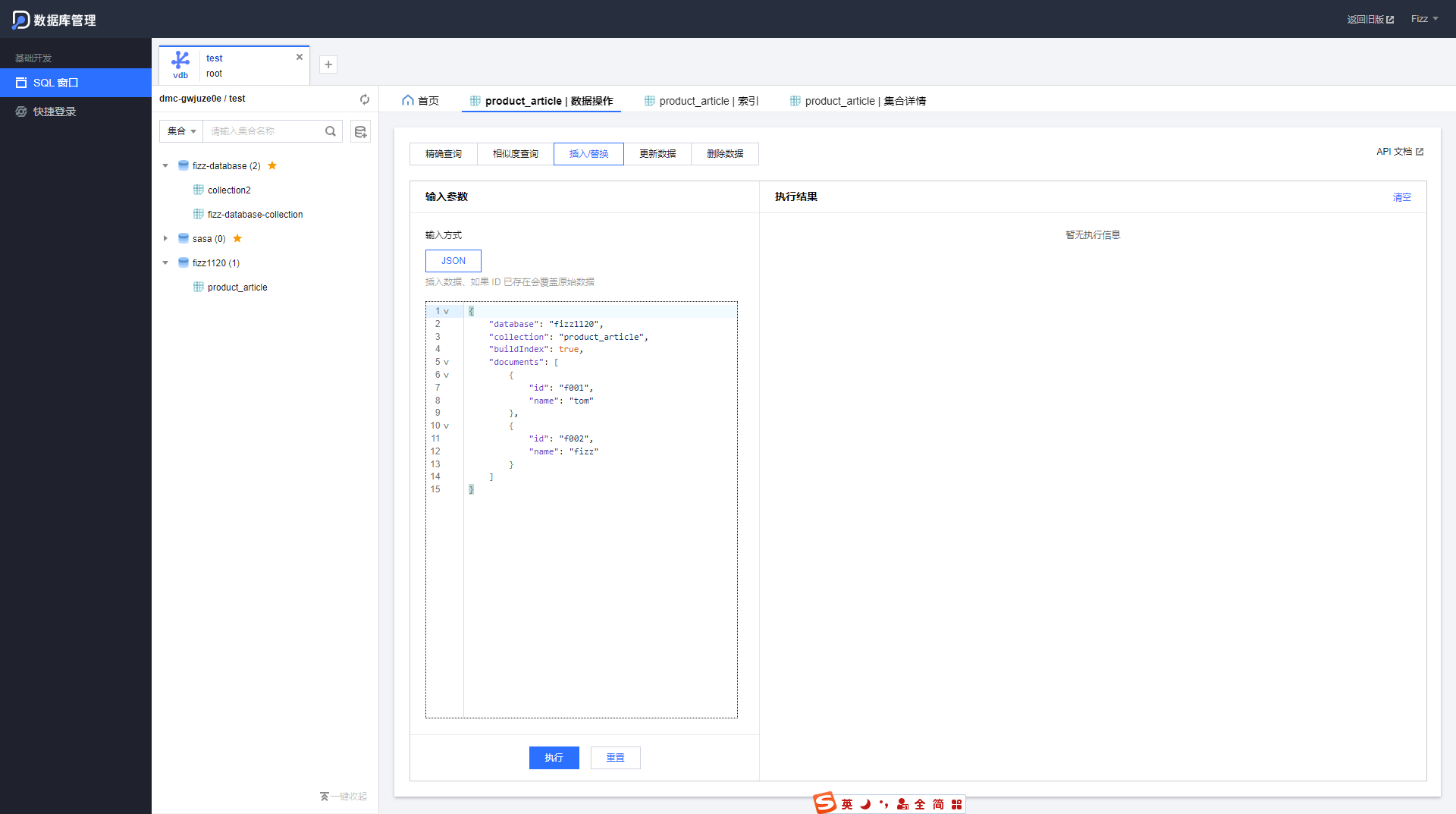
这是一个插入的示例
{
"database": "fizz1120",
"collection": "product_article",
"buildIndex": true,
"documents": [
{
"id": "f001",
"name": "tom"
},
{
"id": "f002",
"name": "fizz"
}
]
}
json中需要包含database,collection和documents 三个重要是属性。
插入数据、如果 ID 已存在会覆盖原始数据,此外在插入数据时,如果你在创建collection时打开了Embedding ,那么documents中的每个记录都需要配置该字段,否则无法插入成功。如下图:
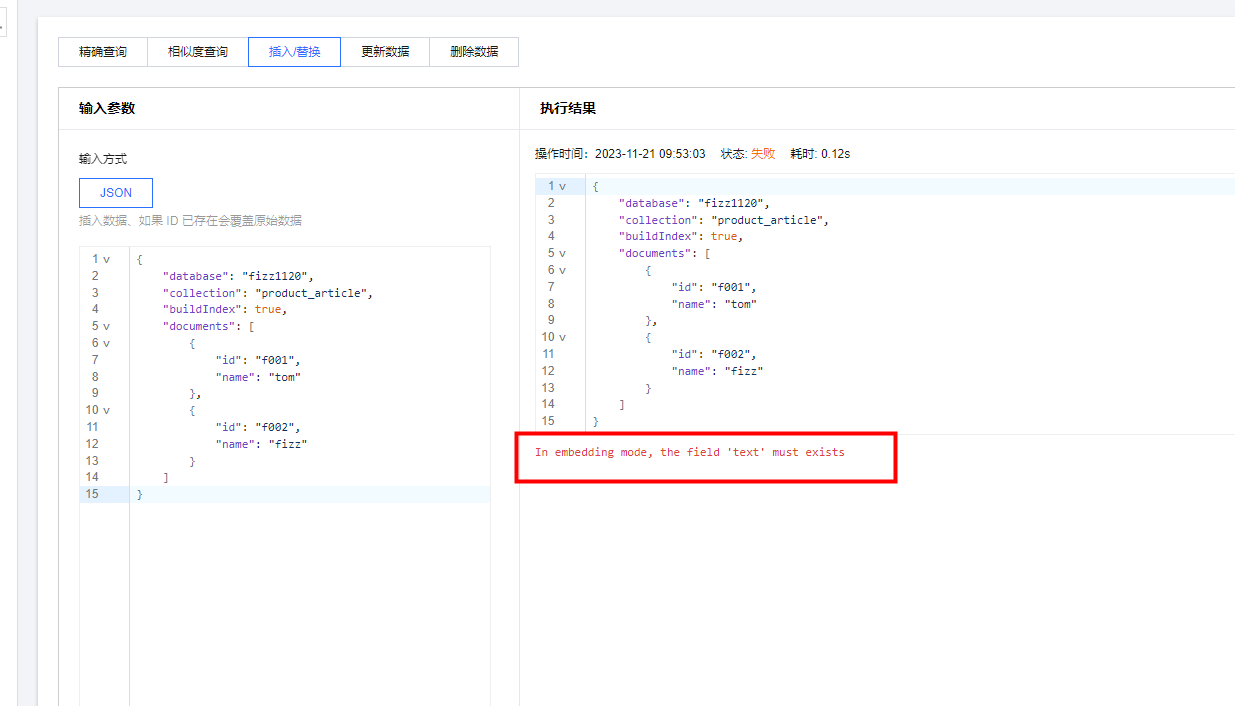
配置text字段后,就能够正常插入值
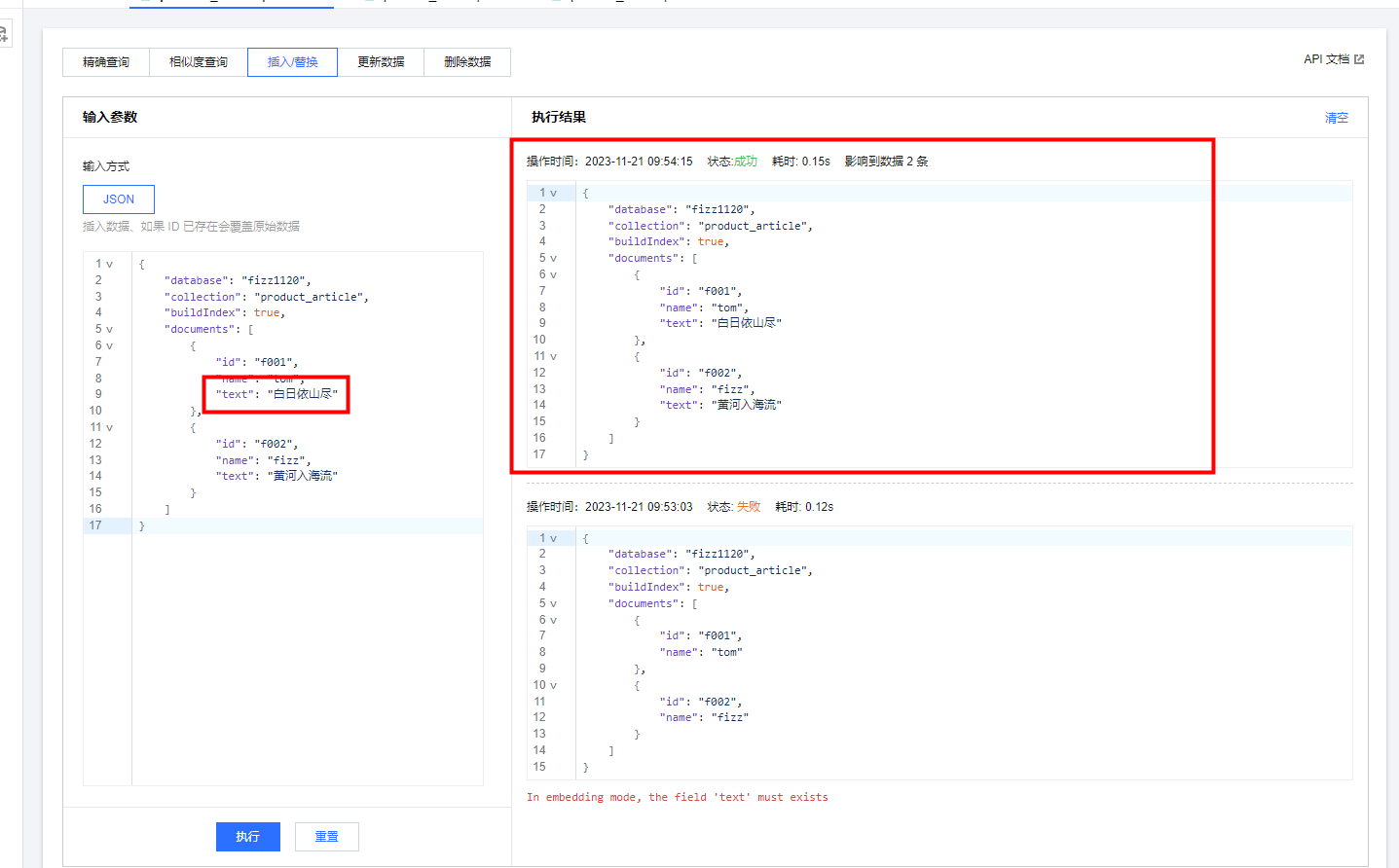
由于document中字段是不必一直的,所以你可以配置成这样子
{
"database": "fizz1120",
"collection": "product_article",
"buildIndex": true,
"documents": [
{
"id": "f001",
"name": "tom",
"text": "白日依山尽",
"time": "2023年11月21日09:56:38",
"updatetime": "2023年11月21日09:56:38",
"address": "中国深圳",
},
{
"id": "f002",
"name": "fizz",
"text": "黄河入海流"
}
]
}
性能测试,测试腾讯向量数据库的查询处理能力
为了验证腾讯腾讯云向量数据库(Tencent Cloud VectorDB)的查询能力,我们使用开源工具 ann-benchmark 对腾讯向量数据库进行了性能测试后,得到了很多详细的数据。
衡量一个数据库的查询能力,一个重要的指标就是吞吐量QPS,它是指系统在单位时间内能够处理的查询请求数量,是衡量系统查询处理能力的重要指标。我们测试了不同维度的 QPS 数据、不同召回率下的 QPS 数据、不同数据规模的 QPS 数据。
最终得出的测试结论:
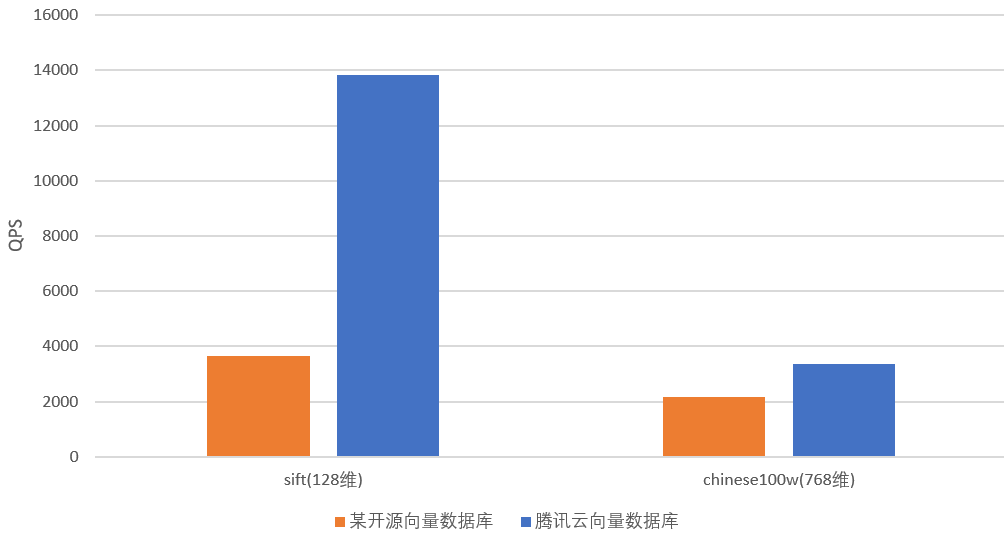
数据集128维与768维某开源向量数据库与腾讯云向量数据库的 QPS 对比测试数据,如下所示。通过如下对比视图,可看出腾讯云的 QPS 性能具有显著优势。通过该项测试,可得出如下结论:
- 在不同维度的数据集下,HNSW 索引都可以达到99%以上的召回率。
- 在数据量相同的情况下,随着向量维度的增加,检索时资源开销增加,腾讯云向量数据库 QPS 会有所降低。
- 同一数据集,与某开源自建向量数据库对比,腾讯云向量数据库的 QPS 有36%到279%的提升。对比视图,如下所示。
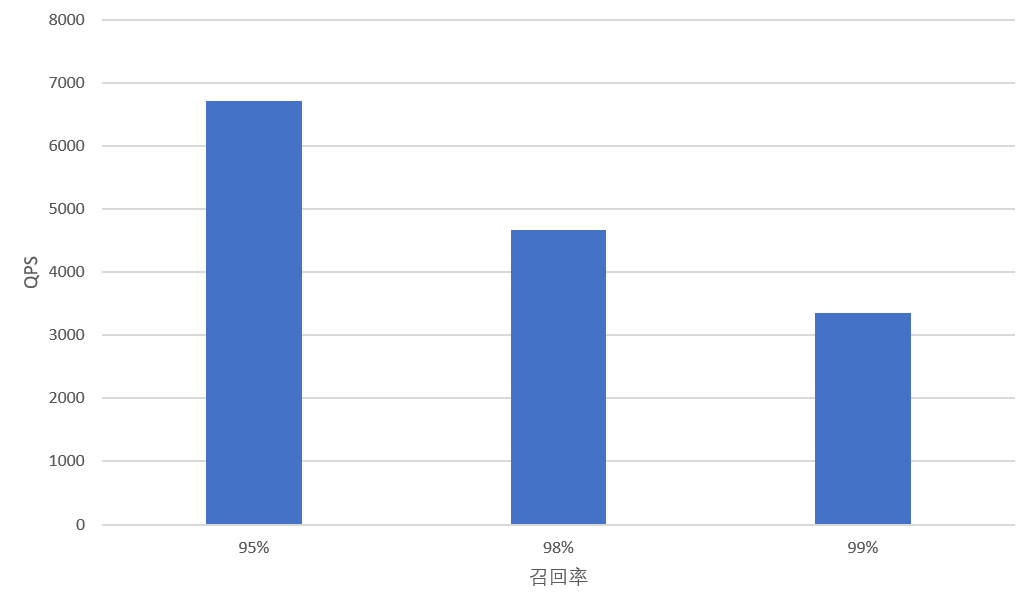
针对不同召回率下的 QPS 对比,测试结果是 - 同一数据集,召回率要求越高,即 ef 参数(指定寻找节点邻居遍历的范围)设置越大时,QPS越低。 不同召回率 QPS 的对比视图,如下所示。
- 同一数据集,在其他配置不变的情况下,若需提高召回率,可适当增加查询参数 ef。
向量数据库如何增强企业知识库搜索?
上面介绍完腾讯云向量数据库(Tencent Cloud VectorDB)的性能后,相信大家一定迫不及待想要在实践一下,看下它在日常搜索中的表现。那么下面我就带领大家以企业知识库的场景实践一下。
在腾讯云向量数据库的产品资料中有关于大模型知识库的场景方案,这里也给大家简单介绍一下。
腾讯云向量数据库可以和大语言模型 LLM 配合使用。企业的私域数据在经过文本分割、向量化后,可以存储在腾讯云向量数据库中,构建起企业专属的外部知识库,从而在后续的检索任务中,为大模型提供提示信息,辅助大模型生成更加准确的答案。
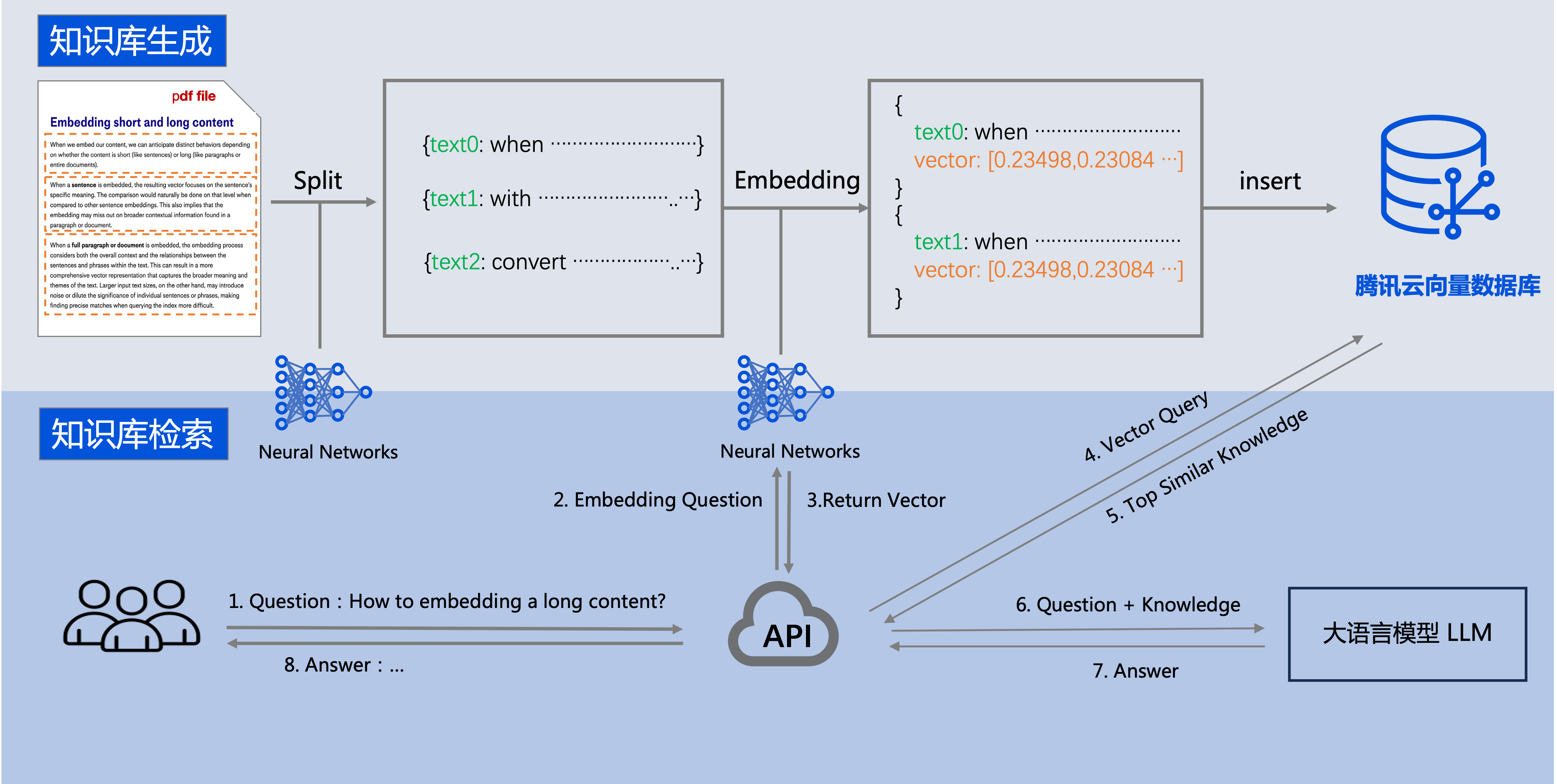
流程比较复杂,我简单描述一下使用神经网络将知识库分割,一条条的记录。然后使用向量化模型进行向量化,存入到向量数据库中。最后通过API来向外提供检索,查询。
知识库处理
本次实践我们暂未使用大模型语言LLM,更加注重向量数据库的使用。
使用的知识库就是 腾讯云向量数据库的知识文档。
为了降低难度和节约时间,我们只解析一页文档。即腾讯云向量数据库的介绍
数据库建模,创建Collection,创建索引,指定搜索算法
我们先创建相应的集合用于保存文档数据。集合配置参数如下: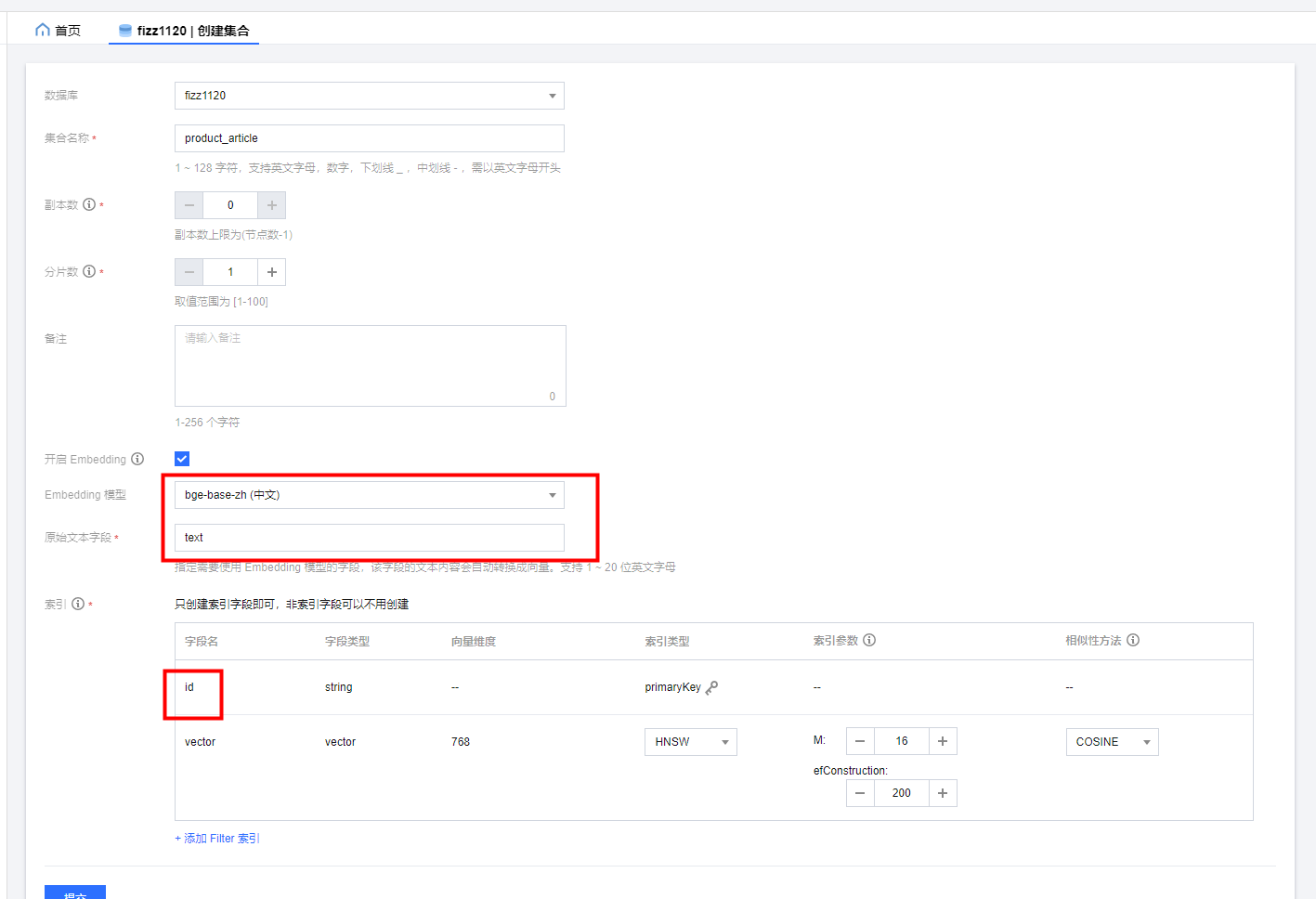
需要向量化的字段为text,主键为id。使用的向量化模型为bge-base-zh,这也是推荐使用的模型。另外相似算法使用的是COSINE。
建好模后,我们来处理知识库的原始数据,将我们知识库的文本内容以txt文件保存下来(目前图片无法进行向量化保存),保存下来后,我们需要将内容进行拆分,分割成一小段,一小段,可以以逗号,句号,和换行符进行分割。最后我们组装成这样的数据结构。
[
{
"id" : "001",
"time": "2023-10-27",
"author": "腾讯云",
"link": "https://cloud.tencent.com/document/product/1709/94945",
"text": "本页面旨在通过回答几个问题来让您大致了解腾讯云向量数据库(Tencent Cloud VectorDB)"
},
{
"id" : "002",
"time": "2023-10-27",
"author": "腾讯云",
"link": "https://cloud.tencent.com/document/product/1709/94945",
"text": "读完本页后,您将了解腾讯云向量数据库是什么、它是如何工作的、关键概念、为什么使用腾讯云向量数据库、支持的索引和指标、架构和相关连接方式"
},
{
"id" : "003",
"time": "2023-10-27",
"author": "腾讯云",
"link": "https://cloud.tencent.com/document/product/1709/94945#54308cd9-4ab5-433c-b6dc-bdacd59183e7",
"text": "腾讯云向量数据库是什么?"
},
{
"id" : "004",
"time": "2023-10-27",
"author": "腾讯云",
"link": "https://cloud.tencent.com/document/product/1709/94945#54308cd9-4ab5-433c-b6dc-bdacd59183e7",
"text": "腾讯云向量数据库是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。"
},
{
"id" : "005",
"time": "2023-10-27",
"author": "腾讯云",
"link": "https://cloud.tencent.com/document/product/1709/94945#54308cd9-4ab5-433c-b6dc-bdacd59183e7",
"text": "该数据库支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。"
},
{
"id" : "006",
"time": "2023-10-27",
"author": "腾讯云",
"link": "https://cloud.tencent.com/document/product/1709/94945#54308cd9-4ab5-433c-b6dc-bdacd59183e7",
"text": "腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域"
}
]
- id 主键
- time 文档撰写时间
- author 作者
- link 文档片段的锚点
- text 需要向量化的原始文档文本
插入数据
一篇文章我们大概能够分割出100多条记录。然后将这些记录,一次性插入到向量数据库中。
本次实践我们使用 HTTP 协议进行数据写入和查询等操作,编程语言是用Nodejs。
以下是向向量数据库批量插入文档的核心代码
批量插入文档
const axios = require('axios')
const documents = require('./documents') // 存放记录的js文件
const account = '' // 数据库账号
const apiKey = '' // 数据库秘钥
const databaseLink = '' // 数据库外网地址
const headers = {
Authorization: `Bearer account=${account}&api_key=${apiKey}`,
}
async function insertDoc(documents) {
try {
const sendData = {
database: 'fizz1120',
collection: 'product_article',
buildIndex: true,
documents,
}
const response = await axios.post(`${databaseLink}/document/upsert`, sendData, headers)
console.log('插入成功', response.statusText)
} catch (error) {
console.error(`请求遇到问题: ${error.message}`)
}
}
insertDoc(documents)
脚本运行成功后,控制台会打印出插入成功的字样。
然后我们在DMC中对某个集合查看详情,
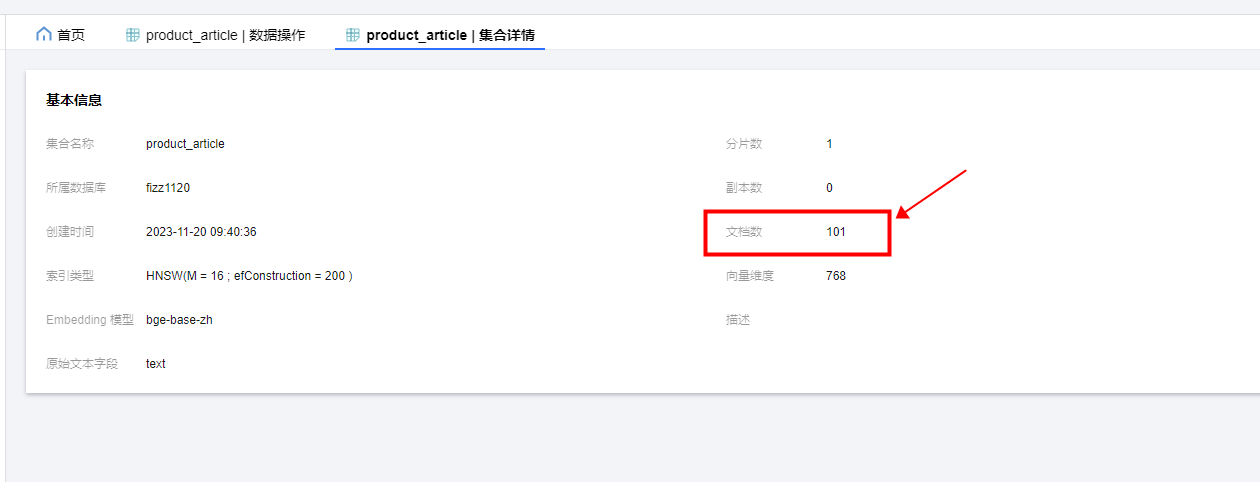
可以看到,文档已经被插入了数据库,目前文档数位101。
数据查询
数据查询我们使用的是相似度匹配的查询方式,接口为/document/search ,用于查找与给定查询向量相似的向量。
有几个必填参数,
database: 指定要查询的Database名称。
collection: 指定要查询的Collection名称。
如果有个关键词,你可以这个传入
"search": {
"embeddingItems": [
"腾讯云向量数据库是什么?"
],
"limit": 3,
}
下面是搜索的核心代码
// 检索方法
async function searchDom(keyword) {
const sendData = {
database: 'fizz1120',
collection: 'product_article',
search: {
embeddingItems: [keyword],
limit: 5,
retrieveVector: false,
},
}
try {
const { data } = await axios({
method: 'post',
url: `${databaseLink}/document/search`,
data: sendData,
headers,
})
console.log(data.documents)
} catch (error) {
console.log(error.message, '111')
}
}
searchDom('腾讯云向量数据库是什么?')
返回结果如下:
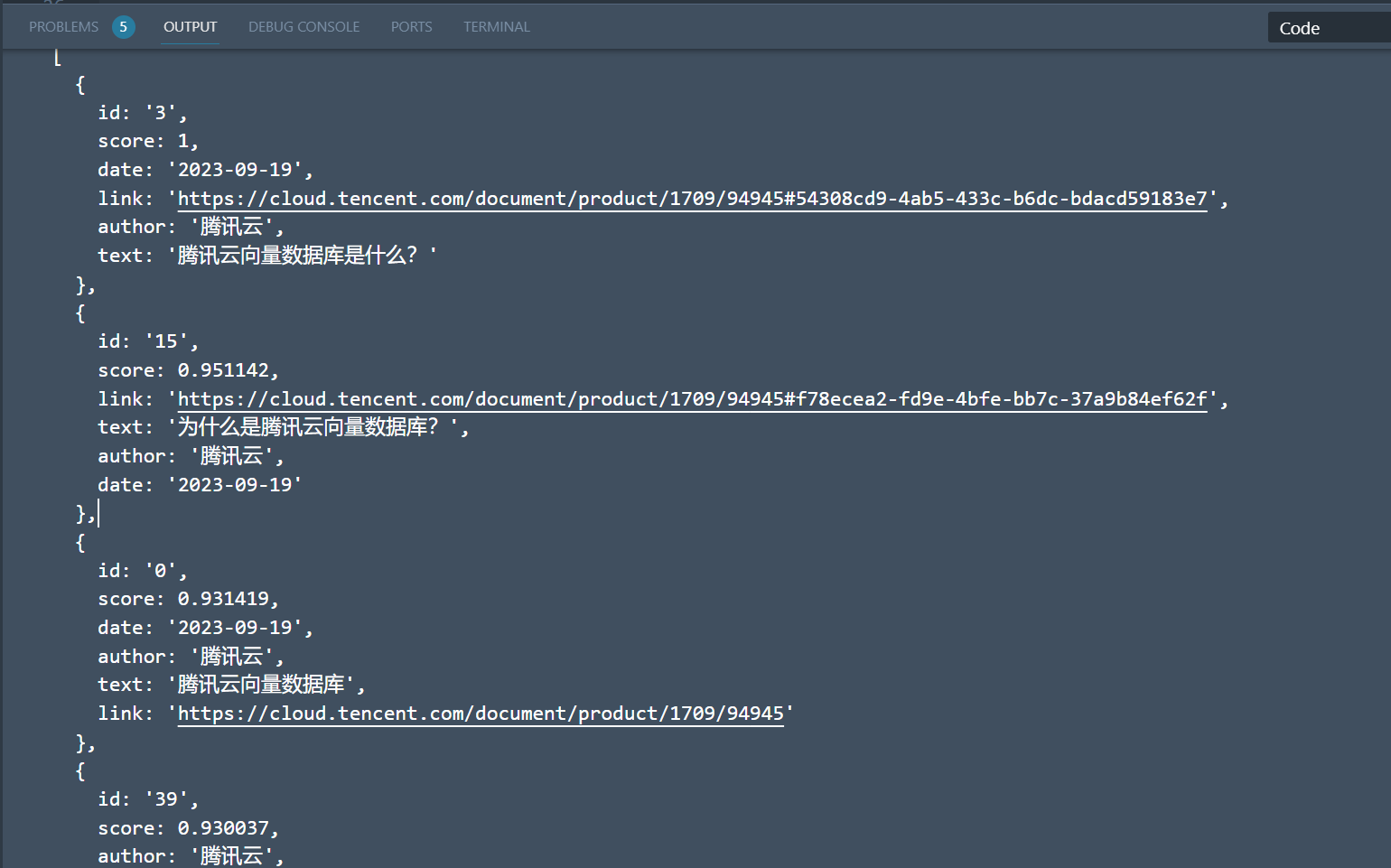
由于我们查询参数limit设置了5,所以结果返回了5条。
除了limit,还有一些参数可以控制我们的查询结果
- vectors 表示要查询的向量列表。
- documentIds 待查询的文档 ID 列表。数组元素数量最大为20
- embeddingItems 输入文本信息,用于检索与该文本信息相似的数据。注意 vectors 、 documentIds、embeddingItems 三个字段,只需配置其中一个即可
- params 索引类型不同,检索时,所需配置的参数不同。
- filter 使用创建 Collection 指定的 Filter 索引的字段设置查询过滤表达式
- retrieveVector 标识是否需要返回检索结果的向量值。
- outputFields 指定需要输出的字段。若不设置,将返回所有字段。
至此,我们的企业知识库的文档处理,批量插入,相似度查询,就全部做完了。
总结
目前腾讯云向量数据库(Tencent Cloud VectorDB)只支持文本向量化写入,对于音视频和图片等非文本,非结构化数据还不支持。但从目前的情况来看在查询和使用上,它已经是一款非常优秀的产品。无论是配套的API支持,还是产品概念,文档。抑或是使用的便捷,都做的非常好。
腾讯云向量数据库作为一种专门存储和检索向量数据的服务提供给用户, 在高性能、高可用、大规模、低成本、简单易用、稳定可靠、智能运维等方面体现出显著优势。
产品建议和意见
1:使用DMC时,在使用插入时,如果该集合开启了embedding,并填写了一个字段,那么在插入时必须要有这个字段,需要在插入时给出的示例能够包含该字段。
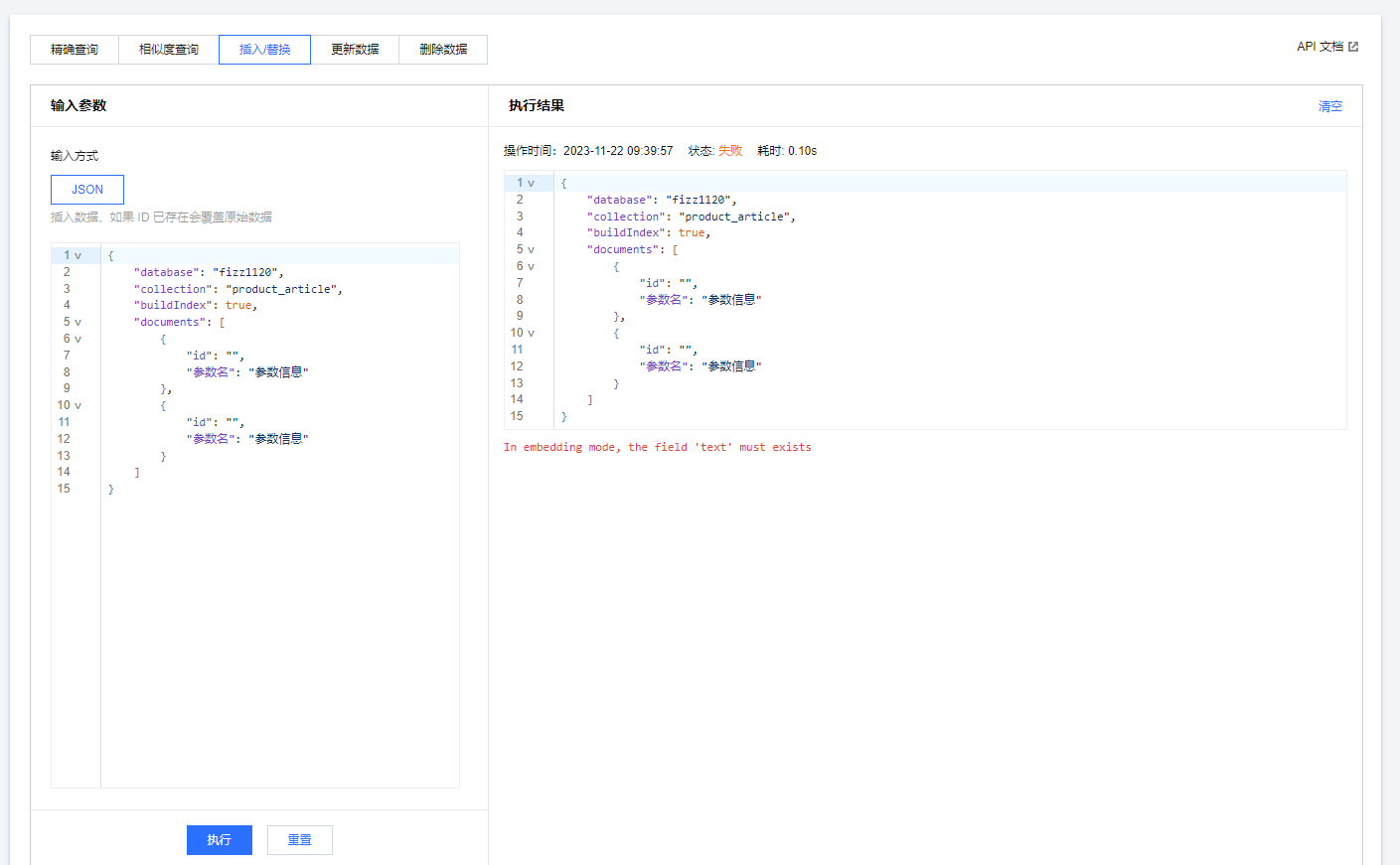
2:在DMC中,希望能够提供一个查看所有Document的的视图
类似下图
3:建议数据库权限划分更加细一下,能够将读写的权限分离。目前一个密钥能够完成所有的增删改查。
4:创建集合的页面不太美观,第一次使用该功能,非常的迷茫,不清楚填入的
相关链接
腾讯云向量数据库
DMC数据库管理