前言:
在当今信息化时代,掌握对数据进行挖掘和分析的能力变得愈发关键。根据需求精准处理数据不仅仅是一项技能,更是对未来决策和操作的至关重要的支持。除了熟练运用适当的算法模型对大数据进行挖掘和分析外,合理高效存储和处理大量数据,对开发者和企业来说变得越来越重要。

文章目录
- 一、走近腾讯云向量数据库
- 二、助力数据收集和处理
- 三、数据挖掘和分析使用指南
- 1. 准备工作
- 2. 数据操作演示(平台端)
- 3. 数据操作演示(SDK接入)
- 4. 以汽车相关数据进行分析预测
- 四、大数据时代下的数据挖掘的未来趋势
- 五、总结
前几天,和往常一样下班后回家打开电脑学一会,偶然机会看到了腾讯云刚发布的向量数据库体验活动,刚好最近手头的工作也忙完了,于是下意识也报名申请了一个体验名额。在体验使用的时候,也融入了一些对数据进行分析和挖掘的算法。

整体使用感觉也非常棒,经过这几天的整理和总结,能够帮助不了解或者没使用过的小伙伴快速熟悉并且有一定的上手。(腾讯云向量数据库:感兴趣的小伙伴可以去申请名额体验)
一、走近腾讯云向量数据库
看到向量数据库你可能会想到数据库,但是它和传统数据库相比有鲜明的优点。可能有不少朋友在平常工作或者生活中,或多或少都接触过一些关于向量数据库的消息,作为一个全能的程序员,除了关注底层的逻辑外,清晰明了向量数据库发展的方向和未来趋势,能否抓住这个在发展风口机会。我们还需要去了解,让我来以腾讯云向量数据库为例给你讲讲吧。

随着AI技术的快速发展,越来越多的公司和企业开始重视底层数据的合作探索。在将大型模型应用于实际场景中,数据处理和挖掘变得至关重要。向量数据库作为支撑大型模型的关键基础设施,将在个人、企业和社交媒体等领域发挥越来越重要的作用。
总的来说:向量数据库的优势在于高效的向量相似性搜索、高维数据处理、特定索引结构、异构数据类型支持,适用于机器学习和深度学习、大规模数据处理,提供实时性能。选择使用向量数据库应基于应用需求和性能评估。
二、助力数据收集和处理
每天,每个人都面临来自各个渠道的数千条信息。而对于开发者和企业用户而言,每天需要处理的信息量更是以万计甚至千亿计。信息的接收和处理成为一个极具挑战性的任务。。

往往让开发者和企业在处理数据方面头疼的问题不外乎:
1. 如何适应业务数据快速变化的需求?
2. 如何保障数据安全?
3. 如何实现业务系统对高实时响应的要求?
4. 如何在多样化的销售和服务场景中?
腾讯云向量数据库由于其卓越的稳定性、性能、易用性和便捷的运维,都展现出了显著优势,能够提供高效稳定的服务。
- 高性能: 向量数据库单索引支持10亿级向量数据规模,可支持百万级 QPS 及毫秒级查询延迟。
- 高可用: 向量数据库提供多副本高可用特性,其多可用区和三节点的架构可用性可达99.99%,显著提高系统的
- 可靠性和容错性:确保数据库在面临节点故障和负载变化等挑战时仍能正常运行。
- 大规模: 向量数据库架构支持水平扩展,单实例可支持百万级 QPS,轻松满足 AI 场景下的向量存储与检索需求。
- 低成本: 只需在管理控制台按照指引,简单操作几个步骤,即可快速创建向量数据库实例,全流程平台托管,无需进行任何安装、部署和运维操作,有效减少机器成本、运维成本和人力成本开销。
- 简单易用: 支持丰富的向量检索能力,用户通过 HTTP API 接口即可快速操作数据库,开发效率高。同时控制台提供了完善的数据管理和监控能力,操作简单便捷。
- 稳定可靠: 向量数据库源自腾讯集团自研的向量检索引擎 OLAMA,近40个业务线上稳定运行,日均处理的搜索请求高达千亿次,服务连续性、稳定性有保障。
三、数据挖掘和分析使用指南

1. 准备工作
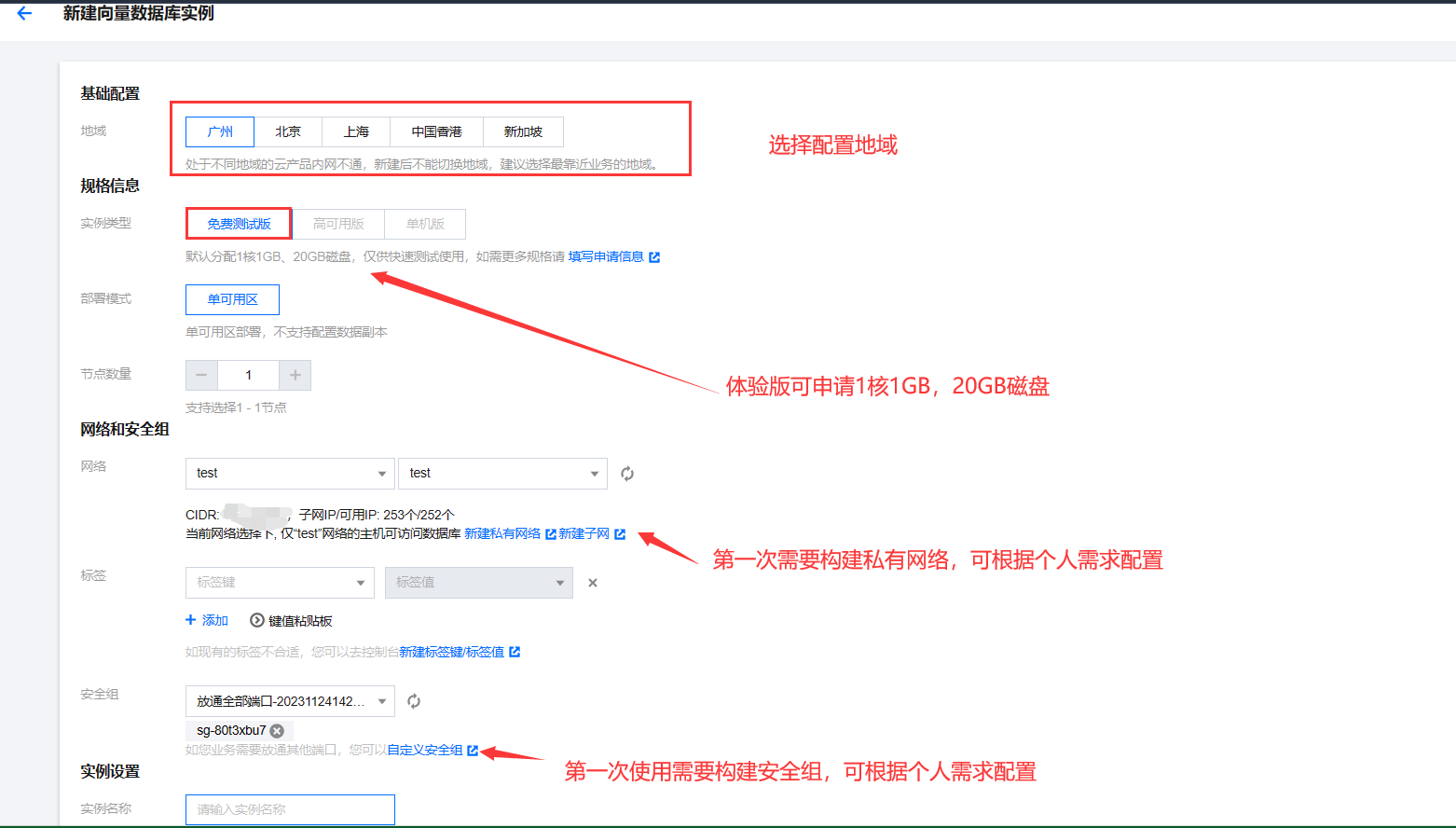
- 首先我们需要去申请一台向量数据库 腾讯云向量数据库申请 ,登录进入后,点击新建。如图,是已经构建好的向量数据库

- 配置向量数据库实例相关信息
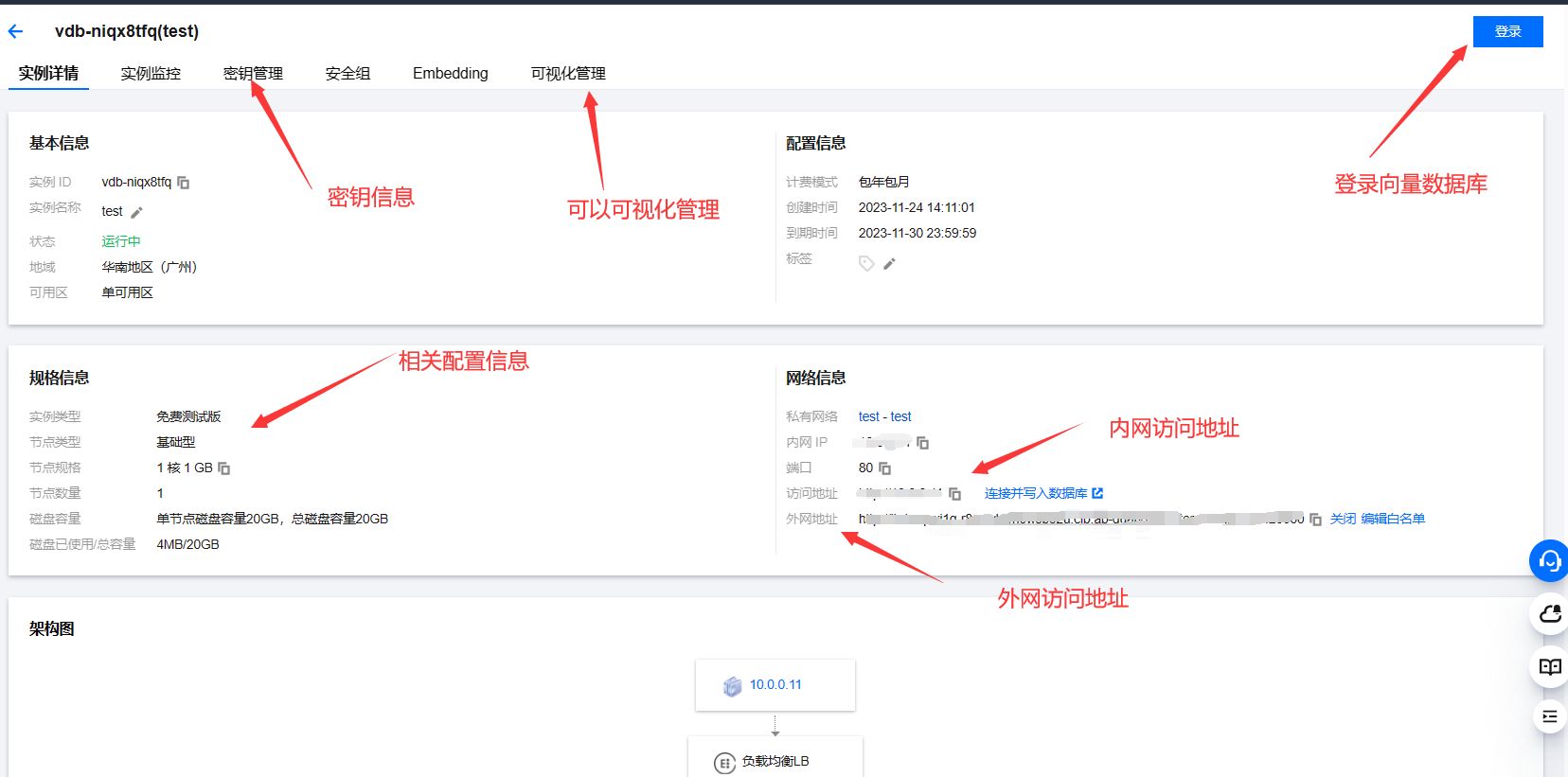
- 创建好向量数据库后,可以查看相关的配置信息,包括内网外网访问地址,以及密钥信息
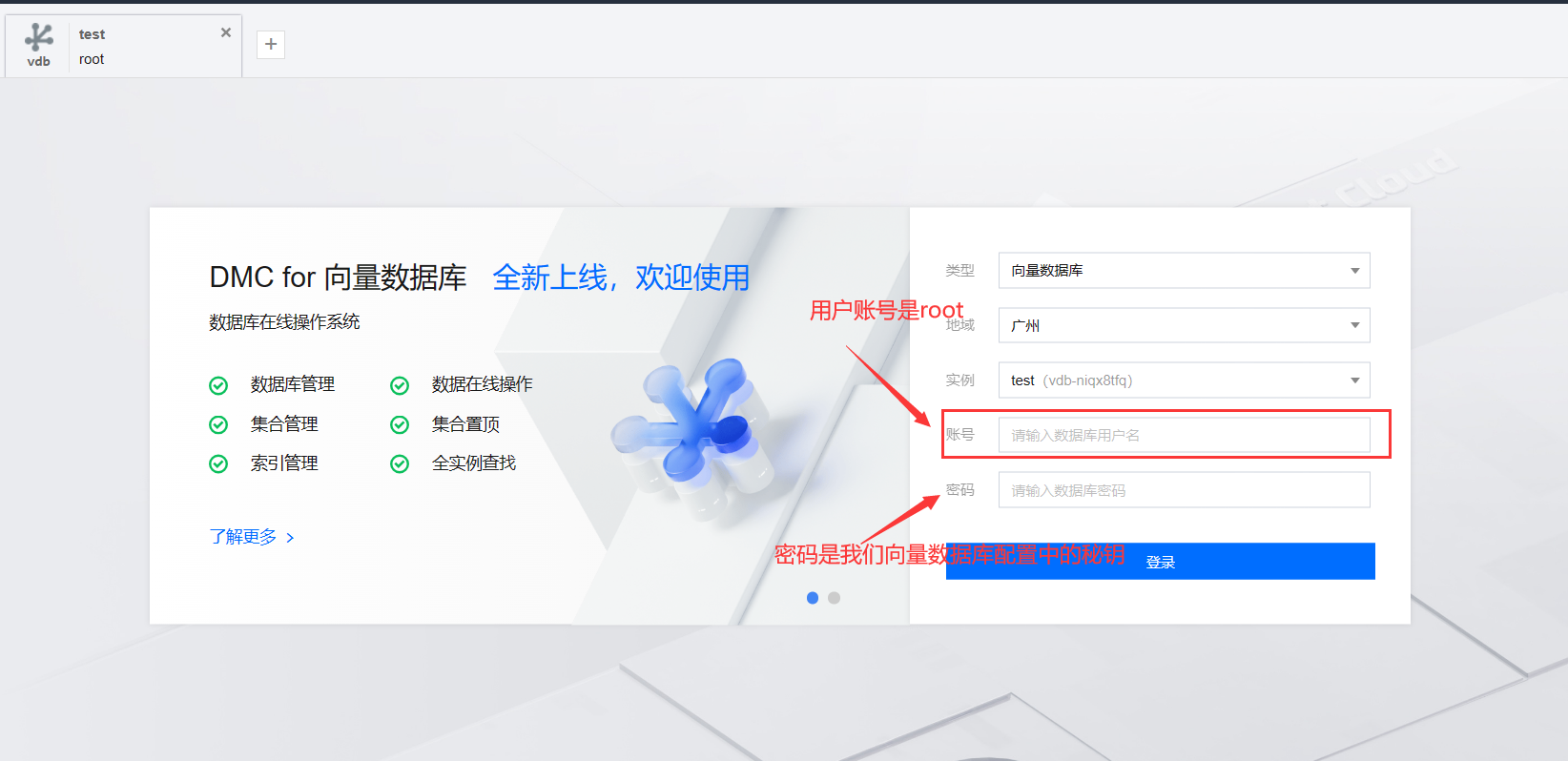
- 创建好向量数据库后,点击登录,来到向量数据库登录界面,如图需要账号和密码账号默认是root,密码是向量数据库配置中的密钥
- 登录进去后,可以看到先向量数据库管理模块和数据操作模块。管理模块可以创建向量数据库,管理集合。数据操作模块可以进行精确、相似度查询、插入/替换、更新、删除数据。
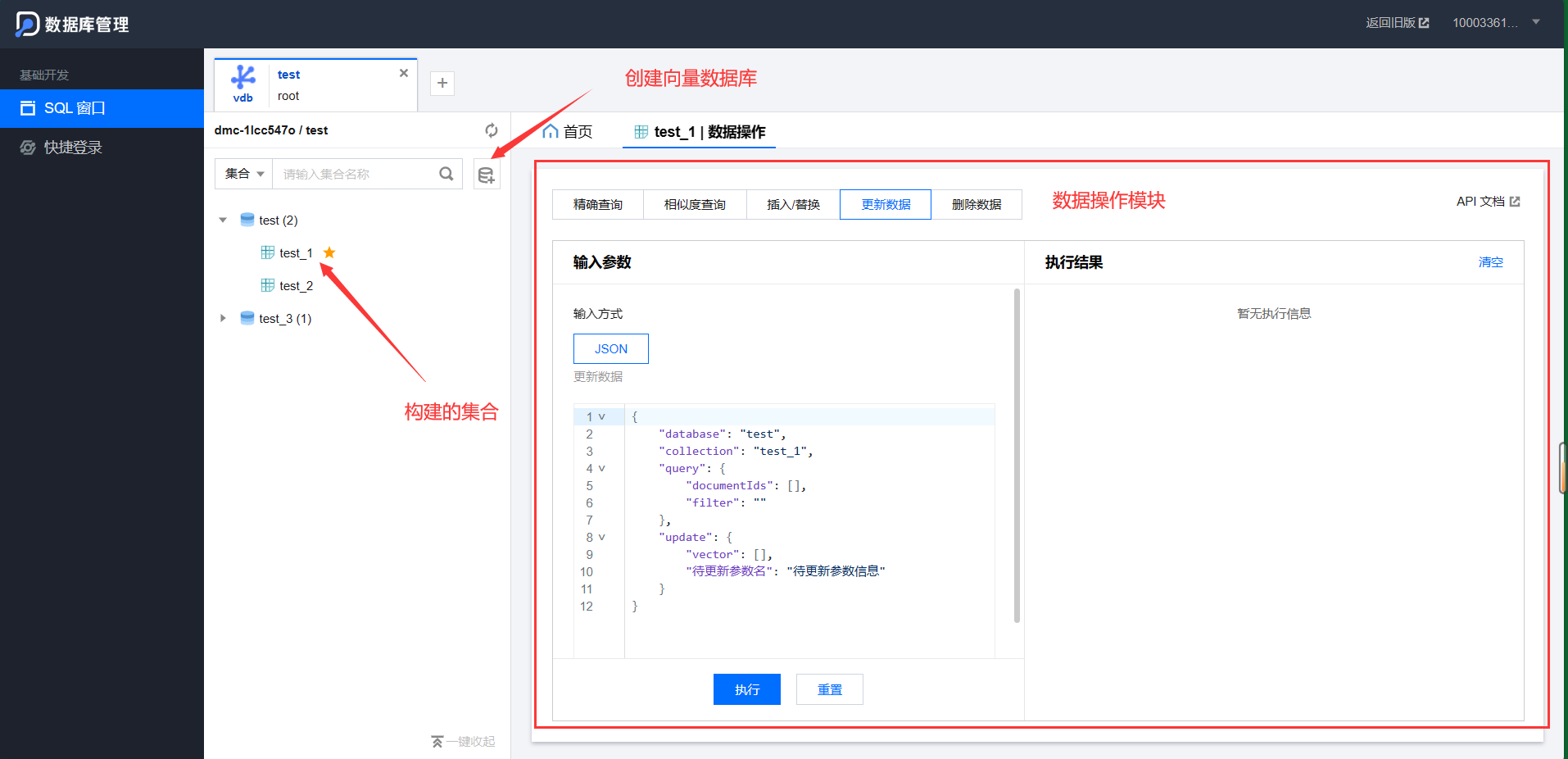
2. 数据操作演示(平台端)
腾讯云向量数据库支持多种方式操作向量数据库,包括:使用平台数据操作模块操作,或者接入Python,Java以及HttpAPI来进行操作,在这里我演示一下平台数据操作和接入Python的SDK使用。
1.插入/更新 参数数据 支持以json格式插入数据
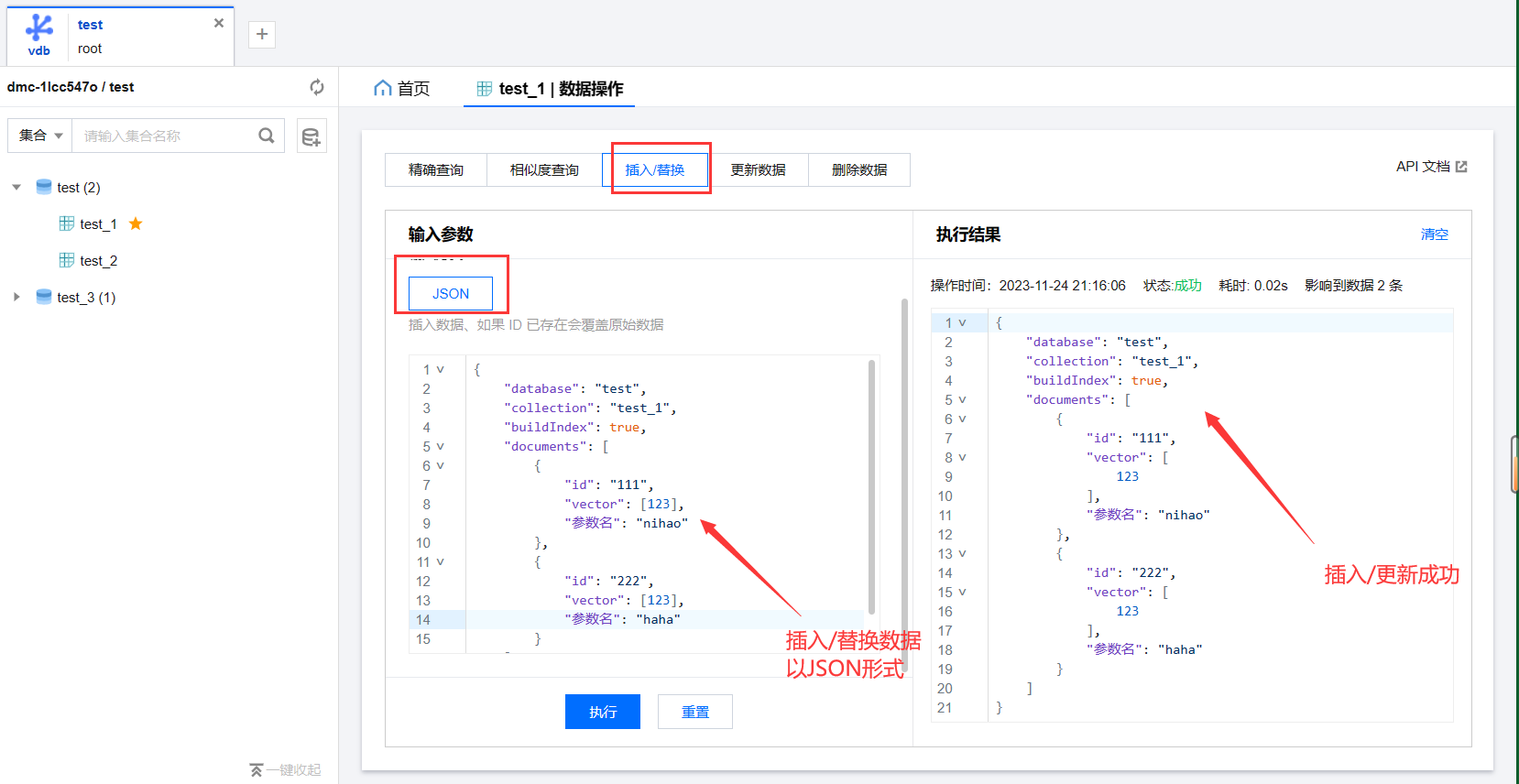
2.精确查询 参数支持以 表单和JSON两种格式根据不同情况(包括:主键和条件进行查询)

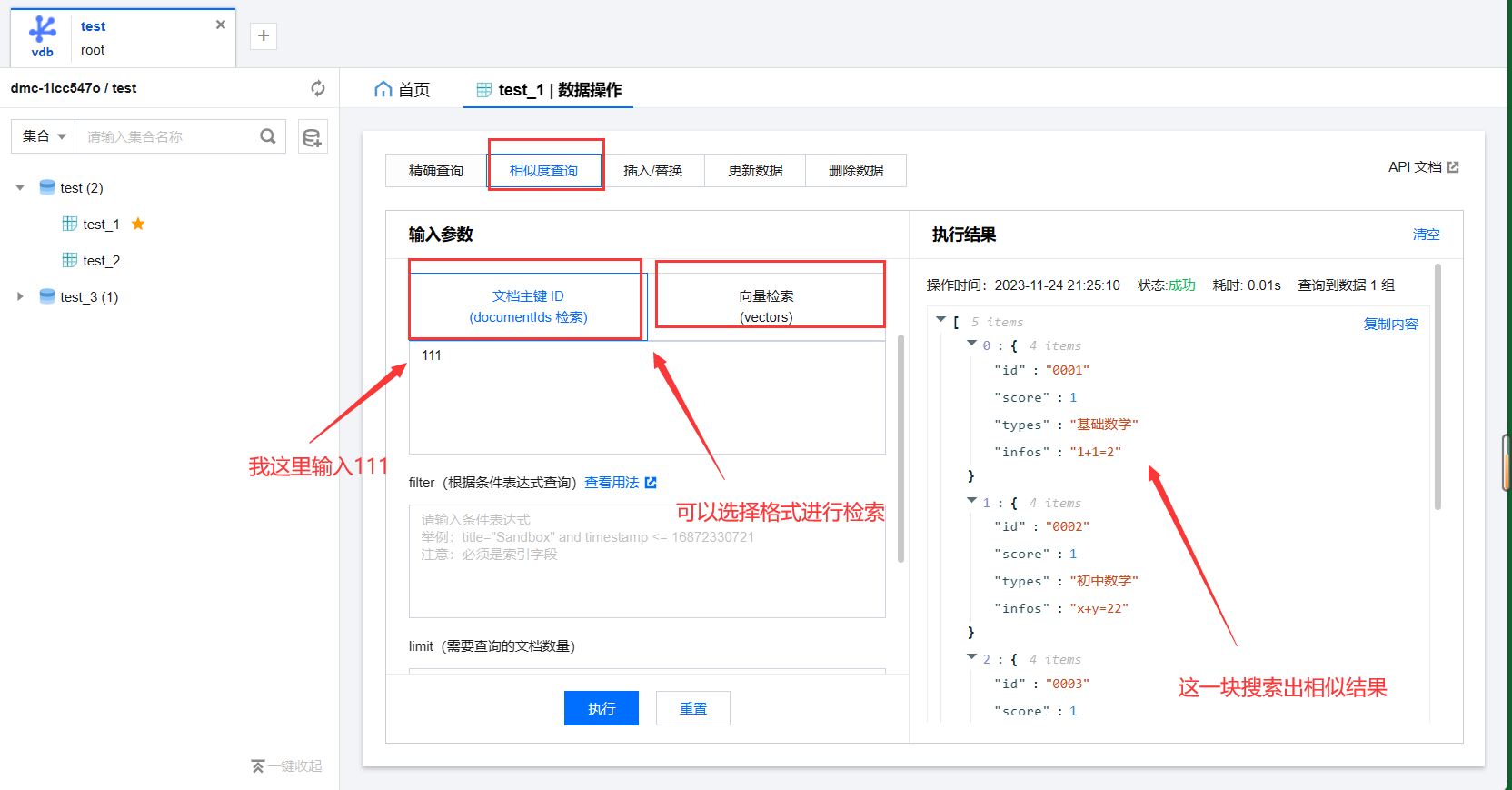
3.相似度查询 可以根据不同格式进行检索,同时也支持条件查询和主键查询,这一步会检索出结果有相似程度的数据
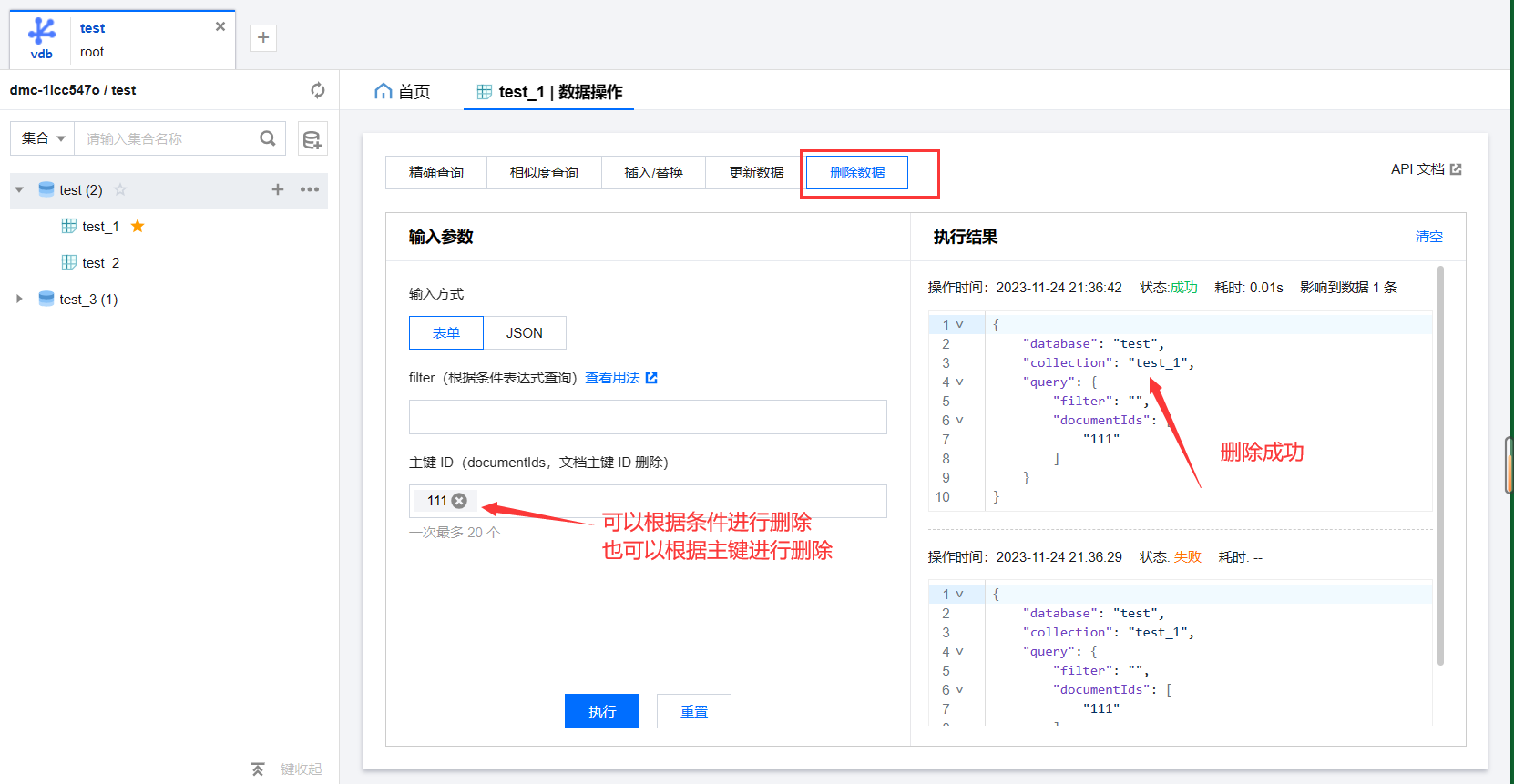
4.删除数据 可以根据条件查询删除,同时也可以根据主键去删除
3. 数据操作演示(SDK接入)
1.官方提供了多种接入方式,在这里我以Python为例子,进行接入 腾讯云向量数据库API文档
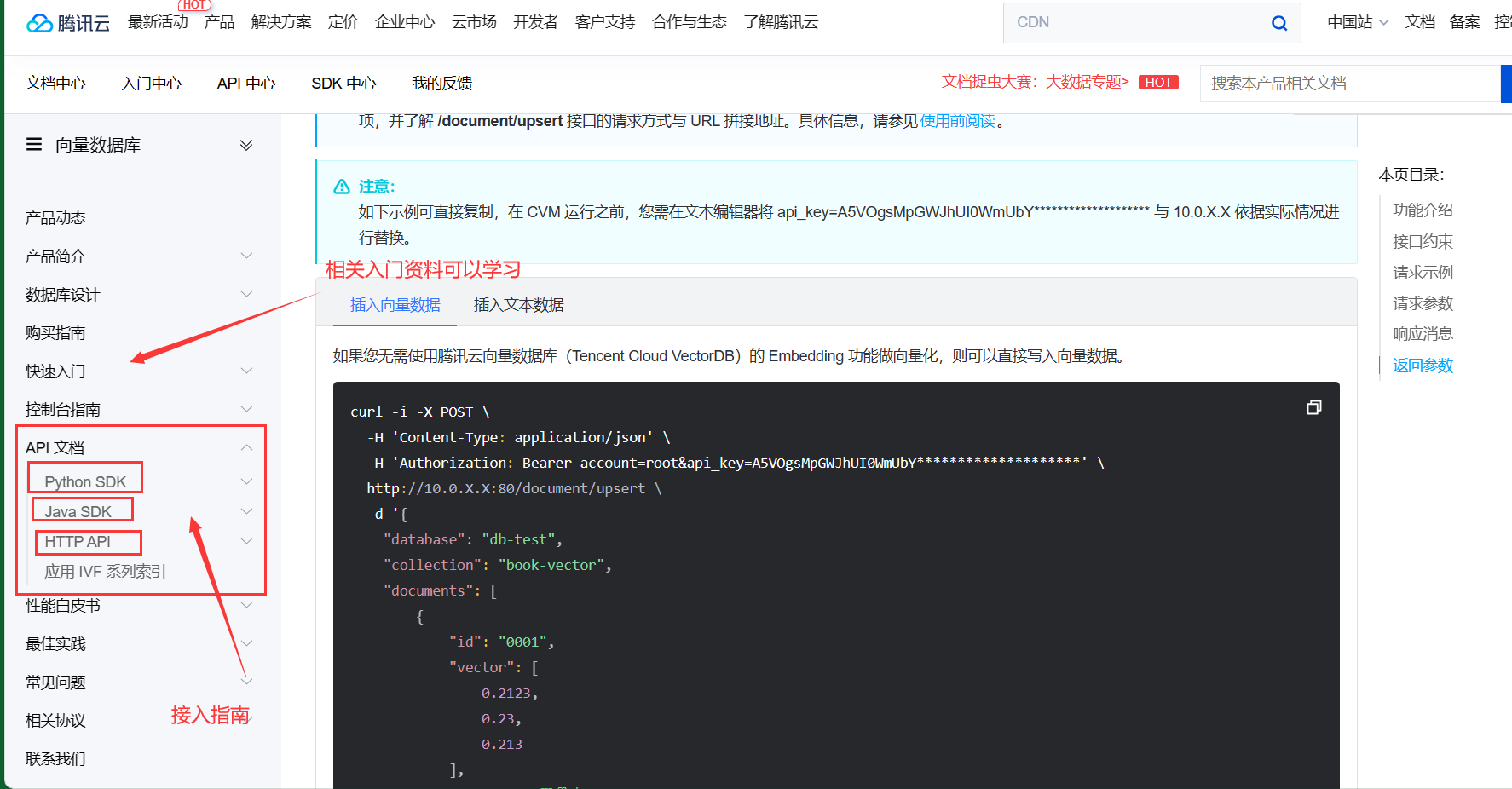
2.以Python为例,本地连接远程向量数据库
首先需要导入依赖:
pip install tcvectordb
然后连接远程向量数据库,这一块url 输入你的向量数据库外网地址,apikey输入你的向量数据库密钥
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
#这一块url 输入你的向量数据库外网地址,apikey输入你的向量数据库密钥
client = tcvectordb.VectorDBClient(url='http://10.0.X.X', username='root', key='eC4bLRy2va******************************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# 连接到数据库
db = client.database('test')
# 获取或创建集合
coll = db.collection("test_1")
3.连接好后,就可以对向量数据库中数据进行相关操作,通过查看文档API,可以实现刚才第二步骤上的平台数据操作流程,下面举几个例子
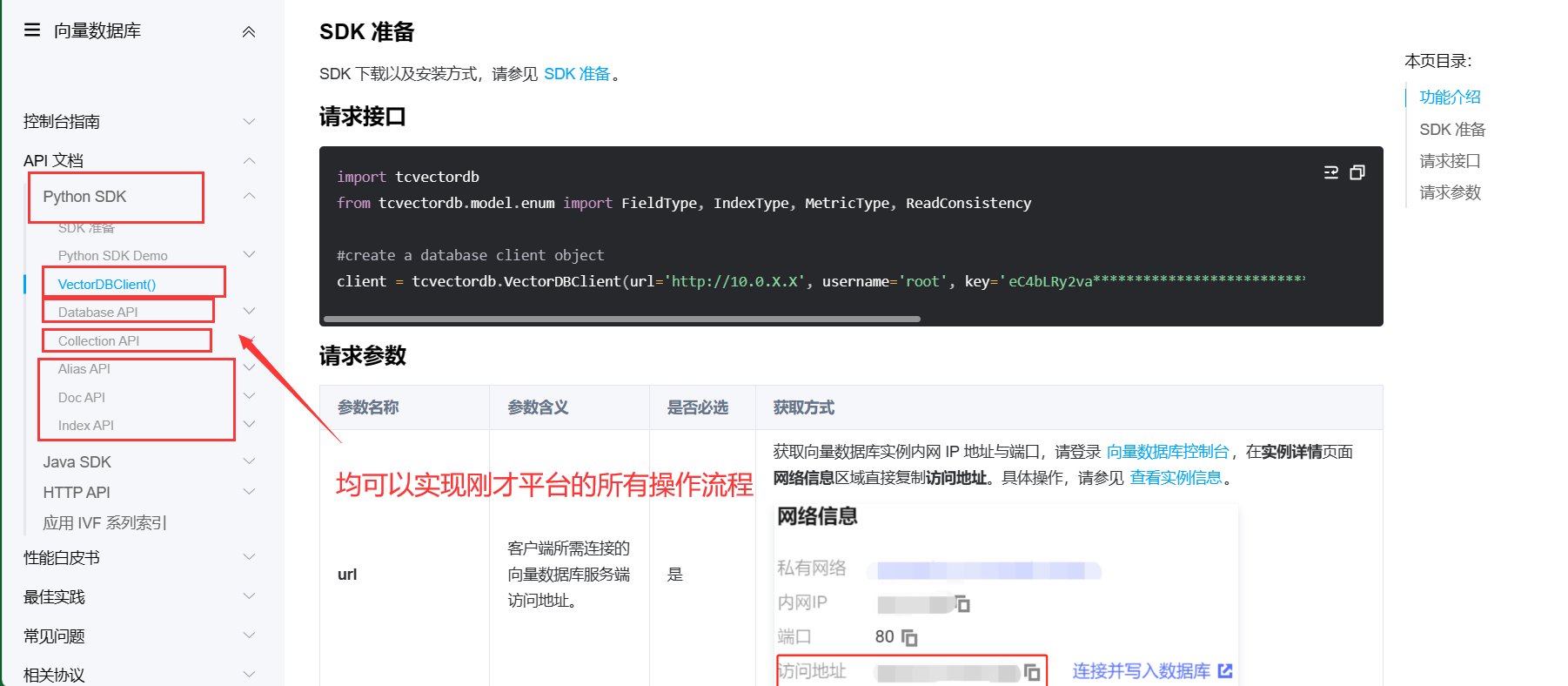 4. 如下图所示,可以根据文档进行代码编写,实现数据库和数据库中集合的相关操作
4. 如下图所示,可以根据文档进行代码编写,实现数据库和数据库中集合的相关操作
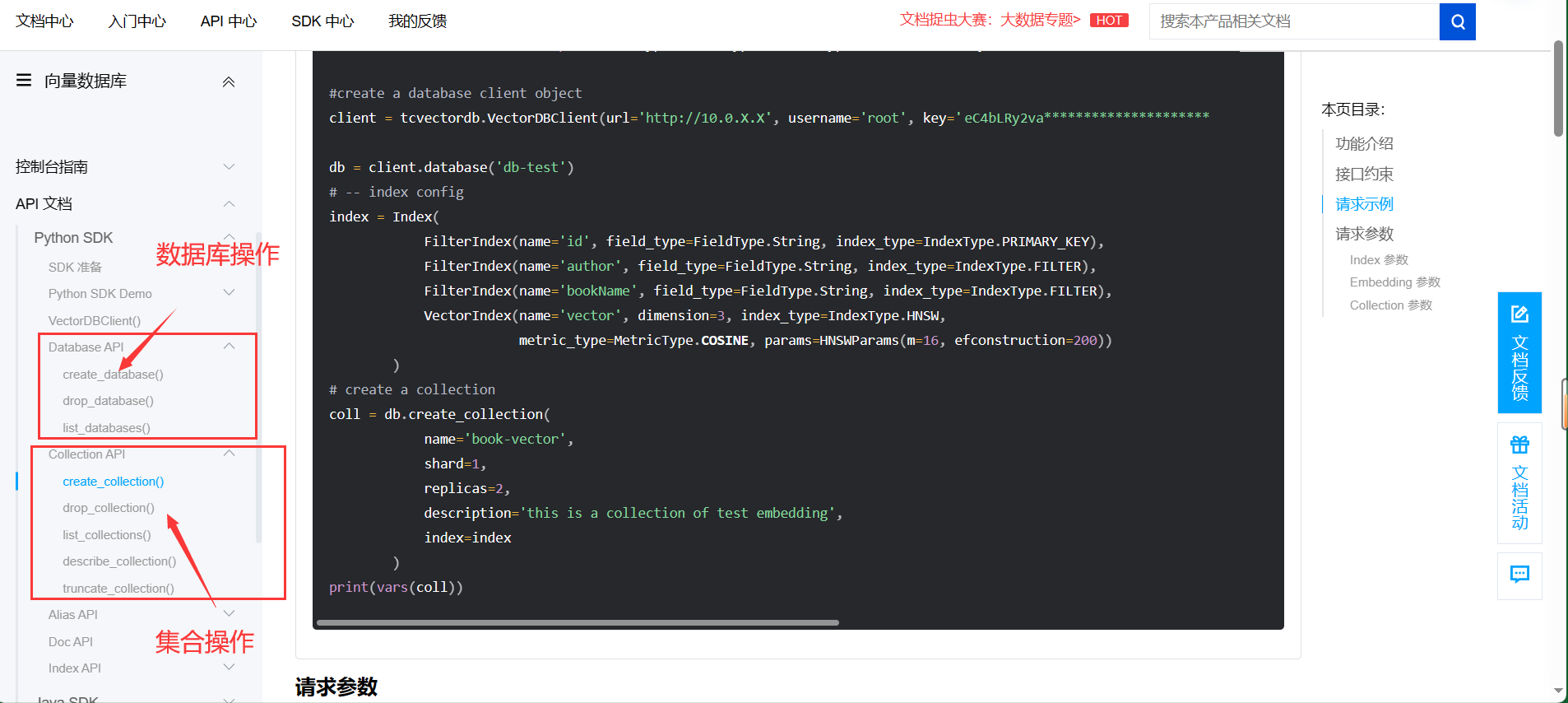
4. 以汽车相关数据进行分析预测
目的:通过数据分析根据二手汽车行驶的公里来预测汽车的二手价格
1.原数据:总共几万条二手汽车信息数据,处理之后存入向量数据库中,模拟实际情况

这里是处理一些脏数据,然后存入向量数据库中
def hadnle(data):
data = data[data.Km != '百公里内']
data = data[data.Boarding_time != '未上牌']
data = data[data.New_price != '暂无']
data = data[['Km', 'Sec_price', 'Boarding_time', 'New_price']]
data['New_price'] = data['New_price'].apply(lambda x: float(x.strip('万')))
def km_to_float(x):
return float(x.strip('万公里'))
data['Km'] = data['Km'].apply(km_to_float)
data['Boarding_time'] = (pd.to_datetime(data['Boarding_time'], format='%Y年%m月') - pd.to_datetime(
'2000-01-01')).dt.days / 30
data['Sec_price'] = data['Sec_price'].apply(lambda x: float(x))
return data
2.通过将部分汽车数据存储在向量数据库的集合中

3.可以通过学习官方API提取出想要的数据:

举例:根据需求从对应向量数据库的集合中提取中想要的数据
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams
from tcvectordb.model.document import Document, Filter, SearchParams
#create a database client object
client = tcvectordb.VectorDBClient(url='http://10.0.X.X', username='root', key='eC4bLRy2va******************************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
db = client.database('db-test')
coll = db.collection('book-vector')
# Set filter
filter_param=Filter(Filter.In("bookName",["三国演义", "西游记"]))
# query
doc_list = coll.query(document_ids=['0001','0002','0003'], retrieve_vector=True, filter=filter_param, limit=3, offset=0, output_fields=['bookName','author'])
for doc in doc_list:
print(doc)
4.通过机器学习方法对需要的数据进行分析:(具体情况根据)
线性回归分析:
data = hadnle(data)
# 根据需要选择输入和输出特征
X = data[['Km','Boarding_time','New_price']]
Y = data['Sec_price']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
# 使用线性回归模型
model = linear_model.LinearRegression()
#训练模型
model.fit(X_train, y_train)
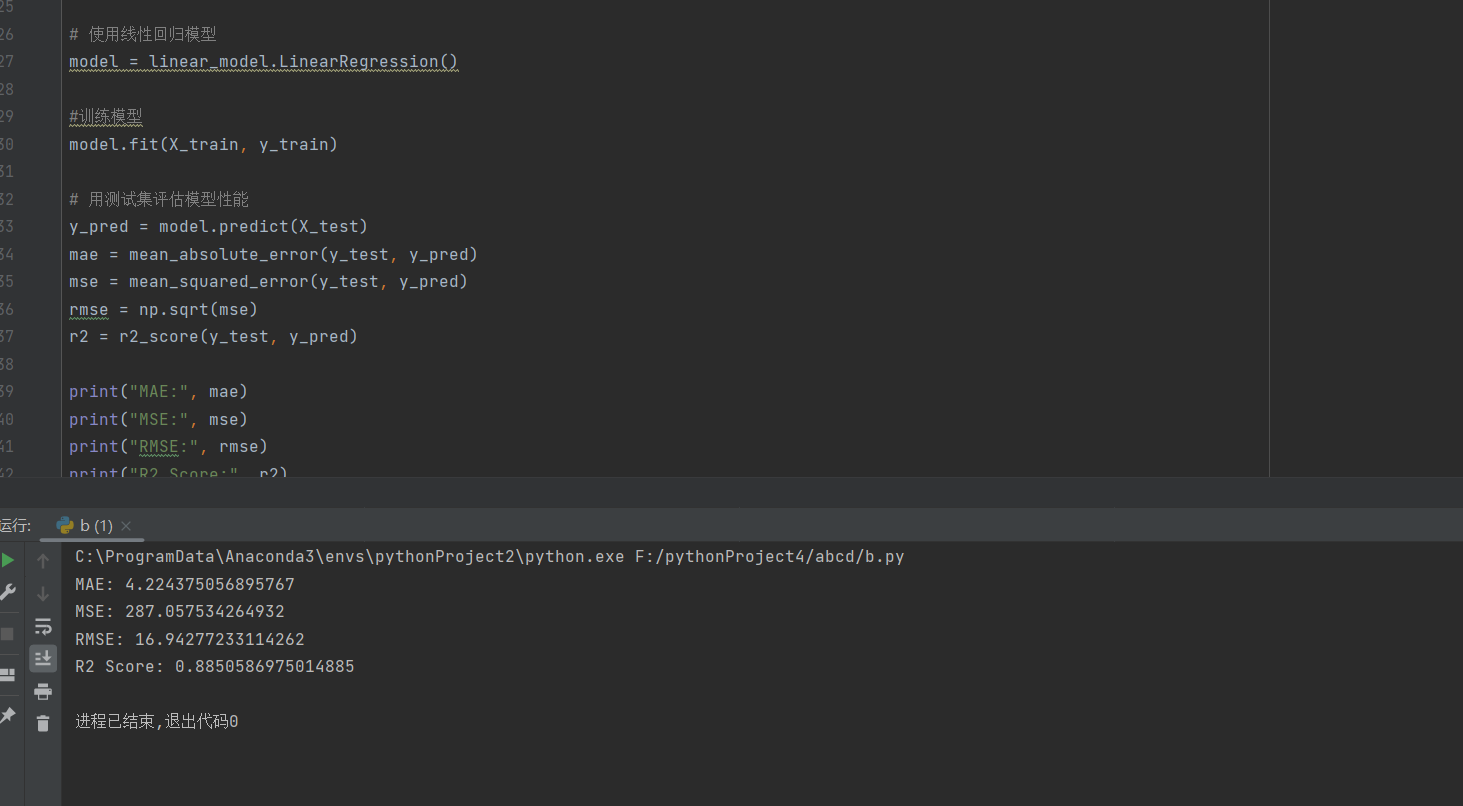
# 用测试集评估模型性能
y_pred = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
分析结果:
5.决策树回归模型分析:
data = hadnle(data)
# 根据需要选择输入和输出特征
X = data[['Km','Boarding_time','New_price']]
Y = data['Sec_price']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
# 创建决策树回归模型
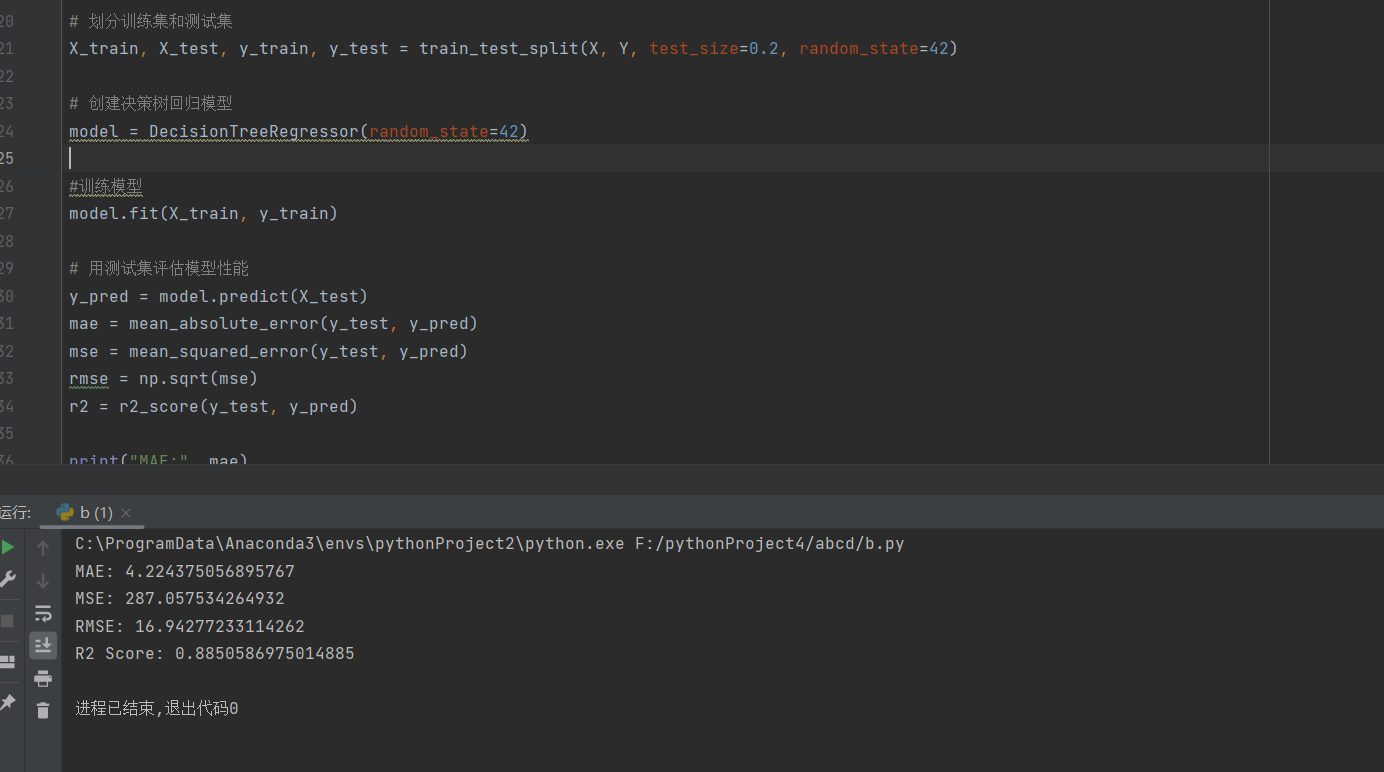
model = DecisionTreeRegressor(random_state=42)
#训练模型
model.fit(X_train, y_train)
# 用测试集评估模型性能
y_pred = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
分析结果:
6.随机森林模型分析:
data = hadnle(data)
# 根据需要选择输入和输出特征
X = data[['Km','Boarding_time','New_price']]
Y = data['Sec_price']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
#随机森林
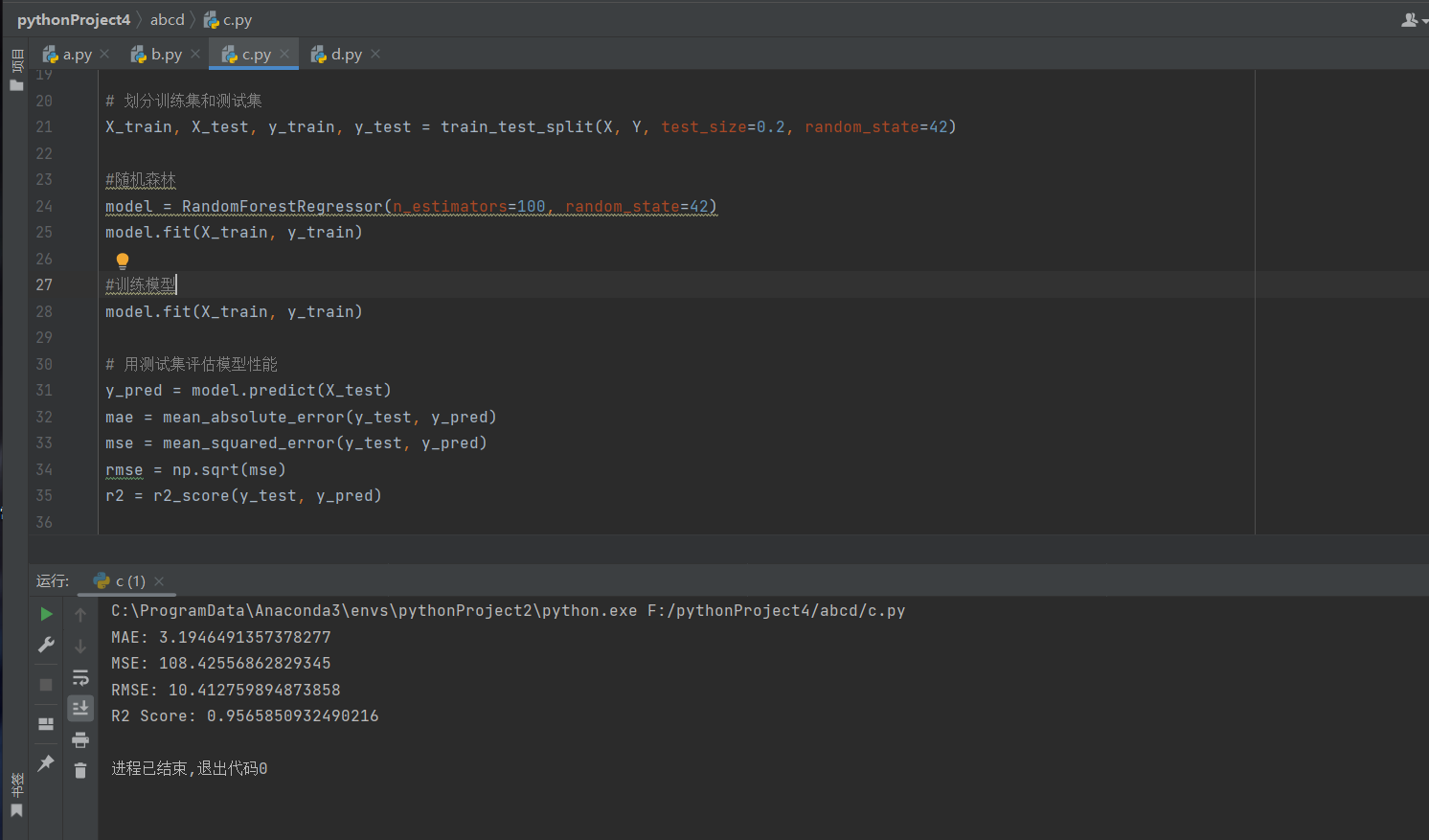
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
#训练模型
model.fit(X_train, y_train)
# 用测试集评估模型性能
y_pred = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
分析结果:
四、大数据时代下的数据挖掘的未来趋势
通过在向量数据库中存储经过AI模型训练的向量嵌入,能够实现高效的相似度搜索和近邻查询,从而显著提升查询速度。向量数据库不仅支持多模态数据的存储和检索,还能够处理各种不同类型的数据,包括文本、图像和音频等。这对于多模态AI应用,如视觉与语义检索以及多模态生成等,具有重要意义。
随着实时性能的不断提升,向量数据库将更好地满足实时数据检索和分析的需求,对预测分析、信息处理等领域产生深远的影响。我们可以期待数据库未来支持更多数据类型,包括但不限于图像、文本和音频,以更好地适应多模态数据的存储和检索。总体而言,向量数据库将为数据处理领域带来创新,为各行业提供更高效、智能的数据管理服务。
五、总结
通过这个参与活动体验腾讯云向量数据库,整体感觉使用起来非常棒,感兴趣的小伙伴可以通过下方方式了解更多信息,体验和使用向量数据库进行开发。也祝腾讯云向量数据库越来越好。