目录
JMeter的安装配置
测试的性能指标
TPS
响应时长
并发连接 和 并发用户
CPU/内存/磁盘/网络 负载
性能测试实战流程
JMeter
JMeter快速上手
GUI模式 运行
HTTP请求默认值
录制网站流量
模拟间隔时间
消息数据关联
变量
后置处理器
CSV 数据文件设置
断言
循环控制器
预处理器
命令行模式 运行
dashboard 产生图表
JMeter的安装配置
参考教程
测试工具JMeter详细安装配置教程(保证一次安装成功)_jmeter安装教程-CSDN博客
基本能成功,不能成功自己按报错自行搜索解决办法
测试的性能指标
参考链接
TPS
TPS (transaction per second) 是 服务端 每秒处理请求的数量
TPS 最直观的反映了 系统的处理能力,当然是重要的性能指标之一。
说到 TPS ,和其相关的还有如下这些名词:
-
RPS (request per second) 是 测试工具 每秒发送请求的数量
RPS 和 TPS 概念不同,前者是每秒发出的请求数量。后者是处理完成的请求数量。
但是显然,RPS 是决定 TPS 的重要因素。
TPS 是由 RPS 、网络延迟 、服务端本身的处理速度 这3个因素决定的。
一个性能表现良好的系统,TPS和RPS几乎是相同的
-
EPS (error per second) 是 服务端 每秒处理出错的数量,也包含在TPS中。
一个性能表现良好的系统,EPS 应该一直为0
-
TOPS (timeout per second) 是 服务端 每秒处理超时的数量
超时时间具体是多少,应该由产品需求定义。
一个性能表现良好的系统,TOPS 应该一直为0
前面说过 TPS 是由 RPS 、网络延迟 、服务端本身的处理速度 这3个因素决定的。
服务端本身的处理速度 就是我们要测试的,测试时,我们要保证的是其他两个因素:RPS 和 网络延迟。
做 性能/压力测试 时, 被测系统和加压系统, 应该在一个带宽网速比较理想的环境中,首先保证网络延迟没有问题。
然后,性能测试工具要测试TPS能否达到 , 主要就是设置每秒发送请求的数量,也就是RPS。
RPS 是由测试工具决定的。
一个压测工具本身的加压性能也很重要。
否则,如果TPS指标比较高,工具本身做不到,就没法测试了。
如果服务端性能无限强,网络无限好,在目前的主流机器上,压测能做到
单进程 Windows系统 2000-5000 RPS, Linux系统下3000-6000 RPS
整机大概在 6000-12000 RPS
定义的一种客户端 里面的行为代码 就决定这种客户端的 RPS
总RPS = 客户端1 RPS * 客户端1数量 + 客户端2 RPS * 客户端2数量 + …
所以,关键看你的客户端行为定义 和 客户端数量定义。
一个性能表现良好的系统,TPS 和 RPS 几乎是相同的。
所以,通常测试指标TPS是多少,工具设置的RPS就是多少。
当然,如果服务端本身的性能不够,TPS自然也会相应的下降。这时,可以相应的提升一下压测工具的RPS
在测试过程中会产生日志文件,记录每秒 RPS、TPS、EPS、TOPS。
可以对测试数据进行统计作图。
注意:RPS、TPS、TOPS 都不需要我们做什么,工具会自动记录。
但是 EPS,必须要我们自己写代码,对响应数据进行检查,并且告知黑羽压测。
因为工具本身不了解业务逻辑,什么样的因为数据是错误的,工具没法预先知道。
响应时长
响应时长 就是 服务端 处理请求耗费的时间
平均响应时长
平均响应时长 就是 服务端 处理请求的平均耗费时间。
这是影响用户体验的重要指标。设想一下如果 TPS 很高,但是,很多请求要很长时间才得到反应,是什么样的用户体验。。。
在测试过程中会产生日志文件,记录每秒 平均响应时长。
响应时长区段统计
光看平均响应时长,往往是不全面的。
可能 有些请求会耗时特别长,严重影响用户体验。但是被平均了就看不出来。
响应时长不能两极分化。
响应时长区段统计就是查看是否两极分化的衡量指标。
并发连接 和 并发用户
并发连接数 是 服务端 和客户端 建立的 TCP连接的数量
并发用户数 是 服务端 同时服务的 用户的数量 。
用户的一个操作可能引发多个并发连接。
并发连接
通常,并发连接数指标,适用于 测试 面向客户端程序的 API服务系统,比如 云服务。
和 TPS 对系统性能的衡量侧重点不同 ,并发连接数指标 衡量 系统 能 同时处理 客户的能力。
两者的区别 用一个比方 来解释,就像银行服务:
并发连接数,就像有多少个服务窗口
TPS, 就像每个窗口 服务员的处理速度
每个窗口服务员的处理速度即使很快,但是同时来了很多人,也必须开多个窗口,否则就会有人得不到服务。
对 并发连接 指标, 是通过 客户端和性能场景 的定义来 设置的 。
如果,这样定义客户端
client = HttpClient('192.168.2.103',timeout=10)
while True:
response = client.sendAndRecv(
'GET',
'/api/path1'
)
sleep(60) # 间隔60秒这样定义性能场景
createClients(
'client-1', # 客户端名称
1000, # 客户端数量
0.1, # 启动间隔时间,秒
)就会每隔1秒创建10个客户端(同时也建立了10个并发连接),直到并发连接数达到1000。
上面代码中,每个客户端发送请求消息间隔时间是60秒。如果服务端 保持连接的时长小于60秒(比如 Nginx就是通过 keepalive_timeout 50; 这样设置的),就会造成连接 被 服务端主动断开,下次次发送请求要重新进行连接。
Linux下 可以通过 如下命令 查看并发连接的数量
netstat -an | grep ESTABLISHED | grep -w 80 | wc -l作为客户端,本地可以打开的socket 数量 受操作系统的限制。
我测试过,
在 Windows 10 专业版 16G内存 可以打开6万个并发连接
而在Linux上通过修改 ip_local_port_range 参数,也可以打开 6万个并发连接。
并发用户
通常,并发用户数指标,适用于 测试 面向真实用户的 系统,比如 淘宝。
一个用户的一个操作可能引发多个并发连接
单独说 并发用户数 这个指标没有意义, 必须指定是 哪种性能测试场景 下的并发用户数。
因为用户的操作行为不一样,对服务端的 请求数量 和 并发连接数也不一样。
而且并发用户指标 是 一段时间 内 的,说某个时间点的 并发用户数 也没有意义,因为该点上,很多用户可能没有任何操作。
CPU/内存/磁盘/网络 负载
我们做性能测试时,不能只看 TPS、响应时长 等指标是否达到,也要看被测系统在达到这些指标时,机器本身的负载情况。
所谓负载情况,主要是: CPU占用率, 内存使用,磁盘IO、磁盘使用率。
测试结束后可以产生系统资源使用图。
在性能测试分析时,我们主要关注这两点
- 是否接近满负荷
如果在达到这些指标时,机器已经处于满负荷状态:CPU使用率 接近 100%, 内存几乎用光,那也是不行的。 因为随时系统可能出问题。
就是说再加点压力,或者再持续一段时间,就很可能出现响应超时甚至响应错误的情况。
- 是否资源使用持续上升
这点特别体现在 内存使用率 上。
如果系统资源使用图上,内存使用率是一个斜线不断上升,的情况,那么很可能被测系统存在内存泄露。
这样只要再持续一段时间,就很可能出现系统因内存耗尽而奔溃的现象。
出现这样的图表,就应该添加测试用例,做一个较长时间的性能测试(longevity testing),观查系统的行为。
性能测试实战流程
参考教程
JMeter
JMeter快速上手
参考链接:
安装他提供给我的网站:安装运行 | 白月黑羽 (byhy.net)
GUI模式 运行
运行JMeter 有2种运行模式: GUI 图形界面模式 和 CLI 命令行模式
前者是开发调试用的,后者才是真正执行压力测试时用的
现在就是开发阶段,当然先使用 图形界面模式,等调试没有问题,再使用命令行模式
HTTP请求默认值
测试过程中,被测系统换了, 就要换配置的地址, 要手动修改 请求参数,请求取样器多了, 就非常麻烦了。
可以使用HTTP请求默认值 解决这个问题。
录制网站流量
JMeter提供了录制浏览器的请求的方法,使用的是代理抓包的机制。
-
确保
HTTP请求默认值里面的服务器IP 和录制的网址一致否则录制时,每个HTTP请求里面都会带上IP,还得手工修改删除,不利于统一使用
HTTP请求默认值里面的服务器IP。 -
在整个测试计划下面添加
HTTP代理服务器英文叫
HTTP(S) Test Script Recorder -
在
线程组里面 添加逻辑控制器 -> 录制控制器 -

-
设置
HTTP代理服务器-
分组 选项 选择:
将每个组放到新的事物控制器中 -
如果你需要录制时过滤掉一些请求
点击Request Filtering 配置页,
排除模式下 添加 你要 过滤掉 不抓取的 的类型资源 ,使用的是正则表达式
- 点击代理服务器的启动按钮

-
-
设置浏览器代理为 本机(localhost) 的 8888端口,进行对应的界面操作
应该发现抓到了相应的请求。
其中,配置过程中遇到了JMeter录制不上的情况,按照下面的方法来
jmeter性能测试脚本录制不了的几种情况_jmeter录制脚本不成功_曹红杏的博客-CSDN博客
这个问题前后花了我三四个小时,上述教程我在很前期就见过,也照着做了,但是在查ip的时候我偷懒在浏览器搜的本机ip,查到的是本机对外(公网)的一个ip,但是教程中用的是一个局域网ip,导致就各种尝试都不对,真tm开心。
具体流程如下:
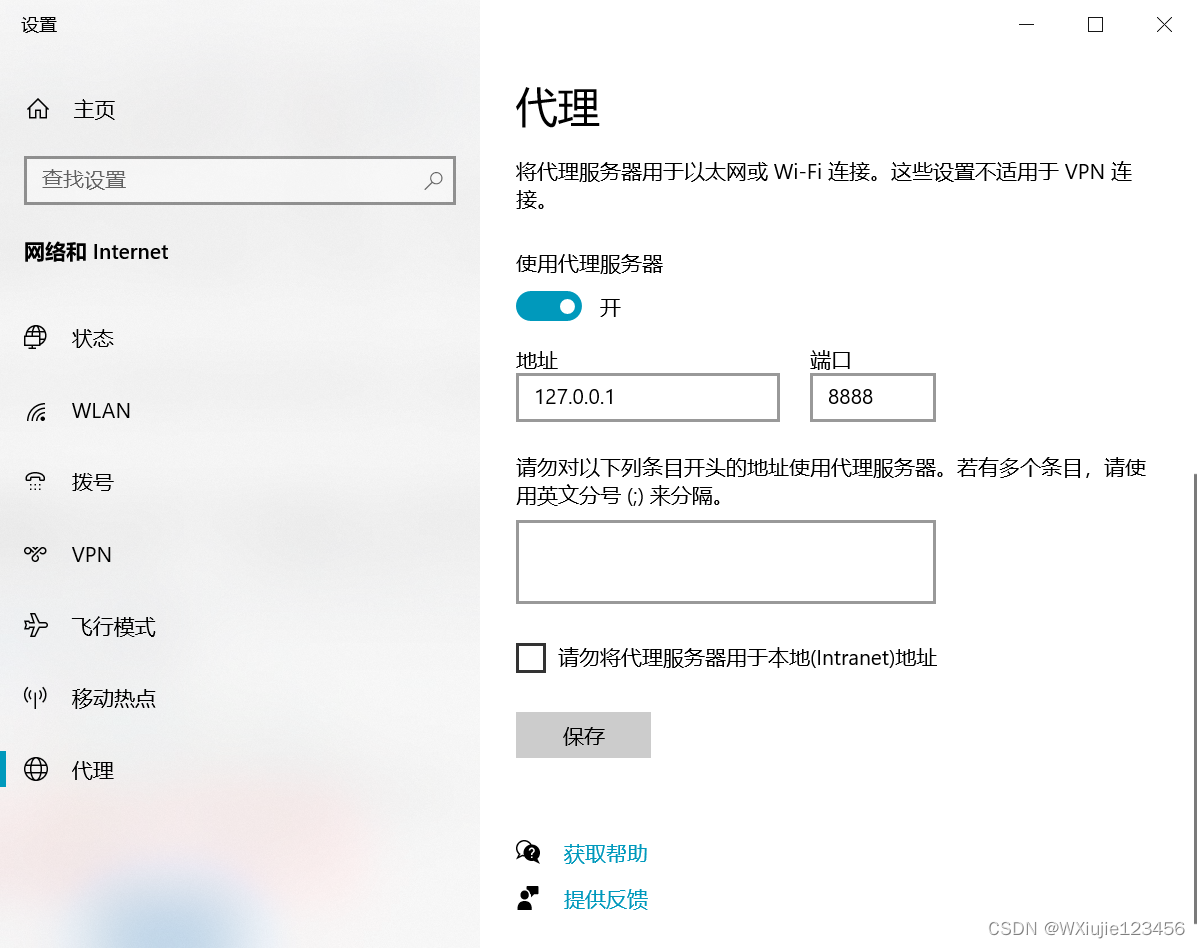
edge浏览器下:设置->搜索“代理”
注意,浏览器访问要录制的页面要设置成本机ip的方式访问(有坑:外网IP和内网ip的区别-CSDN博客)
基本就可以录制了。
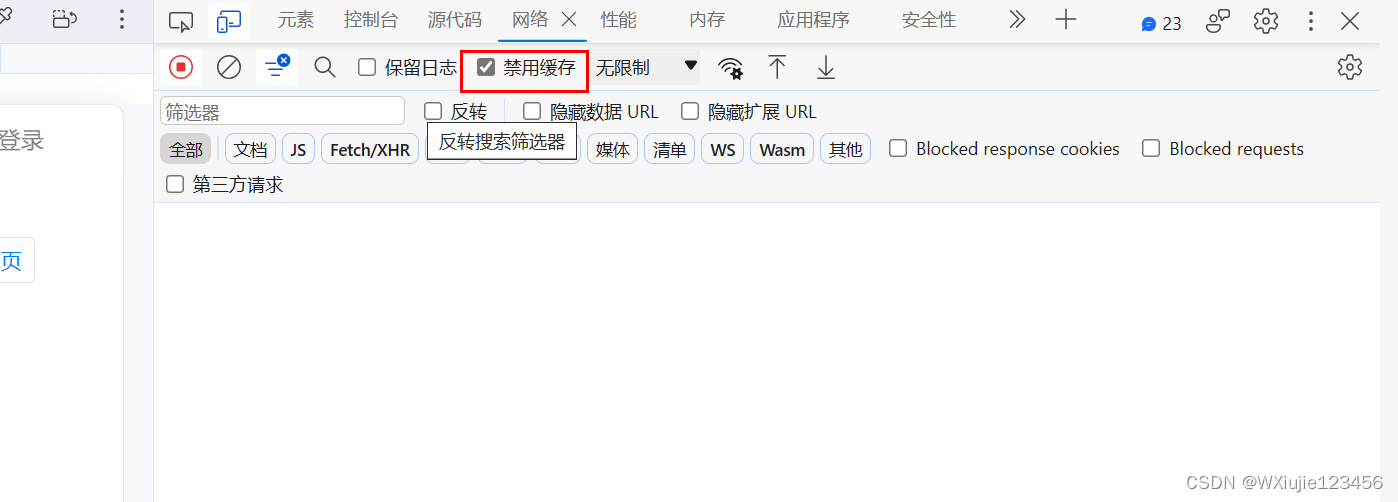
对了要注意 它录制的是一定时间间隔内操作的网络访问所以在录制时,浏览器窗口还是尽可能干净些吧。
此外打开f12,关闭cookie缓存

-
右键点击
录制线程组点击验证,查看一下是否能正确模拟 -
继续其它场景的录制和拖动
-
结束录制,修改浏览器设置,取消代理
模拟间隔时间
场景1中两组请求中间没有间隔,不符合实际情况。
怎么让它们有间隔呢?
可以使用 JMeter的 定时器 Timer
定时器 执行优先级高于 取样器, 会先暂停, 可以放在下一个消息的前面
也可以使用 取样器 里面的 测试活动 flow control action 取样器
Cookie管理器
假设现在有一个性能测试用例,要求:
用户数量 1200 个,
账号为 sz_000001 ~ sz_001200, 密码都是 111111
在10分钟依次进行如下操作 :
打开登录页,进行登录后,进入首页
如果你还用前面录制的方式,录制后,验证一下,就可以发现:
有些后续的API请求返回的结果是错误,返回信息表示,没有登录。
即使前面 发送的登录请求返回表示成功了。 为什么呢?
这是因为 这个被测系统 使用的 用户验证机制是 Cookie Session机制
这就需要 让JMeter自动把接收到的 HTTP 响应消息中的 Cookie 保存起来,并且在后续发给该网站的请求中自动携带上, 可以在测试计划节点下面添加一个 HTTP Cookie管理器

效果
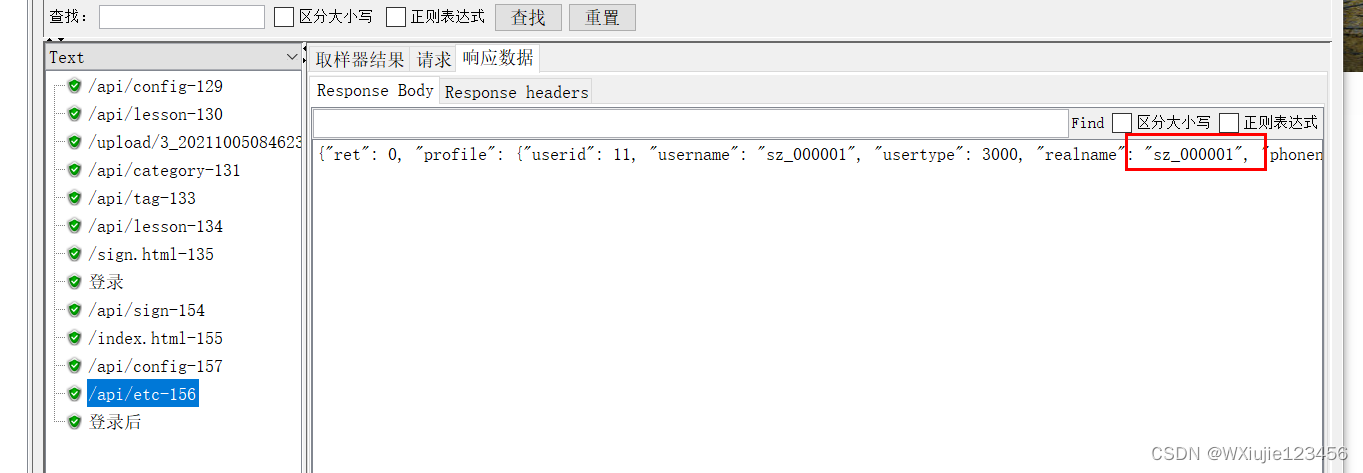
消息数据关联
做API接口性能测试的时候,后面的请求参数 往往 需要 根据前面的请求结果 来决定。
这样,测试工具填入的数据就是动态的,没法预先写死。
比如前面的测试场景,后续还需要做如下操作:
用户登录后,打开 学习中心 -> 我的任务 页面,查看前2个任务。
这样,就要获取前2个任务的id, 因为每个学员 任务分配 的id都是不一样的。
JMeter 需要 从 前面 列出任务的 HTTP API响应结果 里面提取出 ID, 供后面的请求使用。
如何做到呢?
这就要使用 后置处理器 和 变量 。
JMeter 通过 后置处理器 取出 取样器响应结果中 要提出取出来的数据, 存入变量,后续请求使用这些变量。
变量
JMeter中,使用变量,是通过 ${变量名} 这样的格式
变量可以用户自己定义产生,也可以由前置处理器、后置处理器 等 JMeter 元件产生。
有的是JMeter内置变量,比如表示当前线程号的变量 __threadNum ,就可以这样使用 ${__threadNum}
后置处理器
后置处理器通常用于对 取样器 结果进行后续处理。
后置处理器 的有效范围是 同级所有取样器,如果只要针对某个取样器,应该添加在它下面
常用的一个后置处理器是 JSON提取器 , 可以把 HTTP响应消息中的数据提取到变量中,供后续使用
说明文档:https://jmeter.apache.org/usermanual/component_reference.html#JSON_Extractor
测试网页: http://jsonpath.herokuapp.com
具体操作纪律:
打开录制功能,分别录制下面的 动作

分别点击下面两个按钮
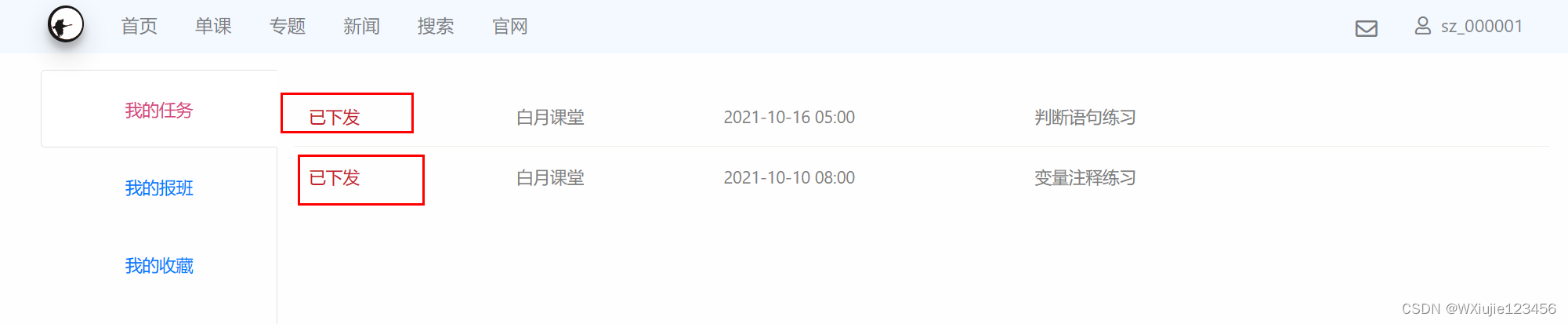

这些操作尽可能快的做完,录制上,然后点击自己录制的结果,翻阅一下,把链接不是来自192.168.172.1的那些请求删掉(可能是浏览器本身在刷新访问其他页面,含有一些隐形的操作也被录了进来)
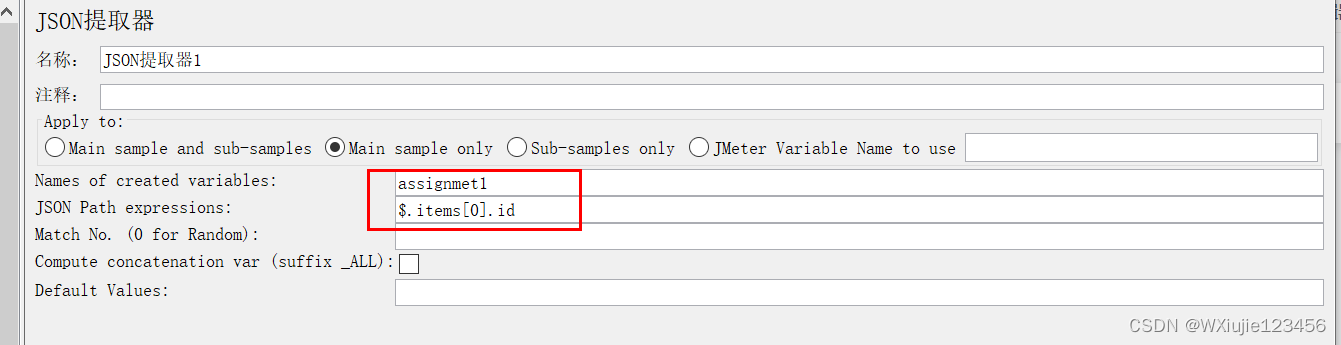
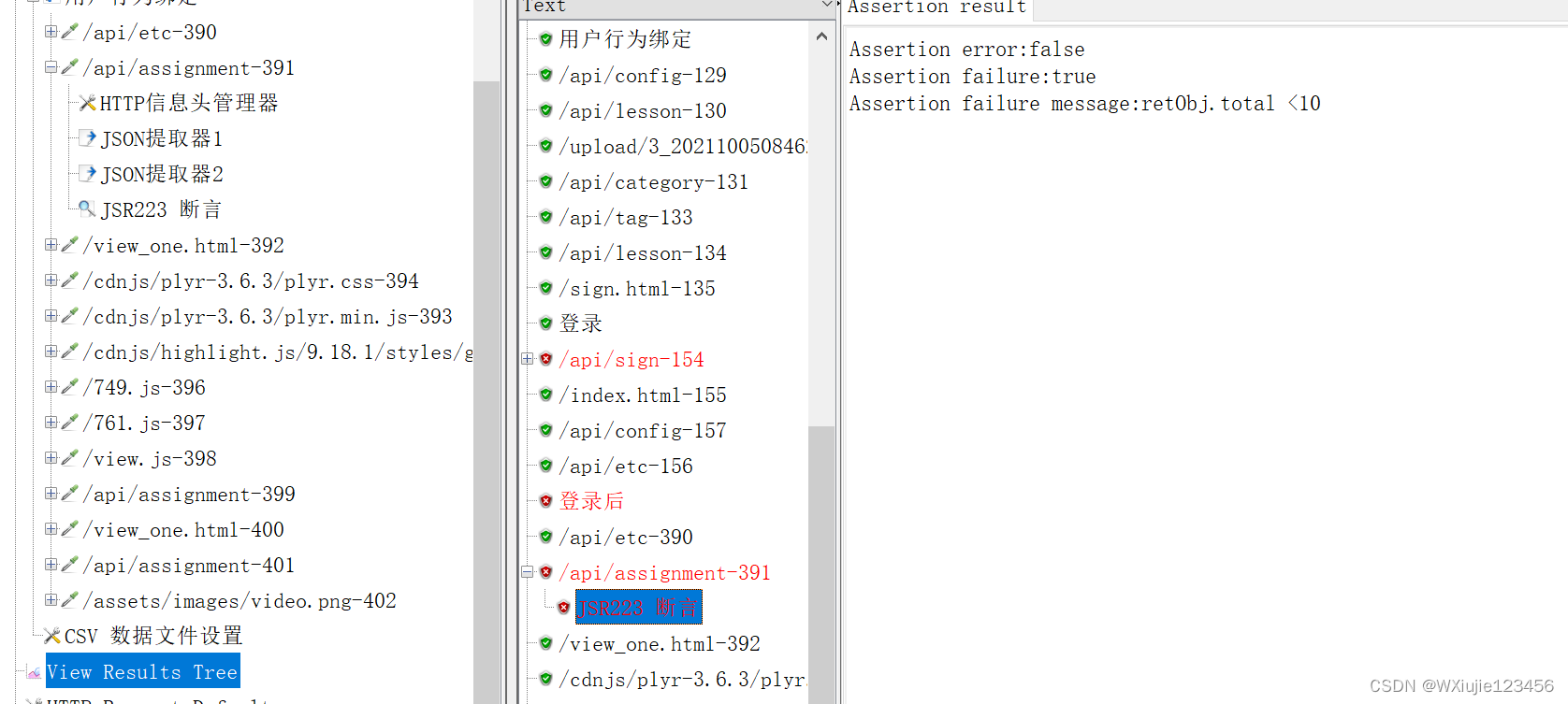
然后把这批请求组成的事务拖动到含有登录操作的线程组下面,阅读接口 手册(或者自己简单翻阅一下或者网页查看f12),找到单击动作得到的id值对应的请求链接(上面那张截图的两个“我的任务”的访问需要这个id),然后给这个请求“/api/assignment-391”添加后置处理器->Josn提取器。

提取器的设置如下
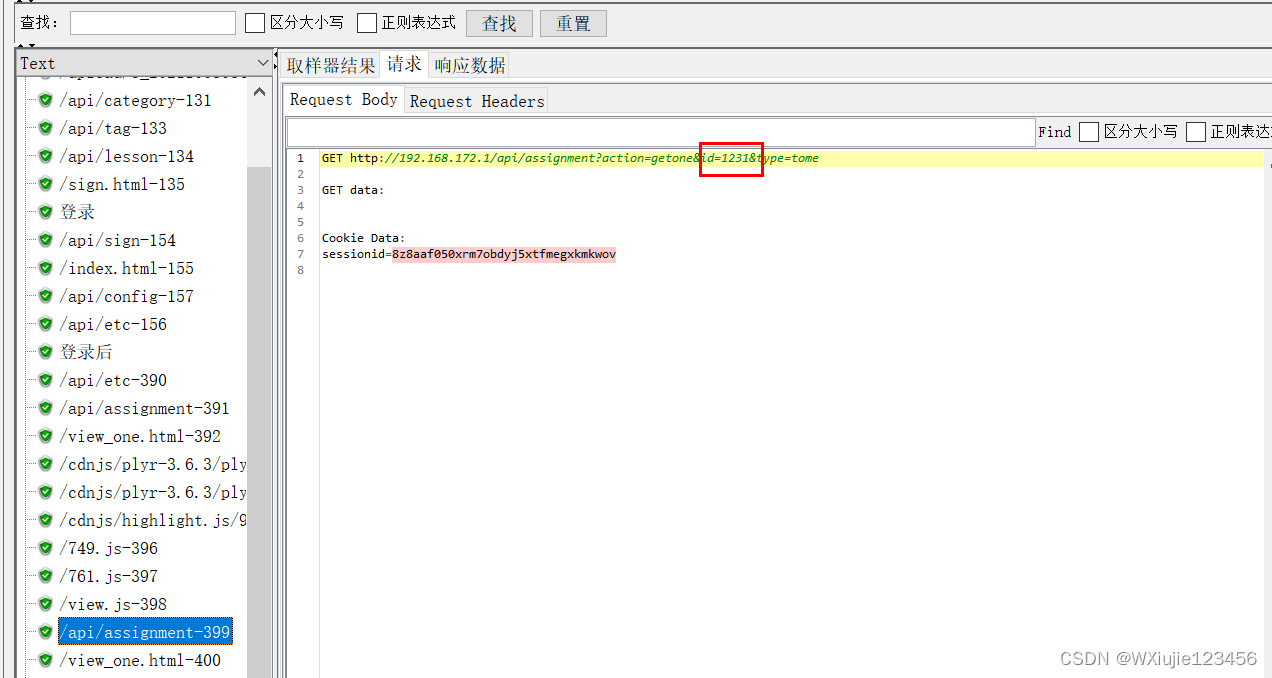
然后将上面JSON提取器设置的变量给需要引用他的页面引用一下

然后 验证一下有没有成功,下图可见传参成功
HTTP响应中有UTF8编码的中文显示为乱码,可以再设置一个 BeanShell PostProcessor 类型的后置处理器,并且在 Script 中增加 prev.setDataEncoding("UTF-8");
CSV 数据文件设置
有时候,性能测试有大量的数据 需要从 CSV 格式的文件读入使用。
CSV格式的文件,其实就是文本文件,里面记录了性能测试数据,比如
sz_000001,111111
sz_000002,111111
sz_000003,111111
这时,可以在某个 线程组下面 添加 CSV data set config(CSV 数据文件设置) 元件
CSV 数据文件设置可以为每列设置一个变量名,比如上例就是 loginname,password
JMeter会把 每行数据依次分配给一个线程。
这样,每个线程里面的元件 就可以使用 这些变量 ,得到对应的数据。
具体使用 点击这里参考官方文档
得到csv文件的方式 :上面的三行数据拷贝放到一个空的data.txt文件中,然后改后缀为csv
设置如下,可见又设置了两个变量

引用两个变量

断言
利用JMeter断言, 可以判定 从被测系统 收到的响应消息是否正确。
断言的有效范围是 同级所有取样器,如果只要针对某个取样器,应该添加在它下面。
例如,可以判断响应是否包含某些特定文本、数据。
甚至可以使用 Groovy、 BeanShell 这样的脚本语言做 更加灵活的断言判定。
比如下面使用 JSR223 断言 脚本,可以检查JSON格式消息体响应中的total字段值是否小于10
import groovy.json.JsonSlurper
def jsonSlurper = new JsonSlurper();
def retObj = jsonSlurper.parseText(prev.getResponseDataAsString());
if(retObj.total < 10){
AssertionResult.setFailureMessage("retObj.total <10");
AssertionResult.setFailure(true);
}



循环控制器
线程组可以整体循环, 但是如果你只想循环 线程组其中的一部分操作呢?
比如:
用户登录一次, 后续操作循环10次,每次间隔20秒 可以使用循环控制器。
循环控制器 内部的元件有时 需要用到 当前循环序号 。
JMeter 的当前循环序号放到变量 __jm__<循环控制器名称>__idx 中。
比如你的 循环控制器 名为 LC, 你就可以通过 ${__jm__LC__idx} 访问到 当前循环序号。

预处理器
预处理器 在取样器请求 发出前执行一些操作
用的比较多的是:设置一些参数、修改取样器的设置、脚本预处理
有效范围是同级所有取样器,如果只要针对某个取样器,应该添加在它下面。
常用的有 用户参数、HTML链接解析器、JSR223/BeanShell 等前置处理器
比如,下面JSR223前置处理器的代码可以把一个 当前循环序号变量值进行预先处理 加1。
long number = Long.parseLong(vars.get('__jm__LC1__idx'))
number = number + 1;
vars.put('loopno',String.valueOf(number))
// OUT.println vars.get('loopno')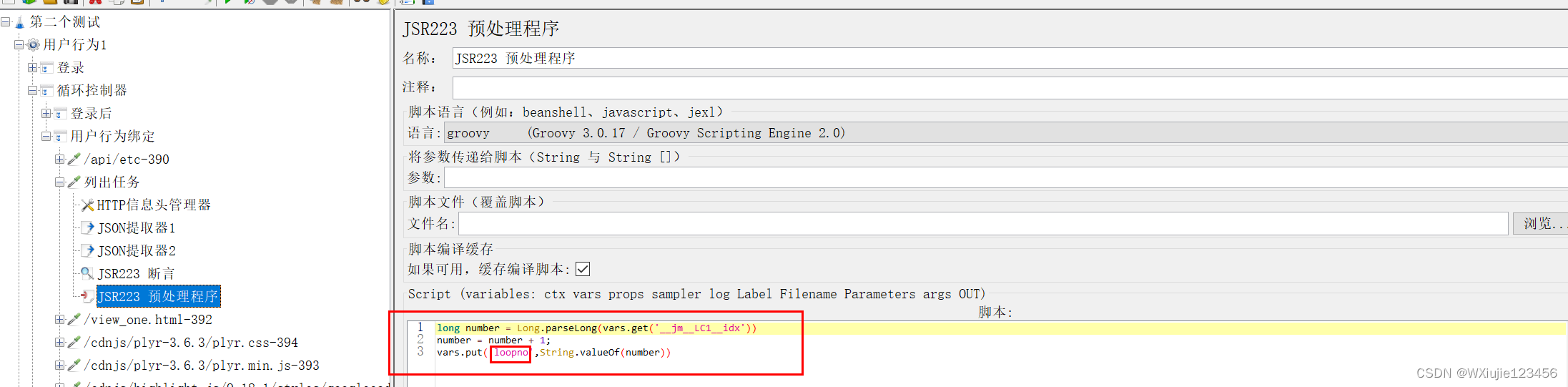

命令行模式 运行
真正实施性能测试应该在命令行模式下运行,命令格式如下:
E:\apache-jmeter-5.6.2\bin\jmeter -n -t loadtest-case1.jmx -l log.jtl注意JMeter的路径替换为你的安装路径
假设 我们有如下的性能测试用例
只有一种用户行为:
无需登录,先访问首页,再访问 单课页 ,再访问 新闻页
访问页面间隔 10 秒
用户数量 1200 个,在10分钟依次上线
dashboard 产生图表
E:\apache-jmeter-5.6.2\bin\jmeter -g log.jtl -o report1就会产生report1目录,里面的index.html 打开就是报告
注意 -o 后面的目录 一定要不存在,或者内容为空,否则会报错。
其中 APDEX (Application Performance Index) 里面的 T (Toleration threshold) 和 F (Frustration threshold) 可以通过 JMeter 工具 bin 目录下面的 user.properties 配置文件里面 这两个选项来设置
jmeter.reportgenerator.apdex_satisfied_threshold
jmeter.reportgenerator.apdex_tolerated_threshold我的一些结果


我本机结果比较抽风,领会精神吧






![[黑马程序员SpringBoot2]——原理篇1](https://img-blog.csdnimg.cn/09fa9c56c3004373be0d7bf359624031.png)