目录
一、前言
二、完成情况
2.1 OpenFWI工程文件框架的理解
2.2 InversionNet网络的理解
2.3 dataset.py的理解
三、遇到的部分问题及解决
3.1 数据读取
3.2 Dataloader中设置num_workers-MemoryError
3.3 RuntimeError: CUDA out of memory
3.4 loss值的变化
四、相关参考
五、总结
5.1 存在的疑惑
5.2 下周计划
一、前言
上周学习OpenFWI的部分代码并完成了Dataset的重写。
本周计划抄写OpenFWI代码中的InversionNet网络相关部分并理解。
二、完成情况
2.1 OpenFWI工程文件框架的理解
OpenFWI中包含的文件如下:

- data_files:存放数据集(包括训练集与测试集)
- dataset.py:数据加载
- dataset_config.json:数据加载相关参数设置
- network.py:网络的定义(其中包含三个网络—接下来的文章中只介绍InversionNet相关代码)
- pytorch_ssim:SSIM包
- rainbow256.npy
- scheduler.py:学习率的调整
- test.py:进行测试
- train.py:进行一般网络的训练
- transforms.py:数据转换,对数据进行处理
- utils.py:loss定义与评价指标
- vis.py:地震数据与速度模型的可视化展示
2.2 InversionNet网络的理解
InversionNet网络的理解:网络框架学习之InversionNet-CSDN博客
InversionNet(深度学习实现的反演)构建了一个具有编码器-解码器结构的卷积神经网络,用以模拟地震数据与地下速度结构之间的对应关系。
网络搭建如下:
class InversionNet(nn.Module):
def __init__(self, dim1=32, dim2=64, dim3=128, dim4=256, dim5=512, **kwargs):
'''
Network architecture of InversionNet
:param dim1: Number of channels in the 1st layer
:param dim2: Number of channels in the 2nd layer
:param dim3: Number of channels in the 3rd layer
:param dim4: Number of channels in the 4th layer
:param dim5: Number of channels in the 5th layer
:param sample_spatial: Scale parameters for sampling in space
'''
super(InversionNet, self).__init__()
# ConvBlock中进行了封装,包括二维的卷积操作、批归一化BN以及Relu三个操作
self.convblock1 = ConvBlock(5, dim1, kernel_size=(7, 1), stride=(2, 1), padding=(3, 0))
self.convblock2_1 = ConvBlock(dim1, dim2, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))
self.convblock2_2 = ConvBlock(dim2, dim2, kernel_size=(3, 1), padding=(1, 0))
self.convblock3_1 = ConvBlock(dim2, dim2, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))
self.convblock3_2 = ConvBlock(dim2, dim2, kernel_size=(3, 1), padding=(1, 0))
self.convblock4_1 = ConvBlock(dim2, dim3, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))
self.convblock4_2 = ConvBlock(dim3, dim3, kernel_size=(3, 1)
self.convblock5_1 = ConvBlock(dim3, dim3, stride=2)
self.convblock5_2 = ConvBlock(dim3, dim3)
self.convblock6_1 = ConvBlock(dim3, dim4, stride=2)
self.convblock6_2 = ConvBlock(dim4, dim4)
self.convblock7_1 = ConvBlock(dim4, dim4, stride=2)
self.convblock7_2 = ConvBlock(dim4, dim4)
self.convblock8 = ConvBlock(dim4, dim5, kernel_size=(8, math.ceil(70 * 1.0 / 8)), padding=0)
self.deconv1_1 = DeconvBlock(dim5, dim5, kernel_size=5)
self.deconv1_2 = ConvBlock(dim5, dim5)
self.deconv2_1 = DeconvBlock(dim5, dim4, kernel_size=4, stride=2, padding=1)
self.deconv2_2 = ConvBlock(dim4, dim4)
self.deconv3_1 = DeconvBlock(dim4, dim3, kernel_size=4, stride=2, padding=1)
self.deconv3_2 = ConvBlock(dim3, dim3)
self.deconv4_1 = DeconvBlock(dim3, dim2, kernel_size=4, stride=2, padding=1)
self.deconv4_2 = ConvBlock(dim2, dim2)
self.deconv5_1 = DeconvBlock(dim2, dim1, kernel_size=4, stride=2, padding=1)
self.deconv5_2 = ConvBlock(dim1, dim1)
self.deconv6 = ConvBlock_Tanh(dim1, 1)2.3 dataset.py的理解
# 重写Dataset
class FWIDataset(Dataset):
''' FWI dataset
For convenience, in this class, a batch refers to a npy file instead of the batch used during training.
Args:
anno: path to annotation file # 注释文件的路径
train: whether to load the whole dataset into memory # 是否将整个数据集加载到内存中
sample_ratio: downsample ratio for seismic data # 地震数据的下采样率
file_size: of samples in each npy file # 每个npy文件中的样本数
transform_data|label: transformation applied to data or label # 数据或标签的转换
'''
# 初始化函数:加载数据—初始化文件路径与文件名列表,完成初始化该类的一些基本参数
def __init__(self, anno, preload=True, sample_ratio=1, file_size=500, transform_data=None, transform_label=None):
# 判断文件路径是否存在
if not os.path.exists(anno):
print(f'Annotation file {anno} does not exists')
# 对继承自父类Dataset的属性进行初始化
super(FWIDataset, self).__init__()
self.preload = preload
self.sample_ratio = sample_ratio
self.file_size = file_size
self.transform_data = transform_data
self.transform_label = transform_label
# 以“只读”的方式打开文件,默认文件访问模式为“r”
with open(anno, 'r') as f:
# 读取所有行并返回列表(列表可由for...in...结构进行处理)
self.batches = f.readlines()
# 判断是否需要将整个数据集加载到内存中
if preload:
self.data_list, self.label_list = [], []
# 循环加载数据
for batch in self.batches:
# 读取每个batch中的数据与标签
data, label = self.load_every(batch)
# 将data添加到列表中
self.data_list.append(data)
if label is not None:
self.label_list.append(label)
# Load from one line
def load_every(self, batch):
# \t :表示空4个字符,类似于文档中的缩进功能,相当于按一个Tab键(txt文件需要根据这个进行分隔)
# split():通过置顶分隔符对字符串进行切片,并返回分割后的字符串列表(list)
# os.path.split():按照路径将文件名和路径分割开
batch = batch.split('\t')
# 切片:除最后一个全取
data_path = batch[0] if len(batch) > 1 else batch[0][:-1]
# np.load():读取数据
data = np.load(data_path)[:, :, ::self.sample_ratio, :]
# astype():转换数据的类型
data = data.astype('float32')
if len(batch) > 1:
label_path = batch[1][:-1]
label = np.load(label_path)
label = label.astype('float32')
else:
label = None
# 返回数据与标签
return data, label
# 对数据进行预处理并返回想要的信息
def __getitem__(self, idx): # 按照索引读取每个元素的具体内容
# //:向下取整
batch_idx, sample_idx = idx // self.file_size, idx % self.file_size
if self.preload:
data = self.data_list[batch_idx][sample_idx]
label = self.label_list[batch_idx][sample_idx] if len(self.label_list) != 0 else None
else:
data, label = self.load_every(self.batches[batch_idx])
data = data[sample_idx]
label = label[sample_idx] if label is not None else None
if self.transform_data:
# 将数据标签转换为Tensor
data = self.transform_data(data)
if self.transform_label and label is not None:
label = self.transform_label(label)
# return回哪些内容,那么我们在训练时循环读取每个batch时,就能获得哪些内容
return data, label if label is not None else np.array([])
# 初始化一些需要传入的参数及数据集的调用
def __len__(self):
# 返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return len(self.batches) * self.file_size三、遇到的部分问题及解决
3.1 数据读取
问题描述:在文件读取的时候,提示需要读取的文件不存在,但是txt文件中的路径没有错误。
解决方式:在文件结尾处多加了一个“y”得以解决。
思考:考虑在代码中对文件读取的部分出现了错误(待处理)。

3.2 Dataloader中设置num_workers-MemoryError
问题描述:Dataloader中出现MemoryError错误。
解决方式:将num_worker设置为0。
思考:num_workers参数:用于指定执行数据加载的子进程个数,当该值为0时仅使用主进程进行数据集加载工作,而当该值大于0时,则会创建对应数量的子进程负责相关的数据集加载工作。
可能报错原因:有其他代码正在运行,导致内存不足,无法正常完成训练,可以在运行程序的时候查看CPU的内存利用率(下次尝试一下单独运行代码)。

3.3 RuntimeError: CUDA out of memory
问题描述:运行train.py文件,出现RuntimeError: CUDA out of memory
可能原因:
- batch_size设置太大;
- 有数据持续存入GPU而未被释放;
- 有其他代码正在运行;
CUDA CPU显存管理总结:
- GPU显存占用率和存入的数据尺寸成正相关,越大的数据占用显存越多
- 只要使用了GPU,至少会占 x M的显存,且这部分显存无法被释放
- 当一块内存不再被变量所引用时,这块内存由激活内存转为失活内存,但仍然存在于这个数据队列中,当数据队列达到某个阈值时,CUDA会触发垃圾回收机制,清理失活内存
- 运行torch.cuda.empty_cache()可以手动清理失活内存
可尝试的解决方法:
方法一:调整batch_size的大小:一般设置为4能够解决问题,若还是报错,则尝试其他方法;
方法二:在报错的部分插入代码,手动清理失活内存:
import torch,gc
gc.collect()
torch.cuda.empty_cache()方法三: 在测试与训练阶段前插入代码with torch.no_grad(),如下所示:
def train(model, criterion, dataloader, device, writer):
model.eval()
# 梯度清零
with torch.no_grad():
for data, label in metric_logger.log_every(dataloader, 20, header):
......(1)关于Python中的with:
- with 语句适用于对资源进行访问的场合,确保使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,如文件使用后自动关闭/线程中锁的自动获取和释放等。
(2)torch.no_grad():
- 在pytorch中,tensor有一个requires_grad参数,若设置为True,则反向传播时,该tensor就会自动求导。requires_grad的属性默认为False,若一个节点(叶子变量:自己创建的tensor)requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True(即使其他相依赖的tensor的requires_grad = False)。
- 当设置为False时,反向传播时不会自动求导,极大程度上节约了显存或者说内存。
(3)with torch.no_grad():
- 在该模块下,所有计算得出的tensor的requires_grad都自动设置为False。

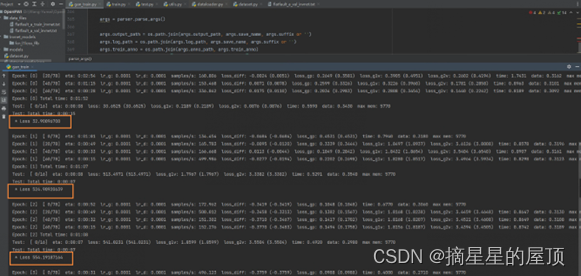
3.4 loss值的变化
四、相关参考
(1)Windows环境下Pytorch由Datalodaer设置num_workers大于1导致的异常错误及解决方式&重复运行:Windows环境下Pytorch由Datalodaer设置num_workers大于1导致的异常错误及解决方式&重复运行_numworkers设置高了会报错_叶怀生的博客-CSDN博客
(2)探究CUDA out of memory背后原因,如何释放GPU显存:【已解决】探究CUDA out of memory背后原因,如何释放GPU显存?_cuda清理指定gpu内存-CSDN博客
(3)with torch.no_grad()用法详解:【pytorch系列】 with torch.no_grad():用法详解-CSDN博客
(4)Python中 with open(file_abs,'r') as f: 的用法以及意义:Python中 with open(file_abs,'r') as f: 的用法以及意义-CSDN博客
(5)split()函数的用法:split()函数的用法_split()函数用法-CSDN博客
五、总结
5.1 存在的疑惑
- 如何检查有数据持续存入GPU未被释放?
- loss值的变化?
- 数据加载“y”问题的解决?
5.2 下周计划
下周继续完成OpenFWI代码的抄写,在抄写过程中带着疑问去理解与学习,希望有不一样的收获。



![[黑马程序员SpringBoot2]——原理篇1](https://img-blog.csdnimg.cn/09fa9c56c3004373be0d7bf359624031.png)