课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间
目录
一、建立数据通路
(一)组合逻辑电路
1、指令周期
2、数据通路
3、CPU所需硬件电路
(二)时序逻辑电路
1、时序逻辑电路可以解决的问题
二、面向流水线的指令设计
(一)现代处理器的流水线设计
编辑
(二)“主频战争”带来的超长流水线
1、超长流水线面临的问题
三、冒险和预测
(一)Hazard
1、结构冒险
2、数据冒险
3、通过流水线停顿解决数据冒险
(二)操作数前推
(三)乱序执行
(四)控制冒险
1、缩短分支延迟
2、分支预测
3、动态分支预测
一、建立数据通路
(一)组合逻辑电路
1、指令周期
- Fetch(取得指令):从 PC 寄存器里找到对应的指令地址,根据指令地址从内存里把具体的指令,加载到指令寄存器中,然后把 PC 寄存器自增,好在未来执行下一条指令。
- Decode(指令译码):根据指令寄存器里面的指令,解析成要进行什么样的操作,是 R、I、J 中的哪一种指令,具体要操作哪些寄存器、数据或者内存地址。
- Execute(执行指令):实际运行对应的 R、I、J 这些特定的指令,进行算术逻辑操作、数据传输或者直接的地址跳转。
- 重复进行 1~3 的步骤。
除了 Instruction Cycle,在 CPU 里还有另外两个常见的 Cycle。一个叫 Machine Cycle,机器周期或者 CPU 周期。CPU 内部的操作速度很快,但是访问内存的速度却要慢很多。每一条指令都需要从内存里面加载而来,所以我们一般把从内存里面读取一条指令的最短时间,叫作 CPU 周期。还有一个是Clock Cycle,也就是时钟周期以及机器的主频。一个 CPU 周期,通常会由几个时钟周期累积起来。一个 CPU 周期的时间,就是这几个 Clock Cycle 的总和。
2、数据通路
数据通路就是处理器单元,通常由两类原件组成:
第一类叫操作元件,也叫组合逻辑元件(Combinational Element),就是 ALU。ALU的功能就是在特定的输入下,根据下面的组合电路的逻辑,生成特定的输出。
第二类叫存储元件,也有叫状态元件(State Element)的。比如我们在计算过程中需要用到的寄存器,无论是通用寄存器还是状态寄存器,其实都是存储元件。
通过数据总线的方式,把它们连接起来,就可以完成数据的存储、处理和传输了,这就是所谓的建立数据通路。
控制器会重复“Fetch - Decode - Execute“循环中的前两个步骤,然后把最后一个步骤,通过控制器产生的控制信号,交给 ALU 去处理。
3、CPU所需硬件电路
- 首先需要ALU,它是一个没有状态的,根据输入计算输出结果的第一个电路。
- 第二,需要有一个能够进行状态读写的电路元件,也就是寄存器,能够存储到上一次的计算结果。
- 第三,需要有一个“自动”的电路,按照固定的周期,不停地实现 PC 寄存器自增,自动地去执行“Fetch - Decode - Execute“的步骤。
- 第四,需要有一个“译码”的电路。无论是对指令进行 decode,还是根据内存地址获取对应的数据或者指令,都需要通过一个电路去寻找数据。
CPU在空闲状态就会停止执行,具体来说就是切断时钟信号,CPU的主频就会瞬间降低为0,功耗也会瞬间降低为0。由于这个空闲状态是十分短暂的,所以你在任务管理器里面也只会看到CPU频率下降,不会看到降低为0。当CPU从空闲状态中恢复时,就会接通时钟信号,这样CPU频率就会上升。所以你会在任务管理器里面看到CPU的频率起伏变化。
(二)时序逻辑电路
1、时序逻辑电路可以解决的问题
- 自动运行问题。时序电路接通之后可以不停地开启和关闭开关,进入一个自动运行的状态,使得我们上一讲说的,控制器不停地让 PC 寄存器自增读取下一条指令成为可能。
- 存储问题。通过时序电路实现的触发器,能把计算结果存储在特定的电路里面,而不是像组合逻辑电路那样,一旦输入有任何改变,对应的输出也会改变。
- 各个功能按照时序协调。无论是程序实现的软件指令,还是到硬件层面,各种指令的操作都有先后的顺序要求。时序电路使得不同的事件按照时间顺序发生。
二、面向流水线的指令设计
(一)现代处理器的流水线设计
CPU 的指令执行过程,是由各个电路模块组成的。取指令的时候,需要一个译码器把数据从内存里面取出来,写入到寄存器中;指令译码的时候,需要另外一个译码器,把指令解析成对应的控制信号、内存地址和数据;到了指令执行的时候,需要的则是一个完成计算工作的 ALU。

这样一来,就不用把时钟周期设置成整条指令执行的时间,而是拆分成完成一个一个小步骤需要的时间。同时,每一个阶段的电路在完成对应的任务之后,也不需要等待整个指令执行完成,而是可以直接执行下一条指令的对应阶段。 这样的协作模式,就是指令流水线。这里面每一个独立的步骤,就称为流水线阶段或者流水线级(Pipeline Stage)。
如果某一个操作步骤的时间太长,就可以考虑把这个步骤,拆分成更多的步骤,让所有步骤需要执行的时间尽量都差不多长。这样,也就可以解决我们在单指令周期处理器中遇到的,性能瓶颈来自于最复杂的指令的问题。
流水线可以增加吞吐率,但是增加流水线深度,是有性能成本的。每一级流水线对应的输出,都要放到流水线寄存器(Pipeline Register)里面,然后在下一个时钟周期,交给下一个流水线级去处理。每增加一级的流水线,就要多一级写入到流水线寄存器的操作。所以,设计合理的流水线级数也是现代 CPU 中非常重要的一点。
可以看到,为了能够不浪费 CPU 的性能,把指令的执行过程,切分成一个一个流水线级,来提升 CPU 的吞吐率。而 CPU 的设计,是由一个个独立的组合逻辑电路串接起来形成的,天然能够适合这样采用流水线“专业分工”的工作方式。因为每一级的 overhead,一味地增加流水线深度,并不能无限地提高性能。同样地,因为指令的执行不再是顺序地一条条执行,而是在上一条执行到一半的时候,下一条就已经启动了,所以也给我们的程序带来了很多挑战。
(二)“主频战争”带来的超长流水线
乍看起来,流水线技术是一个提升性能的灵丹妙药。它通过把一条指令的操作切分成更细的多个步骤,可以避免 CPU“浪费”。每一个细分的流水线步骤都很简单,所以单个时钟周期的时间就可以设得更短。这也变相地让 CPU 的主频提升得很快。
但并不能简单地通过 CPU 的主频,来衡量 CPU 乃至计算机整机的性能。因为不同的 CPU 实际的体系架构和实现都不一样。同样的 CPU 主频,实际的性能可能差别很大。
增加流水线深度,在同主频下,其实是降低了 CPU 的性能。因为一个 Pipeline Stage,就需要一个时钟周期。那么我们把任务拆分成 31 个阶段,就需要 31 个时钟周期才能完成一个任务;而把任务拆分成 11 个阶段,就只需要 11 个时钟周期就能完成任务。事实上,因为每个 Stage 都需要有对应的 Pipeline 寄存器的开销,这个时候,更深的流水线性能可能还会更差一些。
1、超长流水线面临的问题
(1)功耗问题。提升流水线深度,必须要和提升 CPU 主频同时进行。因为在单个 Pipeline Stage 能够执行的功能变简单了,也就意味着单个时钟周期内能够完成的事情变少了。所以,只有提升时钟周期,CPU 在指令的响应时间这个指标上才能保持和原来相同的性能。同时,由于流水线深度的增加,需要的电路数量就变多了,也就是使用的晶体管变多了。主频的提升和晶体管数量的增加都使得 CPU 的功耗变大了。
(2)流水线技术带来的性能提升,是一个理想情况。在实际的程序执行中,并不一定能够做得到,因为有时候指令之间是存在依赖关系的,而流水线里同时执行的指令不能具备依赖关系。
三、冒险和预测
(一)Hazard
流水线设计需要解决的三大冒险,分别是结构冒险(Structural Hazard)、数据冒险(Data Hazard)以及控制冒险(Control Hazard)。
1、结构冒险
结构冒险,本质上是一个硬件层面的资源竞争问题,也就是一个硬件电路层面的问题(可以靠增加硬件资源的方式来解决)。
对于访问内存数据和取指令的冲突,一个直观的解决方案就是把我们的内存分成两部分,让它们各有各的地址译码器。这两部分分别是存放指令的程序内存和存放数据的数据内存。这种解决方案在计算机体系结构里叫作哈佛架构(Harvard Architecture),来自哈佛大学设计Mark I 型计算机时候的设计。
目前使用的CPU,采用的是冯·诺依曼体系结构,也叫普林斯顿架构。并没有把内存拆成程序内存和数据内存这两部分。因为如果那样拆的话,就没有办法根据实际的应用去动态分配程序指令和数据需要的内存空间。虽然解决了资源冲突的问题,但是也失去了灵活性。
不过,借鉴了哈佛结构的思路,现代的 CPU 虽然没有在内存层面进行对应的拆分,却在 CPU 内部的高速缓存部分进行了区分,把高速缓存分成了指令缓存(Instruction Cache)和数据缓存(Data Cache)两部分。
内存的访问速度远比 CPU 的速度要慢,所以现代的 CPU 并不会直接读取主内存。它会从主内存把指令和数据加载到高速缓存中,这样后续的访问都是访问高速缓存。而指令缓存和数据缓存的拆分,使得我们的 CPU 在进行数据访问和取指令的时候,不会再发生资源冲突的问题了。
2、数据冒险
数据冒险,就是同时在执行的多个指令之间,有数据依赖的情况。这些数据依赖,可以分成三大类,分别是先写后读(Read After Write,RAW)、先读后写(Write After Read,WAR)和写后再写(Write After Write,WAW)。
其中,先写后读叫数据依赖,先读后写叫反依赖,写后再写叫输出依赖。
3、通过流水线停顿解决数据冒险
流水线架构的核心,就是在前一个指令还没有结束的时候,开始执行后面的指令。
解决这些数据冒险的一个最简单也是最笨的方法叫流水线停顿(Pipeline Stall),或者叫流水线冒泡(Pipeline Bubbling):指令译码的时候,会拿到对应指令所需要访问的寄存器和内存地址,如果发现后面执行的指令,对前面执行的指令有数据层面的依赖关系,就“再等等”,让整个流水线停顿一个或者多个周期。
并不是让流水线停下来,而是在执行后面的操作步骤前面,插入一个 NOP 操作,也就是执行一个其实什么都不干的操作。这个插入的指令,就好像一个水管(Pipeline)里面,进了一个空的气泡,又被叫作流水线冒泡。

(二)操作数前推
操作数前推的逻辑含义是转发——前面指令的执行结果,直接“转发”给了依赖其结果的后面指令的 ALU 作为输入;硬件含义是旁路(Bypassing)——为了能够实现转发”,需要在 CPU 的硬件里单独拉一根信号传输的线路出来,使得 ALU 的计算结果能够重新回到 ALU 的输入里来。这样的一条线路,就是“旁路”。它越过(Bypass)了写入寄存器,再从寄存器读出的过程。
操作数前推的解决方案不但可以单独使用,还可以和流水线冒泡一起使用。有些时候,的操作数前推并不能减少所有“冒泡”,只能去掉其中的一部分。仍然需要通过插入一些“气泡”来解决冒险问题。
(三)乱序执行
无论是流水线停顿,还是操作数前推,归根到底,只要前面指令的特定阶段还没有执行完成,后面的指令就会被“阻塞”住。但是这个“阻塞”很多时候是没有必要的。因为尽管代码生成的指令是顺序的,但是如果后面的指令不需要依赖前面指令的执行结果,完全可以不必等待前面的指令运算完成。这样的解决方案,在计算机组成里面,被称为乱序执行(Out-of-Order Execution,OoOE)。
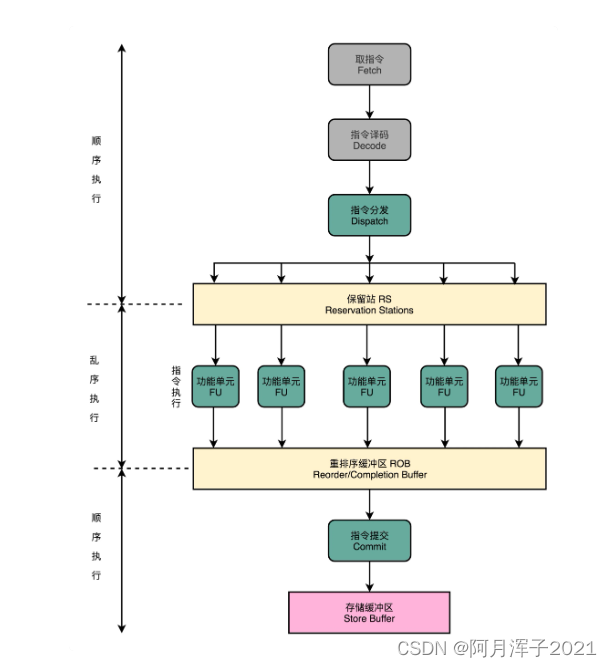
- 在取指令和指令译码的时候,乱序执行的 CPU 和其他使用流水线架构的 CPU 是一样的。它会一级一级顺序地进行取指令和指令译码的工作。
- 在指令译码完成之后,CPU 不会直接进行指令执行,而是进行一次指令分发,把指令发到一个叫作保留站(Reservation Stations)的地方。
- 这些指令不会立刻执行,而要等待它们所依赖的数据,传递给它们之后才会执行。一旦指令依赖的数据来齐了,指令就可以交到后面的功能单元(Function Unit,FU),其实就是 ALU,去执行了。
- 指令执行的阶段完成之后,并不是立刻把结果写回到寄存器里面去,而是把结果再存放到一个叫作重排序缓冲区(Re-Order Buffer,ROB)的地方。
- 在重排序缓冲区里,CPU 会按照取指令的顺序,对指令的计算结果重新排序。只有排在前面的指令都已经完成了,才会提交指令,完成整个指令的运算结果。
- 实际的指令的计算结果数据,并不是直接写到内存或者高速缓存里,而是先写入存储缓冲区(Store Buffer 面,最终才会写入到高速缓存和内存里。
可以看到,在乱序执行的情况下,只有 CPU 内部指令的执行层面,可能是“乱序”的。只要我们能在指令的译码阶段正确地分析出指令之间的数据依赖关系,这个“乱序”就只会在互相没有影响的指令之间发生。
即便指令的执行过程中是乱序的,我们在最终指令的计算结果写入到寄存器和内存之前,依然会进行一次排序,以确保所有指令在外部看来仍然是有序完成的。
乱序执行,极大地提高了 CPU 的运行效率。核心原因是,现代 CPU 的运行速度比访问主内存的速度要快很多。如果完全采用顺序执行的方式,很多时间都会浪费在前面指令等待获取内存数据的时间里。CPU 不得不加入 NOP 操作进行空转。而现代 CPU 的流水线级数也已经相对比较深了,到达了 14 级。这也意味着,同一个时钟周期内并行执行的指令数是很多的。
(四)控制冒险
在结构冒险和数据冒险中,所有的流水线停顿操作都要从指令执行阶段开始。流水线的前两个阶段,也就是取指令(IF)和指令译码(ID)的阶段,是不需要停顿的。CPU 会在流水线里面直接去取下一条指令,然后进行译码。取指令和指令译码不会需要遇到任何停顿,这是基于所有的指令代码都是顺序加载执行的假设。在执行的代码中,一旦遇到 if…else 这样的条件分支,或者 for/while 循环,就会不成立。
在 jmp 指令发生的时候,CPU 可能会跳转去执行其他指令。jmp 后的那一条指令是否应该顺序加载执行,在流水线里面进行取指令的时候,我们没法知道。要等 jmp 指令执行完成,去更新了 PC 寄存器之后,才能知道,是执行下一条指令,还是跳转到另外一个内存地址,去取别的指令。这种为了确保能取到正确的指令,而不得不进行等待延迟的情况,就是控制冒险(Control Harzard)
1、缩短分支延迟
解决控制冒险的第一个办法。
条件跳转指令其实进行了两种电路操作:第一种事进行条件比较,第二种是进行实际的跳转。
可以将条件判断、地址跳转,都提前到指令译码阶段进行,而不需要放在指令执行阶段。需要在 CPU 里面设计对应的旁路,在指令译码阶段,就提供对应的判断比较的电路。
这种方式,本质上和前面数据冒险的操作数前推的解决方案类似,就是在硬件电路层面,把一些计算结果更早地反馈到流水线中。这样反馈变得更快了,后面的指令需要等待的时间就变短了。
但只是改造硬件,并不能彻底解决问题。跳转指令的比较结果,仍然要在指令执行的时候才能知道。在流水线里,第一条指令进行指令译码的时钟周期里,其实就要去取下一条指令了。这个时候,还没有开始指令执行阶段,自然也就不知道比较的结果。
2、分支预测
让CPU 来猜测,条件跳转后执行的指令,应该是哪一条。
最简单的分支预测技术,叫作“假装分支不发生”。顾名思义,就是仍然按照顺序,把指令往下执行。这样的预测方法,是一种静态预测技术。
分支预测正确意味着将节省下来本需要停顿等待的时间。如果分支预测失败就把后面已经取出执行的部分丢弃掉。这个丢弃的操作,在流水线里面,叫作 Zap 或者 Flush。所以,CPU 需要提供对应的丢弃指令的功能,通过控制信号清除掉已经在流水线中执行的指令。只要对应的清除开销不要太大,就是划得来的。
3、动态分支预测
用一个比特,记录当前分支的比较情况,用当前分支的比较情况,来预测下一次分支时候的比较情况。这种策略叫一级分支预测(One Level Branch Prediction),或者叫 1 比特饱和计数(1-bit saturating counter)
还可以引入一个状态机(State Machine)存储更多的信息用来进行预测(如果连续下雨,我们就认为更有可能下雨。之后如果有一天放晴了,我们仍认为会下雨),状态机里,一共有 4 个状态,需要 2 个比特来记录。这样的策略,叫作 2 比特饱和计数,或者叫双模态预测器(Bimodal Predictor)
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间