今天继续给大家介绍Python爬虫相关知识,本文主要内容是Python爬虫进行正则数据解析实战。
一、需求分析
今天,我们尝试使用re正则表达式来对爬取到的页面进行数据解析。需求如下:
针对网页:https://blog.csdn.net/weixin_40228200/article/details/128438620,爬取正文中的所有图片。
简单分析该网站正文图片格式,可以看出图片格式如下所示:
<img src="https://img-blog.csdnimg.cn/4f69582a75a9406fa658b4321513528a.png" alt="在这里插入图片描述">
因此,我们就可以据此获取包含图片URL的正则表达式,然后提取图片下载了。
二、编码实战
针对上述需求,我们编码如下所示:
import re
import requests
import os
import time
url='https://blog.csdn.net/weixin_40228200/article/details/128438620'
UA={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"}
page_text=requests.get(url=url,headers=UA).text
ex=r'<img src="https://img-blog.csdnimg.cn/(.*?).png" alt="在这里'
img_list=re.findall(ex,page_text,re.S)
if not os.path.exists("./csdnIMG"):
os.mkdir("./csdnIMG")
for img in img_list:
img_url="https://img-blog.csdnimg.cn/"+img+".png"
img_data=requests.get(url=img_url,headers=UA).content
img_name="./csdnIMG/"+img+".png"
with open(img_name,'wb') as fp:
fp.write(img_data)
time.sleep(1)
在上述代码中,我们的正则表达式写法为:
ex=r'<img src="https://img-blog.csdnimg.cn/(.*?).png" alt="在这里'
这里的()标识匹配提取的内容,.*?标识非贪婪匹配内容。同时,在代码中为了防止访问过快,我们使用了time.sleep()函数拉大了时间间隔。
三、效果检验
上述代码执行结果如下所示:
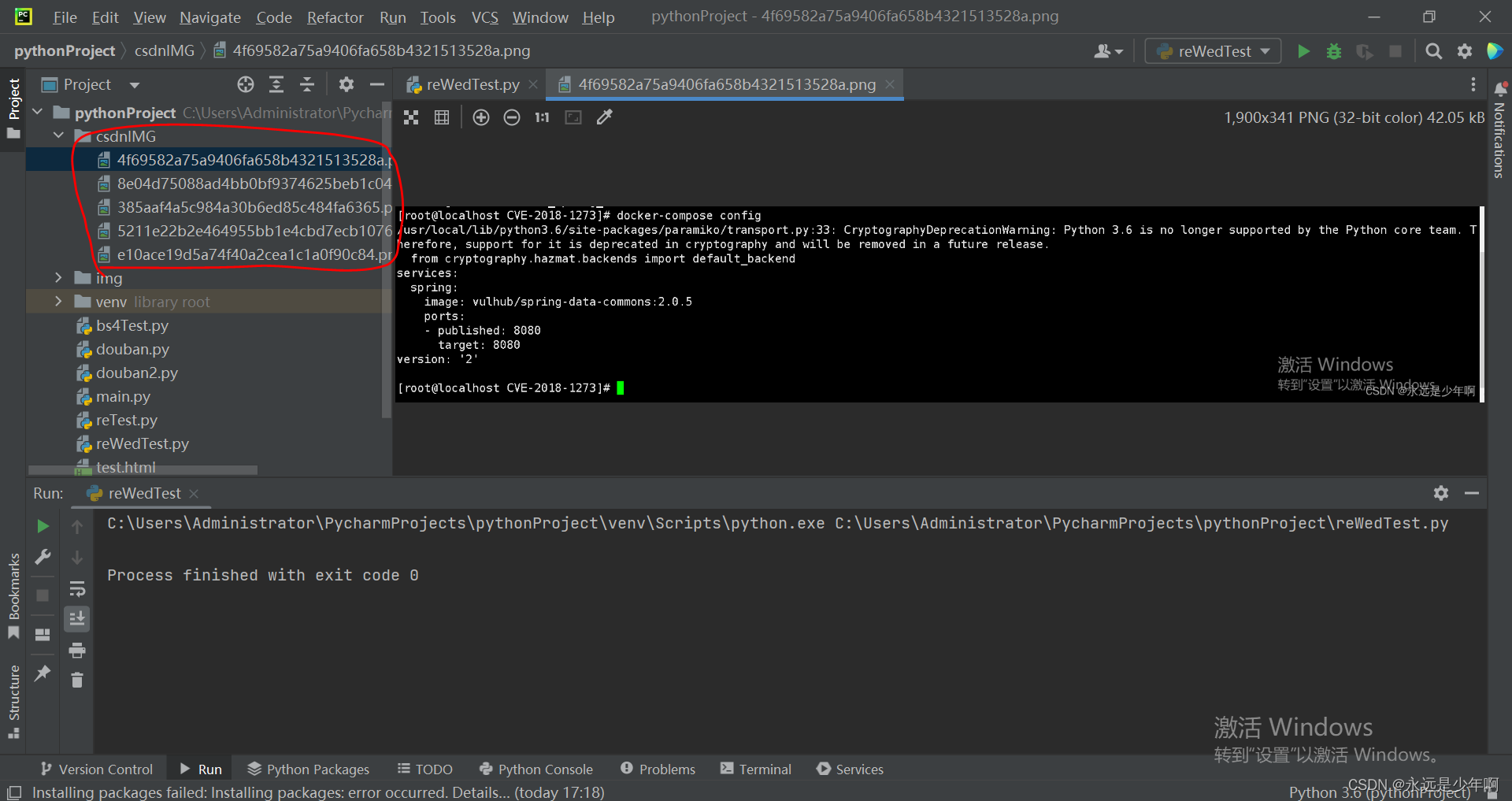
从上图中可以看出,我们成功的爬取到了指定网页的图片数据!
原创不易,转载请说明出处:https://blog.csdn.net/weixin_40228200