窗口函数的官方描述:窗口函数对一组查询行执行类似聚合的操作。但是,虽然聚合操作将查询行分组为单个结果行,但窗口函数会为每个查询行生成一个结果,发生函数评估的行称为当前行,与发生函数评估的当前行相关的查询行构成当前行的窗口。
诞生原因
-
之前 MySQL 5.6 的时候,支持将非 Group By 之后的数据呈现出来,到了 MySQL5.7 以后,除了参与 Group By 的列其他列都不能被展现出来了,这样带来一些不便;
-
此外,我们也希望在分组完成之后,对同一组内的数据进行一些加工之后重新生成一列新的数据,这一列往往是排序、总额(price * amount)等聚合信息,也可能是纵向的平均值,累加值,总和等等,总之这种函数式的处理需求最终会存放在新的列中;
-
当然,如果你不指定分组,那窗口函数就把所有结果作为一个组对待处理;
相关链接
MySQL窗口函数(一) - 掘金
通俗易懂的学会:SQL窗口函数 - 知乎
语法结构

-
在 * 后追加一个函数,即增加了一行新列 ranking,这行新列的数据是通过函数 rank() 获得的,该函数需要 order by 配合,不然不知道按哪个列排序,同时如果追加 partition by (按班级分组),则会在组内进行排序
-
这样的列可以增加不止一个,相互之间并不影响


-
整理完成之后相当于一个新表,该新表仍然遵守着 mysql 的其他查询语言的使用,比如继续分组和排序

-
还可以作为子表进行再次聚合查询
这里有个新知识,以前查询子表是不用给子表起名字的,现在 mysql 8 必须加个别名

-
聚合函数作为窗口函数使用的效果

-
结论一,带 order by 结果表现:
聚合函数当窗口函数使用的结果是支持相同分组下当前行以及当前行以上的聚合结果(所以必须要有排序),如下图很明显
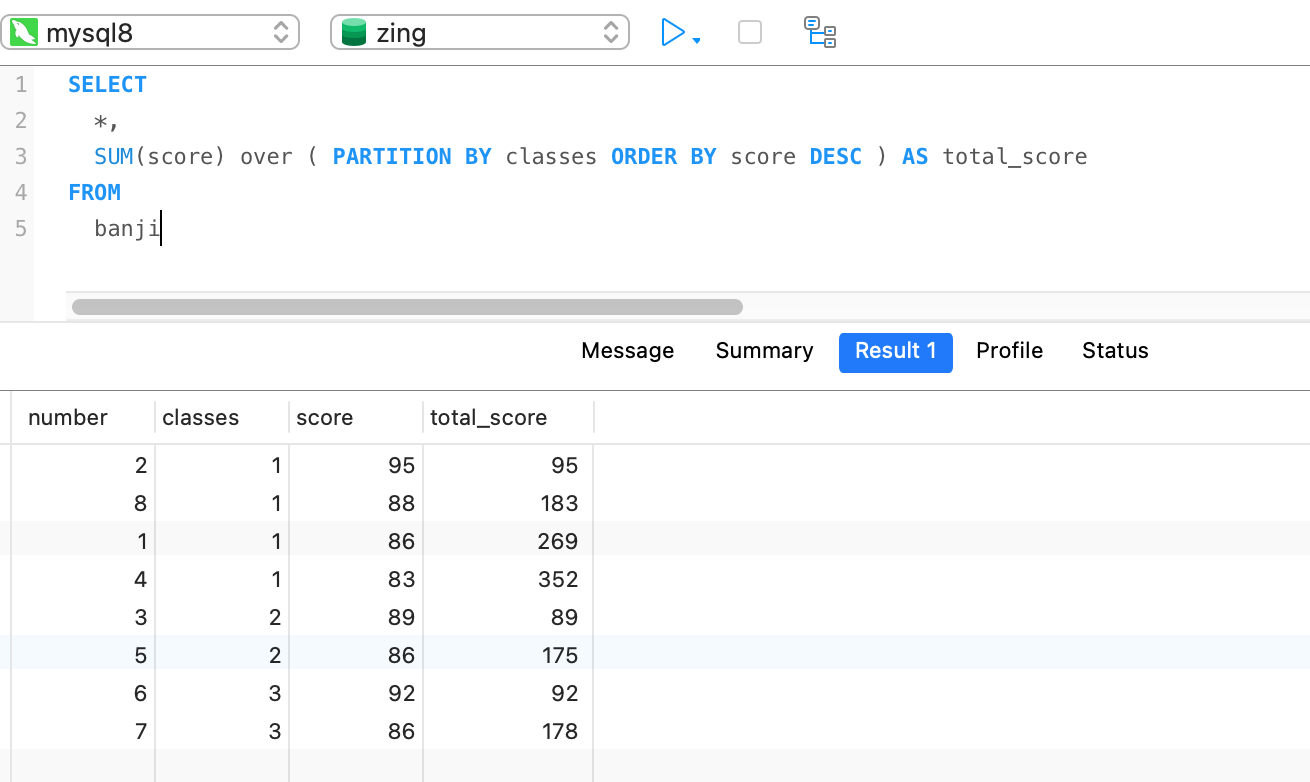
-
不带 order by 结果表现:
不带 order by 就是对相同组内的直接聚合,不会按顺序进行处理,原知乎作者没有指出这一点

阿里云窗口函数
窗口函数的语法及示例_日志服务-阿里云帮助中心
阿里云日志文档中对窗口函数的讲解非常细致,每个都有案例
这里提一个 first_value(count),这是留存计算中用到的,代表着提取第一行中的 count 的值,以下是 15 日留存的 sql 语句这样就能更清楚地分析了,这里的 first_value(count) 提取就是当天安装的那批用户,他们就是第一批用户,每过 1 天
15日留存率脚本
event_source: 5
AND install_time > 0
AND NOT user_id: ""
AND NOT user_id: "null" |
WITH every_day_user AS (
SELECT
DISTINCT user_id,
date_format(install_time / 1000, '%Y-%m-%d') AS install_day,
date_format(event_time, '%Y-%m-%d') AS event_day
FROM log
LIMIT
100000
), live_day_user AS (
SELECT
date_format(install_day, '%Y-%m-%d') AS install_date,
-- 安装时间
date_diff ('day', install_day, event_day) AS live_day,
-- 留存日期
count(*) AS count -- 数量
FROM every_day_user
WHERE
install_day > date_add('day', -15, CURRENT_DATE)
AND install_day <= event_day -- 安装时间在15日内的 且安装时间小于事件时间
GROUP BY
install_date,
live_day
ORDER BY
install_date DESC,
live_day ASC
LIMIT
100000
)
SELECT
install_date,
live_day,
count,
round(
count * 100.0 / (
first_value(count) over (
PARTITION BY install_date
ORDER BY
live_day
)
),
2
) AS ratio
FROM live_day_user
WHERE
(
to_unixtime (CURRENT_DATE)-to_unixtime (date_parse (install_date, '%Y-%m-%d'))
) >= live_day * 24 * 60 * 60
ORDER BY
install_date DESC,
live_day ASC
LIMIT
10000015日留存率看板
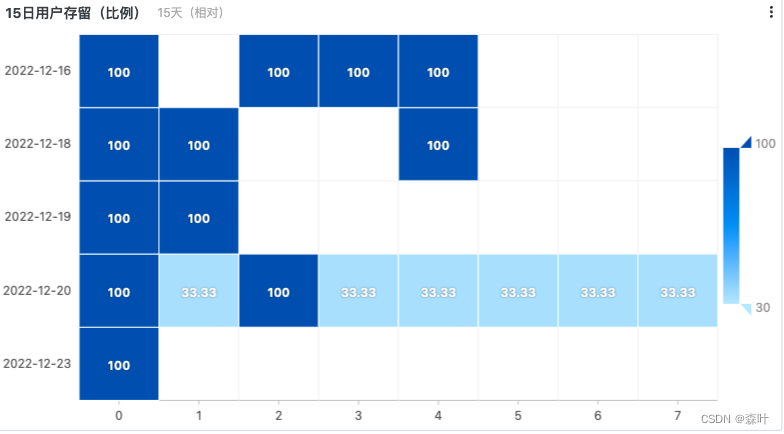
留存率脚本总结
-
阿里云日志的脚本编写方式,如何实现相当于 python 脚本的方式?
-
通过不断地创建子表的方式,然后通过一堆函数进行变换组合出新的列,这些带有新的列的数据形成新的数据表,不断地重复这个过程就能得到自己想得到的任何聚合数据;
-
数据库的思维方式和脚本语言的方式是相反的,脚本语言的是直接提取自己想要的数据出来,例如留存这个,我直接从今天安装人开始,往前推,昨天安装的用户,今天还活跃的有几人,这就牵涉两张表的对应,一张是昨天安装的,一张是今天活跃的,两者进行比对形成新数据,依次上推 15 天,这样比对的逻辑非常庞大,但反过来进行思考,先统计 15 天来所有的数据,按安装天数,事件发生天数,用户 ID 三者进行去重统计,再按安装日期和事件发生日期差值进行 group by 分组,count 所有用户数,这样就得到了安装日期,差 1 天,2 天,3 天用户总数,这就是留存
-
这样有可能缺少某一天的数据,有可能缺少差某天的数据,造成图表对应不上引起异常,但正常数据情况下不会缺失













![洛谷千题详解 | P1029 [NOIP2001 普及组] 最大公约数和最小公倍数问题【C++语言】](https://img-blog.csdnimg.cn/2e1e7732091a4ca2bedf44ddd08f252e.png)