知识库文档处理
- 1 知识库设计
- 2 文档加载
- 2.1 PDF文档
- 2.2 MD文档
- 2.3 MP4视频
- 3 文档分割
- 4 文档词向量化
本项目是一个个人知识库助手项目,旨在帮助用户根据个人知识库内容,回答用户问题。个人知识库应当能够支持各种类型的数据,支持用户便捷地导入导出、进行管理。在我们的项目中,我们以 Datawhale 的一些经典开源课程作为示例,设计了多种文件类型,介绍每一种文件类型的处理方式,从而支持用户无难度地构建自己的知识库。
1 知识库设计
我们的知识库选用 Datawhale 一些经典开源课程、视频(部分)作为示例,具体包括:
pdf: 《机器学习公式详解》PDF版本:https://github.com/datawhalechina/pumpkin-book/releases
md:《面向开发者的 LLM 入门教程`第一部分 Prompt Engineering》:https://github.com/datawhalechina/prompt-engineering-for-developers
mp4: 《强化学习入门指南》:https://www.bilibili.com/video/BV1HZ4y1v7eX/?spm_id_from=333.999.0.0&vd_source=4922e78f7a24c5981f1ddb6a8ee55ab9
我们会将知识库源数据放置在 …/…/data_base/knowledge_db 目录下。
2 文档加载
2.1 PDF文档
我们使用 PyMuPDFLoader 来读取知识库的 PDF 文件。PyMuPDFLoader 是 PDF 解析器中速度最快的一种,结果会包含 PDF 及其页面的详细元数据,并且每页返回一个文档。
## 安装必要的库
pip install rapidocr_onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "unstructured[all-docs]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyMuPDF -i https://pypi.tuna.tsinghua.edu.cn/simple
from langchain.document_loaders import PyMuPDFLoader
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径
loader = PyMuPDFLoader("../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf")
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载
pages = loader.load()
探索加载的数据:
文档加载后储存在 pages 变量中:
- page 的变量类型为 List
- 打印 pages 的长度可以看到 pdf 一共包含多少页
print(f"载入后的变量类型为:{type(pages)},", f"该 PDF 一共包含 {len(pages)} 页")
载入后的变量类型为:<class 'list'>, 该 PDF 一共包含 196 页
page 中的每一元素为一个文档,变量类型为 langchain.schema.document.Document, 文档变量类型包含两个属性:
- page_content 包含该文档的内容。
- meta_data 为文档相关的描述性数据。
page = pages[1]
print(f"每一个元素的类型:{type(page)}.",
f"该文档的描述性数据:{page.metadata}",
f"查看该文档的内容:\n{page.page_content[0:1000]}",
sep="\n------\n")
每一个元素的类型:<class 'langchain.schema.document.Document'>.
------
该文档的描述性数据:{'source': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'file_path': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'page': 1, 'total_pages': 196, 'format': 'PDF 1.5', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'creator': 'LaTeX with hyperref', 'producer': 'xdvipdfmx (20200315)', 'creationDate': "D:20230303170709-00'00'", 'modDate': '', 'trapped': ''}
------
查看该文档的内容:
前言
“周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读
者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推
导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充
具体的推导细节。”
读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我们最初的遐想,后来我们了解到,周
老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数学基础扎实点的大二下学生应该对西瓜书
中的推导细节无困难吧,要点在书里都有了,略去的细节应能脑补或做练习”。所以...... 本南瓜书只能算是我
等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二
下学生”。
使用说明
• 南瓜书的所有内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书
为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书;
• 对于初学机器学习的小白,西瓜书第 1 章和第 2 章的公式强烈不建议深究,简单过一下即可,等你学得
有点飘的时候再回来啃都来得及;
• 每个公式的解析和推导我们都力 (zhi) 争 (neng) 以本科数学基础的视角进行讲解,所以超纲的数学知识
我们通常都会以附录和参考文献的形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入学习;
• 若南瓜书里没有你想要查阅的公式,或者你发现南瓜书哪个地方有错误,请毫不犹豫地去我们 GitHub 的
Issues(地址:https://github.com/datawhalechina/pumpkin-book/issues)进行反馈,在对应版块
提交你希望补充的公式编号或者勘误信息,我们通常会在 24 小时以内给您回复,超过 24 小时未回复的
话可以微信联系我们(微信号:at-Sm1les);
配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU
在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第 1 版)
最新版 PDF 获取地址:https://github.com/datawhalechina/pumpkin-book/re
我们运行上面代码,将结果输出如下:
2.2 MD文档
我们可以以几乎完全一致的方式读入 markdown 文档:
from langchain.document_loaders import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("../../data_base/knowledge_db/prompt_engineering/1. 简介 Introduction.md")
pages = loader.load()
读取的对象和 PDF 文档读取出来是完全一致的:
print(f"载入后的变量类型为:{type(pages)},", f"该 Markdown 一共包含 {len(pages)} 页")
载入后的变量类型为:<class 'list'>, 该 Markdown 一共包含 1 页
page = pages[0]
print(f"每一个元素的类型:{type(page)}.",
f"该文档的描述性数据:{page.metadata}",
f"查看该文档的内容:\n{page.page_content[0:]}",
sep="\n------\n")
2.3 MP4视频
LangChain 提供了对 Youtube 视频进行爬取并转写的处理接口,但是如果我们想直接对我们的本地 MP4 视频进行处理,需要首先经过转录加载成文本格式,在加载到 LangChain 中。
我们使用 Whisper 实现视频的转写,Whisper 的安装方式此处不再赘述,详见教程:
知乎|开源免费离线语音识别神器whisper如何安装:https://zhuanlan.zhihu.com/p/595691785
此处我们直接使用 Whisper 在原目录下输出转写结果:
whisper ../../data_base/knowledge_db/easy_rl/强化学习入门指南.mp4 --model large --model_dir whisper-large --language zh --output_dir ../../data_base/knowledge_db/easy_rl
上述过程是 使用whisper 工具进行转写操作;
注意,此处 model_dir 参数应是你下载到本地的 large-whisper 参数路径。
转化完后,会在原目录下生成 强化学习入门指南.txt 文件,我们直接加载该 txt 文件即可:
from langchain.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader("../../data_base/knowledge_db/easy_rl/强化学习入门指南.txt")
pages = loader.load()
加载出来的数据属性同上文一致:
page = pages[0]
print(f"每一个元素的类型:{type(page)}.",
f"该文档的描述性数据:{page.metadata}",
f"查看该文档的内容:\n{page.page_content[0:1000]}",
sep="\n------\n")
3 文档分割
Langchain 中文本分割器都根据 chunk_size (块大小)和 chunk_overlap (块与块之间的重叠大小)进行分割。


- chunk_size 指每个块包含的字符或 Token (如单词、句子等)的数量
- chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小:
- RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- CharacterTextSplitter(): 按字符来分割文本。
- MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。
- TokenTextSplitter(): 按token来分割文本。
- SentenceTransformersTokenTextSplitter(): 按token来分割文本
- Language(): 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
'''
* RecursiveCharacterTextSplitter 递归字符文本分割
RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),
这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置
RecursiveCharacterTextSplitter需要关注的是4个参数:
* separators - 分隔符字符串数组
* chunk_size - 每个文档的字符数量限制
* chunk_overlap - 两份文档重叠区域的长度
* length_function - 长度计算函数
'''
#导入文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 知识库中单段文本长度
CHUNK_SIZE = 500
# 知识库中相邻文本重合长度
OVERLAP_SIZE = 50
# 此处我们使用 PDF 文件作为示例
from langchain.document_loaders import PyMuPDFLoader
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径
loader = PyMuPDFLoader("../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf")
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载
pages = loader.load()
page = pages[1]
# 使用递归字符文本分割器
from langchain.text_splitter import TokenTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=OVERLAP_SIZE
)
text_splitter.split_text(page.page_content[0:1000])
['前言\n“周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读\n者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推\n导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充\n具体的推导细节。”\n读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我们最初的遐想,后来我们了解到,周\n老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数学基础扎实点的大二下学生应该对西瓜书\n中的推导细节无困难吧,要点在书里都有了,略去的细节应能脑补或做练习”。所以...... 本南瓜书只能算是我\n等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二\n下学生”。\n使用说明\n• 南瓜书的所有内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书\n为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书;\n• 对于初学机器学习的小白,西瓜书第 1 章和第 2 章的公式强烈不建议深究,简单过一下即可,等你学得',
'有点飘的时候再回来啃都来得及;\n• 每个公式的解析和推导我们都力 (zhi) 争 (neng) 以本科数学基础的视角进行讲解,所以超纲的数学知识\n我们通常都会以附录和参考文献的形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入学习;\n• 若南瓜书里没有你想要查阅的公式,或者你发现南瓜书哪个地方有错误,请毫不犹豫地去我们 GitHub 的\nIssues(地址:https://github.com/datawhalechina/pumpkin-book/issues)进行反馈,在对应版块\n提交你希望补充的公式编号或者勘误信息,我们通常会在 24 小时以内给您回复,超过 24 小时未回复的\n话可以微信联系我们(微信号:at-Sm1les);\n配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU\n在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第 1 版)\n最新版 PDF 获取地址:https://github.com/datawhalechina/pumpkin-book/re']
split_docs = text_splitter.split_documents(pages)
print(f"切分后的文件数量:{len(split_docs)}")
切分后的文件数量:737
print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in split_docs])}")
切分后的字符数(可以用来大致评估 token 数):314712
4 文档词向量化
在机器学习和自然语言处理(NLP)中,Embeddings(嵌入)是一种将类别数据,如单词、句子或者整个文档,转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。嵌入背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近。
举个例子,我们可以使用**词嵌入(word embeddings)**来表示文本数据。在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。例如,“king” 和 “queen” 这两个单词在嵌入空间中的位置将会非常接近,因为它们的含义相似。而 “apple” 和 “orange” 也会很接近,因为它们都是水果。而 “king” 和 “apple” 这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
让我们取出我们的切分部分并对它们进行 Embedding 处理。
这里提供三种方式进行,一种是直接使用 openai 的模型去生成 embedding,另一种是使用 HuggingFace 上的模型去生成 embedding。
- openAI 的模型需要消耗 api,对于大量的token 来说成本会比较高,但是非常方便。
- HuggingFace 的模型可以本地部署,可自定义合适的模型,可玩性较高,但对本地的资源有部分要求。
- 采用其他平台的 api。对于获取 openAI key 不方便的同学可以采用这种方法。
对于只想体验一下的同学来说,可以尝试直接用生成好的 embedding,或者在本地部署小模型进行尝试。
**HuggingFace **是一个优秀的开源库,我们只需要输入模型的名字,就会自动帮我们解析对应的能力。
# 使用前配置自己的 api 到环境变量中如
import os
import openai
import zhipuai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']
openai.api_key = os.environ['OPENAI_API_KEY']
zhihuai.api_key = os.environ['ZHIPUAI_API_KEY']
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from zhipuai_embedding import ZhipuAIEmbeddings
# embedding = OpenAIEmbeddings()
# embedding = HuggingFaceEmbeddings(model_name="moka-ai/m3e-base")
embedding = ZhipuAIEmbeddings()
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
query1 = "机器学习"
query2 = "强化学习"
query3 = "大语言模型"
# 通过对应的 embedding 类生成 query 的 embedding。
emb1 = embedding.embed_query(query1)
emb2 = embedding.embed_query(query2)
emb3 = embedding.embed_query(query3)
# 将返回结果转成 numpy 的格式,便于后续计算
emb1 = np.array(emb1)
emb2 = np.array(emb2)
emb3 = np.array(emb3)
可以直接查看 embedding 的具体信息,embedding 的维度通常取决于所使用的模型。
print(f"{query1} 生成的为长度 {len(emb1)} 的 embedding , 其前 30 个值为: {emb1[:30]}")
机器学习 生成的为长度 1024 的 embedding , 其前 30 个值为: [-0.02768379 0.07836673 0.1429528 -0.1584693 0.08204 -0.15819356
-0.01282174 0.18076552 0.20916627 0.21330206 -0.1205181 -0.06666514
-0.16731478 0.31798768 0.0680017 -0.13807729 -0.03469152 0.15737721
0.02108428 -0.29145902 -0.10099868 0.20487919 -0.03603597 -0.09646764
0.12923686 -0.20558454 0.17238656 0.03429411 0.1497675 -0.25297147]
我们已经生成了对应的向量,我们如何度量文档和问题的相关性呢?
这里提供两种常用的方法:
- 计算两个向量之间的点积。
- 计算两个向量之间的余弦相似度
点积是将两个向量对应位置的元素相乘后求和得到的标量值。点积相似度越大,表示两个向量越相似。
这里直接使用 numpy 的函数进行计算
print(f"{query1} 和 {query2} 向量之间的点积为:{np.dot(emb1, emb2)}")
print(f"{query1} 和 {query3} 向量之间的点积为:{np.dot(emb1, emb3)}")
print(f"{query2} 和 {query3} 向量之间的点积为:{np.dot(emb2, emb3)}")
机器学习 和 强化学习 向量之间的点积为:17.218882120572722
机器学习 和 大语言模型 向量之间的点积为:16.522186236712727
强化学习 和 大语言模型 向量之间的点积为:11.368461841901752
点积:计算简单,快速,不需要进行额外的归一化步骤,但丢失了方向信息。
余弦相似度:可以同时比较向量的方向和数量级大小。
余弦相似度将两个向量的点积除以它们的模长的乘积。其基本的计算公式为:
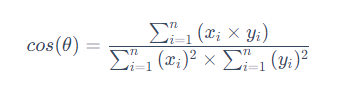
余弦函数的值域在-1到1之间,即两个向量余弦相似度的范围是[-1, 1]。当两个向量夹角为0°时,即两个向量重合时,相似度为1;当夹角为180°时,即两个向量方向相反时,相似度为-1。即越接近于 1 越相似,越接近 0 越不相似。
print(f"{query1} 和 {query2} 向量之间的余弦相似度为:{cosine_similarity(emb1.reshape(1, -1) , emb2.reshape(1, -1) )}")
print(f"{query1} 和 {query3} 向量之间的余弦相似度为:{cosine_similarity(emb1.reshape(1, -1) , emb3.reshape(1, -1) )}")
print(f"{query2} 和 {query3} 向量之间的余弦相似度为:{cosine_similarity(emb2.reshape(1, -1) , emb3.reshape(1, -1) )}")
机器学习 和 强化学习 向量之间的余弦相似度为:[[0.68814796]]
机器学习 和 大语言模型 向量之间的余弦相似度为:[[0.63382724]]
强化学习 和 大语言模型 向量之间的余弦相似度为:[[0.43555894]]
可以看出,模型认为机器学习和强化学习更相关一点,强化学习和大语言模型之间的相关性更差。(这部分跟训练语料的时间相关,embedding 的模型应该没有大语言模型相关的语料。)
目前,我们已经学习了文档的基本处理,但是如何管理我们生成的 embedding 并寻找和 query 最相关的内容呢?难道要每次遍历所有文档么?向量数据库可以帮我们快速的管理和计算这些内容。