时序预测 | Pytorch实现TCN-Transformer的时间序列预测
目录
- 时序预测 | Pytorch实现TCN-Transformer的时间序列预测
- 效果一览
- 基本介绍
- 程序设计
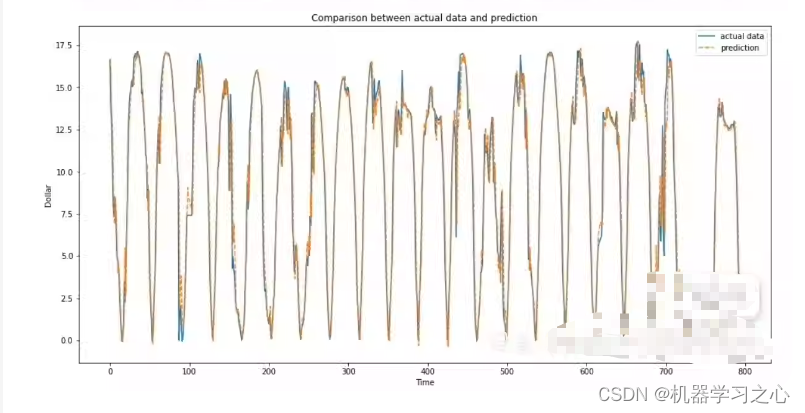
效果一览
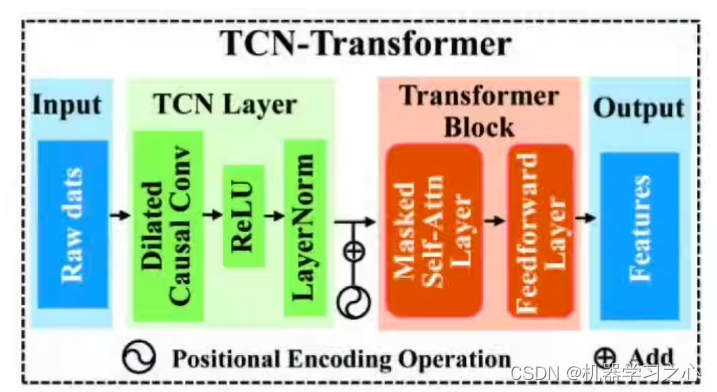
基本介绍
基于TCN-Transformer模型的时间序列预测,可以用于做光伏发电功率预测,风速预测,风力发电功率预测,负荷预测等,python程序
python代码,pytorch
程序设计
- 完整程序和数据获取方式1:资源处直接下载Pytorch实现TCN-Transformer的时间序列预测
- 完整程序和数据获取方式2:私信博主回复Pytorch实现TCN-Transformer的时间序列预测。
数据集描述
通过预览数据,可知此次实验的数据属性为date(日期)、open(开盘价)、high(最高价)、low(最低价)、close(收盘价)以及volume(成交量)
其中,我们要实现股票预测,需要着重对close(收盘价)一列进行探索性分析。
"""
from torch import nn
# 1.导入库 对数据集进行处理
import pandas as pd
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error
from torch.utils.data import DataLoader, Dataset
import torch
from model import TCN_transfomer
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei'#绘图正常显示中文
plt.rcParams['axes.unicode_minus']=False#用来正常显示负号#有中文出现的情况,
from tqdm import tqdm
epoch = 100
totall_loss = [] # 记录损失值
batch_size=32
num_inputs=5
sequence_length=32
num_channels=[64,16,4,1]
kernel_size=3
dropout=0.3
nb_unites=sequence_length
# 需要u'内容'
# 2.定义获取数据函数,数据预处理。去除ID,股票代码,
# 前一天的收盘价,交易日期等对训练集无用的数据
def getData(root, sequence_length, batch_size):
stock_data = pd.read_csv(root)
print(stock_data.info())
print(stock_data.head().to_string())
#首先删除一些对预测close无用的信息
stock_data.drop('id', axis=1, inplace=True) # 删除date
stock_data.drop(labels="ts_code", axis=1, inplace=True)
stock_data.drop(labels="trade_date", axis=1, inplace=True)
stock_data.drop(labels="pre_close", axis=1, inplace=True)
stock_data.drop(labels="change", axis=1, inplace=True)
stock_data.drop(labels="pct_chg", axis=1, inplace=True)
stock_data.drop(labels="amount", axis=1, inplace=True)
print("整理后\n", stock_data.head())
#获取收盘价的最大值与最下值
close_max = stock_data["close"].max() # 收盘价的最大值
close_min = stock_data["close"].min() # s收盘价的最小值
# 2.1对数据进行标准化min-max
scaler = MinMaxScaler()
df = scaler.fit_transform(stock_data)
print("整理后\n", df)
# 2.2构造X,Y
# 根据前n天的数据,预测未来一天的收盘价(close),
# 例如根据1月1日、1月2日、1月3日、1月4日、1月5日的数据
# (每一天的数据包含8个特征),预测1月6日的收盘价。
sequence = sequence_length
x = []
y = []
for i in range(df.shape[0] - sequence):
x.append(df[i:i + sequence, :])
y.append(df[i + sequence, 3])
x = np.array(x, dtype=np.float32)
y = np.array(y, dtype=np.float32).reshape(-1, 1)
print("x.shape=", x.shape)
x=np.transpose(x,(0,2,1))
print("转置后x.shape=", x.shape)
print("y.shape", y.shape)
# 2.3构造batch,构造训练集train与测试集test
total_len = len(y)
print("total_len=", total_len)
trainx, trainy = x[:int(0.90 * total_len), ], y[:int(0.90 * total_len), ]
testx, testy = x[int(0.90 * total_len):, ], y[int(0.90 * total_len):, ]
train_loader = DataLoader(dataset=Mydataset(trainx, trainy), shuffle=True, batch_size=batch_size)
test_loader = DataLoader(dataset=Mydataset(testx, testy), shuffle=True, batch_size=batch_size)
return [close_max, close_min, train_loader, test_loader]
[1] https://blog.csdn.net/kjm13182345320/article/details/129036772?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/128690229