文章目录
- 1、分支合并框架
- 2、案例
- 3、ForkJoinTask
- 4、工作窃取算法
- 5、ForkJoinPool
一个个任务执行在一个个线程上,倘若某一个任务耗时很久,期间其他线程都无事可做,显然没有利用好多核CPU这一计算机资源,因此,出现了"分而治之"的解决方案。
1、分支合并框架
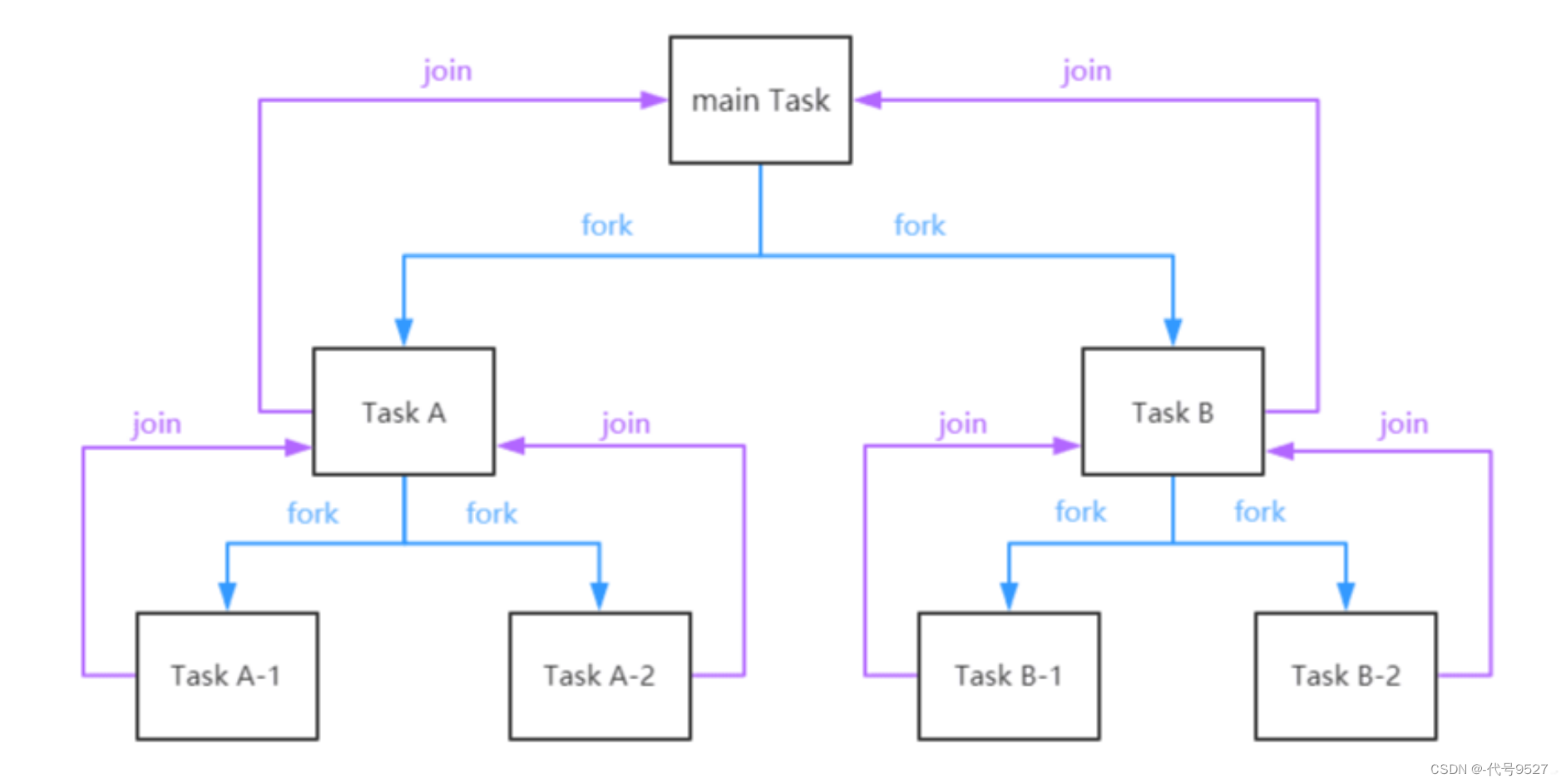
Fork/Join即分支合并,用处是把一个大任务拆分成多个子任务来并行处理,最后再合并子任务的结果。(since Java1.7)
- Fork:把一个复杂的任务进行拆分,大事化小
- Join:把拆分的子任务的结果做合并
示意图:
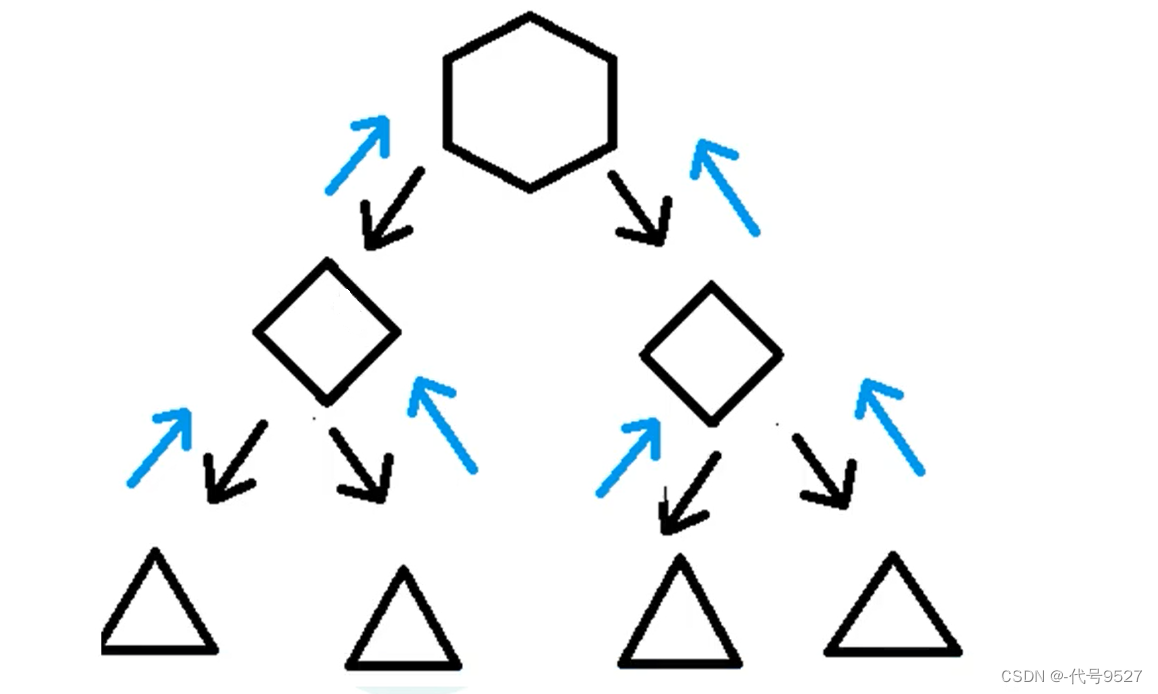
举个实际例子:
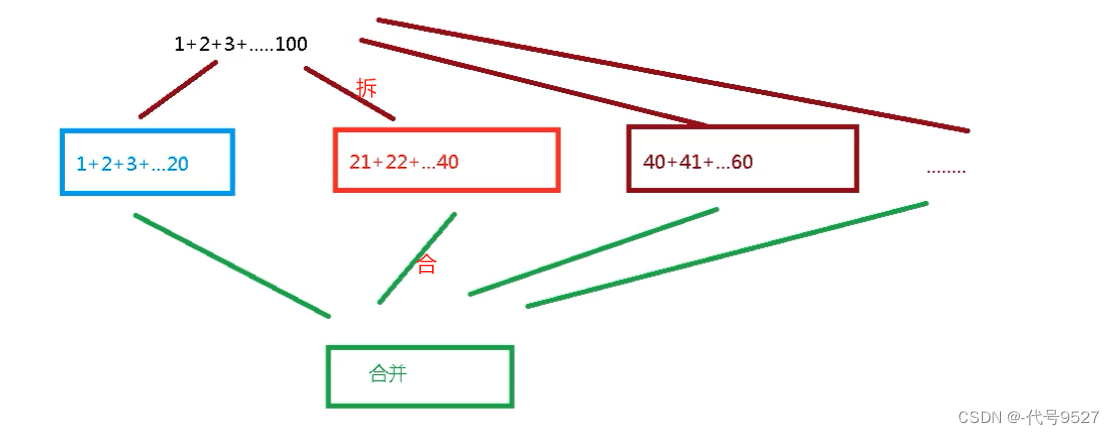
2、案例
以下采用分支合并框架来实现1+2+…+100
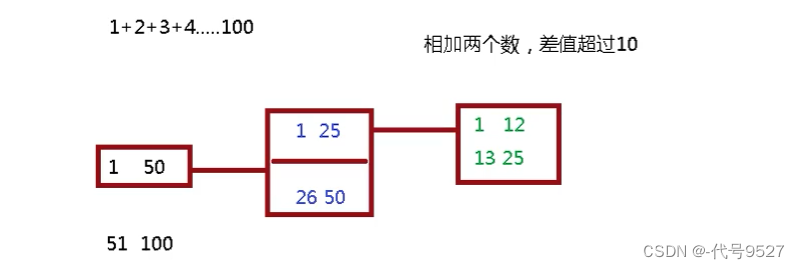
通过继承RecursiveTask类自定义任务,泛型为result的类型:
//自定义任务类继承RecursiveTask
class MyTask extends RecursiveTask<Integer> {
//拆分差值不超过10,来计算10以内的运算
private static final int VALUE = 10;
//拆分起始值
private int begin;
//拆分结束值
private int end;
//返回结果
private int result;
//构造中传入起始值
public MyTask(int begin, int end) {
this.begin = begin;
this.end = end;
}
//拆分与合并
@Override
protected Integer compute() {
//判断即将要相加的两个数差值是否大于10
if (end - begin <= VALUE) {
for (int i = begin; i <= end; i++) {
result = result + i;
}
//否,则进一步拆分
} else {
//中间值
int middle = (begin+end) /2;
//左边
MyTask task01 = new MyTask(begin, middle);
//右边
MyTask task02 = new MyTask(middle + 1, end);
//调用方法拆分
task01.fork();
task02.fork();
//合并结果
result = task01.join() + task02.join();
}
return result;
}
}
以上自定义Task中体现的思路就是:问题足够小的时候,直接处理,否则就继续拆分。创建forkjoinpool对象,提交任务,获取执行结果:
public class ForkJoinDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//创建拆分任务对象
MyTask myTask = new MyTask(0, 100);
//创建分支合并池对象
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> forkJoinTask = forkJoinPool.submit(myTask);
//获取最终合并之后的结果
Integer result = forkJoinTask.get();
System.out.println(result);
//关闭池对象
forkJoinPool.shutdown();
}
}
结果:
5050
3、ForkJoinTask
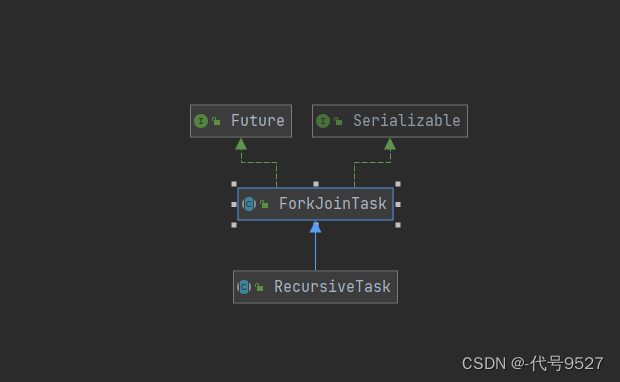
ForkJoinTask有两个子类:Recursive即递归的意思
- RecursiveTask:有返回值的任务
- RecursiveAction:没有返回值的任务
ForkJoinTask还实现了Future接口,即说明是一个可以异步获取结果的任务。常用方法有:
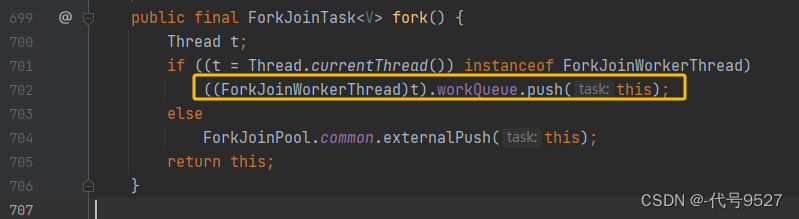
- fork:分割子任务,判断当前线程是否可以转型为ForkJoinWorkerThread类型,即是不是通过ForkJoinPool线程池执行的ForkJoinTask,是就push到队列里
- 合并子任务结果:join
//调用方法拆分
task01.fork();
task02.fork();
//合并结果
result = task01.join() + task02.join();
- 获取任务执行结果:get,即等待任务执行完成并返回任务计算结果
【方法源码详解参考这篇】
4、工作窃取算法
先看类ForkJoinWorkerThread类,它是执行前面ForkJoinTask的线程。ForkJoin框架使用的线程维护了一个双端队列,并通过工作窃取算法(work-stealing)来提高任务执行的效率。
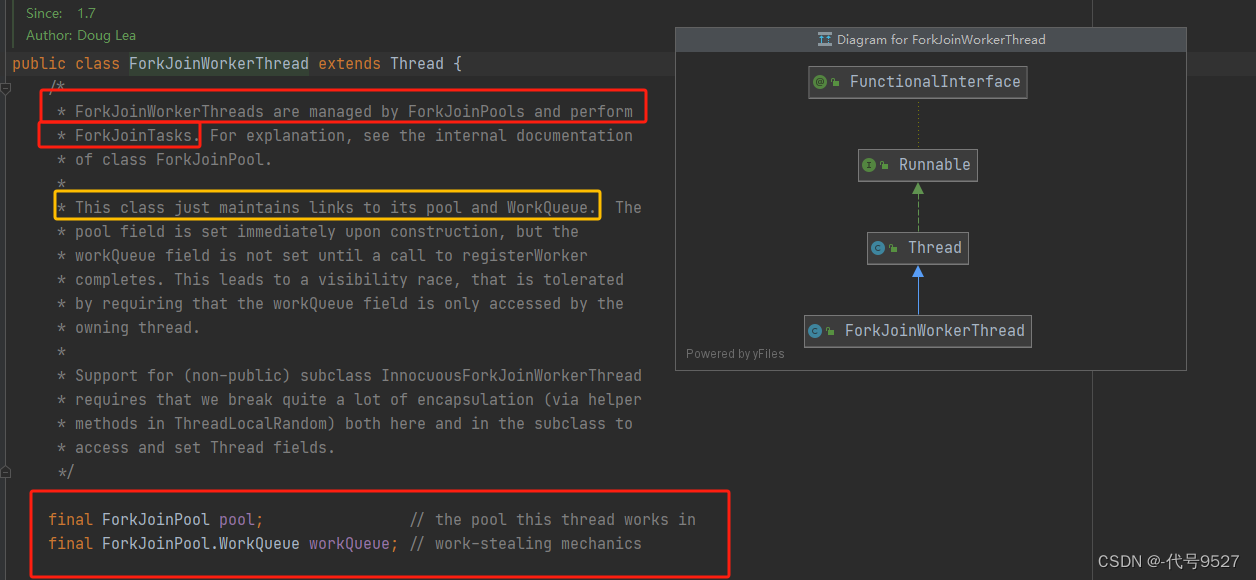
工作窃取算法,在ForkJoin框架中就是一个线程的任务队列里的活儿都干完了,就去其他线程维护的任务队列的尾部窃取一个任务来执行。用张网图示意:
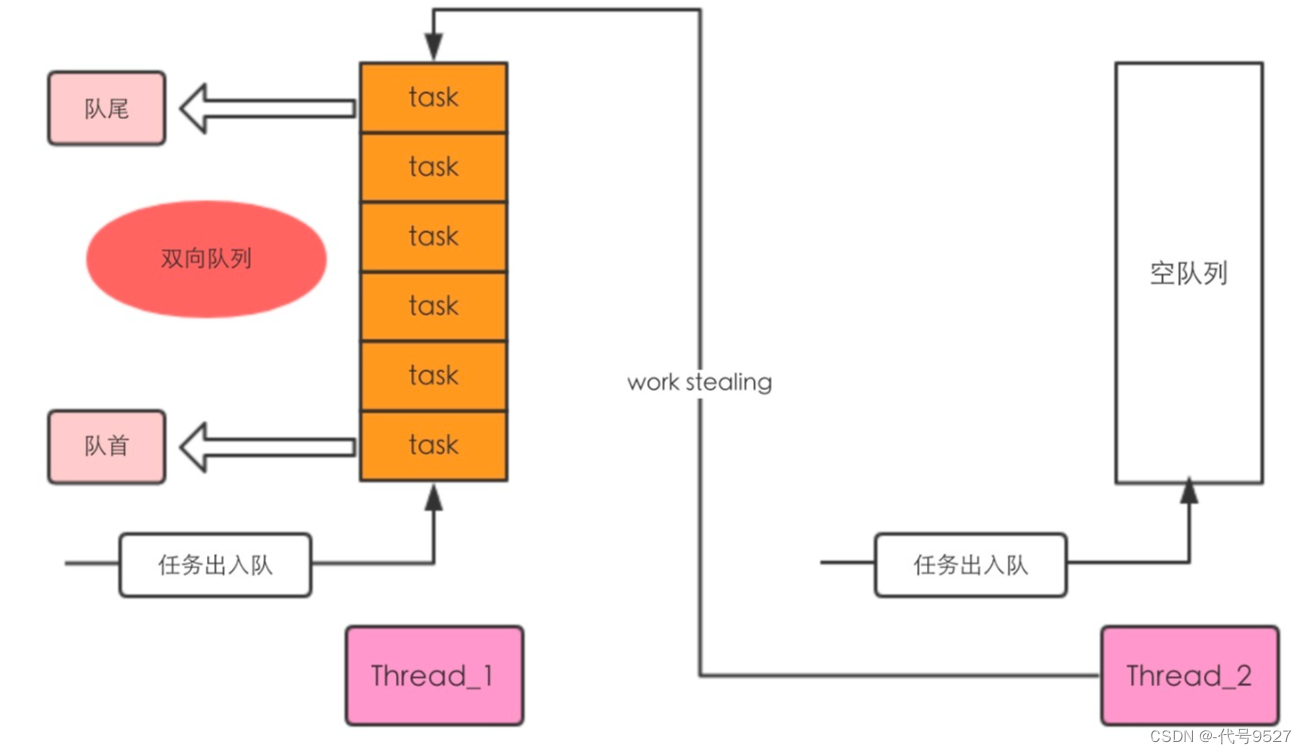
因此:
- 对于线程自身维护的任务队列,线程自身执行任务的顺序是后进先出
- 对于窃取其他线程队列的线程,则是先进先出(从队尾窃取并执行)
如图,对于线程1,任务的出入队都在队首,而负责窃取任务的线程2,其从队尾取任务,也就是说,只有线程1的任务队列只剩最后一个任务的时候,才会抢夺一次锁。如此,就大大提高了并发任务的执行效率。
5、ForkJoinPool
FoolJoinPool是运行ForkJoinTask的线程池,同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口
任务提交到ForkJoinPool后,池里维护的线程来执行任务
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> forkJoinTask = forkJoinPool.submit(myTask);
其构造方法有四个参数:
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode){
//.....
分别是:
- parallelism:期望并发数,默认会使用Runtime.getRuntime().availableProcessors()的值,即当前计算机可用的CPU数量
- factory:创建ForkJoin工作线程的工厂,默认为defaultForkJoinWorkerThreadFactory
- handler:执行任务时遇到不可恢复的错误时的处理程序,默认为null
- asyncMode:工作线程获取任务使用FIFO(先进先出)模式还是LIFO模式,默认为LIFO(后进先出)