数据湖是一个集中化的存储系统,旨在以低成本、大容量的方式,无需预先对数据进行结构化处理,存储各种结构化和非结构化数据。以下是数据湖概念、发展背景和价值的详细介绍。
数据湖概念
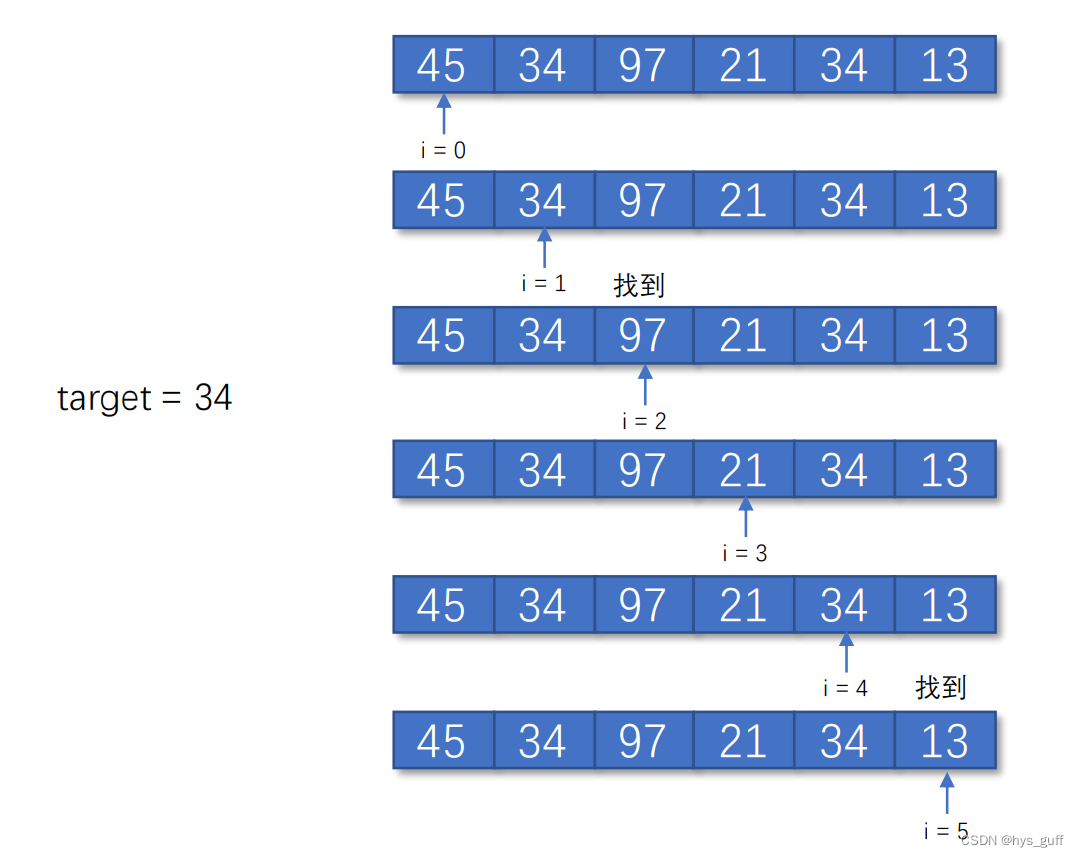
数据湖的概念源自于对传统数据仓库的补充。传统数据仓库通常要求对数据进行预处理和结构化,而数据湖则提供了一个中央化的存储库,允许直接存储原始、未加工的数据。其典型分层结构如下图所示。

发展背景
互联网早期:初始阶段,各公司的数据量较小,使用基于关系型数据库的简单数据架构。然而,随着互联网的爆发,数据量急剧增长,传统的数据库架构出现了问题,无法支撑大规模数据的存储和处理。
Hadoop的出现:Hadoop通过开源方式成为大数据分析的分水岭。然而,Hadoop在某些方面存在局限性,如不支持事务、缺少Schema等,引发了对数据管理和可用性的新问题。
Hadoop+数据仓库:为解决Hadoop本身的缺陷,用户选择将Hadoop与数据仓库结合使用,然而,这种数据架构重新引入了数据孤岛问题,导致数据冗余和运维上的复杂性。同时也带来了新的挑战,如数据一致性和运维成本的管理。
数据湖的涌现:数据湖的引入是为了弥补Hadoop和数据仓库各自的不足,提供了低成本、大容量、事务支持等综合性能,为企业提供更灵活、更综合的数据存储和处理方案。
数据湖的引入及价值
为满足用户对系统既具备Hadoop低成本大容量优势又具备数据仓库ACID事务等能力的需求,数据湖应运而生。数据湖可被理解为一种融合了Hadoop和数据仓库优势的技术。它建立在低成本分布式存储之上,提供更好的事务和性能支持,形成了统一的数据存储系统。数据湖的价值如下:
综合数据存储: 数据湖能够容纳各种结构化和非结构化数据,无需预处理,为企业提供了一个统一的数据存储平台。
低成本大容量: 借助Hadoop的优势,数据湖提供了低成本和大容量的存储能力,使企业能够经济高效地管理海量数据。
灵活性和扩展性: 数据湖结合了Hadoop的灵活性和扩展性,支持多种数据类型和大规模数据的存储和处理。
ACID事务支持: 数据湖继承了数据仓库的ACID事务支持,提高了数据的可靠性和一致性,使其更适用于关键业务场景。
解决数据孤岛问题: 数据湖通过统一的数据存储系统,解决了Hadoop和数据仓库搭配使用时可能出现的数据冗余和数据孤岛问题。
综上所述,数据湖的出现为企业提供了更灵活、更综合、更经济的数据管理和分析解决方案,使其能够更好地利用数据资产,做出更明智的决策。