参考书籍:
- 《数据结构与抽象:Java语言描述》 第四版
一、背景知识
- 散列(hashing):是仅利用项的查找键,无需查找就可确定其下标的一项技术
- 散列表(hash table):数组
- 散列索引(hash index):下标
- 散列函数(hash function):根据查找键得到元素在散列表中的整数下标
- 查找键映射(map)或散列(hash)到下标
- 散列函数使用hashCode()方法从查找键来计算散列码(hash code),然后将散列码压缩为散列表的地址。
- 散列码:c;
- 散列表的位置个数:n;(大于2的素数)
- c%n 在0~n-1之间
- c%n 是有n个位置的散列表的理想下标
- 对象不equals,散列码就不同。
- 冲突(collision):多个查找键映射到散列表中的同一个位置
- 冲突解决方案(collision resolution):
- 1、开放地址法
- (1)线性探查(linear probing):检查散列表中的连续位置,从原始散列地址开始,每次的增量为1,直到找到下一个可用的位置
- 出现的问题:基本聚集(primary clustering),即散列表中一组组(簇,cluster)连续的位置被占用
- 优点:能够到达散列表的每个位置
- (2)二次探查(quadratic probing):从最初的散列地址
开始,每次的增量为
,检查地址为
的位置。

- 如果探查序列到达散列表的表尾,它会绕回到表的开头。越到序列的后面距离增量会越大
- 出现的问题:通过检查散列表中最初的散列地址加上
- (3)双散列(double hashing):检查散列表中最初的散列地址加上由第二个散列函数定义的增量的位置
- 优点:避免了基本聚集和二级聚集
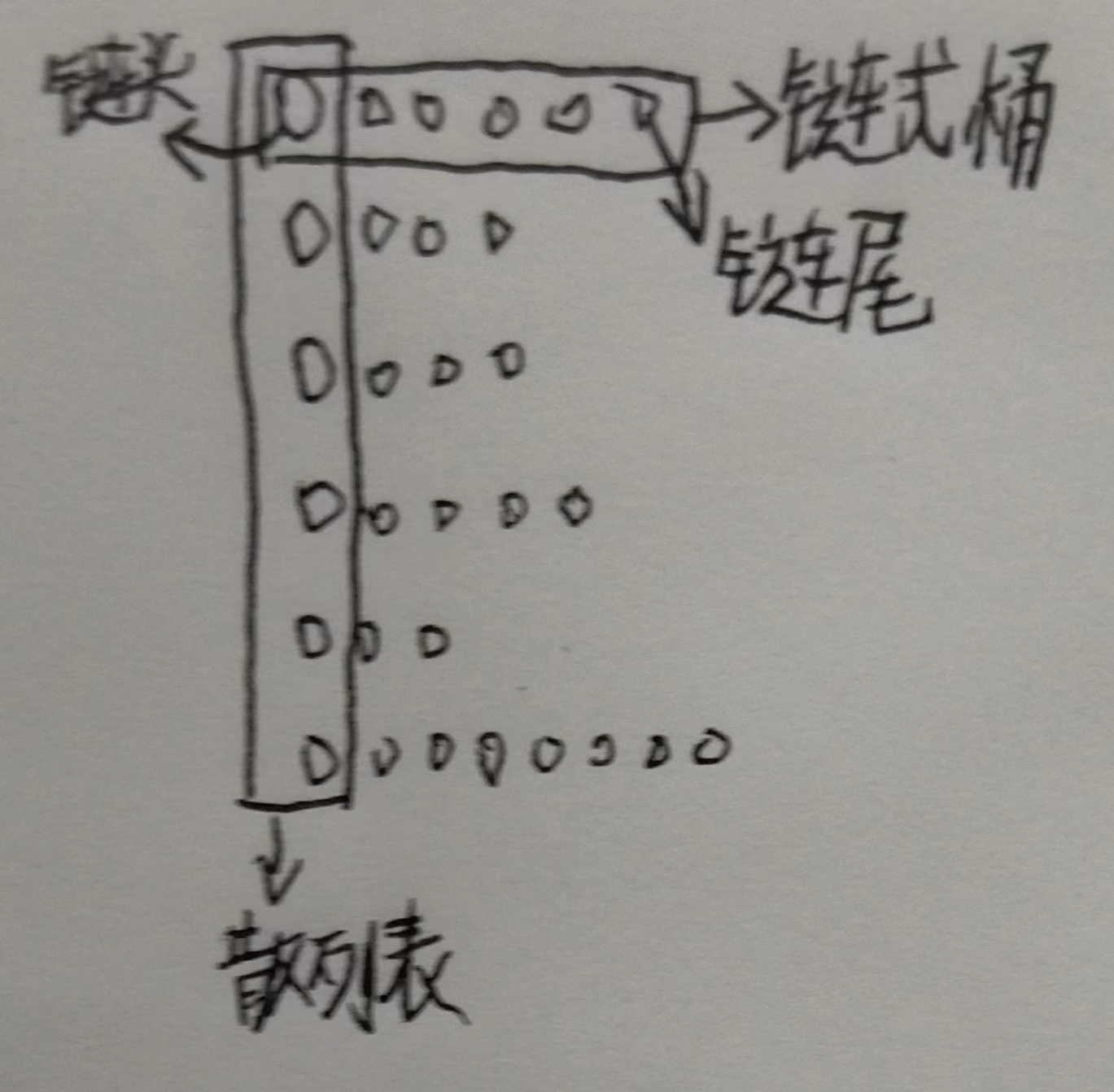
- 2、拉链法
- 桶(bucket):每个位置可以表示多个值,多用链式结构,因为可以给桶按需分配内存
- 散列表的每个位置都是一个个链式桶,先散列查找键,然后在链式桶里查找键-值对。如果允许重复键,就把新项添加到链头,否则遍历链式桶,添加到链尾。
- 改变了散列表的结构
- 散列表:
- 时间复杂度
二、(Hash Table)
老东西,现在不咋用了
三、哈希映射(Hash Map)
//哈希映射常用方法:
Map<T,T> map=new HashMap<>();//创建一个哈希映射
map.clear();//清空哈希映射
map.containsKey(key);//是否包括元素key,返回boolean值
map.containsValue(value);//是否包括元素value,返回boolean值
map.get(key);//返回键key对应的值value
map.isEmpty();//哈希映射是否为空,返回boolean值
map.put(key,value);//把键值对存入哈希映射
map.remove(key);//移除key这对键值对
map.size();//获取哈希映射的大小
map.getOrDefault(key,value);//如果map中包含key,就获取对应的值,否则返回value哈希集合的遍历方式:
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class Test {
public static void main(String[] args) {
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("1","value1");
hashMap.put("2","value2");
hashMap.put("3","value3");
hashMap.put("4","value4");
hashMap.put("5","value5");
hashMap.put("6","value6");
/**
* 第一种遍历方式,采用for遍历key值,然后通过key去获取hashmap中的数据
*/
for (String key:hashMap.keySet()) {
System.out.println("key: " + key + " value: " + hashMap.get(key));
}
/**
* 第二种遍历方式,采用Iterator 把hashmap中的数据放到迭代器中,然后用while循环把迭代器中的数据都读出来
*/
Iterator iterator = hashMap.entrySet().iterator();
while(iterator.hasNext()) {
Map.Entry<String, String> entry=(Map.Entry<String, String>) iterator.next();
System.out.println("Key: "+entry.getKey()+" Value: "+entry.getValue());
}
/**
* 第三种遍历方式,采用for循环遍历hashmap中的数据,使用方便,但是数据量小时好用,如果数据量大的话非常消耗性能
*/
for(Map.Entry<String, String> entry: hashMap.entrySet()) {
System.out.println("Key: "+ entry.getKey()+ " Value: "+entry.getValue());
}
}
}
三、 哈希集合(Hash Set)
//哈希集合常用方法:
Set<T> set=new HashSet<>();//创建一个T类型的哈希集合
set.add(e);//添加元素
set.clear();//清空哈希集合
set.contains(e);//哈希集合中是否包含元素e,返回boolean值
set.isEmpty();//哈希集合中是否为空,返回boolean值
set.iterator();//返回一个迭代器
set.remove(e);//删除元素e
set.size();//获取哈希集合的大小
set.toArray();//返回一个包含哈希集合所有元素的数组
HashTable HashMapHashSet实现了接口 Map实现了接口 Map实现了接口Collection 存储键值对 存储键值对 仅存储对象(元素) 线程安全 线程不安全 线程不安全 不允许键或值为null,且不保证元素顺序 允许键和值为null,但不保证元素顺序,且键不可重复 允许值为null,但不保证元素顺序,且元素不可重复
四、例题
1、两数之和

方法一:双重for循环
class Solution {
public int[] twoSum(int[] nums, int target) {
int[] arr=new int[2];//把结果存入数组中返回
for(int i=0;i<nums.length-1;i++){
for(int j=i+1;j<nums.length;j++){
if(nums[i]+nums[j]==target){
arr[0]=i;
arr[1]=j;
break;
}
}
}
return arr;
}
}
方法二:哈希表
class Solution {
public int[] twoSum(int[] nums, int target) {
int[] arr=new int[2];
Map<Integer,Integer> ht=new HashMap<>();//创建一个哈希表
for(int i=0;i<nums.length;i++){
if(ht.containsKey(target-nums[i])){
arr[0]=i;
arr[1]=ht.get(target-nums[i]);//键
break;
}
ht.put(nums[i],i);//哈希表的键:数组元素;值:数组元素下标
}
return arr;
}
}
/**
思路:
1、在哈希表中查找target-x
2、如果哈希表中不存在target-x,再将x插入哈希表中,即可保证x不会和自己匹配
*/
进一步优化:(去掉数组后,降低了时间复杂度)
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer,Integer> ht=new HashMap<>();//创建一个哈希表
for(int i=0;i<nums.length;i++){
if(ht.containsKey(target-nums[i])){
return new int[]{i,ht.get(target-nums[i])};
}
ht.put(nums[i],i);//哈希表的键:数组元素;值:数组元素下标
}
return new int[0];
}
}
/**
思路:
1、在哈希表中查找target-x
2、如果哈希表中不存在target-x,再将x插入哈希表中,即可保证x不会和自己匹配
*/
2、字母异位词分组
 方法一:哈希表
方法一:哈希表
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> list1=new ArrayList<>();
Map<String,List<String>> hashtable=new HashMap<>();
//遍历数组,存下标进哈希表
for(int i=0;i<strs.length;i++){
//对单词进行重排序
char[] c=strs[i].toCharArray();
Arrays.sort(c);
String s=new String(c);
//String s=c.toString();
if(!hashtable.containsKey(s)){//哈希表中未出现这种字母组合
List<String> list3=new ArrayList<>();
list3.add(strs[i]);
hashtable.put(s,list3);
}else{//哈希表中已有这种字母组合,直接添加单词进去,更新list3
hashtable.get(s).add(strs[i]);//相当于list3.add(strs[i]);
}
}
//遍历哈希表,存单词进链表
for(String key:hashtable.keySet()){
list1.add(hashtable.get(key));
}
return list1;
}
}
/**
思路:
把单词按字母顺序重新排序后,存入哈希表中,当键
遍历哈希表,取出值(一条条链表list3)存入链表list1中返回
*/

简洁化代码:
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<String, List<String>>();
for (String str : strs) {
//将排序之后的字符串作为哈希表的键
char[] array = str.toCharArray();
Arrays.sort(array);
String key = new String(array);
//如果哈希表中的key存在,就调用map.get(key)方法,返回值
//如果不存在,就返回new ArrayList<String>(),创建新链表
List<String> list = map.getOrDefault(key, new ArrayList<String>());
list.add(str);
map.put(key, list);
}
//把哈希表里的值取出存入新链表返回
return new ArrayList<List<String>>(map.values());
}
}
//哈希表的键为一组字母异位词的标志,哈希表的值为一组字母异位词列表。
3、最长连续序列
方法一:普通遍历
class Solution {
public int longestConsecutive(int[] nums) {
if(nums.length==0){
return 0;
}
Arrays.sort(nums);//对原数组进行排序
int len=1;//连续序列长度
int m=1;//最大值
if(nums.length>1){
for(int i=0;i<nums.length-1;i++){
if(nums[i+1]-nums[i]==1){//元素是连续
len++;//长度加一
m=Math.max(m,len);//维护一个最大值
}else if(nums[i+1]-nums[i]>1){//元素不连续
len=1;//连续序列长度重置为0,继续搜寻下一组连续序列
}
}
}
return m;
}
}
/**
思路:
1、对原数组进行排序
2、遍历原数组,维护一个序列长度的最大值
*/
方法二:哈希表
考察了hashset的contains()方法查找元素和其元素的无序性
class Solution {
public int longestConsecutive(int[] nums) {
Set<Integer> num_set = new HashSet<Integer>();
for (int num : nums) {//用哈希表存储数组元素,去重(哈希集合不能存储相同的元素)
num_set.add(num);
}
int longestStreak = 0;//最长序列长度
for (int num : num_set) {//遍历哈希表
if (!num_set.contains(num - 1)) {//当前值不存在前驱,要么它是连续序列中的第一个元素,要么它不在连续序列,跳过
int currentNum = num;
int currentStreak = 1;
while (num_set.contains(currentNum + 1)) {//当前值存在前驱,进入内层循环,去匹配该组连续序列的数,
currentNum += 1;
currentStreak += 1;
}
longestStreak = Math.max(longestStreak, currentStreak);//维护一个最大值
}
}
return longestStreak;
}
}