一、复习知识点:
CPU性能指标:
load average:负载,linux查看的时候,通常显示如下:
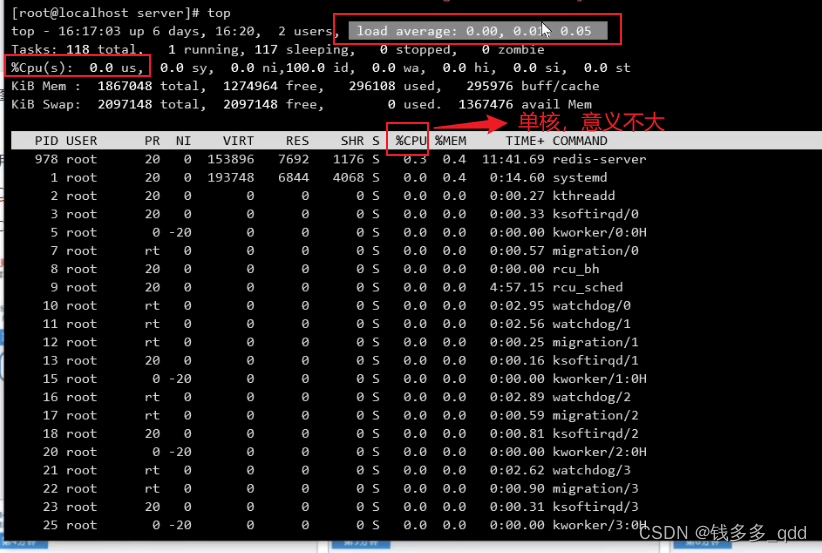
load average后面有三段数字:代表了系统1分钟,5分钟,15分钟平均负载。
形象的类别可以参考:了解 Linux CPU 负载 - 什么时候应该担心?(网址可翻译中文)
另一个形象的比喻:CPU的load和使用率傻傻分不清(非常重要,建议详细阅读)
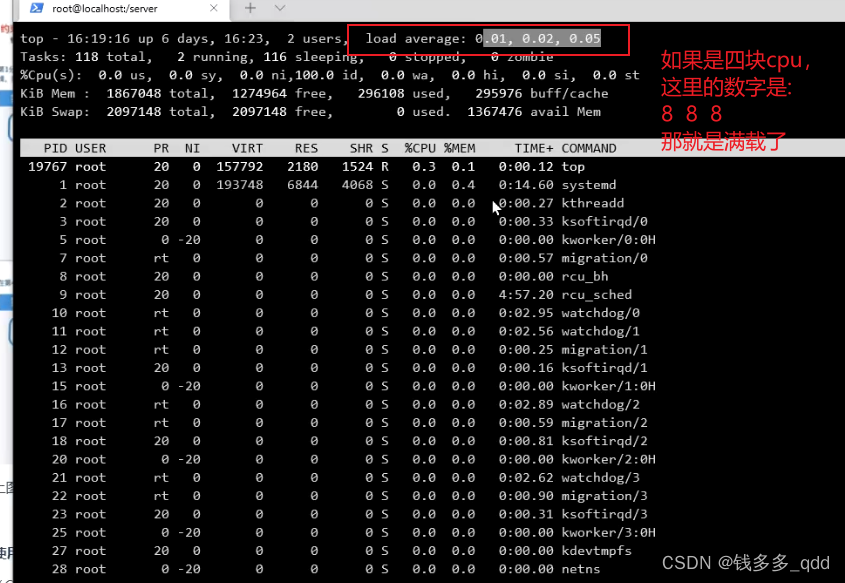
当load average高,%Cpu(s)低,表示:负载高,利用率低。
二、查看cpu飙升原因需要用到的命令
查看cpu信息:
cat /proc/cpuinfo
仅显示将使用的处理器名称:
grep -c 'model name' /proc/cpuinfo
2.1 定位CPU标高
1.执行完 java -jar 2_cpu-0.0.1-SNAPSHOT.jar 8 > log.file 2>&1 & 命令:
2.查看进程号,jps -l :

3.用top查看进程中的线程,top -Hp 25128 :
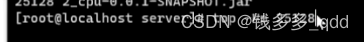
4.执行后,就出来了每个线程锁占的cpu,如图:
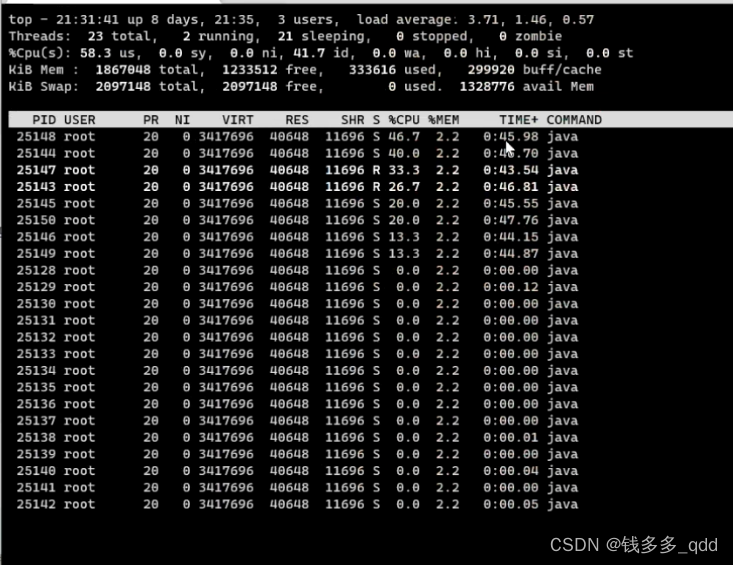
最简单直接的,就是看某个线程的cpu占用;
有一种情况不好分析:分析是正常现象还是异常现象,有些项目可以cpu执行就稳态在60%-70%之间。
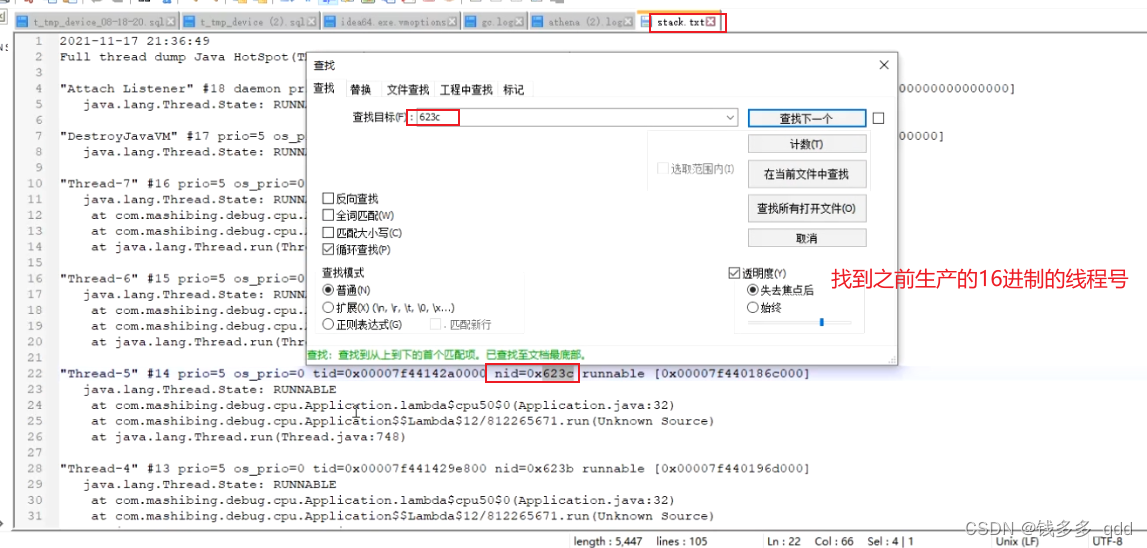
5.将线程转成16进制,printf “%x\n” 25148 :

这里的623c就是25148线程的16进制线程号。
6.导出某线程的stack,jstack 25128 》stack.txt:

7.到stack.txt文本中找623c线程号相关日志:
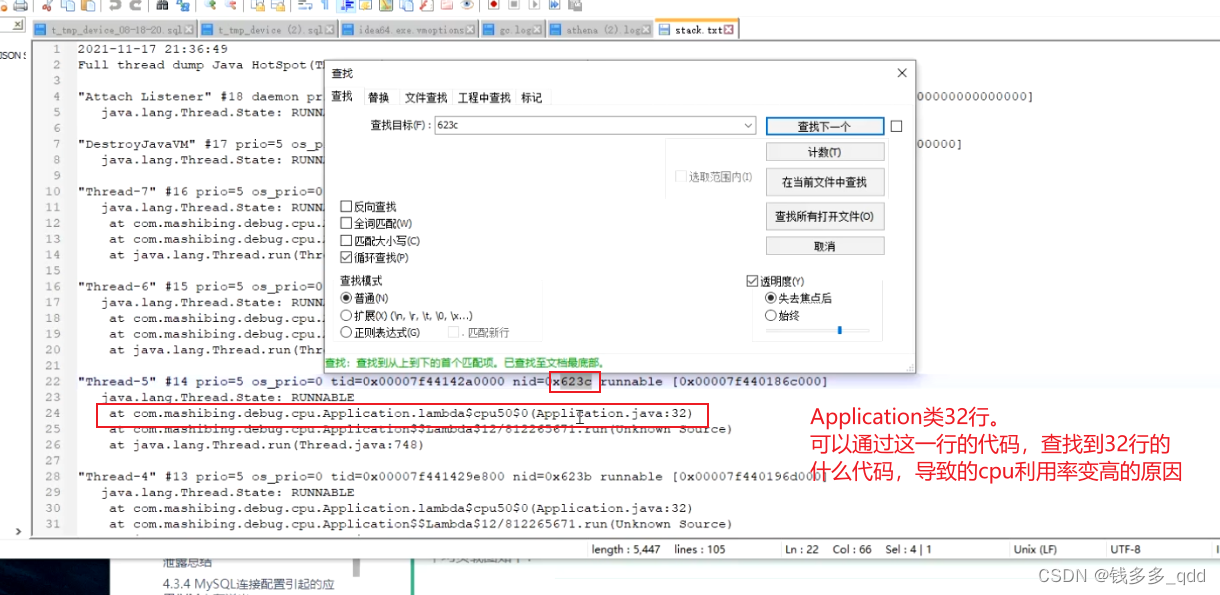
2.2 总结
方法1:
- 启动:java -jar 2_cpu-0.0.1-SNAPSHOT.jar 8 > log.file 2>&1 &
- 一般来说,应用服务器通常只部署了java应用,可以top一下先确认,是否是java应用导致的:命令:top
- 如果是,查看java进场ID,命令:jps -l
- 找出该进程内最好非CPU的线程,命令:top -Hp pid 25128
- 将线程ID转化为16进制,命令:printf “%x\n” 线程ID 623c 25148
- 导出java堆栈信息,根据上一步的线程ID查找结果:命令:
jstack 11976 >stack.txt
grep 2ed7 stack.txt -A 20
方法2:
在线工具:FastThread
- 方法1中导出的对快照文件,上传到该网站即可
三、案例一:序列化问题引起的应用服务CPU飙高
3.1 发现问题
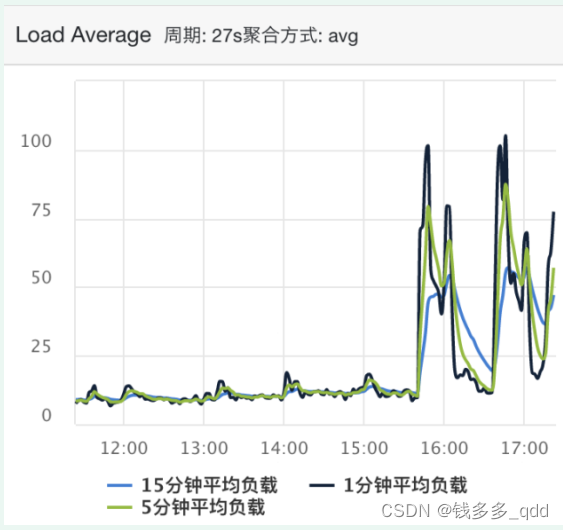
7.8日 17:09监控大盘发现xxx-web的CPU快跑满,导致机器不断扩容增加机器。
平均负载图如下:
CPU利用率:

3.2 分析阶段
根据对线程dump文件进行分析,主要是否存在死锁、阻塞现象,以及CPU线程的占用情况,分析工具采用在线fastThread工具。地址: https://gceasy.io/ft-index.jsp
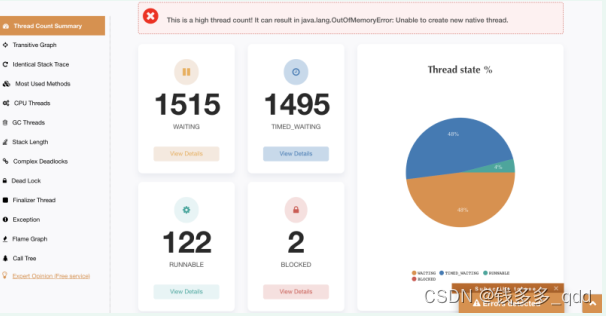
3.2.1 查看线程数情况
数据图示可知,创建的线程等待线程有3000,提示高线程数可能导致内存泄露异常,从而可能影响后面任务的创建线程。
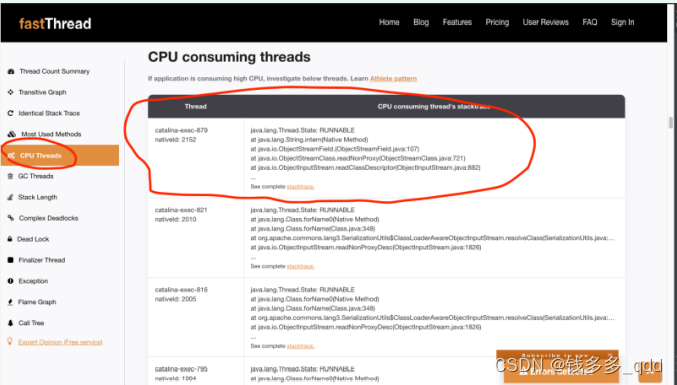
3.2.2 查看当前CPU线程使用情况
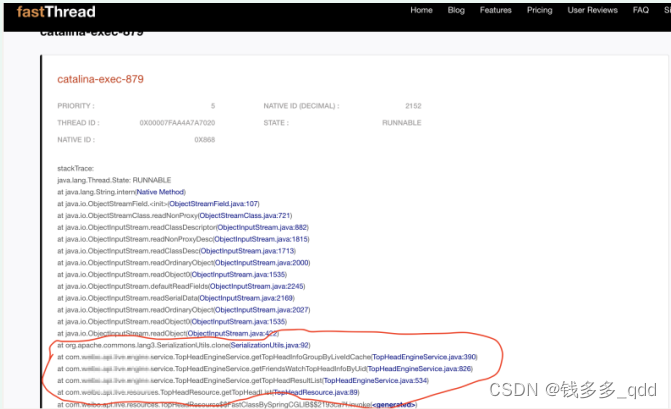
根据CPU线程情况,查询CPU正在执行的线程堆栈列表,可以发现大部分日志都是类似于:catalina-exec-879
3.2.3 定位出现问题的线程堆栈
查看是新版头像圈的一段代码逻辑,其中有个步骤需要深拷贝对象,以便以后逻辑更改使用。
3.3 问题恢复
从而猜测可能是跟8号开放一批白名单规则用户有关,所以临时采用更改config的白名单策略配置,降低灰度用户范围。通过配置推送后,CPU利用率恢复正常情况。
3.4 相关代码
public Map<String, TopHeadInfoV3> getTopHeadInfoGroupByLiveIdCache(){
Map<String, TopHeadInfoV3> topHeadInfoGroupByLiveIdMap =
topHeadInfoGroupByLiveIdCache.getUnchecked("top_head_info_group_by_live_id");
if (MapUtils.isEmpty(topHeadInfoGroupByLiveIdMap)) {
return Collections.emptyMap();
}
// guava cache 对象对外不可⻅,防⽌上游对cache⾥对象进⾏修改,并发场景下出现问题
Map<String, TopHeadInfoV3> topHeadInfoGroupByLiveIdMapDeepCopy =
Maps.newHashMapWithExpectedSize(topHeadInfoGroupByLiveIdMap.size());
for (Map.Entry<String, TopHeadInfoV3> entry : topHeadInfoGroupByLiveIdMap.entrySet()) {
topHeadInfoGroupByLiveIdMapDeepCopy.put(entry.getKey(),
SerializationUtils.clone(entry.getValue()));
}
return topHeadInfoGroupByLiveIdMapDeepCopy;
}
其中影响性能的问题方法是apache commongs工具包提供的对象克隆工具:SerializationUtils.clone(entry.getValue())),基本操作就是利用Object InputStream和Object OutputSTream进行,先序列化再发序列化。频繁克隆且耗时较长,导致占用其他任务的执行。
// Clone
//-----------------------------------------------------------------------
/**
* <p>Deep clone an {@code Object} using serialization.</p>
* *
<p>This is many times slower than writing clone methods by hand
* on all objects in your object graph. However, for complex object
* graphs, or for those that don't support deep cloning this can
* be a simple alternative implementation. Of course all the objects
* must be {@code Serializable}.</p>
* *
@param <T> the type of the object involved
* @param object the {@code Serializable} object to clone
* @return the cloned object
* @throws SerializationException (runtime) if the serialization fails
*/
public static <T extends Serializable> T clone(final T object) {
if (object == null) {
return null;
}
final byte[] objectData = serialize(object);
final ByteArrayInputStream bais = new ByteArrayInputStream(objectData);
try (ClassLoaderAwareObjectInputStream in = new ClassLoaderAwareObjectInputStream(bais,object.getClass().getClassLoader())) {
/*
* when we serialize and deserialize an object,
* it is reasonable to assume the deserialized object
* is of the same type as the original serialized object
*/
@SuppressWarnings("unchecked") // see above
final T readObject = (T) in.readObject();
return readObject;
} catch (final ClassNotFoundException ex) {
throw new SerializationException("ClassNotFoundException while reading cloned
object data", ex);
} catch (final IOException ex) {
throw new SerializationException("IOException while reading or closing cloned
object data", ex);
}
}
源代码注释:
使用序列化来深度克隆一个对象。
这比在你的对象图中的所有对象上手工编写克隆方法要慢很多倍。然而,对于复杂的对象图,或者那些不支持深度克隆的对象,这可以是一个简单的替代实现。当然,所有的对象必须是可序列化的。
3.5 优化方案
经过讨论临时采用创建对象和属性设置的方式进行对象复制,先不采用对象序列化工具。实现java.lang.Cloneable接口并实现clone方法。
主要对象拷贝代码如下:
@Override
public TopHeadInfoV3 clone() {
Object object = null;
try {
object = super.clone();
} catch (CloneNotSupportedException e) {
return null;
}
TopHeadInfoV3 topHeadInfoV3 = (TopHeadInfoV3) object;
topHeadInfoV3.playEnums = Sets.newHashSet(topHeadInfoV3.playEnums);
topHeadInfoV3.recallTypeEnums = Sets.newHashSet(topHeadInfoV3.recallTypeEnums);
topHeadInfoV3.behaviorEnums = Sets.newHashSet(topHeadInfoV3.behaviorEnums);
topHeadInfoV3.micLinkUserList =
topHeadInfoV3.micLinkUserList.stream().map(MicLinkUser::clone).collect(Collectors.toList());
return topHeadInfoV3;
}
3.7 问题总结
针对相对大流量的接口可以提前做好压测分析;
上线后定期通过监控大盘查看线上运行情况,留意机器监控告警便于及时发现问题;
若告警或大盘发现问题CPU或内存使用情况异常,其中可以打印线程堆栈日志,通过堆栈分析工具帮助分析线程使用的情况。
序列化参考:eishay/jvm-serializers
四、案例二:FULL GC引起的应用服务CPU飙高
4.1 排查过程
- 查看机器监控,初步判断可能有耗CPU的线程;
- 导出jstat信息,发现JVM老年代占用过高(达到97%),Full-GC频率超高,FULL-GC总共占用了36小时。初步定位是频繁FULL-GC导致CPU负载过高。
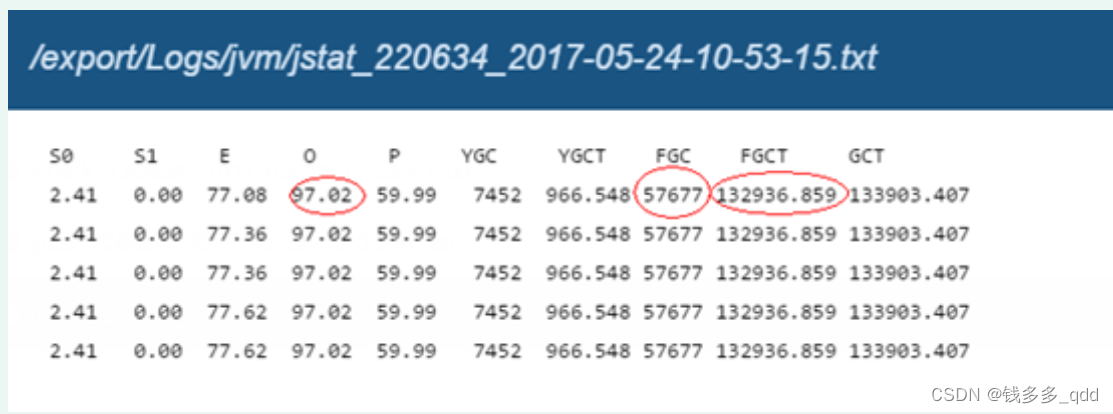
- 使用jmap –histo导出堆概要信息,发现有个超大的HashMap;
- 使用jmap –dump导出堆。得出hashMap中的KEY是运单号;
4.2 总结
- 使用缓存时要做容量估算,并考虑数据增长率;
- 缓存要有过期时间;
五、gc问题导致调用端出现RpcException问题排查
5.1 场景问题案例解读:
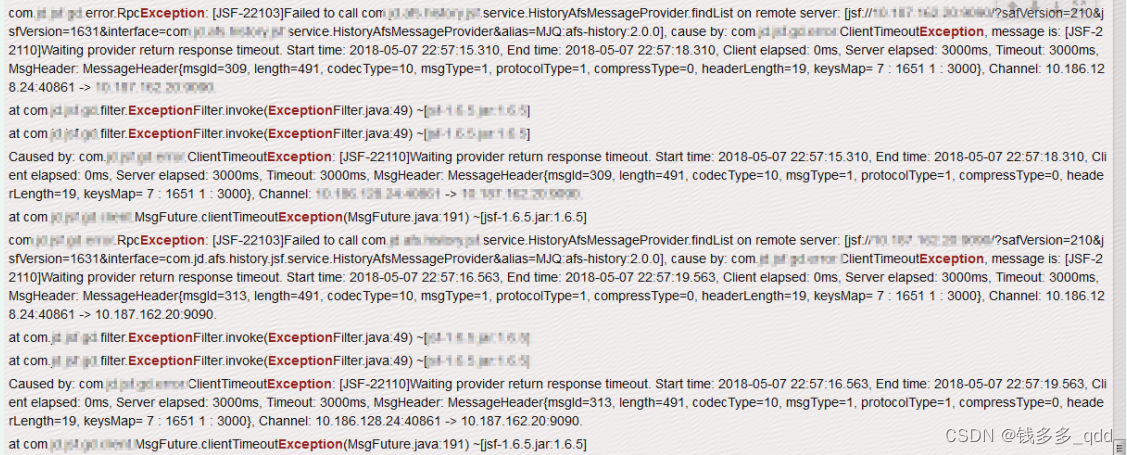
- 该应用上线弹性数据库后,调用端通过接口查询历史库应用服务时,出现大面积RpcException,如下图所示:
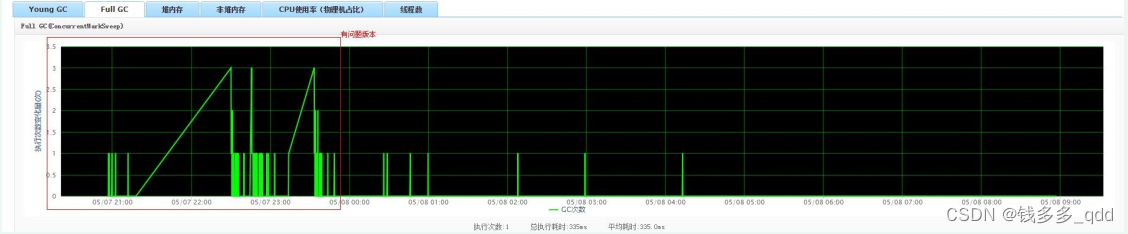
- 观察该应用,full gc 情况,如下图所示,会出现高频full gc 情况,如图所示:
- 观察应用,young gc情况,如下图所示:
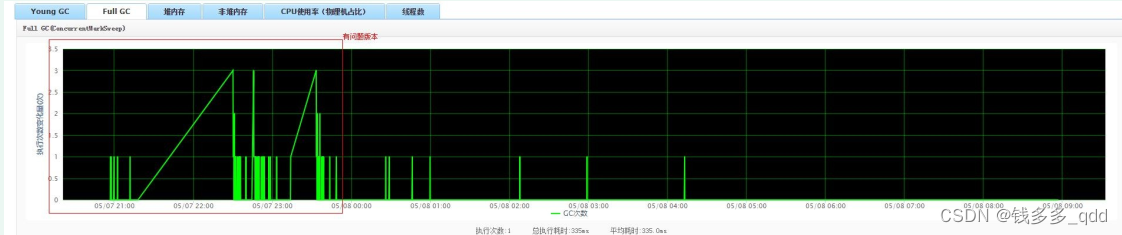
- 查看jvm配置参数时,配置内容如下(可以通过ump、应用配置、堡垒机打印应用信息等方式查看)
-Xss512k
-Xmn2048m
-XX:+UseConcMarkSweepGC
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+CMSParallelRemarkEnabled
-XX:+CMSClassUnloadingEnabled
-XX:CMSInitiatingOccupancyFraction=60
-XX:CMSInitiatingPermOccupancyFraction=60
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintClassHistogram
-Xloggc:/export/Logs/jvm/gc.log
- 通过jstat命令打印内存,情况如下图所示:
命令:jstat -gcutil pid
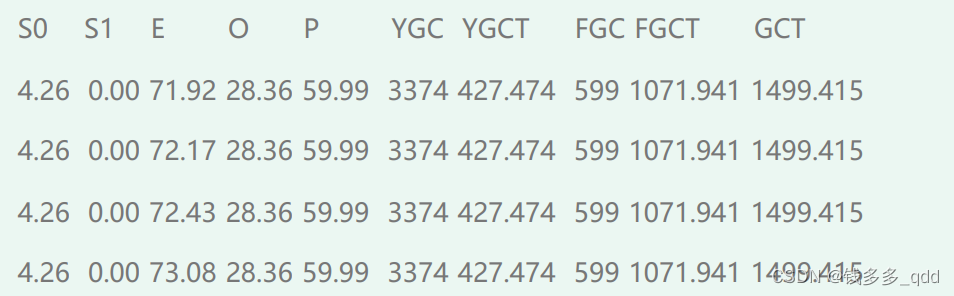
- 之前我们已经配置了jvm参数来打印gc日志,如下所示

综上所述:
通过gc日志可以看到CMS remark阶段耗时较长,如果频繁的full gc且remark时间比较长,会导致调用端大面积超时,接下来需要通过jstat命令查看内存情况结合配置的jvm启动参数看一下为啥会频繁的full gc。应用jvm启动参数配置了-XX:CMSInitiatingPermOccupancyFraction=60,持久带使用空间占60%的时候就会触发一次full gc,由于持久带存放的是静态文件,持久带一般情况下对垃圾回收没有显著影响。所以可考虑去掉该配置项。
解决方案:
持久带用于存放静态文件,如今Java类、方法等, 持久代一般情况下对垃圾回收没有显著影响,应用启动后持久带使用量占比即接近60%,所以可考虑去掉该配置项。
同时增加配置项-XX:+CMSScavengeBeforeRemark,在CMS GC前启动一次young gc,目的在于减少old gen对ygc gen的引用,降低remark时的开销(通过上述案例可观察到,一般CMS的GC耗时 80%都在remark阶段 )
jvm启动参数更正如下:
-Xss512k
-XX:+UseConcMarkSweepGC
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=80
-XX:+CMSScavengeBeforeRemark
-XX:+CMSParallelRemarkEnabled
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-Xloggc:/export/Logs/jvm/gc.log
-javaagent:/export/servers/jtrace-agent/pinpoint-bootstrap-1.6.2.jar
-Dpinpoint.applicationName=afs
-Dpinpoint.sampling.rate=100
备注:相比有问题版本,去除了配置项:-XX:CMSInitiatingPermOccupancyFraction=60。
-XX:CMSInitiatingOccupancyFraction 修改为80(Concurrent Mark Sweep (CMS)
Collector ),添加配置项
-XX:+CMSScavengeBeforeRemark,为了个更好的观察
gc日志,修改时间戳打印格式为-XX:+PrintGCDateStamps
5.2 其他:
- -XX:CMSInitiatingOccupancyFraction;
- -XX:+CMSScavengeBeforeRemark;
这两个参数建议不要配,直接使用jvm默认的。
垃圾回收器:
国内基本都是用jdk1.8,要不用CMS,要不就是用G1;
触发young gc只可能有两个条件:
- 新生代(eden区)内存不够;
- 配置了XX:+CMSScavengeBeforeRemark 参数,在运行full gc(full gc本身就会有young gc)之后,强制又运行了young gc;
命令:
- jps
- jinfo
五、Idea安装VisualVM launcher插件
Idea 离线安装插件 Idea 安装离线插件
IDEA插件的在线离线安装
IDEA集成性能分析神器VisualVM
注意:
VisualVM launcher离线安装是jar格式,不是zip格式;




![[架构之路-247]:目标系统 - 设计方法 - 软件工程 - 结构化方法的基本思想、本质、特点以及在软件开发、在生活中的应用](https://img-blog.csdnimg.cn/eec47958ab184d6d818aeab39d796148.png)