文章目录
- RDD编程模型介绍
- RDD的两种算子及延迟计算
- 常见的Transformation算子
RDD编程模型介绍
- RDD是Spark 对于分布式数据集的抽象,它用于囊括所有内存中和磁盘中的分布式数据实体。每一个RDD都代表着一种分布式数据形态。
- 在RDD的编程模型中,一共有两种算子,Transformations类算子和Actions类算子。开发者需要使用Transformations类算子,定义并描述数据形态的转换过程,然后调用Actions类算子,将计算结果收集起来、或是物化到磁盘。
RDD的两种算子及延迟计算
-
Transformation算子:基于不同RDD数据形态之间的转换,构建计算流图(DAG,Directed Acyclic Graph)。
-
Actions类算子:以回溯的方式去触发执行这个计算流图。
-
开发者调用的各类Transformations算子,并不立即执行计算,当且仅当开发者调用Actions算子时,之前调用的转换算子才会付诸执行。在业内,这样的计算模式有个专门的术语,叫作“延迟计算”(Lazy Evaluation),也叫作懒加载。
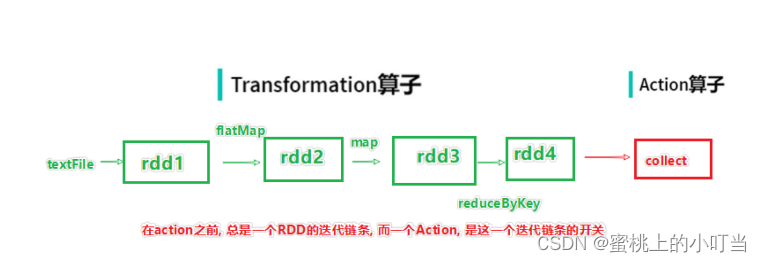
常见的Transformation算子
- map算子:将RDD的数据一条条处理(处理的逻辑基于map算子中的接收的处理函数),返回新的RDD。map可以自定义函数,也可以使用lambda匿名函数,部分代码如下:
rdd1 = sc.parallelize([1,2,3,4,5,6],3)
def func(a):
return 2 * a + 1
print(rdd1.map(func).collect())
rdd2 = sc.parallelize([1,2,3,4,5,6],3)
print(rdd2.map(lambda x :2*x +1).collect())
#结果输出
[3, 5, 7, 9, 11, 13]
[3, 5, 7, 9, 11, 13]
- flatMap算子:对RDD执行map操作后解除嵌套的操作,部分代码如下:
rdd1 = sc.parallelize(['a b c','d e f','g h i'],3)
rdd2 = rdd1.flatMap(lambda line: line.split(" "))
rdd_rs = rdd2.collect()
print(f'结果是:{rdd_rs}')
# 结果输出
结果是:['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i']
- reduceByKey算子:针对KV型RDD,自动按照Key分组,然后根据聚合逻辑,完成组内数据的聚合操作,部分代码如下:
rdd1 = sc.parallelize([('a',1),('a',2),('b',1),('b',3)],3)
rdd2 = rdd1.reduceByKey(lambda a,b : a+b)
rdd_rs = rdd2.collect()
print(f'结果是:{rdd_rs}')
# 结果输出
结果是:[('b', 4), ('a', 3)]
- mapValues算子:对KV型RDD中values进行map操作,部分代码如下:
rdd1 = sc.parallelize([('a',1),('a',2),('b',1),('b',3)],3)
rdd2 = rdd1.mapValues(lambda x: x * 10)
rdd_rs = rdd2.collect()
print(f'结果是:{rdd_rs}')
# 输出结果
结果是:[('a', 10), ('a', 20), ('b', 10), ('b', 30)]
- groupBy算子:将RDD的数据进行分组,部分代码如下
rdd1 = sc.parallelize([('a',1),('b',2),('a',3),('b',4)],3)
rdd2 = rdd1.groupBy(lambda x:x[0])
#需要list转换
#rdd3 = rdd2.map(lambda t:(t[0],list(t[1])))
rdd3 = rdd2.mapValues(lambda t : list(t))
rdd_rs = rdd3.collect()
print(f'结果是:{rdd_rs}')
rdd4 = sc.parallelize([1,2,3,4,5,6],3)
rdd5 = rdd4.groupBy(lambda x: 'odd' if (x%2==1) else 'even')
rdd_rs1 = rdd5.map(lambda x: (x[0],list(x[1]))).collect()
print(f'结果是:{rdd_rs1}')
# 结果是:[('b', [('b', 2), ('b', 4)]), ('a', [('a', 1), ('a', 3)])]
# 结果是:[('even', [2, 4, 6]), ('odd', [1, 3, 5])]
- filter算子:RDD过滤掉想要的数据进行保留,部分代码如下:
rdd1 = sc.parallelize([1,2,3,4,5,6],3)
#使用filter过滤出奇数
rdd2 = rdd1.filter(lambda x: x%2 == 1)
rdd_rs = rdd2.collect()
print(f'结果是:{rdd_rs}')
# 结果是:[1, 3, 5]
- distinct算子:对RDD数据进行去重,部分代码如下
rdd1 = sc.parallelize([1,1,2,2,3,3,3],3).distinct().collect()
rdd2 = sc.parallelize([('a',1), ('a',1), ('a',3)]).distinct().collect()
print(rdd1)
print(rdd2)
# [3, 1, 2]
# [('a', 1), ('a', 3)]
- union算子:将2个RDD合并成一个RDD并返回,部分代码如下
rdd1 = sc.parallelize([1,1,2,3,],3)
rdd2 = sc.parallelize(['a','a','b','c'],3)
rdd_union1 = rdd2.union(rdd1)
rdd_union1_rs = rdd_union1.collect()
print(f'结果是:{rdd_union1_rs}')
# 结果是:['a', 'a', 'b', 'c', 1, 1, 2, 3]
- join算子:对两个RDD执行join操作和SQL原理一样,部分代码如下:
rdd1 = sc.parallelize([('1001','Tom'),('1002','Jerry'),('1003','Spike'),('1004','Butch')])
rdd2 = sc.parallelize([('1001','技术部'),('1002','销售部'),('1005','行政部')])
# 内连接
rdd_join = rdd1.join(rdd2)
rdd_join_rs = rdd_join.collect()
print(f'结果是:{rdd_join_rs}')
# 左外连接
rdd_left = rdd1.leftOuterJoin(rdd2)
rdd_left_rs = rdd_left.collect()
print(f'结果是:{rdd_left_rs}')
# 右外连接
rdd_right1 = rdd1.rightOuterJoin(rdd2)
rdd_right2 = rdd2.leftOuterJoin(rdd1)
rdd_right1_rs = rdd_right1.collect()
rdd_right2_rs = rdd_right2.collect()
print(f'结果是:{rdd_right1_rs}')
print(f'结果是:{rdd_right2_rs}')
# 结果是:[('1001', ('Tom', '技术部')), ('1002', ('Jerry', '销售部'))]
# 结果是:[('1001', ('Tom', '技术部')), ('1004', ('Butch', None)), ('1002', ('Jerry', '销售部')), ('1003', ('Spike', None))]
# 结果是:[('1001', ('Tom', '技术部')), ('1005', (None, '行政部')), ('1002', ('Jerry', '销售部'))]
# 结果是:[('1001', ('技术部', 'Tom')), ('1005', ('行政部', None)), ('1002', ('销售部', 'Jerry'))]
- intersection算子:求两个RDD的交集,返回一个新的RDD,部分代码如下:
rdd1 = sc.parallelize([('a',1),('b',2),('c',3)])
rdd2 = sc.parallelize([('a',1),('d',4)])
rdd_intersect = rdd1.intersection(rdd2)
rdd_intersect_rs = rdd_intersect.collect()
print(f'结果是:{rdd_intersect_rs}')
# 结果是:[('a', 1)]
- glom算子:将RDD数据加上嵌套,嵌套是按照分区来进行,部分代码如下:
rdd1 = sc.parallelize([1,2,3,4,5,6,7],2).glom()
rdd_rs = rdd1.collect()
print(f'结果是:{rdd_rs}')
# 结果是:[[1, 2, 3], [4, 5, 6, 7]]
- groupByKey算子:对KV型RDD,自动按照Key分组,部分代码如下:
rdd1 = sc.parallelize([('a',1),('b',2),('a',3),('b',4)],3)
rdd2 = rdd1.groupByKey()
#rdd3 = rdd2.map(lambda t:(t[0],list(t[1])))
rdd3 = rdd2.mapValues(lambda t : list(t))
rdd_rs = rdd3.collect()
print(f'结果是:{rdd_rs}')
# 结果是:[('b', [2, 4]), ('a', [1, 3])]
- sortBy算子:对RDD数据进行排序,基于指定的排序为依据,部分代码如下:
rdd1 = sc.parallelize([('a',1),('b',2),('c',10),('d',6),('e',5)],3)
rdd2 = rdd1.sortBy(lambda x:x[1], ascending=True, numPartitions=3)
rdd3 = rdd1.sortBy(lambda x:x[1],ascending=False, numPartitions=3)
rdd_rs1 = rdd2.collect()
rdd_rs2 = rdd3.collect()
print(f'结果是:{rdd_rs1}')
print(f'结果是:{rdd_rs2}')
"""
# 参数1:告知Spark按照数据的哪个列进行排序
# 参数2:True表示升序、False表示降序
# 参数3:指定分区数
# 一般来说设置numPartitions值之后排序的最终结果只能保证在分区内是有序的,不能保证分区间是有序的。
# 将numPartitions设置为1,可以保证整体有序。
"""
# 结果是:[('a', 1), ('b', 2), ('e', 5), ('d', 6), ('c', 10)]
# 结果是:[('c', 10), ('d', 6), ('e', 5), ('b', 2), ('a', 1)]
- sortByKey算子:针对KV型RDD,按照Key进行排序,部分代码如下:
rdd1 = sc.parallelize([('a', 1), ('E', 1), ('C', 1), ('D', 1), ('b', 1), ('g', 1), ('f', 1),
('y', 1), ('u', 1), ('i', 1), ('o', 1), ('p', 1),
('m', 1), ('n', 1), ('j', 1), ('k', 1), ('l', 1)], 3)
rdd2 = rdd1.sortByKey(ascending=True, numPartitions=3, keyfunc=lambda key:str(key).lower())
rdd_rs = rdd2.collect()
print(f'结果是:{rdd_rs}')
# 只是改变排序过程中的大小写,但是对结果并未有任何影响
# 结果是:[('a', 1), ('b', 1), ('C', 1), ('D', 1), ('E', 1), ('f', 1), ('g', 1), ('i', 1), ('j', 1), ('k', 1), ('l', 1), ('m', 1), ('n', 1), ('o', 1), ('p', 1), ('u', 1), ('y', 1)]
![[附源码]Python计算机毕业设计GuiTar网站设计](https://img-blog.csdnimg.cn/04514b1dae9842f79d2730aaf5f9d354.png)



![[附源码]SSM计算机毕业设计班级风采网站JAVA](https://img-blog.csdnimg.cn/fb4d03f8cf8f41bb85cbca6aa71605b8.png)



![[MySQL]复杂查询(进阶)](https://img-blog.csdnimg.cn/30a79469ee0341b7820dca7d4ccead77.png)



