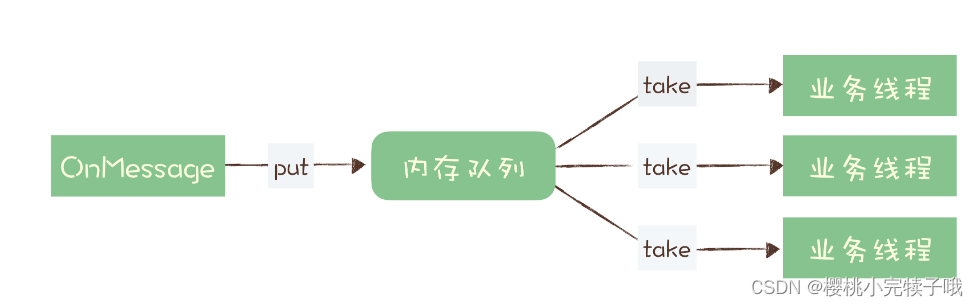
实现场景
要实现亿级数据的长期收集更新,并对采集后的数据进行整理和加工,用于人工智能的训练数据素材集。
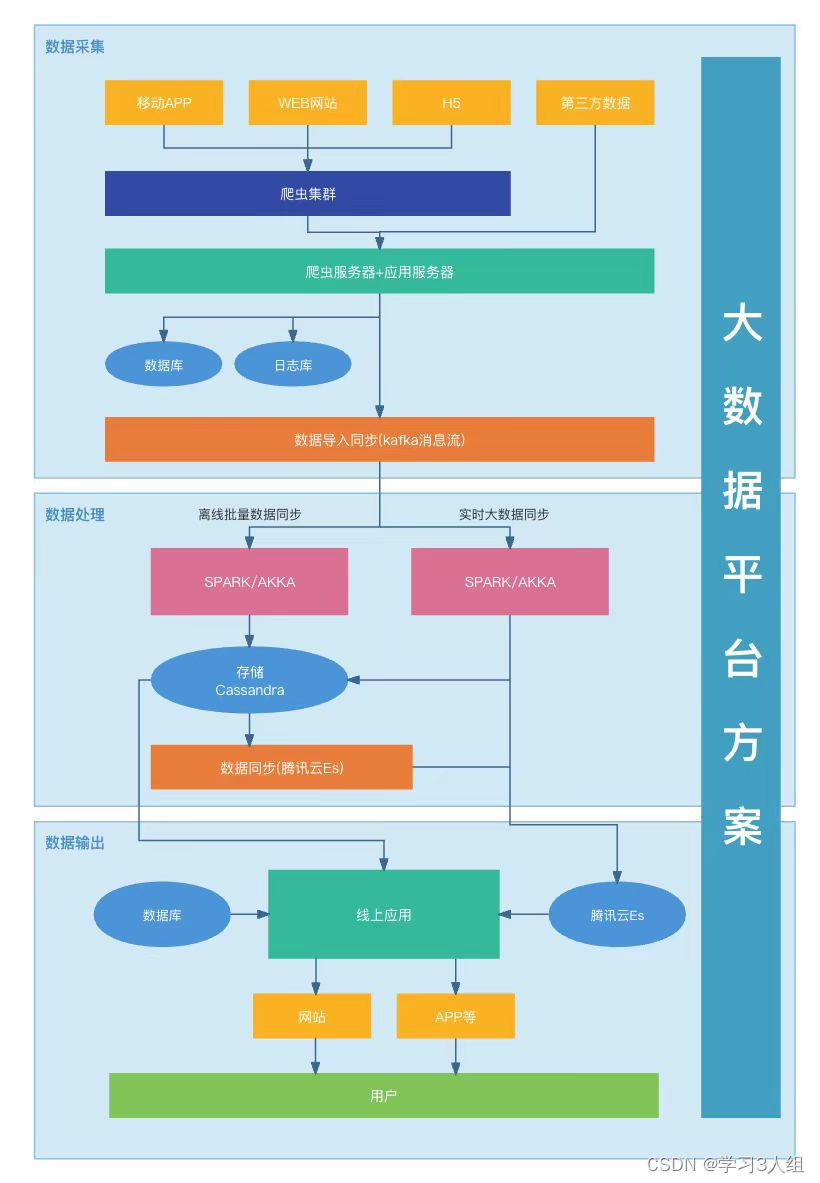
数据采集
java支持的爬虫框架还是有很多的,如:webMagic、Spider、Jsoup等添加链接描述
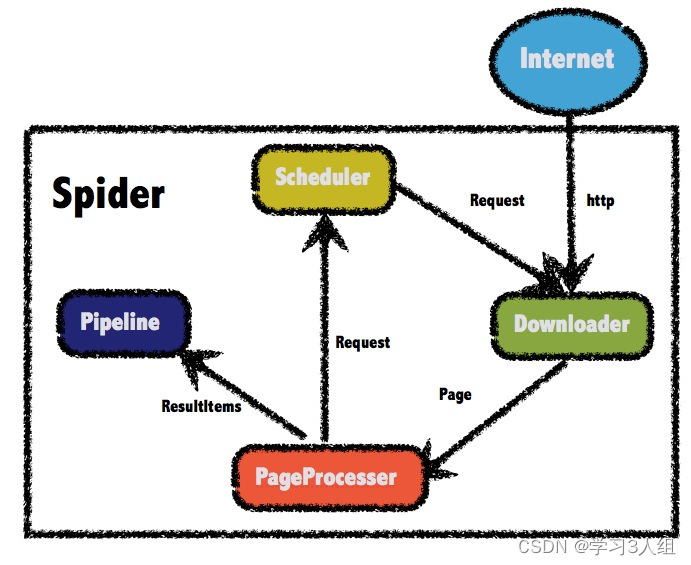
pipeline处理管道
数据并发开发与应用
AKKA
Akka 是一个构建在 JVM 上,基于 Actor 模型的的并发框架,为构建伸缩性强,有弹性的响应式并发应用提高更好的平台。
Actor 模型
Actor 的基础就是消息传递,一个 Actor 可以认为是一个基本的计算单元,它能接收消息并基于其执行运算,它也可以发送消息给其他 Actor。Actors 之间相互隔离,它们之间并不共享内存。
Actor 本身封装了状态和行为,在进行并发编程时,Actor 只需要关注消息和它本身。而消息是一个不可变对象,所以 Actor 不需要去关注锁和内存原子性等一系列多线程常见的问题。
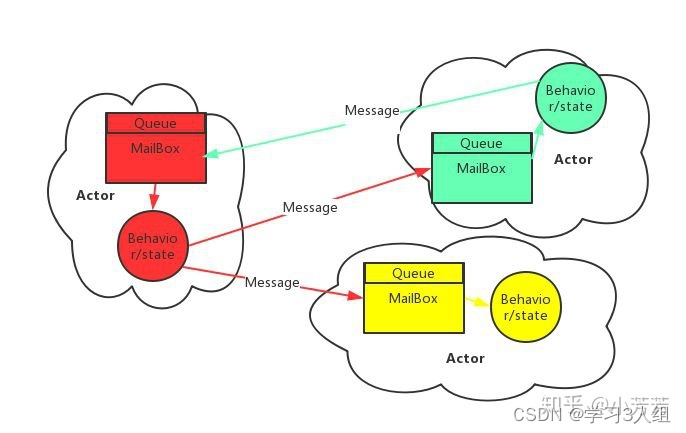
所以 Actor 是由状态(State)、行为(Behavior)和邮箱(MailBox,可以认为是一个消息队列)三部分组成:
状态:Actor 中的状态指 Actor 对象的变量信息,状态由 Actor 自己管理,避免了并发环境下的锁和内存原子性等问题。
行为:Actor 中的计算逻辑,通过 Actor 接收到的消息来改变 Actor 的状态。
邮箱:邮箱是 Actor 和 Actor 之间的通信桥梁,邮箱内部通过 FIFO(先入先出)消息队列来存储发送方 Actor 消息,接受方 Actor 从邮箱队列中获取消息。
2.1 模型概念
可以看出按消息的流向,可以将 Actor 分为发送方和接收方,一个 Actor 既可以是发送方也可以是接受方。
另外我们可以了解到 Actor 是串行处理消息的,另外 Actor 中消息不可变。
Actor 模型特点
对并发模型进行了更高的抽象。
使用了异步、非阻塞、高性能的事件驱动编程模型。
轻量级事件处理(1 GB 内存可容纳百万级别 Actor)。
简单了解了 Actor 模型,我们来看一个基于其实现的框架。
Scala 特性
面向对象特性
Scala是一种纯面向对象的语言,每个值都是对象。对象的数据类型以及行为由类和特质描述。
类抽象机制的扩展有两种途径:一种途径是子类继承,另一种途径是灵活的混入机制。这两种途径能避免多重继承的种种问题。
函数式编程
Scala也是一种函数式语言,其函数也能当成值来使用。Scala提供了轻量级的语法用以定义匿名函数,支持高阶函数,允许嵌套多层函数,并支持柯里化。Scala的case class及其内置的模式匹配相当于函数式编程语言中常用的代数类型。更进一步,程序员可以利用Scala的模式匹配,编写类似正则表达式的代码处理XML数据。
数据存储
Cassandra
[kəˈsændrə]【卡桑德拉】
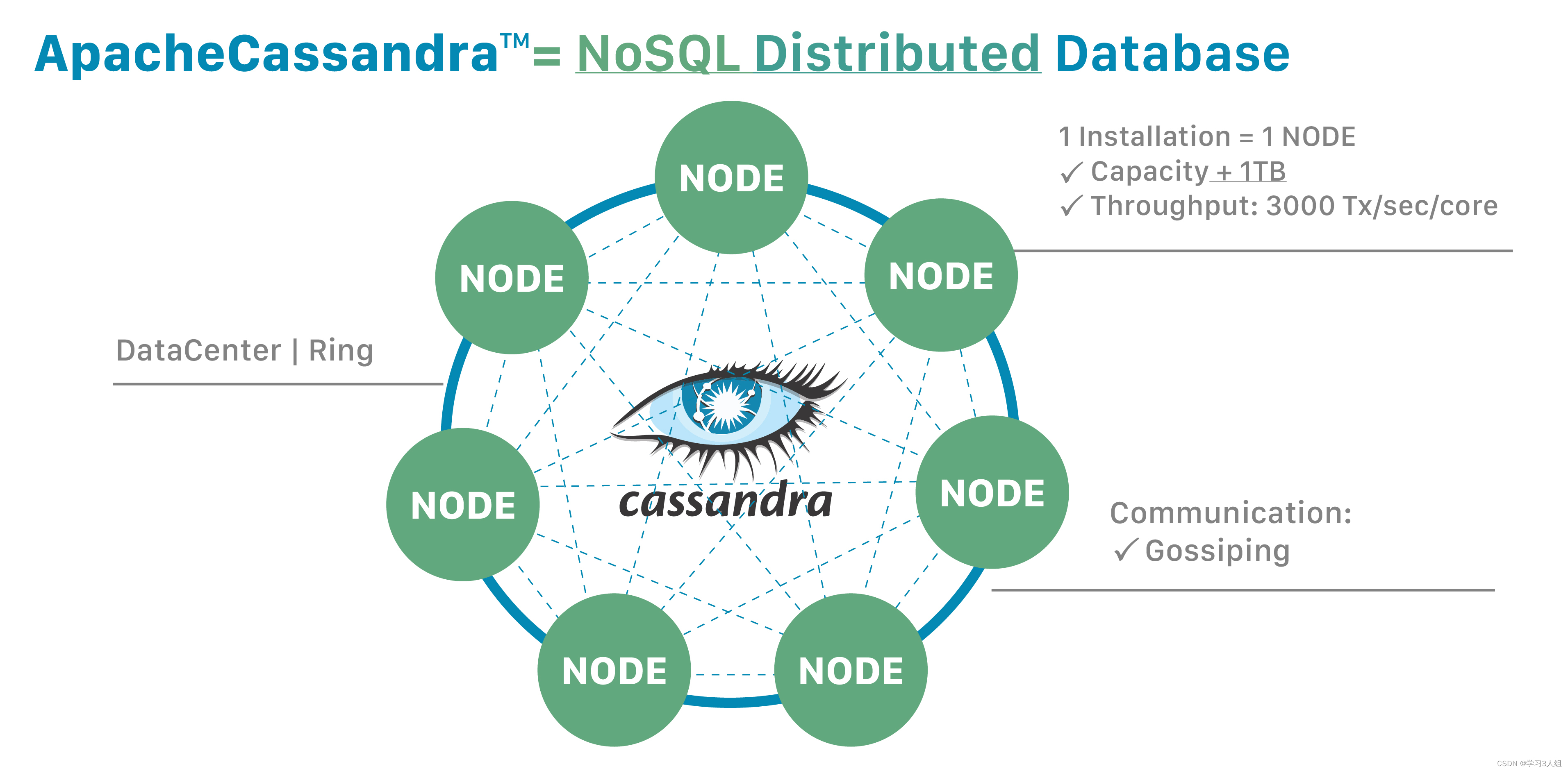
高度可扩展的分布式数据库,具有快速读取和写入能力,适用于需要快速查询大数据集的场景
 https://cassandra.apache.org/_/cassandra-basics.html
https://cassandra.apache.org/_/cassandra-basics.html
https://github.com/apache/cassandra
Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身。Facebook于2008将 Cassandra 开源,此后,由于Cassandra良好的可扩展性,被Digg、Twitter等知名Web 2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。
Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra 的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra集群来说,扩展性能是比较简单的事情,只管在群集里面添加节点就可以了。
这里有很多理由来选择Cassandra用于您的网站。和其他数据库比较,有三个突出特点:
模式灵活
使用Cassandra,像文档存储,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。这是一个惊人的效率提升,特别是在大型部署上。
可扩展性
Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以指向另一台电脑。你不必重启任何进程,改变应用查询,或手动迁移任何数据。添加链接描述

![[ATC复盘] abc329 20231118](https://img-blog.csdnimg.cn/f9e79c7560c940c199eb509e623e084b.png)


![【C++入门到精通】右值引用 | 完美转发 C++11 [ C++入门 ]](https://img-blog.csdnimg.cn/bb879b6a195246ec9f312e41c2be3af3.png)
![[黑马程序员SpringBoot2]——开发实用篇1](https://img-blog.csdnimg.cn/aea901f2eb224e418a9d11e4dab0b693.png)