一、CAS是什么?
Java 并发机制实现原子操作有两种: 一种是锁,还有一种是CAS。
在Java中,锁在并发处理中占据了一席之地,但是使用锁有一个不好的地方,就是当一个线程没有获取到锁时会被阻塞挂起,这会导致线程上下文的切换和重新调度开销。Java提供了非阻塞的volatile关键字来解决共享变量的可见性问题,这在一定程度上弥补了锁带来的开销问题,但是volatile只能保证共享变量的可见性,不能解决读一改一写等的原子性问题。CAS即CompareandSwap,其是JDK提供的非阻塞原子性操作,它通过硬件保证了比较一更新操作的原子性。
二、CAS示例
为什么需要CAS机制?我们先从一个错误现象谈起。
我们经常使用volatile关键字修饰某一个变量,表明这个变量是全局共享的一个变量,同时具有了可见性和有序性。但是却没有原子性。比如说一个常见的操作a++。这个操作其实可以细分成三个步骤:
(1)从内存中读取a
(2)对a进行加1操作
(3)将a的值重新写入内存中
在单线程状态下这个操作没有一点问题,但是在多线程中就会出现各种各样的问题了。因为可能一个线程对a进行了加1操作,还没来得及写入内存,其他的线程就读取了旧值。造成了线程的不安全现象。如何去解决这个问题呢?最常见的方式就是使用AtomicInteger来修饰a。
示例:
public class CasTest {
//使用AtomicInteger定义a
static AtomicInteger a = new AtomicInteger();
public static void main(String[] args) {
CasTest test = new CasTest();
Thread[] threads = new Thread[5];
for (int i = 0; i < 5; i++) {
threads[i] = new Thread(() -> {
try {
for (int j = 0; j < 10; j++) {
//使用getAndIncrement函数进行自增操作
System.out.println(a.incrementAndGet());
Thread.sleep(500);
}
} catch (Exception e) {
e.printStackTrace();
}
});
threads[i].start();
}
}
}
三、CAS机制
CAS全拼又叫做compareAndSwap,从名字上的意思就知道是比较交换的意思。
执行过程是这样(核心):
它包含 3 个参数 CAS(V,E,N),V内存值,A预期值,B要修改的值。仅当 V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程则什么都不做。最后,CAS 返回当前V的真实值。
CAS 操作时抱着乐观的态度进行的,它总是认为自己可以成功完成操作。所以CAS也叫作乐观锁,那什么是悲观锁呢?悲观锁就是我们“家喻户晓”的synchronized。悲观锁的思想你可以这样理解,一个线程想要去获得这个锁但是却获取不到,必须要别人释放了才可以。
现在我们使用AtomicInteger类并且调用了incrementAndGet方法来对a进行自增操作。这个incrementAndGet是如何实现的呢?我们可以看一下AtomicInteger的源码。

public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
var1:AtomicInteger这个对象a(当前对象)
var2:偏移量(有效地址)(偏移量)
var5:AtomicInteger这个对象a在地址var2上的期待值(期待值)
var5+var4:是值+1操作(更新值)
其实看到这一步就稍微有点眉目了,原来底层调用的是compareAndSwapInt方法,这个compareAndSwapInt方法其实就是CAS机制。因此如果我们想搞清楚AtomicInteger的原子操作是如何实现的,我们就必须要把CAS机制搞清楚,这也是为什么我们需要掌握CAS机制的原因。
四、CAS原理
想要弄清楚其底层原理,深入到源码是最好的方式,通过源码看到了其实就是Usafe的方法来完成的,在这个方法中使用了compareAndSwapInt这个CAS机制。
public final class Unsafe {
// compareAndSwapInt 是 native 类型的方法
public final native boolean compareAndSwapInt(
Object o,
long offset,
int expected,
int x
);
//剩余还有很多方法
}
我们可以看到这里面主要有四个参数,
第一个参数就是我们操作的对象a,
第二个参数是对象a的地址偏移量,有效地址
第三个参数表示我们期待这个a是什么值,
第四个参数表示的是a的实际值。
不过这里我们会发现这个compareAndSwapInt是一个native方法,也就是说再往下走就是C语言代码(好像有点点偏了),保持我们的好奇心,继续深入进去看看。
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe,
jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
// 根据偏移量valueOffset,计算 value 的地址
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
// 调用 Atomic 中的函数 cmpxchg来进行比较交换
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
上面的代码我们解读一下:首先使用jint计算了value的地址,然后根据这个地址,使用了Atomic的cmpxchg方法进行比较交换。现在问题又抛给了这个cmpxchg,真实实现的是这个函数。我们再进一步深入看看,坚持住!真相已经离我们不远了。
unsigned Atomic::cmpxchg(unsigned int exchange_value,
volatile unsigned int* dest,
unsigned int compare_value) {
assert(sizeof(unsigned int) == sizeof(jint), "more work to do");
/*
* 根据操作系统类型调用不同平台下的重载函数,
这个在预编译期间编译器会决定调用哪个平台下的重载函数
*/
return (unsigned int)Atomic::cmpxchg((jint)exchange_value,
(volatile jint*)dest, (jint)compare_value);
}
好家伙,皮球又一次被完美的踢走了,在不同的操作系统下会调用不同的cmpxchg重载函数,我现在用的是win10系统,所以我们看看这个平台下的实现,在坚持坚持,别着急再往下走走看:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest,
jint compare_value) {
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
看到这块的代码就有点涉及到汇编指令相关的代码了,到这一步就彻底接近真相了,首先三个move指令表示的是将后面的值移动到前面的寄存器上。然后调用了LOCK_IF_MP和下面cmpxchg汇编指令进行了比较交换。现在我们不知道这个LOCK_IF_MP和cmpxchg是如何交换的,没关系我们最后再深入一下。
inline jint Atomic::cmpxchg (jint exchange_value,
volatile jint* dest, jint compare_value) {
//1、 判断是否是多核 CPU
int mp = os::is_MP();
__asm {
//2、 将参数值放入寄存器中
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
//3、LOCK_IF_MP指令
cmp mp, 0
//4、 如果 mp = 0,表明线程运行在单核CPU环境下。此时 je 会跳转到 L0 标记处,直接执行 cmpxchg 指令
je L0
_emit 0xF0
//5、这里真正实现了比较交换
L0:
/*
* 比较并交换。简单解释一下下面这条指令,熟悉汇编的朋友可以略过下面的解释:
* cmpxchg: 即“比较并交换”指令
* dword: 全称是 double word 表示两个字,一共四个字节
* ptr: 全称是 pointer,与前面的 dword 连起来使用,表明访问的内存单元是一个双字单元
* 这一条指令的意思就是:
将 eax 寄存器中的值(compare_value)与 [edx] 双字内存单元中的值进行对比,
如果相同,则将 ecx 寄存器中的值(exchange_value)存入 [edx] 内存单元中。
*/
cmpxchg dword ptr [edx], ecx
}
}
到这一步了,相信应该理解了这个CAS真正实现的机制了吧,最终是由操作系统的汇编指令完成的。
五、unsafe类
JDK的rtjar包中的Unsafe类提供了硬件级别的原子性操作,Unsafe类中的方法都是native方法,它们使用JNI的方式访问本地C++实现库。下面我们来了解一下Unsafe提供的几个主要的方法以及编程时如何使用Unsafe类做一些事情。
- long objectFieldOffset(Field field)方法:返回指定的变量在所属类中的内存偏移地址,该偏移地址仅仅在该Unsafe函数中访问指定字段时使用。如下代码使用Unsafe类获取变量value在AtomicLong对象中的内存偏移。
- int arrayBaseOffset(Class arrayClass)方法:获取数组中第一个元素的地址。
- int arrayIndexScale(Class arrayClass)方法:获取数组中一个元素占用的字节。
- boolean compareAndSwapLong(Object obj, long offiset, long expect, long update)方法: 比较对象obj中偏移量为offset的变量的值是否与expect相等,相等则使用update值更新,然后返回true,否则返回false。
- public native long getLongvolatile(Object obj, long offset)方法:获取对象obj中偏移量为offset的变量对应volatile语义的值。
- void putLongvolatile(Object obj, long offset, long value) 方法:设置obj对象中offset偏移的类型为long的field 的值为value,支持volatile语义。
- void putOrderedLong(Object obj, long offset, long value)方法:设置obj对象中offset偏移地址对应的long型field的值为value。这是一个有延迟的putLongvolatile方法,并且不保证值修改对其他线程立刻可见。只有在变量使用volatile修饰并且预计会被意外修改时才使用该方法。
- long getAndSetLong(Object obj, long offset, long update)方法:获取对象obj中偏移量为offset的变量volatile语义的当前值,并设置变量volatile语义的值为update。
public class TestUnSafe {
//获取Unsafe的实例(2.2.1)
static final Unsafe unsafe = Unsafe.getUnsafe();
//记录变量state在类TestUnSafe中的偏移值(2.2.2)
static final long stateOffset;
//变量(2.2.3)
private volatile long state = 0;
static {
try {
//获取state变量在类TestUnSafe中的偏移值(2.2.4)
stateOffset = unsafe.objectFieldOffset(TestUnSafe.class.getDeclaredField("state"));
} catch (Exception ex) {
System.out.println(ex.getLocalizedMessage());
throw new Error(ex);
}
}
public static void main(String[] args) {
//创建实例,并且设置state值为1(2.2.5)
TestUnSafe test = new TestUnSafe();
// (2.2.6)
Boolean sucess = unsafe.compareAndSwapInt(test, stateOffset, 0, 1);
System.out.println(sucess);
}
}
在如上代码中,代码(2.2.1) 获取了Unsafe的一个实例,代码(2.2.3) 创建了一个变量state并初始化为0。
代码(2.2.4) 使用unsafe.objectFieldOffset获取TestUnSafe类里面的state 变量,在TestUnSafe对象里面的内存偏移量地址并将其保存到stateOffset变量中。
代码(2.2.6)调用创建的unsafe实例的compareAndSwapInt方法,设置test对象的state变量的值。具体意思是,如果test对象中内存偏移量为stateOffset的state变量的值为0,则更新该值为1。
运行上面的代码,我们期望输出true,然而执行后会输出如下结果


查看Unsafe源码可以看出:
代码(2.2.7) 获取调用getUnsafe这个方法的对象的Class对象,这里是TestUnSafe.class。
代码(2.2.8)判断是不是Bootstrap类加载器加载的localClass,在这里是看是不是Bootstrap 加载器加载了TestUnSafe.class。 很明显由于TestUnSafe.class 是使用AppClassLoader加载的,所以这里直接抛出了异常。
思考一下,这里为何要有这个判断?我们知道Unsafe类是rt.jar包提供的,rt.jar 包里面的类是使用Bootstrap类加载器加载的,而我们的启动main函数所在的类是使用AppClassLoader加载的,所以在main函数里面加载Unsafe类时,根据委托机制,会委托给Bootstrap去加载Unsafe类。
如果没有代码(2.2.8)的限制,那么我们的应用程序就可以随意使用Unsafe做事情了,而Unsafe类可以直接操作内存,这是不安全的,所以JDK开发组特意做了这个限制,不让开发人员在正规渠道使用Unsafe类,而是在rt.jar包里面的核心类中使用Unsafe功能。
当然我们可以通过反射来实现
public class TestUnSafe1 {
static final Unsafe unsafe;
static final long stateOffset;
private volatile long state = 0;
static {
try {
//使用反射获取Unsafe的成员变量theUnsafe
Field field = Unsafe.class.getDeclaredField("theUnsafe");
//设置为可存取
field.setAccessible(true);
//获取该变量的值
unsafe = (Unsafe) field.get(null);
//获取state在TestUnSafe中的汇编语言偏移量
stateOffset = unsafe.objectFieldOffset(TestUnSafe.class.getDeclaredField("state"));
} catch (Exception ex) {
System.out.println(ex.getLocalizedMessage());
throw new Error(ex);
}
}
public static void main(String[] args) {
//创建实例,并且设置state值为1(2.2.5)
TestUnSafe1 test = new TestUnSafe1();
// (2.2.6)
Boolean sucess = unsafe.compareAndSwapInt(test, stateOffset, 0, 1);
System.out.println(sucess+"------>"+unsafe.getIntVolatile(test, stateOffset));
Boolean sucess1 = unsafe.compareAndSwapInt(test, stateOffset, 1, 10);
System.out.println(sucess1+"------>"+unsafe.getIntVolatile(test, stateOffset));
Boolean sucess2 = unsafe.compareAndSwapInt(test, stateOffset, 9, 20);
System.out.println(sucess2+"------>"+unsafe.getIntVolatile(test, stateOffset));
}
}
六、CAS的优缺点
(1)优点
之前在文中我们提到过,CAS是一种乐观锁,而且是一种非阻塞的轻量级的乐观锁,什么是非阻塞式的?其实就是一个线程想要获得锁,对方会给一个回应表示这个锁能不能获得。在资源竞争不激烈的情况下性能高,相比synchronized重量锁,synchronized会进行比较复杂的加锁,解锁和唤醒操作。
(2)缺点
循环时间长开销大:cpu开销大,在高并发下,许多线程,更新一变量,多次更新不成功,循环反复,给cpu带来大量压力。
ABA问题
假设一个变量 A ,修改为 B之后又修改为 A,CAS 的机制是无法察觉的,但实际上已经被修改过了。这就是ABA问题,
ABA问题会带来大量的问题,比如说数据不一致的问题等等。可以举一个例子来解释说明。
假如你有一瓶水放在桌子上,别人把这瓶水喝完了,然后重新倒上去。你再去喝的时候发现水还是跟之前一样,就误以为是刚刚那杯水。如果你知道了真相,那是别人用过了你还会再用嘛?(除非是女朋友喝的 哈哈哈)
七、ABA问题
想到ABA问题,就联想到喝水的例子,以后出去还是要注意下。言归正传,直接看示例。
public class ABAAtomic {
private static AtomicInteger atomicInt = new AtomicInteger(100);
public static void main(String[] args) throws InterruptedException {
Thread intT1 = new Thread(new Runnable() {
@Override
public void run() {
atomicInt.compareAndSet(100, 101);
System.out.println("thread intT1:" + atomicInt.get());
atomicInt.compareAndSet(101, 100);
System.out.println("thread intT1:" + atomicInt.get());
}
});
Thread intT2 = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
boolean c3 = atomicInt.compareAndSet(100, 101);
System.out.println("thread intT2:" + atomicInt.get() + ",c3 is:" + c3); //true
}
});
intT1.start();
intT2.start();
}
}
线程intT2获取到的变量值A,尽管和当前的实际值相同,但内存地址V中的变量已经经历了A->B->A的改变。intT2线程是无法感知这个变化,也就是我们说的ABA问题。
ABA解决办法
public class ABAAtomic1 {
private static AtomicStampedReference<Integer> atomicStampedRef = new AtomicStampedReference<Integer>(100, 0);
public static void main(String[] args) {
Thread refT1 = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
atomicStampedRef.compareAndSet(100, 101, atomicStampedRef.getStamp(), atomicStampedRef.getStamp() + 1);
System.out.println("thread refT1:" + atomicStampedRef.getReference());
atomicStampedRef.compareAndSet(101, 100, atomicStampedRef.getStamp(), atomicStampedRef.getStamp() + 1);
System.out.println("thread refT1:" + atomicStampedRef.getReference());
}
});
Thread refT2 = new Thread(new Runnable() {
@Override
public void run() {
int stamp = atomicStampedRef.getStamp();
System.out.println("before sleep : stamp = " + stamp); // stamp = 0
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("after sleep : stamp = " + atomicStampedRef.getStamp());//stamp = 1
boolean c3 = atomicStampedRef.compareAndSet(100, 101, stamp, stamp + 1);
System.out.println("thread refT2:" + atomicStampedRef.getReference() + ",c3 is " + c3); //true
}
});
refT1.start();
refT2.start();
}
}
解决ABA问题是使用AtomicStampedReference它内部不仅维护了对象值,还维护了一个版本号(使用整数来表示状态值,并且是用volatile修饰,保证值的可见性)。当AtomicStampedReference对应的数值被修改时,除了更新数据本身外,还必须要更新版本号。当AtomicStampedReference设置对象值时,对象值以及版本号都必须满足期望值,写入才会成功。因此,即使对象值被反复读写,写回原值,只要版本号发生变化,就能防止不恰当的写入。
八、Java并发包中原子操作类原理剖析
JUC包提供了一系列的原子性操作类,这些类都是使用非阻塞算法CAS实现的,相比使用锁实现原子性操作这在性能上有很大提高。由于原子性操作类的原理都大致相同,所以本章只讲解最简单的AtomicLong类的实现原理以及JDK8中新增的LongAdder和LongAccumulator类的原理。有了这些基础,再去理解其他原子性操作类的实现就不会感到困难了。
8.1 原子变量操作类
JUC并发包中包含有AtomicInteger、AtomicLong 和AtomicBoolean等原子性操作类,它们的原理类似,我们讲解AtormicLong类。AtomicLong 是原子性递增或者递减类,其内部使用Unsafe来实现,不多说上代码。


代码(1)通过Unsafe.getUnsafe ()方法获取到Unsafe类的实例,这里你可能会有疑问,为何能通过Unsafe.getUnsafe()方法获取到Unsafe类的实例?其实这是因为AtomicLong类也是在rt.jar包下面的,AtomicLong 类就是通过BootStarp类加载器进行加载的。代码(5)中的value被声明为volatile的,这是为了在多线程下保证内存可见性,value是具体存放计数的变量。代码(2)(4)获取value变量在AtomicLong类中的偏移量。下面重点看下AtomicLong中的主要函数。


在如上代码内部都是通过调用Unsafe的getAndAddLong方法来实现操作,这个函数是个原子性操作,这里第一个参数是AtomicLong实例的引用,第二个参数是value变量在AtomicLong中的偏移值,第三个参数是要设置的第二个变量的值。
下面通过一个多线程使用AtomicLong统计0的个数的例子来加深对AtomicLong的理解。
public class Atomic {
//(10)创建Long型原子计数器
private static AtomicLong atomicLong = new AtomicLong();
// (11)创建数据源.
private static Integer[] arrayOne = new Integer[]{0, 1, 2, 3, 0, 5, 6, 0, 56, 0};
private static Integer[] arrayTwo = new Integer[]{10, 1, 2, 3, 0, 5, 6, 0, 56, 0};
public static void main(String[] args) throws InterruptedException {
// (12) 线程one统计 数组arrayOne中0的个数
Thread threadOne = new Thread(new Runnable() {
@Override
public void run() {
int size = arrayOne.length;
for (int i = 0; i < size; ++i) {
if (arrayOne[i].intValue() == 0) {
atomicLong.incrementAndGet();
}
}
}
});
// (13)线程two统计数组arrayTwo中0的个数
Thread threadTwo = new Thread(new Runnable() {
@Override
public void run() {
int size = arrayTwo.length;
for (int i = 0; i < size; ++i) {
if (arrayTwo[i].intValue() == 0) {
atomicLong.incrementAndGet();
}
}
}
});
//(14).启动子线程
threadOne.start();
threadTwo.start();
// (15)等待线程执行完毕
threadOne.join();
threadTwo.join();
System.out.println("count 0:" + atomicLong.get());
}
}

在没有原子类的情况下,实现计数器需要使用一定的同步措施,比如使用synchronized关键字等,但是这些都是阻塞算法,对性能有一定损耗,而本章介绍的这些原子操作类都使用CAS非阻塞算法,性能更好。但是在高并发情况下AtomicLong还会存在性能问题。
比如在高并发环境下进行累加操作,我们每做一次加法都会将变量的值同步回主存,由于竞争十分激烈,发生冲突的情况会大大增加(也就是存在大量更新时去比较预期的值发生了变化,导致此次更新失效的情况),因此效率会大大降低。
JDK8提供了一个在高并发下性能更好的LongAdder类。
8.2 JDK新增的原子操作LongAdder
前面讲过,AtomicLong 通过CAS提供了非阻塞的原子性操作,相比使用阻塞算法的同步器来说它的性能已经很好了,但是JDK开发组并不满足于此。使用AtomicLong时, 在高并发下大量线程会同时去竞争更新同一个原子变量,但是由于同时只有一个线程的CAS操作会成功,这就造成了大量线程竞争失败后,会通过无限循环不断进行自旋尝试CAS的操作,而这会白白浪费CPU资源。
因此JDK8新增了一个原子性递增或者递减类LongAdder用来克服在高并发下使用AtomicLong的缺点。既然AtomicLong的性能瓶颈是由于过多线程同时去竞争一个变量的更新而产生的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源,是不是就解决了性能问题?是的,LongAdder 就是这个思路。下 面通过图来理解两者设计的不同之处,如图所示。

使用AtomicLong时是多个线程同时竞争同一个原子变量。

如图所示,使用LongAdder时,则是在内部维护多个Cell变量,每个Cell里面有一个初始值为0的long型变量,这样,在同等并发量的情况下,争夺单个变量更新操作的线程量会减少,这变相地减少了争夺共享资源的并发量。另外,多个线程在争夺同一个Cell原子变量时如果失败了,它并不是在当前Cell变量上一直自旋CAS重试,而是尝试在其他Cell的变量上进行CAS尝试,这个改变增加了当前线程重试CAS成功的可能性。最后,在获取LongAdder当前值时,是把所有Cell变量的value值累加后再加上base返回的。
LongAdder维护了一个延迟初始化的原子性更新数组(默认情况下Cell数组是null)和一个基值变量base。由于Cell占用的内存是相对比较大的,所以一开始并不创建它,而是在需要时创建,也就是惰性加载。当一开始判断Cell数组是null并且并发线程较少时,所有的累加操作都是对base变量进行的。
对于大多数孤立的多个原子操作进行字节填充是浪费的,因为原子性操作都是无规律地分散在内存中的(也就是说多个原子性变量的内存地址是不连续的),多个原子变量被放入同一个缓存行的可能性很小。但是原子性数组元素的内存地址是连续的,所以数组内的多个元素能经常共享缓存行,因此这里使用@sun.misc.Contended注解对Cell类进行字节填充,这防止了数组中多个元素共享一个缓存行,在性能上是一个提升。
用法和AtomicLong类似,把之前的例子修改下如下:
public class Atomic1 {
//(10)创建Long型原子计数器
private static LongAdder la = new LongAdder();
// (11)创建数据源.
private static Integer[] arrayOne = new Integer[]{0, 1, 2, 3, 0, 5, 6, 0, 56, 0};
private static Integer[] arrayTwo = new Integer[]{10, 1, 2, 3, 0, 5, 6, 0, 56, 0};
public static void main(String[] args) throws InterruptedException {
// (12) 线程one统计 数组arrayOne中0的个数
Thread threadOne = new Thread(new Runnable() {
@Override
public void run() {
int size = arrayOne.length;
for (int i = 0; i < size; ++i) {
if (arrayOne[i].intValue() == 0) {
la.increment();
}
}
}
});
// (13)线程two统计数组arrayTwo中0的个数
Thread threadTwo = new Thread(new Runnable() {
@Override
public void run() {
int size = arrayTwo.length;
for (int i = 0; i < size; ++i) {
if (arrayTwo[i].intValue() == 0) {
la.increment();
}
}
}
});
//(14).启动子线程
threadOne.start();
threadTwo.start();
// (15)等待线程执行完毕
threadOne.join();
threadTwo.join();
System.out.println("count 0:" + la.longValue());
}
}
8.3 LongAdder源码分析
LongAdder类结构


由该图可知,LongAdder 类继承自Striped64 类,在Striped64内部维护着三个变量。
LongAdder的真实值其实是base的值与Cell数组里面所有Cell元素中的value值的累加,base是个基础值,默认为0。cellsBusy 用来实现自旋锁,状态值只有0和1,当创建Cell元素,扩容Cell数组或者初始化Cell数组时,使用CAS操作该变量来保证同时只有一个线程可以进行其中之一的操作。
Cell的结构:
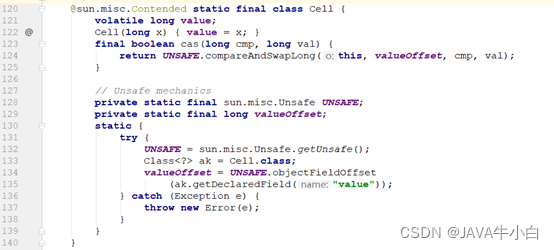
可以看到,Cell 的构造很简单,其内部维护一个被声明为volatile的变量,这里声明为volatile是因为线程操作value变量时没有使用锁,为了保证变量的内存可见性这里将其声明为volatile的。另外cas函数通过CAS操作,保证了当前线程更新时被分配的Cell元素中value值的原子性。另外,Cell 类使用@sun.misc.Contended修饰是为了避免伪共享。
longsum()返回当前的值,内部操作是累加所有Cell内部的value值后再累加base。例如下面的代码,由于计算总和时没有对Cell数组进行加锁,所以在累加过程中可能有其他线程对Cell中的值进行了修改,也有可能对数组进行了扩容,所以sum返回的值并不是非常精确的,其返回值并不是一个调用sum方法时的原子快照值。

longValue的值和sum一样

add方法实现

![【C++入门到精通】右值引用 | 完美转发 C++11 [ C++入门 ]](https://img-blog.csdnimg.cn/bb879b6a195246ec9f312e41c2be3af3.png)
![[黑马程序员SpringBoot2]——开发实用篇1](https://img-blog.csdnimg.cn/aea901f2eb224e418a9d11e4dab0b693.png)