问题出现:
当我训练图网络模型时,源码默认使用cpu,查看后台性能运行,发现正在使用cpu训练,这大大降低了训练速率,并且增加了电脑负载。所以我决定将模型改造并训练放在GPU上运行。
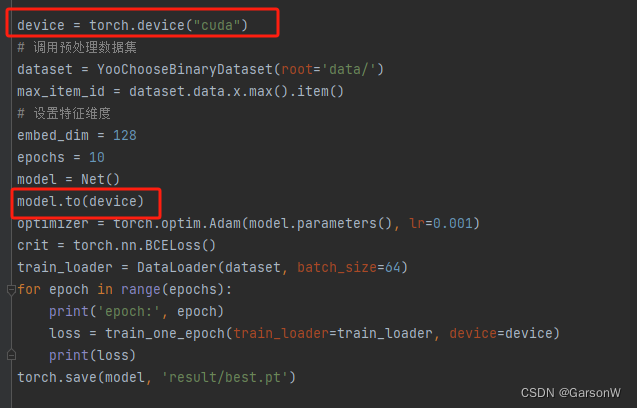
我在train方法中,将原有的data使用to(device)放在了GPU中:
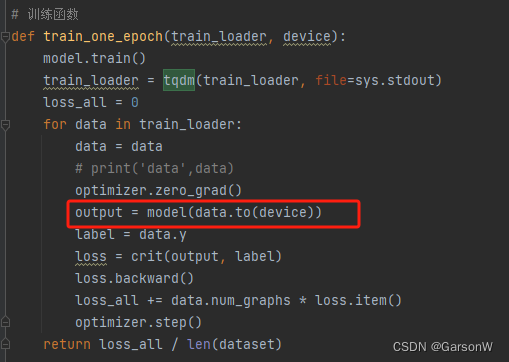
再运行便报错:
RuntimeError: Input, output and indices must be on the current device
报错翻译:输入输出模型必须存在同一设备中
问题解决:
问题解决这个问题是源于没有将自定义的model模型也放在GPU中,所以需要在方法外先把model也设置为GPU