文章目录
- Abstract
- 1. Introduction
- 2. Method
- 2.1. A Brief Review of PP-YOLOv2
- 2.2. Improvement of PP-YOLOE
- Anchor-free
- Backbone and Neck
- Task Alignment Learning (TAL)
- Efficient Task-aligned Head (ET-head)
- 3.Experiment
- 4. Conclusion
原文链接
源代码
Abstract
在本报告中,我们介绍了PP-YOLOE,一种具有高性能和友好部署的工业最先进的目标探测器。我们在之前的PP-YOLOv2的基础上进行优化,采用无锚模式,使用强大的骨干和颈部,引入CSPRepResStage, ET-head和动态标签分配算法TAL
我们为不同的实践场景提供s/m/l/x模型,PP- YOLOE - l在COCO测试开发上实现了51.4 mAP,在Tesla V100上实现了78.1 FPS,与之前最先进的工业车型PP-YOLOv2和YOLOX相比,分别实现了(+1.9 AP, +13.35%提速)和(+1.3 AP, +24.96%提速)的显著提升。在TensorRT和fp16精度下,PP-YOLOE推理速度达到149.2 FPS。我们还进行了大量的实验来验证我们设计的有效性
1. Introduction
自YOLOv1[21]以来,YOLO系列目标探测器在网络结构、标签分配等方面发生了巨大的变化
YOLOX引入了先进的无锚方法,配备了动态标签分配,提高了探测器的性能,在精度方面明显优于YOLOv5[14]
受YOLOX的启发,我们进一步优化了之前的工作PP-YOLOv2[13],我们提出了YOLO的进化版本,命名为PP-YOLOE
PP-YOLOE避免使用可变形卷积[3,35]和矩阵NMS[29]等算子,以便在各种硬件上得到很好的支持。此外,PP- YOLOE可以轻松扩展到具有不同计算能力的各种硬件的一系列模型。这些特点进一步推动了PP-YOLOE在更广泛的实际场景中的应用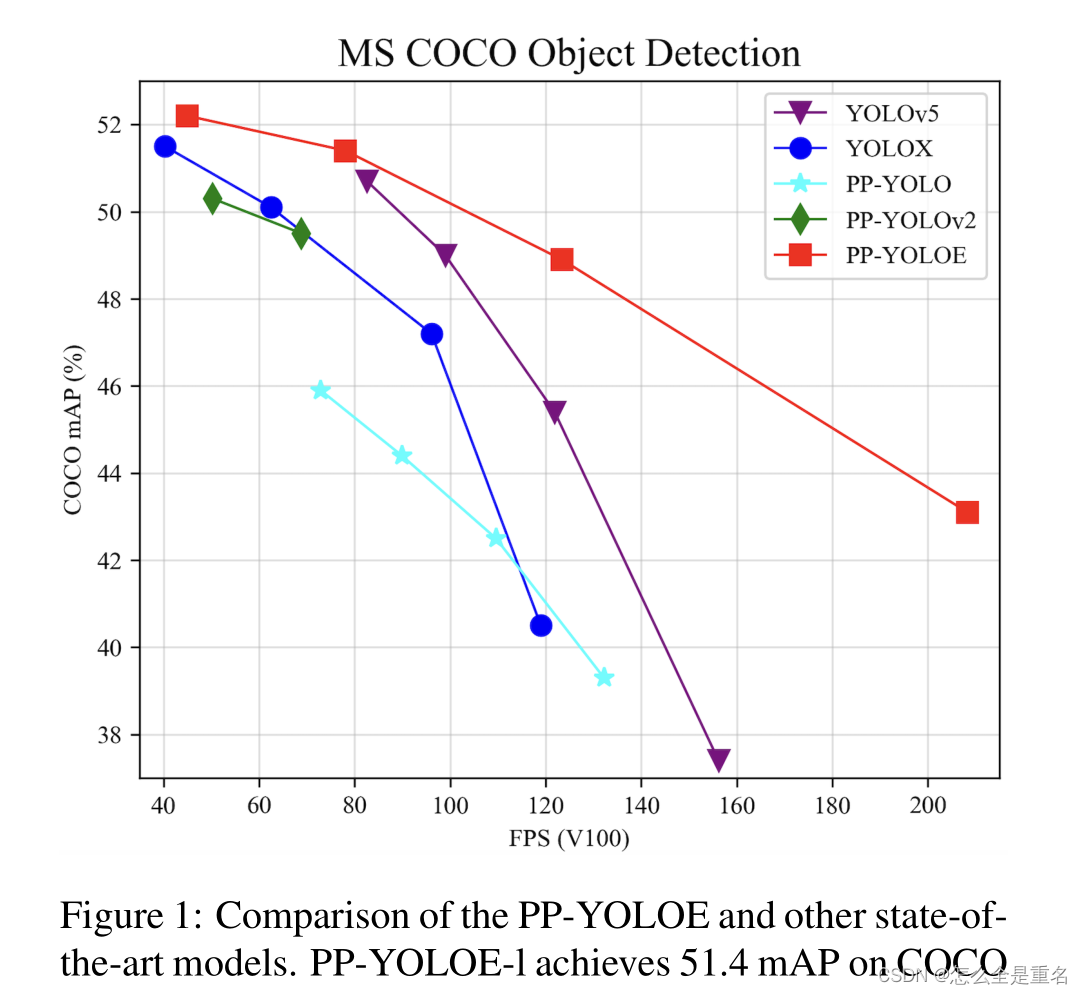
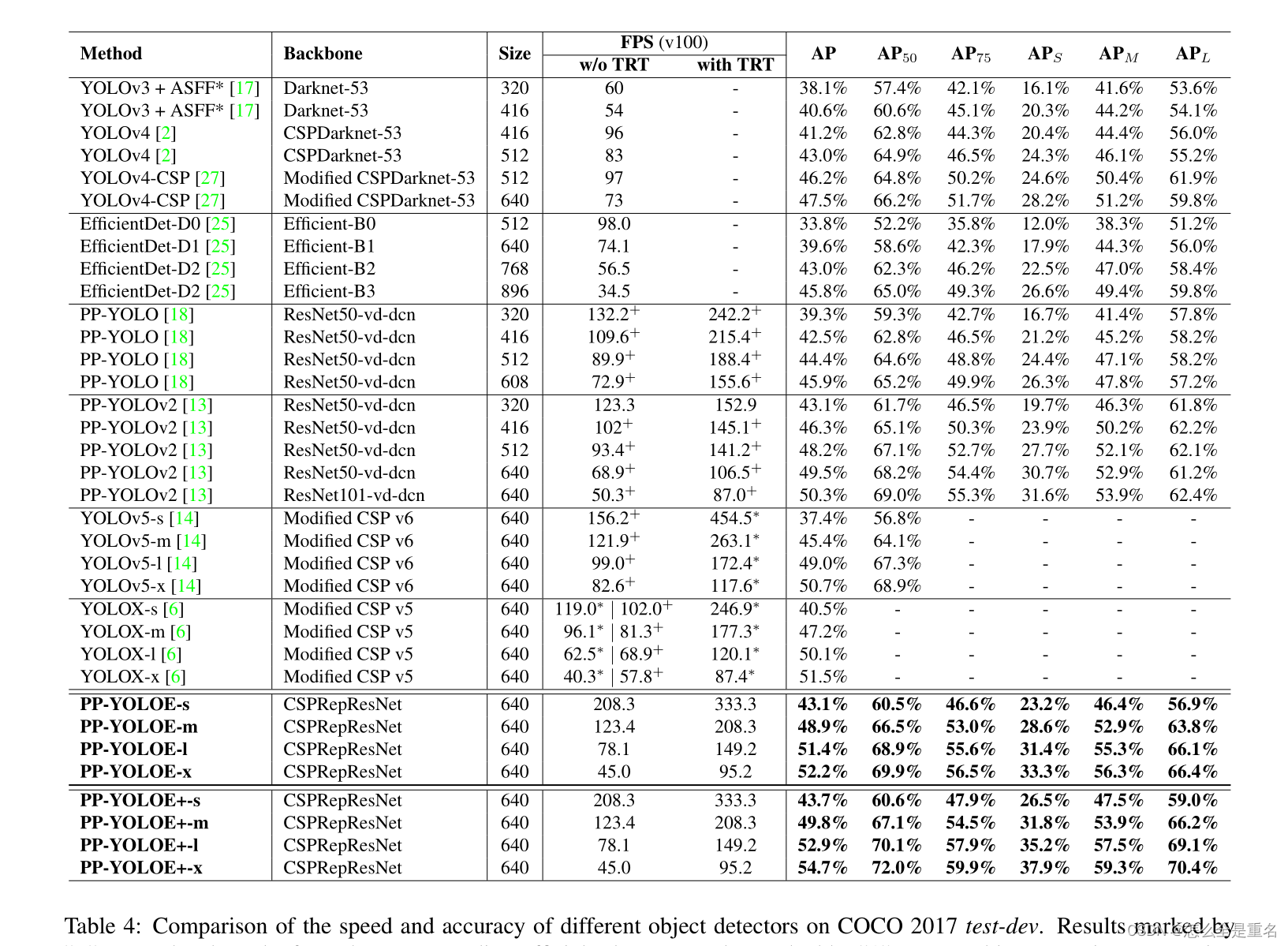
如图1所示,PP-YOLOE在速度和精度权衡方面优于YOLOv5和YOLOX。具体来说,PP-YOLOE- 1以78.1 FPS的速度在COCO上实现了640 × 640分辨率的51.4 mAP,超越了PP-YOLOv2 1.9%的AP和yolox - 1 1.3%的AP。此外,PP-YOLOE有一系列的模型,可以像YOLOv5一样通过宽度倍增器和深度倍增器进行简单的配置
2. Method
我们将首先回顾我们的基线模型(YOLOv2),然后从网络结构、标签分配策略、头部结构和损失函数等方面详细介绍PP-YOLOE的设计(图2)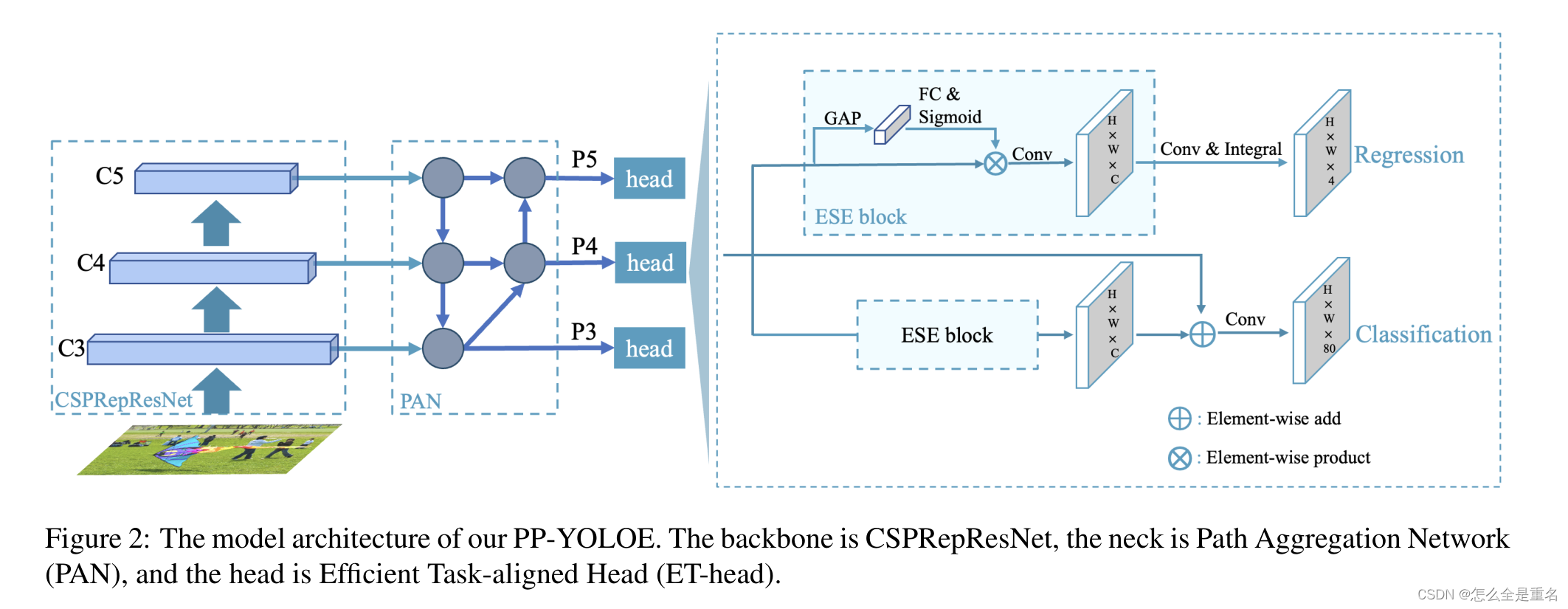
2.1. A Brief Review of PP-YOLOv2
PP-YOLOv2的整体架构包括具有可变形卷积的ResNet50-vd[10]、具有SPP层和DropBlock[7]的PAN颈和轻量级IoU感知头。在PP- YOLOv2中,主干部位采用ReLU激活函数,颈部部位采用Mish激活函数。继YOLOv3之后,PP-YOLOv2只为每个地面真值对象分配一个锚框。除了分类损失、回归损失和对象损失外,PP-YOLOv2还使用IoU损失和IoU感知损失来提高性能
2.2. Improvement of PP-YOLOE
Anchor-free
我们在PP-YOLOv2中引入无锚法。FCOS[26]在每个像素上平铺一个锚点,我们设置了三个检测头的上界和下界,将ground truth分配给相应的feature map。然后,计算边界框的中心,选择最接近的像素作为正样本
根据YOLO序列,预测一个四维向量(x, y, w, h)进行回归。这个修改使模型更快了一点,损失了0.3 AP,如表2所示。虽然根据PP- YOLOv2的锚点尺寸仔细设置了上界和下界,但基于锚点和无锚点的分配结果仍然存在一些小的不一致,这可能导致精度下降很小
Backbone and Neck
残差连接[9,30,11]和密集连接[12,15,20]在现代卷积神经网络中得到了广泛的应用。残差连接引入了解决梯度消失问题的捷径,也可以看作是一种模型集成方法。密集连接集合了具有不同接收域的中间特征,在目标检测任务中表现出良好的性能。CSPNet[28]利用了跨级密集连接,在不损失精度的情况下降低了计算量,在YOLOv5[14]、YOLOX等有效的目标检测器中得到了广泛应用
我们提出了一种新颖的RepResBlock,将残差连接与密集连接相结合,用于我们的backbone和颈部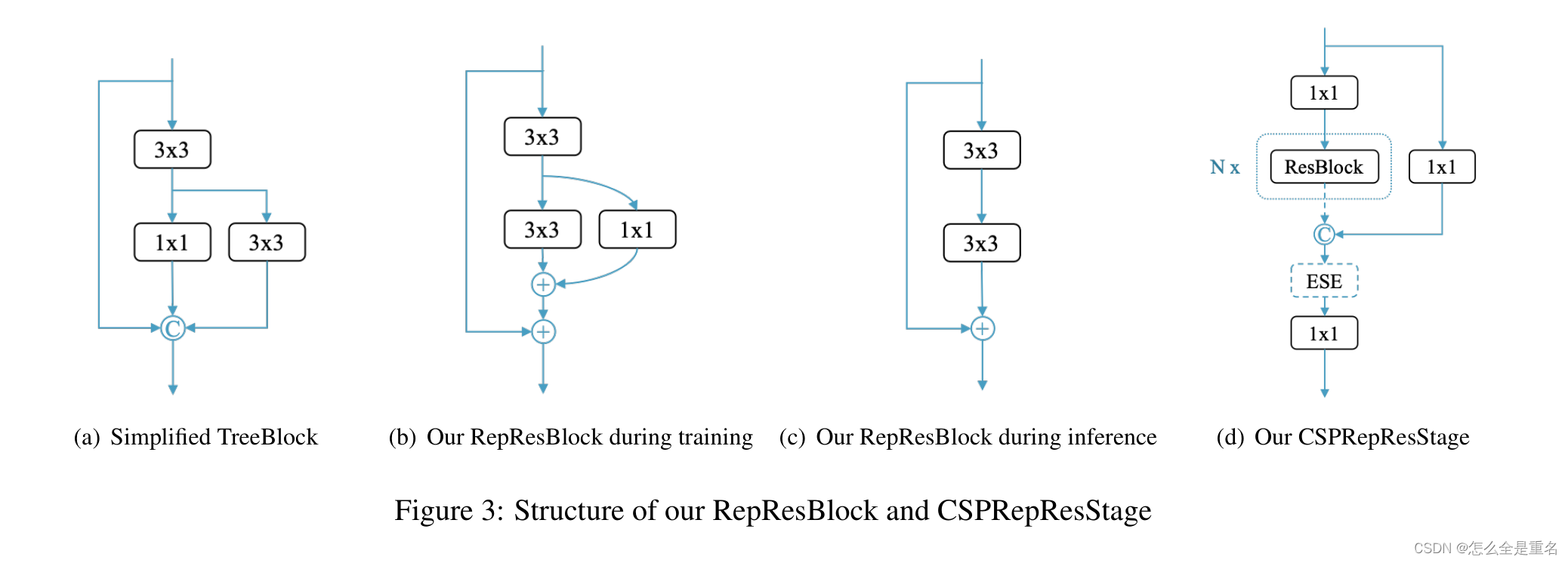
我们的RepResBlock源自TreeBlock[20],在训练阶段如图3(b)所示,在推理阶段如图3©所示。首先,我们对原始TreeBlock进行简化(图3(a))。然后,我们用元素相加操作替换连接操作(图3(b)),因为RMNet[19]在某种程度上显示了这两种操作的近似。因此,在推理阶段,我们可以将RepResBlock重新参数化为ResNet-34以RepVGG[4]风格使用的基本剩余块(图3©)
我们使用所提出的RepResBlock来构建backbone 和 neck。与ResNet类似,我们的主干名为CSPRepResNet,包含一个由三个卷积层组成的主干,以及由我们的RepResBlock堆叠的四个后续阶段,如图3(d)所示。在每一步中,采用跨阶段部分连接,避免了大量3 × 3卷积层带来的大量参数和计算负担。ESE(有效挤压和提取)层也用于在构建主干时在每个CSPRepResStage中施加信道注意。我们在PP-YOLOv2[13]之后使用所提出的RepResBlock和CSPRepResStage构建颈部。与主干不同的是,主干去掉了RepResBlock中的快捷键和CSPRepResStage中的ESE层
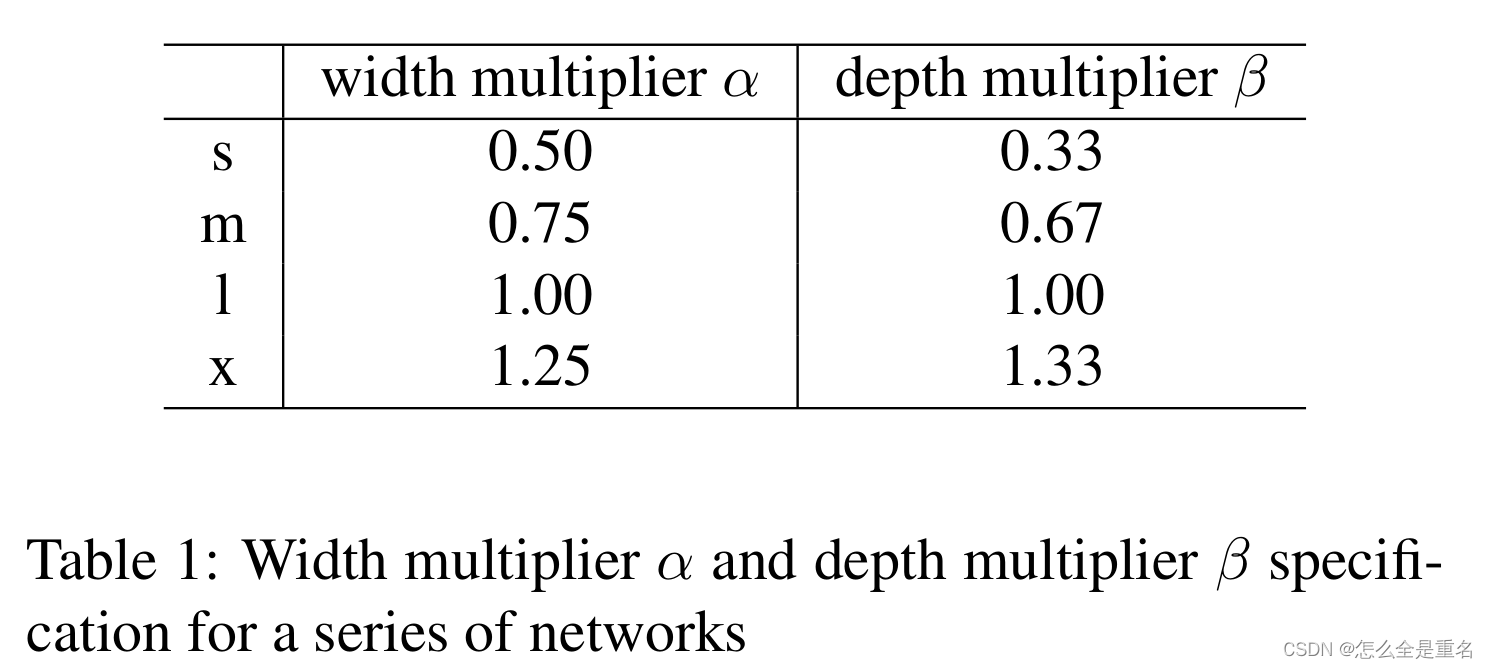
我们使用宽度乘法器α和深度乘法器β来像YOLOv5[14]一样对基本骨干和颈部进行联合缩放。因此,我们可以得到一系列具有不同参数和计算量的检测网络。基本骨干宽度设置为[64,128,256,512,1024]。除主干外,基本主干的深度设置为[3,6,6,3]。基本颈宽设置为[192,384,768],深度设置为3。表1给出了不同模型的宽度乘法器α和深度乘法器β的规格。这样的修改使AP性能提高了0.7%,即49.5%
Task Alignment Learning (TAL)
为了进一步提高精度,标签分配是另一个需要考虑的方面。YOLOX使用SimOTA作为标签分配策略来提高性能。然而,为了进一步克服分类和定位的不对齐问题,在TOOD[5]中提出了任务对齐学习(TAL),它由动态标签分配和任务对齐损失组成。动态标签分配意味着预测/损失意识。根据预测,为每个真值分配动态的正锚点个数。通过显式地对齐这两个任务,TAL可以同时获得最高的分类分数和最精确的边界框
对于与任务对齐的损失,Tood使用一个归一化的t,即hat t来代替损失中的目标。它采用每个实例中最大的IoU作为归一化。分类的二进制交叉熵(Binary Cross Entropy, BCE)可以重写为: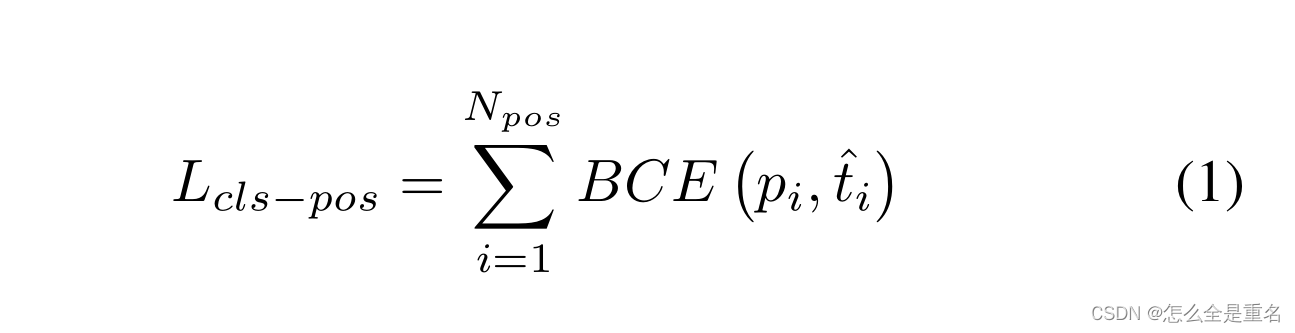
本文以CSPRepResNet为骨干,在上述改进的模型上进行了实验。为了快速得到验证结果,我们只在COCO train2017上训练了36个epoch,并在COCO val上进行验证,如表3所示,TAL达到了最佳的45.2% AP性能。我们使用TAL替代标签分配,如FCOS样式,并实现0.9% AP改进- 50.4% AP
Efficient Task-aligned Head (ET-head)
在目标检测中,分类与定位之间的任务冲突是一个众所周知的问题。许多文献[5,33,16,31]都提出了相应的解决方案。YOLOX的解耦头部吸取了大多数一级和两级检测器的经验,并成功应用于YOLO模型,提高了精度。但是,解耦的头部可能会使分类和定位任务分离和独立,缺乏针对任务的学习
基于TOOD [5],我们改进了head,提出了速度和精度并重的ET-head。如图2所示,我们使用ESE替换了tood中的层关注,将分类分支的对齐简化为shortcut,将回归分支的对齐替换为分布焦损(DFL)层[16]。通过上述变化,ET-head在V100上增加了0.9ms
对于分类和定位任务的学习,我们分别选择了变焦损失(VFL)和分布焦损失(DFL)。PP-Picodet[32]成功地将VFL和DFL应用于目标检测器中,并获得了性能的提高。[33]中的VFL,与[16]中的质量焦损(QFL)不同,VFL使用目标分数来加权阳性样本的损失。这种实现使得高IoU的阳性样本对损失的贡献相对较大。这也使得模型在训练时更加关注高质量的样本,而不是那些低质量的样本
相同的是,两者都使用IACS作为预测的目标。这可以有效地学习分类分数和定位质量估计的联合表示,使训练和推理之间具有较高的一致性。对于DFL,为了解决边界框表示不灵活的问题,[16]提出使用一般分布来预测边界框。我们的模型损失函数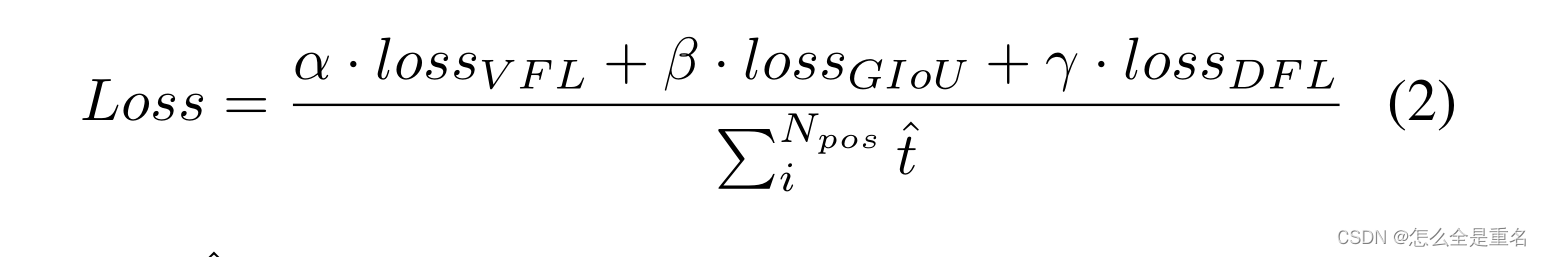
式中,t hat为归一化目标分数
ET-head获得0.5% AP改善


3.Experiment
4. Conclusion
在本报告中,我们提出了PP- YOLOv2的几个更新,包括可扩展的主干颈结构,高效的任务对齐头,先进的标签分配策略和改进的目标损失函数,形成了一系列高性能的目标检测器PP- YOLOE。同时,我们提出了s/m/l/x模型,可以覆盖不同的实际场景。此外,在PaddlePaddle官方支持下,这些模型可以顺利过渡到部署