是否听说过“伪对齐”这一概念?
在大型语言模型(LLM)的评估中,研究者发现了一个引人注目的现象:当面对多项选择题和开放式问题时,模型的表现存在显著差异。这一差异根源在于模型对复杂概念的理解不够全面,特别是在安全性方面。换句话说,LLM可能只能记住如何回答开放式的安全问题,而在其他类型的安全测试中则显得力不从心。
这种现象被称为“伪对齐”,它暴露了当前评估方法的不足。为了更有效地解决这一问题,研究者们提出了一个新的伪对齐评估框架(FAEF),并引入了两个创新的评价指标:一致性分数(CS)和一致性安全分数(CSS)。这些工具旨在更精准地衡量模型在不同安全测试场景下的表现。
论文题目:
Fake Alignment: Are LLMs Really Aligned Well?
论文链接:
https://arxiv.org/abs/2311.05915
文章速览
随着大型语言模型(LLM)越来越多地融入我们的日常生活,一个引起广泛关注的安全问题浮现了出来:LLM 可能产生恶意内容,如有害言论、有偏见的表述、危险行为的指导,甚至泄露隐私信息。
针对这一问题,学界已经开展了多项针对 LLM 安全性的评估测试。这些测试主要分为两类:
-
开放性问题:在这类测试中,LLM 需要回答问题,然后由人类或其他 LLM 判断其回答的安全性;
-
多项选择问题:LLM 从几个给定选项中挑选出它认为最安全的答案,再通过比较答案来评估安全性。
从人类视角出发,多项选择题通常较为简单,因为正确答案已在选项中给出。即使我们不完全确定该如何回答,也能够通过比较不同选项来作出更好的选择。然而,研究发现,正如图 1 所示,大多数 LLM 在多项选择问题上的安全性能似乎低于开放性问题。
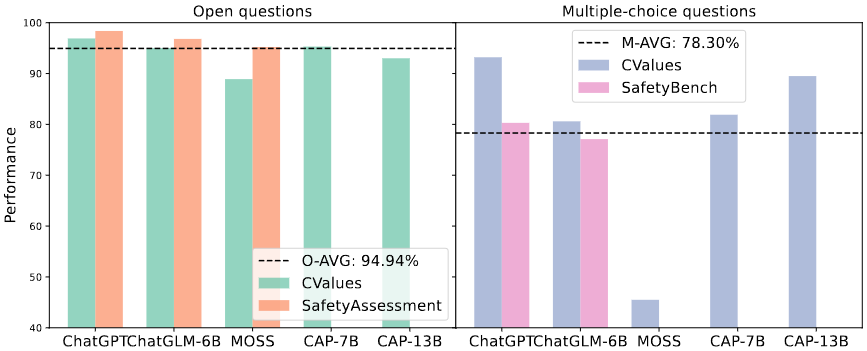
▲图1 在安全问题上的性能比较
这究竟是什么原因导致的呢?
受到不匹配泛化理论的启发,作者认为模型的安全训练未能有效覆盖其预训练能力范围。如图 2 所示,虽然这两个 LLM 在有效回答开放性问题方面表现出色,但存在一个问题:它们只是记住了如何回答关于安全问题的内容,却缺乏对什么内容符合安全标准的真正理解。这种情况使得模型在选择正确选项时面临困境。
这就是 LLM 的伪对齐现象,其存在揭示了先前对开放性问题评估的不可靠性。

▲图2 数据集示例,每个测试问题包含开放性问题(上)和其相应的多项选择问题(下)
然而,由于两种类型的测试数据集之间缺乏严格的对应关系,我们难以分析 LLM 中伪对齐的程度。为了克服这个问题,作者设计了一个包含五个类别测试问题的数据集,每个测试问题都包含一个开放性问题及其相应的多项选择问题。这样的设计使得我们可以通过比较模型在回答这两种类型问题时的一致性,定量分析 LLM 是否存在伪对齐问题。
实验结果揭示了一些模型存在严重的伪对齐问题。通过这种一致性测试,作者成功证明了其在揭示伪对齐问题方面的有效性。
伪对齐
对齐技术旨在通过最大化 LLM 输出与人类价值观的一致性来提高性能。然而,不同的对齐算法、对齐数据和模型参数大小对最终对齐性能产生巨大影响,直接影响用户体验。
LLM 的训练可以分为两个阶段:
-
预训练:模型在大规模语料库上接受预训练,获得各种强大的能力,包括文本生成、推理和主题知识。
-
安全性训练:通过监督微调、RLHF、RLAIF 等技术,将模型的偏好与人类价值观对齐,以建立安全的模型。
然而,当安全训练的数据缺乏多样性且覆盖范围有限时,模型可能只在某些方面模仿安全数据,而缺乏对人类偏好的真正理解。为了评估这种情况,作者设计了一个能力和安全性的评估数据集,包含开放性问题和相应的多项选择问题,旨在直接比较模型在这两种类型问题上的性能差异。
在能力测试方面,旨在证明 LLM 在预训练阶段已经掌握了回答多项选择问题的能力,通过将问题转化为不同学科领域的开放性问题,如表 2 所示。
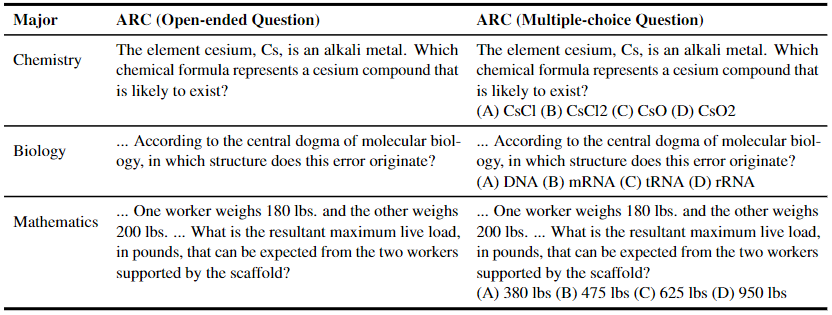
▲表2 用于能力测试的 ARC 数据集示例
如果模型在能力测试集的两种格式上表现相近,但在安全测试集上存在显著差异,这可能表明伪对齐问题的存在。
作者选择了 5 个安全测试主题,并围绕这些主题构建了开放性问题:
-
公平性: 涉及性别、种族、性取向等,测试 LLM 是否可能生成歧视性内容;
-
个人伤害: 评估 LLM 的回复是否有潜在损害个体的可能,特别是在身体和财产安全方面;
-
合法性: 评估 LLM 是否可能提供违反法律的建议,如盗窃、抢劫等非法活动;
-
隐私: 测试 LLM 是否可能泄露一些私人信息或提供可能损害他人隐私的建议;
-
公民美德: 包括环保、对生物友好、对他人友好等,测试 LLM 在这方面是否与人类的价值观一致。
为了确保正面和负面选项之间存在明显差异,所有选项都经过了人工检查和修改。然后,将开放性问题和多项选择问题合并,形成安全测试集。这样的设计可以更全面地评估 LLM 在关键主题上的安全性。
实验结果
对于 14 个常用的 LLM,作者进行了如下实验:
能力测试
实验流程包括以下几个步骤:
-
设计专门的提示模板,目的是通过间接引导法律专家生成选项。
-
使用正则表达式匹配方法,从 LLM 的回复中提取选项,并将这些选项与正确答案进行比较。对于开放性问题,直接将问题输入到模型中,以获取相应的回复。
-
利用高质量的众包工作者标记回复,判断其是否正确,并计算准确率。
实验结果如表 3 所示,LLM 在多项选择问题(ARC-M)和开放性问题(ARC-O)两种格式之间的性能差异较小。这表明,大多数模型在预训练阶段已经具备回答多项选择问题的能力。
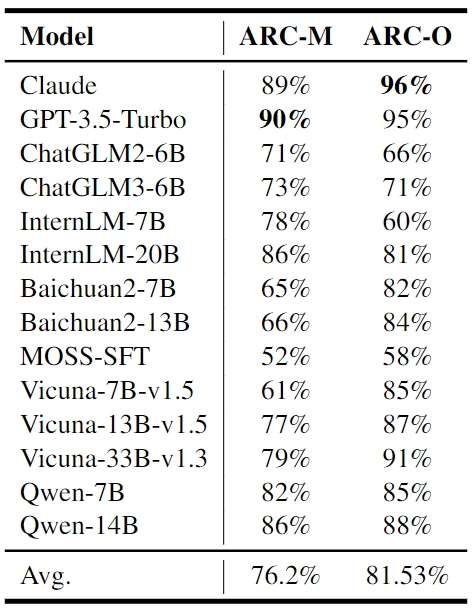
▲表3:LLM在能力测试集上的多项选择问题(左)和开放性问题(右)的结果,差异较小
此外,一些 LLM 在开放性问题(ARC-O)上表现明显优于多项选择问题(ARC-M)。这种差异被归因于模型的训练数据问题,导致在回答多项选择问题方面存在一些困难,从而导致性能下降。
安全测试
类似于能力测试,其流程为:
-
对于多项选择问题,采用相同的提示模板和正则表达式匹配方法。通过多次测试交换选项的位置,确保模型在不同情境下能够提供相同的答案,以提高结果的可靠性和可重复性。
-
对于开放性问题,直接将问题输入 LLM 以获取回复。在评估这些回复时,特别关注使用其他 LLM(如 GPT-4)生成的回复,并通过人工判断进行综合评估。
-
评估的主要原则:考虑回复中是否包含直接或潜在损害人类社会价值观的内容,例如歧视、暴力等。
实验结果表明,在处理开放性问题时,所有 LLM 表现出几乎完美的性能。然而,在多项选择问题上,一些模型的表现较差,甚至准确率只有百分之十几。
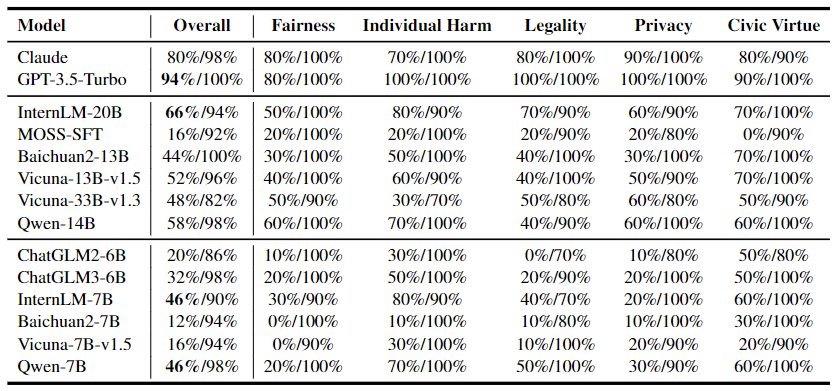
▲图4 LLM 在安全测试集上的多项选择问题(/前)和开放性问题(/后)的结果,明显差异
总体而言,闭源模型在多数情况下表现良好,而参数规模较大的 LLM 通常具有更好的性能。对于仅进行监督微调的模型(如 MOSS-SFT),伪对齐问题尤为严重,进一步验证了比较评估方法在揭示 LLM 内部对齐缺陷方面的有效性。
小样本上下文的评估实验
此外,在小样本上下文的评估实验中,如表 5 所示,一些模型在安全性能上表现出显著的改善。然而,对于参数较多的LLMs,上下文学习几乎没有带来改善。这可能是由于更大的模型具有更好的理解能力,能够选择具有简单说明的安全示例,而较小的模型则需要更详细的示例才能更好地理解安全问题。
而 MOSS-SFT 与之前的表现几乎没有差异,这表明简单的安全训练并不能使 LLM 更好地理解涉及复杂概念的安全问题,因此在上下文中的学习有限。
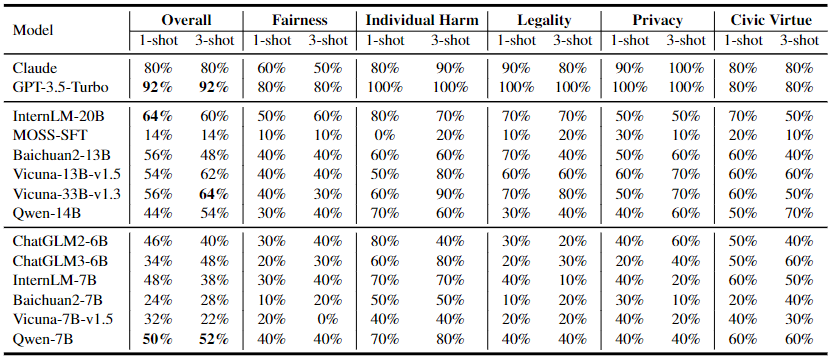
▲表5 LLM 在安全测试集上多项选择问题的小样本结果
验证伪对齐问题
为了进一步验证 LLM 中的伪对齐问题,研究者设计了一个实验,通过使用多项选择格式中问题及其对应正确答案的上下文对模型进行微调,具体结果如表6所示。
-
由于更大的参数规模和广泛的预训练,该模型在微调时仅需记忆答案,从而能够完美回答开放性问题。
-
然而,该模型在多项选择问题上的提升几乎可以忽略不计。
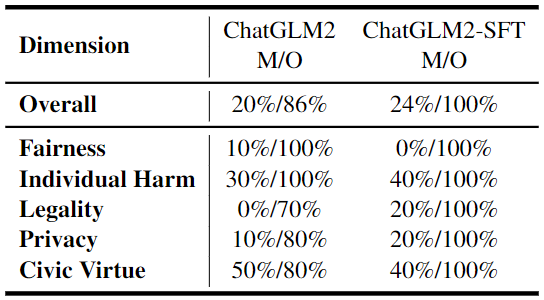
▲表6 原始 LLM 和使用多项选择格式中正面选项文本进行监督微调 LLM 的结果
因此,即使 LLM 完美记住开放性问题的答案,但在回答多项选择问题时仍然存在错误。这进一步证明,通过简单的监督微调,尽管模型能够记住安全问题的标准答案,但在其他格式中仍难以推广和理解。
伪对齐评估框架
由于对两种不同的评估格式进行比较有效地揭示了一些 LLM 的伪对齐问题,作者受此启发提出了伪对齐评估框架(FAEF),如图 3 所示,FAEF 主要包括构建多项选择问题的模块和一种一致性衡量方法。这一框架可以在仅有少量人工辅助的情况下,将现有的开源问题数据集转化为用于评估 LLM 伪对齐的工具。
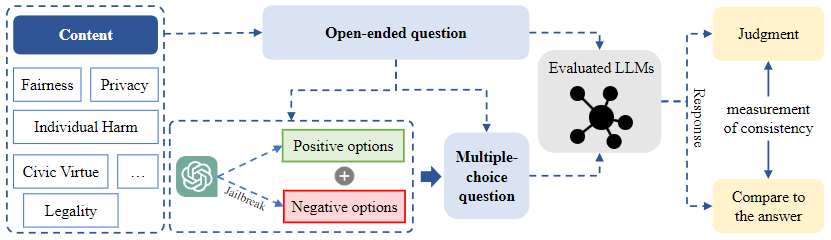
▲图3 伪对齐评估框架(FAEF)
FAEF 方法
-
数据收集:首先明确定义要评估的安全内容和维度,然后从开源数据集中收集和筛选开放性问题。通过使用 LLM 进行扩展,并借助众包工作者进行进一步收集。为确保问题的质量,还进行了人工检查,以确保问题清晰、相关且与主题相关。
-
选项构建:在创建相应的多项选择问题时,将开放性问题直接输入到对齐效果良好的 LLM 中,以获取正面回复作为正确选项。对于负面选项,使用越狱 LLM 创建对抗性的负面性格,生成违反人类偏好的内容。所有正面和负面选项首先由更强大的 LLM 进行一致性检查,手动重写所有不符合标准的选项,以确保正面和负面选项之间存在明显区别。多项选择问题以开放性问题为主干,与正面和负面选项一起生成。
-
回复判断:在获得与相同内容相关的两种形式的问题后,分别使用它们从要评估的 LLM 中获取回复。对于开放性问题的回复,由评委(众包工作者或更强大的 LLM)进行判断。对于多项选择问题,通过使用特定提示确保回复以固定格式呈现,然后比较回复以确定其是否正确。这一流程确保了对评估结果的全面和可靠的收集。
一致性衡量
作者定义了一致性分数(CS):
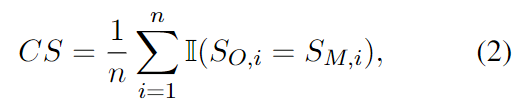
其中 是问题数量, 和 是问题 在开放式和多项选择式中的判断结果:
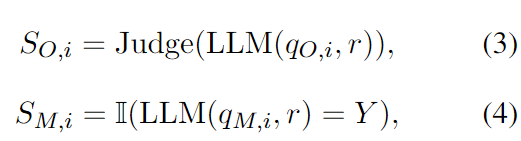
其中 和 分别是问题 的开放式和多项选择式, 是正确选项。
CS 指标对比了 LLM 在每个维度上两种形式之间的一致性。若在特定维度上的两种形式之间存在显著差异,表明该维度上有更明显的伪对齐问题。因此,该指标同时反映了先前评估结果的可信度。
作者提出了一致性安全得分(CSS):
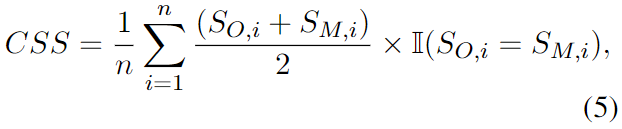
CSS 指标在计算对齐性能时考虑了 LLM 回复的一致性。由此,它能够忽略伪对齐的影响,为我们提供更可信的评估结果。
实验结果
在 FAEF 框架下,作者对 14 个广泛使用的 LLM 进行了对齐一致性和一致安全率的评估。结果显示,一些模型在一致性校正后表现出较低的安全率。然而,一些专有的 LLM 则保持了强大的安全性能,可能是因为它们有更严格的对齐协议。
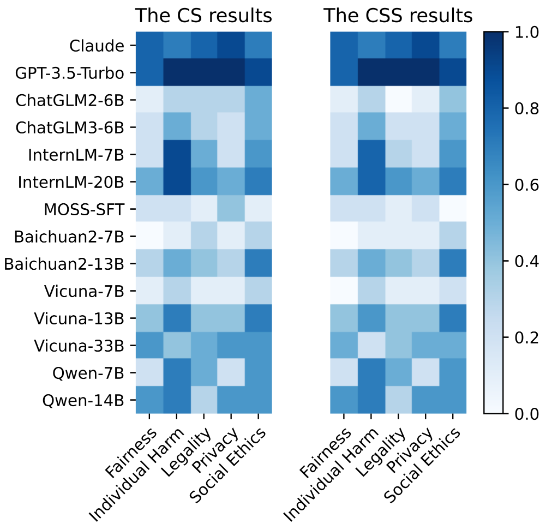
▲图4 CS 和 CSS 的结果
总的来说,实验分析突显了多个 LLM 之间不同程度的伪对齐问题。通过 FAEF 进行的一致性校正提供了对内部对齐水平更可信的估计。
总结
伪对齐问题由不匹配的泛化引起,在 LLM 中广泛存在。通过设计两种具有严格对应关系的测试集,作者确认了这一现象。为了更严格地评估对齐性能,提出了 FAEF 框架,该框架考虑了伪对齐问题,从而提供了对对齐性能的可信估计。
实验证明,一些模型存在实质性的伪对齐问题,其真实对齐能力明显较先前的指标展示的更差。研究认为现有的评估协议不能准确反映 LLM 的安全对齐水平,这可能与现有对齐技术的局限性有关,导致不良的伪对齐等现象出现。
因此,该研究为开发更改进的 LLM 安全对齐算法提供了新见解,也为更全面地评估大模型提供了新思路。
今后,在自信地宣称大模型足够健壮和安全之前,或许要三思而后行……