DataLoader 是 PyTorch 中最常用的类之一。 而且,它是你首先学习的内容之一。 该类有很多参数,但最有可能的是,你将使用其中的大约三个参数(dataset、shuffle 和 batch_size)。 今天我想解释一下 collate_fn 的含义—根据我的经验,我发现它让初学者感到困惑。 我们将简要探讨 PyTorch 如何创建批数据,并了解如何根据需要修改默认行为。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、批创建流程
每个深度学习课程中最重要的信息之一是我们批量执行训练/推理。 大多数时候,一个批次只是一些堆叠的数据样本。 但在某些情况下,我们想修改它的创建方式。
首先,让我们研究一下默认情况下会发生什么。 假设我们有以下玩具数据集。 它包含四个示例,每个示例三个功能。
import torch
from torch.utils.data import DataLoader
import numpy as np
data = np.array([
[0.1, 7.4, 0],
[-0.2, 5.3, 0],
[0.2, 8.2, 1],
[0.2, 7.7, 1]])
print(data)如果我们向加载程序请求一个批次,我们将看到以下内容(请注意,我设置了 shuffle=False 以消除随机性):
loader = DataLoader(data, batch_size=2, shuffle=False)
batch = next(iter(loader))
print(batch)
# tensor([[ 0.1000, 7.4000, 0.0000],
# [-0.2000, 5.3000, 0.0000]], dtype=torch.float64)结果毫不奇怪,但让我们正式描述一下已经做了什么:
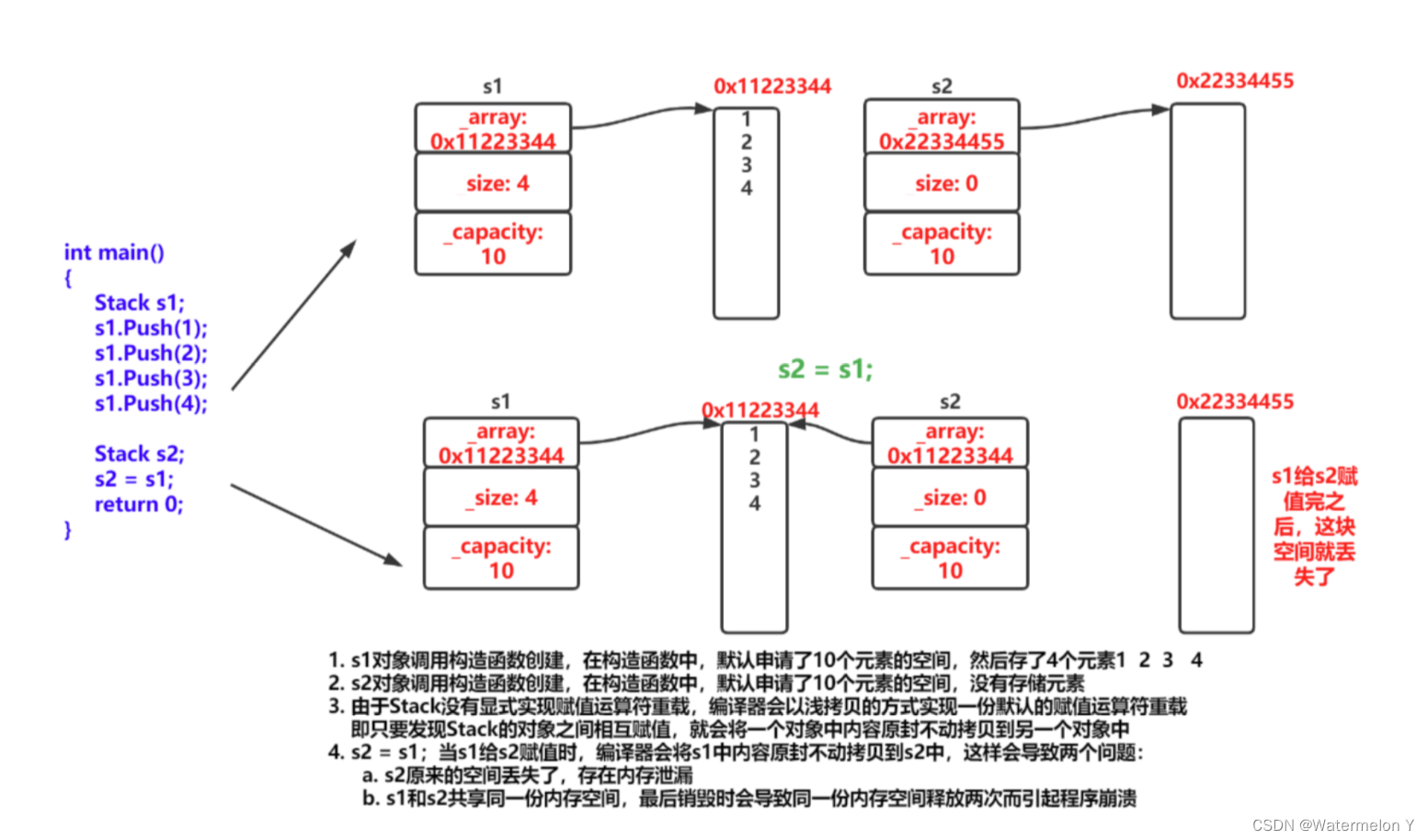
- 加载器从数据集中选择了 2 个样本。
- 这些样本被转换为张量(2 个大小为 3 的样本)。
- 创建并返回一个新的张量 (2x3)。
默认设置还允许我们使用字典。 让我们看一个例子:
from pprint import pprint
# now dataset is a list of dicts
dict_data = [
{'x1': 0.1, 'x2': 7.4, 'y': 0},
{'x1': -0.2, 'x2': 5.3, 'y': 0},
{'x1': 0.2, 'x2': 8.2, 'y': 1},
{'x1': 0.2, 'x2': 7.7, 'y': 10},
]
pprint(dict_data)
# [{'x1': 0.1, 'x2': 7.4, 'y': 0},
# {'x1': -0.2, 'x2': 5.3, 'y': 0},
# {'x1': 0.2, 'x2': 8.2, 'y': 1},
# {'x1': 0.2, 'x2': 7.7, 'y': 10}]
loader = DataLoader(dict_data, batch_size=2, shuffle=False)
batch = next(iter(loader))
pprint(batch)
# {'x1': tensor([ 0.1000, -0.2000], dtype=torch.float64),
# 'x2': tensor([7.4000, 5.3000], dtype=torch.float64),
# 'y': tensor([0, 0])}加载器足够聪明,可以正确地从字典列表中重新打包数据。 当你的数据采用 JSONL 格式(我个人更喜欢这种格式而不是 CSV)时,此功能非常方便。
2、自定义collate函数
如果默认规则如此智能,为什么我们需要创建自定义collate规则呢? 默认设置有一个很大的限制——批数据必须处于同一维度。 假设我们有一个 NLP 任务,并且数据是分词后的文本。
# values are token indices but it does not matter - it can be any kind of variable-size data
nlp_data = [
{'tokenized_input': [1, 4, 5, 9, 3, 2],
'label':0},
{'tokenized_input': [1, 7, 3, 14, 48, 7, 23, 154, 2],
'label':0},
{'tokenized_input': [1, 30, 67, 117, 21, 15, 2],
'label':1},
{'tokenized_input': [1, 17, 2],
'label':0},
]
loader = DataLoader(nlp_data, batch_size=2, shuffle=False)
batch = next(iter(loader))上面的代码不会工作并引发错误:
/usr/local/lib/python3.7/dist-packages/torch/utils/data/_utils/collate.py in default_collate(batch)
80 elem_size = len(next(it))
81 if not all(len(elem) == elem_size for elem in it):
---> 82 raise RuntimeError('each element in list of batch should be of equal size')
83 transposed = zip(*batch)
84 return [default_collate(samples) for samples in transposed]
RuntimeError: each element in list of batch should be of equal size错误消息表明不可能创建非矩形张量。 顺便说一句,可以看到触发错误的是 default_collate函数。
我们可以做什么? 有两种解决方案:
- 将整个数据集填充到最长的样本。
- 在批创建期间动态填充。
第一个解决方案可能看起来更简单—只需将所有样本扩展到最长的样本即可。 但有一个问题—我们会浪费内存和计算能力(它们在 GPU 上很昂贵!)来处理 padding,这并不影响结果。 如果我们的数据中有一些长序列,而且大多数序列都相对较短,那就尤其痛苦。 在这种情况下,我们主要是处理填充而不是数据!

如果我们将整个数据集填充到最长的序列,会浪费大量空间!
另一种方法是动态填充数据。 当选择该批的样本时,我们只将它们填充到最长的样本。 如果我们另外按长度对数据进行排序,则填充将是最小的。 如果有一些非常长的序列,它们只会影响它们的批次,而不是整个数据集。
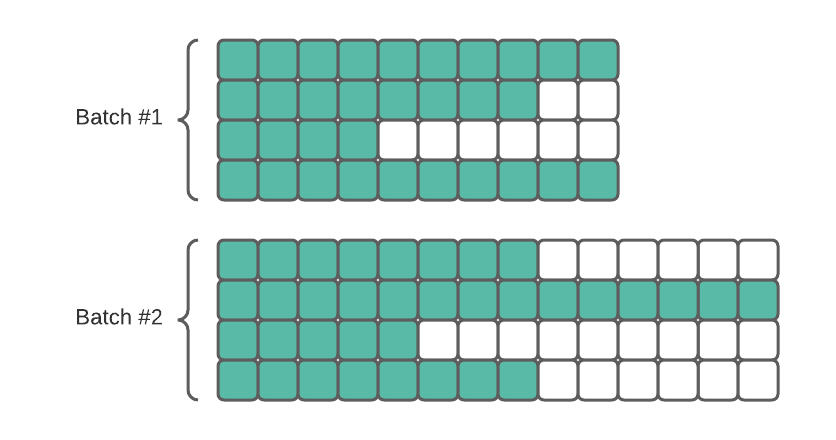
好吧,但是如何实现呢? 只需创建一个自定义 collate_fn , 这很简单:
from torch.nn.utils.rnn import pad_sequence #(1)
def custom_collate(data): #(2)
inputs = [torch.tensor(d['tokenized_input']) for d in data] #(3)
labels = [d['label'] for d in data]
inputs = pad_sequence(inputs, batch_first=True) #(4)
labels = torch.tensor(labels) #(5)
return { #(6)
'tokenized_input': inputs,
'label': labels
}
loader = DataLoader(
nlp_data,
batch_size=2,
shuffle=False,
collate_fn=custom_collate
) #(7)
iter_loader = iter(loader)
batch1 = next(iter_loader)
pprint(batch1)
batch2 = next(iter_loader)
pprint(batch2)
# {'label': tensor([0, 0]),
# 'tokenized_input': tensor([
# [ 1, 4, 5, 9, 3, 2, 0, 0, 0],
# [ 1, 7, 3, 14, 48, 7, 23, 154, 2]
# ])}
# {'label': tensor([1, 0]),
# 'tokenized_input': tensor([
# [ 1, 30, 67, 117, 21, 15, 2],
# [ 1, 17, 2, 0, 0, 0, 0]])}代码说明如下:
- 我们使用
pad_sequence进行填充 Collate函数要传入单个参数 - 样本列表。 在这种情况下,它将是一个字典列表,但它也可以是一个元组列表等——具体取决于数据集。- 当数据出现时,如果格式为“字典列表”,我们需要遍历它并为所有输入和标签创建一个单独的列表。 与此同时,
tokenized_input被转换为一维张量(它是一个整数列表)。 - 执行填充。
- 由于标签是整数列表,我们将其转换为张量。
- 返回格式化的批次。
- 在加载器中设置我们的自定义整理函数。
正如我们所看到的,批的格式与字典的默认排序规则相同。 我们清楚地看到填充量很小。
3、结束语
创建自定义整理函数可能不是最常见的任务,但你绝对需要知道如何去做。
原文链接:PyTorch collate_fn详解 - BimAnt