大型语言模型 (LLM) 以其广泛的计算要求而闻名。 通常,模型的大小是通过将参数数量(大小)乘以这些值的精度(数据类型)来计算的。 然而,为了节省内存,可以通过称为量化的过程使用较低精度的数据类型来存储权重。
我们在文献中区分了两个主要的权重量化技术:
- 训练后量化 (PTQ:Post-Training Quantization) 是一种简单的技术,其中已训练模型的权重将转换为较低的精度,而无需任何重新训练。 尽管易于实施,但 PTQ 会导致潜在的性能下降。
- 量化感知训练(QAT:Quantization-Aware Training)在预训练或微调阶段结合了权重转换过程,从而提高了模型性能。 然而,QAT 的计算成本很高,并且需要有代表性的训练数据。
在本文中,我们重点关注 PTQ 来降低参数的精度。 为了获得良好的直觉,我们将使用 GPT-2 模型将简单的和更复杂的技术应用于玩具示例。
整个代码可以在 Google Colab 和 GitHub 上免费获得。
在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、浮点数表示
数据类型的选择决定了所需的计算资源的数量,从而影响模型的速度和效率。 在深度学习应用中,平衡精度和计算性能成为一项至关重要的练习,因为更高的精度通常意味着更大的计算需求。
在各种数据类型中,浮点数主要用于深度学习,因为它们能够以高精度表示各种值。 通常,浮点数使用 n 位来存储数值。 这 n 位进一步分为三个不同的组成部分:
- 符号(Sign):符号位表示数字的正数或负数。 它使用一位,其中 0 表示正数,1 表示负数。
- 指数(Exponent):指数是一段位,表示基数(在二进制表示中通常为 2)的幂。 指数也可以是正数或负数,允许数字表示非常大或非常小的值。
- 有效数/尾数(Significand/Mantissa):剩余位用于存储有效数,也称为尾数。 这代表数字的有效数字。 数字的精度在很大程度上取决于有效数字的长度。
这种设计允许浮点数以不同的精度级别覆盖广泛的值。 用于这种表示的公式是:
![]()
为了更好地理解这一点,让我们深入研究深度学习中一些最常用的数据类型:float32 (FP32)、float16 (FP16) 和 bfloat16 (BF16):
- FP32 使用 32 位来表示数字:1位表示符号,8位表示指数,其余 23 位表示有效数。 虽然 FP32 提供高精度,但其缺点是计算量和内存占用量较高。

- FP16 使用 16 位来存储数字:1位用于符号,5位用于指数,10位用于有效数。 尽管这使其内存效率更高并加速计算,但范围和精度的降低可能会导致数值不稳定,从而可能影响模型的准确性。

- BF16 也是一种 16 位格式,但其中1位用于符号,8位用于指数,7位用于有效数。 与 FP16 相比,BF16 扩大了可表示范围,从而降低了下溢和上溢风险。 尽管由于有效位数较少而导致精度降低,但 BF16 通常不会显着影响模型性能,并且对于深度学习任务来说是一个有用的折衷方案。

在机器学习术语中,FP32 通常被称为“全精度”(4 字节),而 BF16 和 FP16 则被称为“半精度”(2 字节)。 但是我们可以做得更好并使用单个字节存储权重吗? 答案是 INT8 数据类型,它由能够存储 2⁸ = 256 个不同值的 8 位表示组成。 在下一节中,我们将了解如何将 FP32 权重转换为 INT8 格式。
2、朴素的8 位量化
在本节中,我们将实现两种量化技术:一种具有绝对最大 (absmax) 量化的对称技术和一种具有零点(zeropoint)量化的非对称技术。 在这两种情况下,目标都是将 FP32 张量 X(原始权重)映射到 INT8 张量 X_quant(量化权重)。
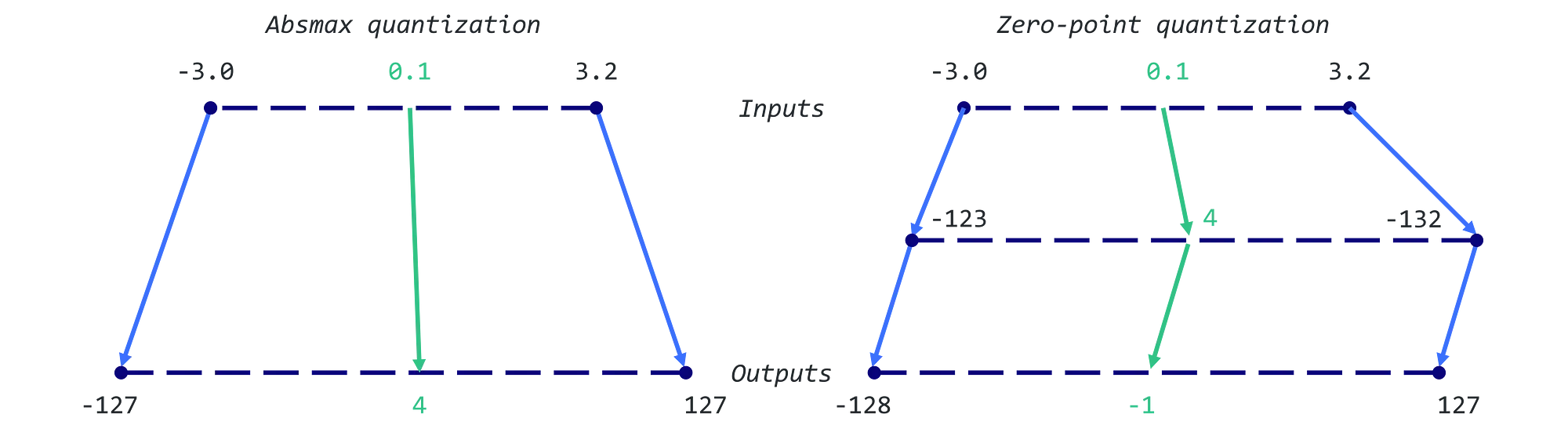
通过 absmax 量化,原始数字除以张量的绝对最大值,并乘以缩放因子 (127),以将输入映射到范围 [-127, 127]。 为了检索原始 FP16 值,将 INT8 数字除以量化因子,承认由于舍入而造成的一些精度损失。
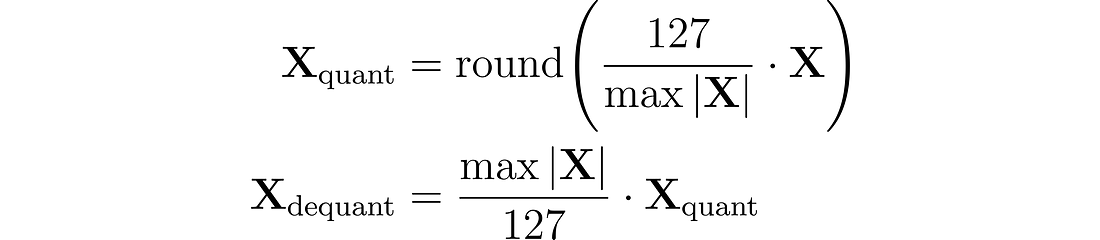
例如,假设我们的绝对最大值为 3.2。 权重 0.1 将被量化为 round(0.1 × 127/3.2) = 4。如果我们想对其进行反量化,我们将得到 4 × 3.2/127 = 0.1008,这意味着误差为 0.008。 下面是相应的 Python 实现:
import torch
def absmax_quantize(X):
# Calculate scale
scale = 127 / torch.max(torch.abs(X))
# Quantize
X_quant = (scale * X).round()
# Dequantize
X_dequant = X_quant / scale
return X_quant.to(torch.int8), X_dequant通过零点量化,我们可以考虑不对称输入分布,例如,当考虑 ReLU 函数的输出(仅正值)时,这非常有用。 输入值首先按值的总范围 (255) 除以最大值和最小值之差进行缩放。 然后将该分布移动零点,将其映射到范围 [-128, 127](注意与 absmax 相比的额外值)。 首先,我们计算比例因子和零点值:
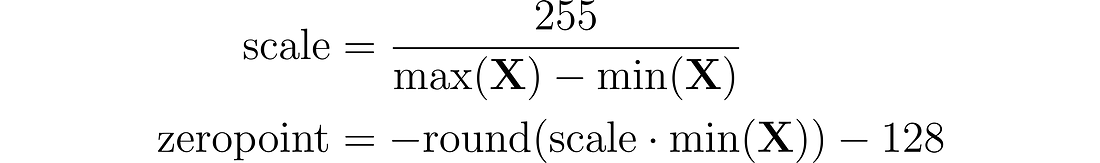
然后,我们可以使用这些变量来量化或反量化我们的权重:

举个例子:最大值为 3.2,最小值为 -3.0。 我们可以计算出比例为 255/(3.2 + 3.0) = 41.13,零点 -round(41.13 × -3.0) - 128 = 123 -128 = -5,因此我们之前的权重 0.1 将被量化为 round( 41.13 × 0.1 -5) = -1。 这与之前使用 absmax 获得的值(4 与 -1)有很大不同。
Python 的实现非常简单:
def zeropoint_quantize(X):
# Calculate value range (denominator)
x_range = torch.max(X) - torch.min(X)
x_range = 1 if x_range == 0 else x_range
# Calculate scale
scale = 255 / x_range
# Shift by zero-point
zeropoint = (-scale * torch.min(X) - 128).round()
# Scale and round the inputs
X_quant = torch.clip((X * scale + zeropoint).round(), -128, 127)
# Dequantize
X_dequant = (X_quant - zeropoint) / scale
return X_quant.to(torch.int8), X_dequant借助 Transformer 库,我们可以在真实模型上使用这两个函数,而不是依赖完整的玩具示例。
我们首先加载 GPT-2 的模型和标记器。 这是一个非常小的模型,我们可能不想量化,但对于本教程来说它已经足够了。 首先,我们想要观察模型的大小,以便稍后进行比较并评估 8 位量化带来的内存节省。
!pip install -q bitsandbytes>=0.39.0
!pip install -q git+https://github.com/huggingface/accelerate.git
!pip install -q git+https://github.com/huggingface/transformers.gitfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
# Set device to CPU for now
device = 'cpu'
# Load model and tokenizer
model_id = 'gpt2'
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Print model size
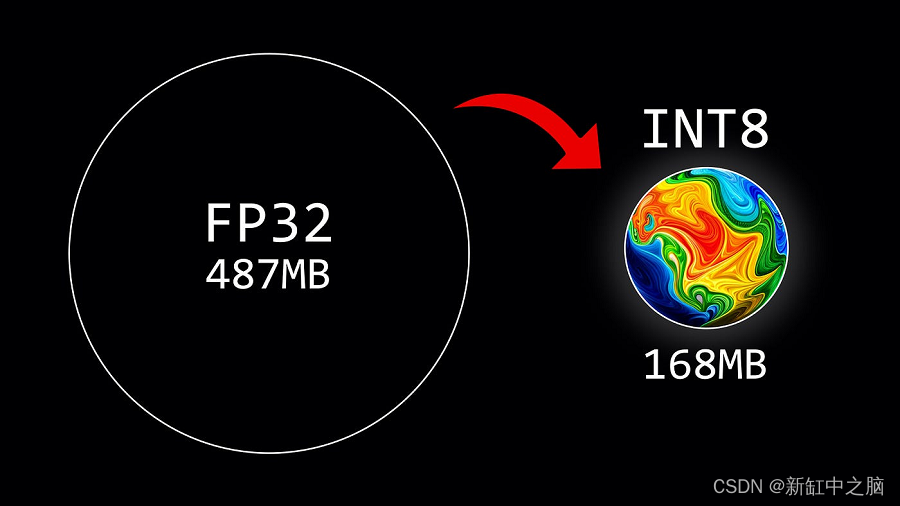
print(f"Model size: {model.get_memory_footprint():,} bytes")Model size: 510,342,192 bytesGPT-2 模型的大小在 FP32 中约为 487MB。 下一步包括使用零点和绝对最大量化来量化权重。 在下面的示例中,我们将这些技术应用于 GPT-2 的第一个注意力层以查看结果。
# Extract weights of the first layer
weights = model.transformer.h[0].attn.c_attn.weight.data
print("Original weights:")
print(weights)
# Quantize layer using absmax quantization
weights_abs_quant, _ = absmax_quantize(weights)
print("\nAbsmax quantized weights:")
print(weights_abs_quant)
# Quantize layer using absmax quantization
weights_zp_quant, _ = zeropoint_quantize(weights)
print("\nZero-point quantized weights:")
print(weights_zp_quant)输出结果如下:
Original weights:
tensor([[-0.4738, -0.2614, -0.0978, ..., 0.0513, -0.0584, 0.0250],
[ 0.0874, 0.1473, 0.2387, ..., -0.0525, -0.0113, -0.0156],
[ 0.0039, 0.0695, 0.3668, ..., 0.1143, 0.0363, -0.0318],
...,
[-0.2592, -0.0164, 0.1991, ..., 0.0095, -0.0516, 0.0319],
[ 0.1517, 0.2170, 0.1043, ..., 0.0293, -0.0429, -0.0475],
[-0.4100, -0.1924, -0.2400, ..., -0.0046, 0.0070, 0.0198]])
Absmax quantized weights:
tensor([[-21, -12, -4, ..., 2, -3, 1],
[ 4, 7, 11, ..., -2, -1, -1],
[ 0, 3, 16, ..., 5, 2, -1],
...,
[-12, -1, 9, ..., 0, -2, 1],
[ 7, 10, 5, ..., 1, -2, -2],
[-18, -9, -11, ..., 0, 0, 1]], dtype=torch.int8)
Zero-point quantized weights:
tensor([[-20, -11, -3, ..., 3, -2, 2],
[ 5, 8, 12, ..., -1, 0, 0],
[ 1, 4, 18, ..., 6, 3, 0],
...,
[-11, 0, 10, ..., 1, -1, 2],
[ 8, 11, 6, ..., 2, -1, -1],
[-18, -8, -10, ..., 1, 1, 2]], dtype=torch.int8)原始值 (FP32) 和量化值 (INT8) 之间的差异很明显,但 absmax 和零点权重之间的差异更为微妙。 在这种情况下,输入看起来偏移了 -1 值。 这表明该层的权重分布非常对称。
我们可以通过量化 GPT-2 中的每一层(线性层、注意力层等)来比较这些技术,并创建两个新模型:model_abs 和 model_zp。 准确地说,我们实际上会用去量化的权重替换原始权重。 这有两个好处:它允许我们:1) 比较权重的分布(相同比例)和 2) 实际运行模型。
事实上,PyTorch 默认情况下不允许 INT8 矩阵乘法。 在实际场景中,我们会对它们进行反量化以运行模型(例如在 FP16 中),但将它们存储为 INT8。 在下一节中,我们将使用bitsandbytes库来解决这个问题。
import numpy as np
from copy import deepcopy
# Store original weights
weights = [param.data.clone() for param in model.parameters()]
# Create model to quantize
model_abs = deepcopy(model)
# Quantize all model weights
weights_abs = []
for param in model_abs.parameters():
_, dequantized = absmax_quantize(param.data)
param.data = dequantized
weights_abs.append(dequantized)
# Create model to quantize
model_zp = deepcopy(model)
# Quantize all model weights
weights_zp = []
for param in model_zp.parameters():
_, dequantized = zeropoint_quantize(param.data)
param.data = dequantized
weights_zp.append(dequantized)现在我们的模型已经量化,我们想要检查这个过程的影响。 直观上,我们希望确保量化后的权重接近原始权重。 检查它的一种直观方法是绘制反量化权重和原始权重的分布。 如果量化是有损的,则会极大地改变权重分布。
下图显示了这种比较,其中蓝色直方图代表原始(FP32)权重,红色直方图代表反量化(来自 INT8)权重。 请注意,我们仅显示 -2 和 2 之间的图,因为异常值的绝对值非常高(稍后会详细介绍)。
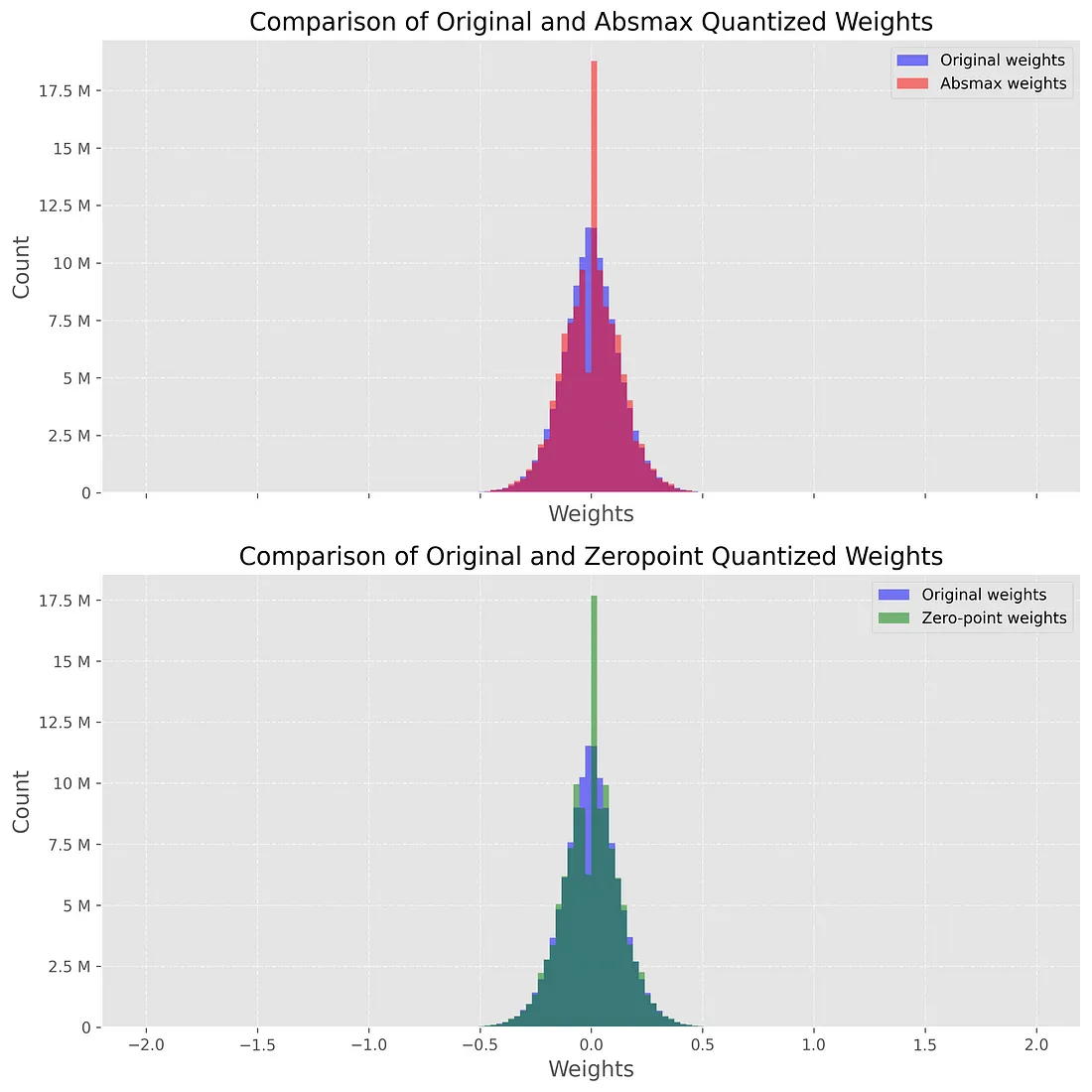
两个图都非常相似,在 0 附近有一个令人惊讶的峰值。这个峰值表明我们的量化是相当有损的,因为反转过程不会输出原始值。 对于 absmax 模型尤其如此,该模型在 0 附近显示较低的谷值和较高的峰值。
让我们比较原始模型和量化模型的性能。 为此,我们定义了一个generate_text()函数来通过top-k采样生成50个token。
def generate_text(model, input_text, max_length=50):
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
output = model.generate(inputs=input_ids,
max_length=max_length,
do_sample=True,
top_k=30,
pad_token_id=tokenizer.eos_token_id,
attention_mask=input_ids.new_ones(input_ids.shape))
return tokenizer.decode(output[0], skip_special_tokens=True)
# Generate text with original and quantized models
original_text = generate_text(model, "I have a dream")
absmax_text = generate_text(model_abs, "I have a dream")
zp_text = generate_text(model_zp, "I have a dream")
print(f"Original model:\n{original_text}")
print("-" * 50)
print(f"Absmax model:\n{absmax_text}")
print("-" * 50)
print(f"Zeropoint model:\n{zp_text}")输出结果如下:
Original model:
I have a dream, and it is a dream I believe I would get to live in my future. I love my mother, and there was that one time I had been told that my family wasn't even that strong. And then I got the
--------------------------------------------------
Absmax model:
I have a dream to find out the origin of her hair. She loves it. But there's no way you could be honest about how her hair is made. She must be crazy.
We found a photo of the hairstyle posted on
--------------------------------------------------
Zeropoint model:
I have a dream of creating two full-time jobs in America—one for people with mental health issues, and one for people who do not suffer from mental illness—or at least have an employment and family history of substance abuse, to work part我们可以通过计算每个输出的困惑度(perplexity)来量化它,而不是试图查看一个输出是否比其他输出更有意义。 这是用于评估语言模型的常用指标,它衡量模型在预测序列中下一个标记时的不确定性。 在此比较中,我们做出共同的假设:分数越低,模型越好。 实际上,一个高度困惑的句子也可能是正确的。
我们使用最小函数来实现它,因为我们的句子很短,所以不需要考虑诸如上下文窗口的长度之类的细节。
def calculate_perplexity(model, text):
# Encode the text
encodings = tokenizer(text, return_tensors='pt').to(device)
# Define input_ids and target_ids
input_ids = encodings.input_ids
target_ids = input_ids.clone()
with torch.no_grad():
outputs = model(input_ids, labels=target_ids)
# Loss calculation
neg_log_likelihood = outputs.loss
# Perplexity calculation
ppl = torch.exp(neg_log_likelihood)
return ppl
ppl = calculate_perplexity(model, original_text)
ppl_abs = calculate_perplexity(model_abs, absmax_text)
ppl_zp = calculate_perplexity(model_zp, absmax_text)
print(f"Original perplexity: {ppl.item():.2f}")
print(f"Absmax perplexity: {ppl_abs.item():.2f}")
print(f"Zeropoint perplexity: {ppl_zp.item():.2f}")输出结果如下:
Original perplexity: 15.53
Absmax perplexity: 17.92
Zeropoint perplexity: 17.97我们看到原始模型的困惑度略低于其他两个模型。 单个实验不太可靠,但我们可以多次重复此过程以查看每个模型之间的差异。 理论上,零点量化应该比absmax稍好,但计算成本也更高。
在此示例中,我们将量化技术应用于整个层(基于每个张量)。 但是,我们可以将其应用到不同的粒度级别:从整个模型到单个值。 一次性量化整个模型会严重降低性能,而量化单个值会产生很大的开销。 在实践中,我们通常更喜欢向量量化,它考虑同一张量内的行和列中值的可变性。
然而,即使向量量化也不能解决离群特征的问题。 异常值特征是当模型达到一定规模(>6.7B 参数)时出现在所有 Transformer 层中的极值(负或正)。 这是一个问题,因为单个异常值可能会降低所有其他值的精度。 但放弃这些异常特征并不是一个选择,因为它会大大降低模型的性能。
3、使用 LLM.int8() 进行 8 位量化
由 Dettmers 等人提出, LLM.int8() 是异常值问题的解决方案。 它依赖于矢量方式(absmax)量化方案并引入混合精度量化。 这意味着异常值特征以 FP16 格式处理以保持其精度,而其他值以 INT8 格式处理。 由于异常值约占值的 0.1%,这有效地将 LLM 的内存占用量减少了近 2 倍。

LLM.int8() 的工作原理是通过三个关键步骤进行矩阵乘法计算:
- 使用自定义阈值从输入隐藏状态 X 中提取包含异常值特征的列。
- 使用 FP16 执行异常值的矩阵乘法,使用 INT8 执行非异常值的矩阵乘法,并进行向量量化(隐藏状态 X 为行式,权重矩阵 W 为列式)。
- 对非异常值结果(INT8 到 FP16)进行反量化,并将其添加到异常值结果中,以获得 FP16 中的完整结果。
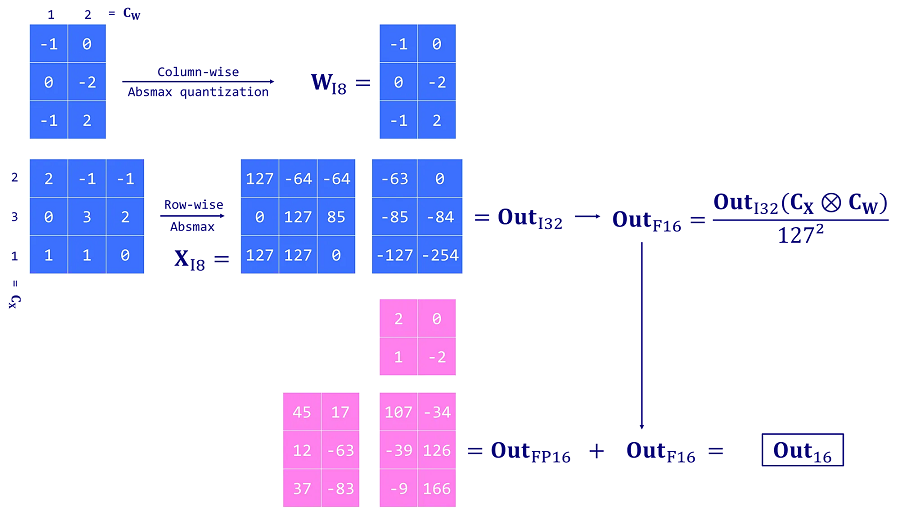
这种方法是必要的,因为 8 位精度是有限的,并且在量化具有大值的向量时可能会导致严重的错误。 当这些错误通过多层传播时,它们也往往会放大。
由于将bitsandbytes 库集成到Hugging Face 生态系统中,我们可以轻松使用此技术。 我们只需要在加载模型时指定 load_in_8bit=True(它也需要GPU)。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_int8 = AutoModelForCausalLM.from_pretrained(model_id,
device_map='auto',
load_in_8bit=True,
)
print(f"Model size: {model_int8.get_memory_footprint():,} bytes")输出结果如下:
Model size: 176,527,896 bytes有了这行额外的代码,模型现在几乎小了三倍(168MB vs. 487MB)。 我们甚至可以像之前那样比较原始权重和量化权重的分布:
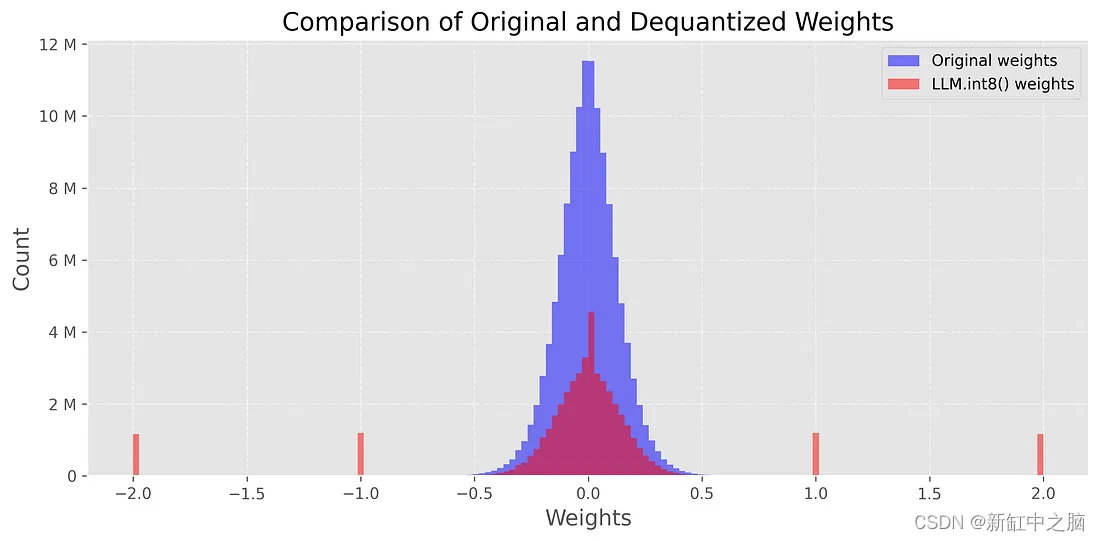 在本例中,我们看到 -2、-1、0、1、2 等附近的峰值。这些值对应于以 INT8 格式存储的参数(非异常值)。 你可以通过使用
在本例中,我们看到 -2、-1、0、1、2 等附近的峰值。这些值对应于以 INT8 格式存储的参数(非异常值)。 你可以通过使用 model_int8.parameters() 打印模型的权重来验证它。
我们还可以使用这个量化模型生成文本并将其与原始模型进行比较。
# Generate text with quantized model
text_int8 = generate_text(model_int8, "I have a dream")
print(f"Original model:\n{original_text}")
print("-" * 50)
print(f"LLM.int8() model:\n{text_int8}")输出结果如下:
Original model:
I have a dream, and it is a dream I believe I would get to live in my future. I love my mother, and there was that one time I had been told that my family wasn't even that strong. And then I got the
--------------------------------------------------
LLM.int8() model:
I have a dream. I don't know what will come of it, but I am going to have to look for something that will be right. I haven't thought about it for a long time, but I have to try to get that thing再次,很难判断什么是最好的输出,但我们可以依靠困惑度度量来给我们一个(近似的)答案。
print(f"Perplexity (original): {ppl.item():.2f}")
ppl = calculate_perplexity(model_int8, text_int8)
print(f"Perplexity (LLM.int8()): {ppl.item():.2f}")Perplexity (original): 15.53
Perplexity (LLM.int8()): 7.93在这种情况下,量化模型的困惑度是原始模型的两倍。 一般来说,情况并非如此,但它表明这种量化技术非常有竞争力。 事实上, LLM.int8() 的作者表明,性能下降非常低,可以忽略不计(<1%)。 然而,它在计算方面有额外的成本:对于大型模型, LLM.int8() 大约慢 20% 左右。
4、结束语
本文概述了最流行的权重量化技术。 我们首先了解浮点表示,然后介绍两种 8 位量化技术:absmax 和零点量化。 然而,它们的局限性,特别是在处理异常值方面,导致了 LLM.int8(),这种技术也保留了模型的性能。 这种方法强调了权重量化领域所取得的进展,揭示了正确解决异常值的重要性。
展望未来,我们的下一篇文章将深入探讨 GPTQ 权重量化技术。 该技术由 Frantar 等人提出,仅使用 4 位,代表了权重量化领域的重大进步。 我们将提供有关如何使用 AutoGPTQ 库实现 GPTQ 的全面指南。
原文链接:LLM权重量化实战 - BimAnt



![[C/C++]数据结构 链表(单向链表,双向链表)](https://img-blog.csdnimg.cn/1a4b0101308d4abb9c2d7b49427d50f6.png)