记录一下做的练习题
目录
1)自定义一个 Series 并命名为 s1,自定义索引值,采用随机数作为其中数据尝试使用 s1.sum(计算其中所有数据的和,使用 s.mean(计算其中所有数据的平均值。
2)创建一个形状为4*6的 DataFrame 并命名为 df1,并指定行索引为[“a”,“b”,“c”,"d"]、列索引为[“A",“B”,“C”,“D”,“E”,“F”],元素的取值为 1-100 之间的随机数。
3)对 df1 中的数据进行过滤,删除"B"列中不大于 70 的元素所在的行。
4) 以列表的形式输出 df1 各列中元素的平均值。
5) 以列表的形式输出 df1 各行中元素的和。
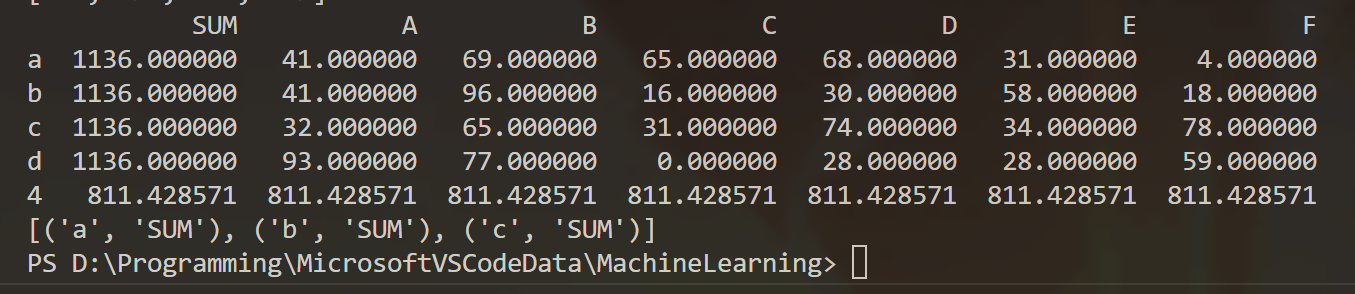
6) 自定义函数 df extend()实现如下功能: 传入一个 DataFrame,该函数会在该 DataFrame 中添加一列,列索引为“SUM”,其中的元素为各列元素的和。然后再添加一行,行索引为“MEAN”,其中的元素为各列元素的平均值。
7)自定义数 max three()实现如下功能: 传入一个 DataFrame,该函数会以列表的方式返回该 DataFrame 中最大的三个元素的坐标;(用元组表示坐标,例如:[(2,4),(3,6),(1,5)] 。
import numpy as np
import pandas as pd1)自定义一个 Series 并命名为 s1,自定义索引值,采用随机数作为其中数据尝试使用 s1.sum(计算其中所有数据的和,使用 s.mean(计算其中所有数据的平均值。
#(1)
data = np.random.RandomState(16).randint(0,100,16)
index = range(1,17)
s1 = pd.Series(data=data,index=index)
print(s1)
print(s1.sum())
print(s1.mean())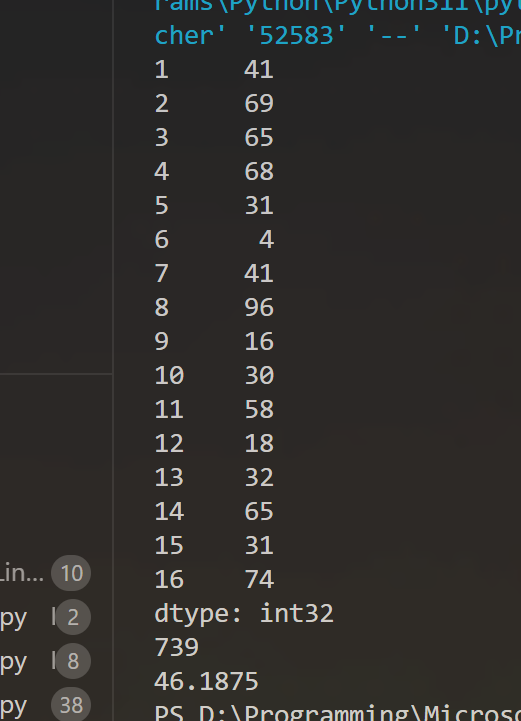
2)创建一个形状为4*6的 DataFrame 并命名为 df1,并指定行索引为[“a”,“b”,“c”,"d"]、列索引为[“A",“B”,“C”,“D”,“E”,“F”],元素的取值为 1-100 之间的随机数。
#(2)
data1 = np.random.RandomState(16).randint(0,100,24)
df1 = pd.DataFrame(data=data1.reshape(4,6),index=["a","b","c","d"],columns=["A","B","C","D","E","F"])
print(df1)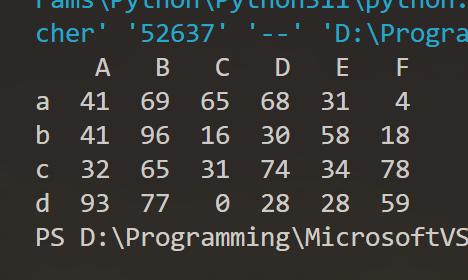
3)对 df1 中的数据进行过滤,删除"B"列中不大于 70 的元素所在的行。
#(3)
df2 = df1.drop([i for i in df1[df1.B <= 70].index],axis=0)
print(df2)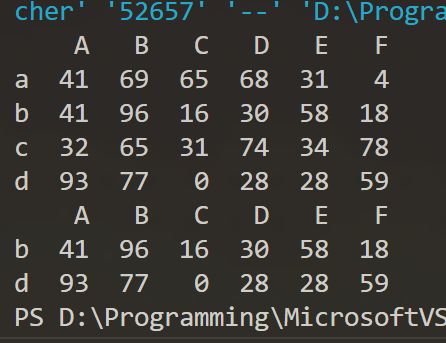
4) 以列表的形式输出 df1 各列中元素的平均值。
5) 以列表的形式输出 df1 各行中元素的和。
#(4)
list_1 = []
for lie in df1.columns:
list_1.append(df1.loc[:,lie].mean())
print(list_1)
#(5)
list_2 = []
for hang in df1.index:
list_2.append(df1.loc[hang].sum())
print(list_2)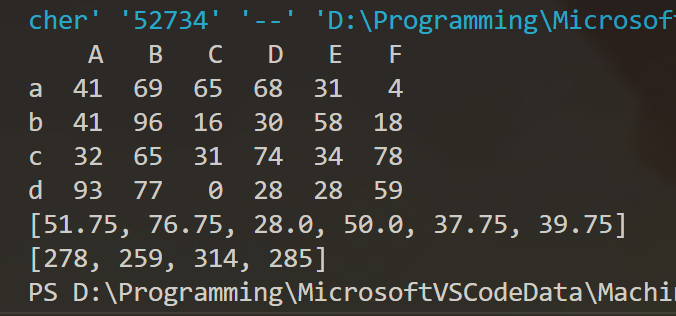
6) 自定义函数 df extend()实现如下功能: 传入一个 DataFrame,该函数会在该 DataFrame 中添加一列,列索引为“SUM”,其中的元素为各列元素的和。然后再添加一行,行索引为“MEAN”,其中的元素为各列元素的平均值。
#(6)
def df_extend(df1):
sum_lie = 0
for lie in df1.columns:
sum_lie = sum_lie + df1.loc[:,lie].sum()
df1.insert(loc=0,column="SUM",value=sum_lie)
mean_hang = 0
for hang in df1.index:
mean_hang = mean_hang + df1.loc[hang].mean()
df1.loc[4] = mean_hang
print(df1)
df_extend(df1)
7)自定义数 max three()实现如下功能: 传入一个 DataFrame,该函数会以列表的方式返回该 DataFrame 中最大的三个元素的坐标;(用元组表示坐标,例如:[(2,4),(3,6),(1,5)] 。
#(7)
def max_three(df1):
list_value = []
list_position = []
for lie in df1.columns:
for hang in df1.index:
list_value.append(df1[lie][hang])
list_position.append((hang,lie))
dic = {k:v for k, v in zip(list_position, list_value)}
list_value.sort(reverse=True)
position_keys = [key for key, value in dic.items() if value in list_value[:3]]
if len(position_keys) >= 3:
position_keys = position_keys[:3]
print(position_keys)
max_three(df1)