🌈欢迎来到C++专栏~~ 模拟实现string
- (꒪ꇴ꒪(꒪ꇴ꒪ )🐣,我是Scort🎓
- 🌍博客主页:张小姐的猫~江湖背景
- 快上车🚘,握好方向盘跟我有一起打天下嘞!
- 送给自己的一句鸡汤🤔:
- 🔥真正的大师永远怀着一颗学徒的心
- 作者水平很有限,如果发现错误,可在评论区指正,感谢🙏
- 🎉🎉欢迎持续关注!


string类的模拟实现
- 🌈欢迎来到C++专栏~~ 模拟实现string
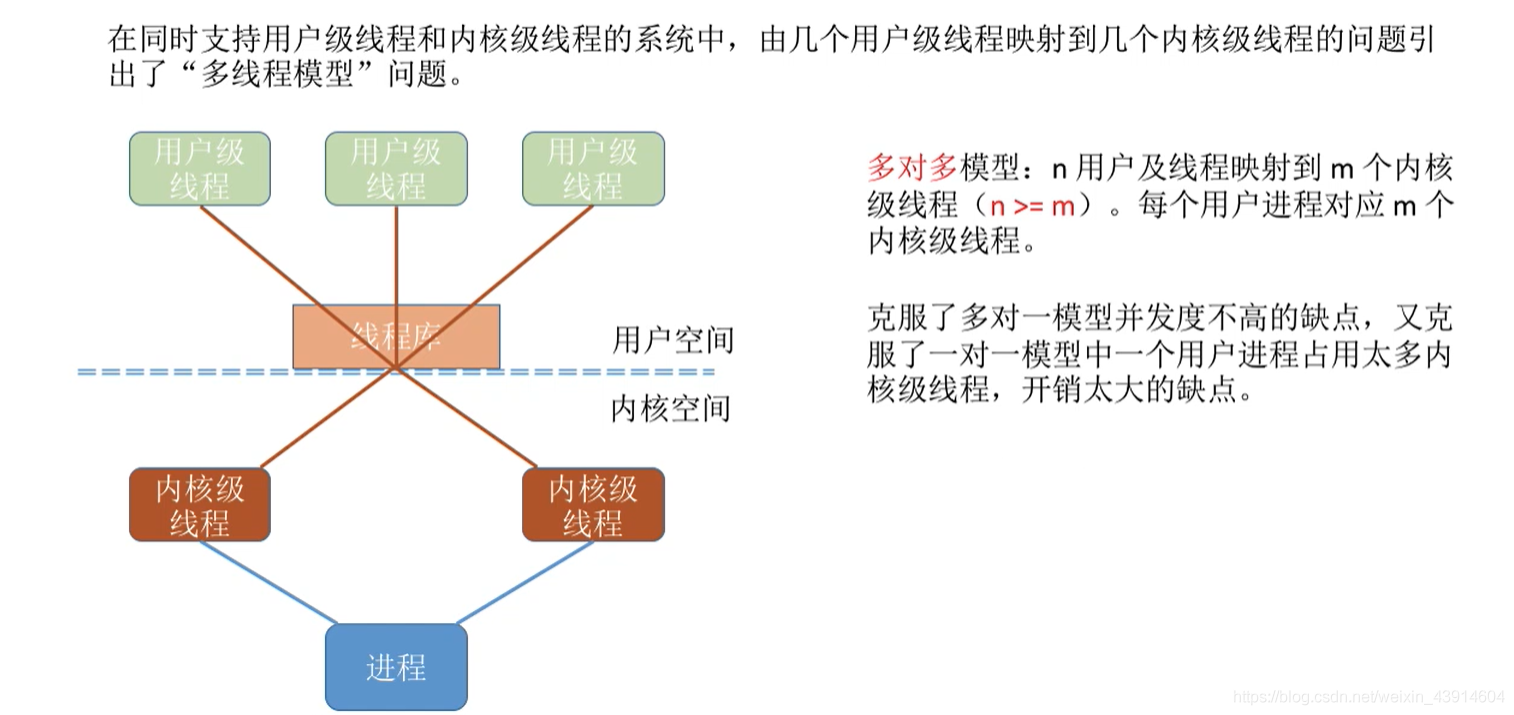
- 一. 构造 & 拷贝构造 & 赋值重载 & 析构 & 赋值重载
- 🎨传统写法
- 🎨现代写法(资本家)
- 🎨swap的区别
- 二. 基本接口
- 🌈size & capacity
- 🌈c_str
- 🌈[]
- 🌈迭代器
- 三. 增
- ⚡reserve & resize
- ⚡push_back & append
- ⚡+=
- ⚡insert
- 四. 删
- 🌌erase
- 🌌clear
- 六、find & substr
- 七、运算符重载
- 🐋大小运算符的比较
- 🐋 >> & <<
- 附源码:`string.h` & `test.c`
- 😀说在最后

一. 构造 & 拷贝构造 & 赋值重载 & 析构 & 赋值重载
🎨传统写法
【面试题】实现一个简洁的string类,即只考虑_str这个成员,着重考察深浅拷贝
💢1.构造函数
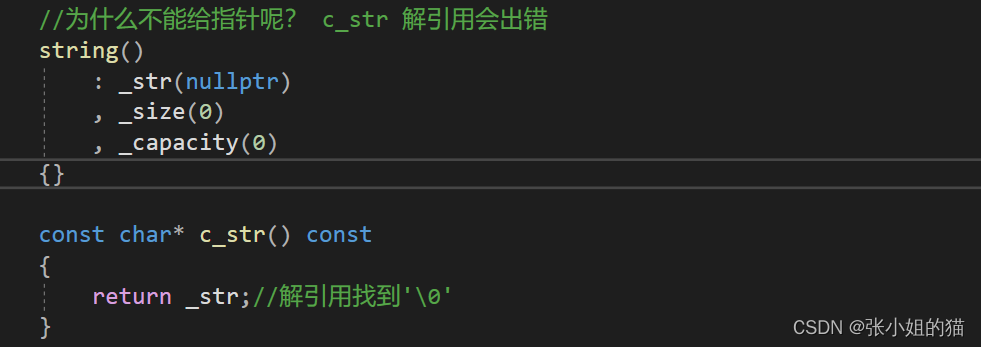
构造函数,我们一般是带参/无参两种构造方式。其中文档可查到无参时默认构造空串"" (隐含了’\0’),给一个缺省值即可,注意不是给空指针nullptr( c_str会出错 )
string(const char* str = "")
{
_size = strlen(str);//复用 —— 且不用关心初始化顺序
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
ps:capacity是指能存储有效字符的个数,因此开空间时要注意给\0预留空间,string类要特别注意\0的存在
💢2.拷贝构造
我们知道,拷贝构造&赋值重载这两个特殊的成员函数,如果自己不写编译器会自动生成。这份默认的拷贝构造(赋值重载)对于内置类型完成浅拷贝;对于自定义类型会调用它的拷贝构造(赋值重载)
如果使用默认生成的默认构造,完成的是浅拷贝,析构时会崩溃~~ 看图

对此我们要实现深拷贝,动态开辟一个空间,实现数据独立
//s2(s1) 拷贝构造
string(const string& s)
:_str(new char[s._capacity+1])
,_size(s._size)
,_capacity(s._capacity)
{
strcpy(_str, s._str);
}
💢3.赋值重载
如果使用默认生成的赋值重载 ,会导致以下问题 ——

我们还是要实现深拷贝,释放旧空间
有些点要注意:
- 上来最好不要直接销毁,有可能自己给自己赋值
s3=s3,导致把自身释放了,所以要判断一下地址是否相同
string& operator=(const string& s)
{
if (this != &s)
{
delete[] _str;
_str = new char[strlen(s._str)];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
return *this;
}
}
- 还有没有可能会new失败呢 ?还没有new成功我们就把_str给释放了,为此我先开一个中转的空间,并且给给
tmp,若开辟成功才释放_str
string& operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
}
💢4.析构函数
前面都是 new[] 开的空间,也要delete[]释放
~string
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
以上均为传统写法,但现在都什么年代?还在用传统写法??
🎨现代写法(资本家)
传统写法就是老老实实,一步一个脚印的开空间、拷贝,现代写法更注重灵活,投机取巧,要对前面比较熟悉才能掌握
🌍1.构造函数 & 析构函数
现代写法多是复用的思维,构造函数 & 析构函数只能老老实实
🌍2.拷贝构造
复用含参构造出tmp(打工人),把tmp和s2身体互换
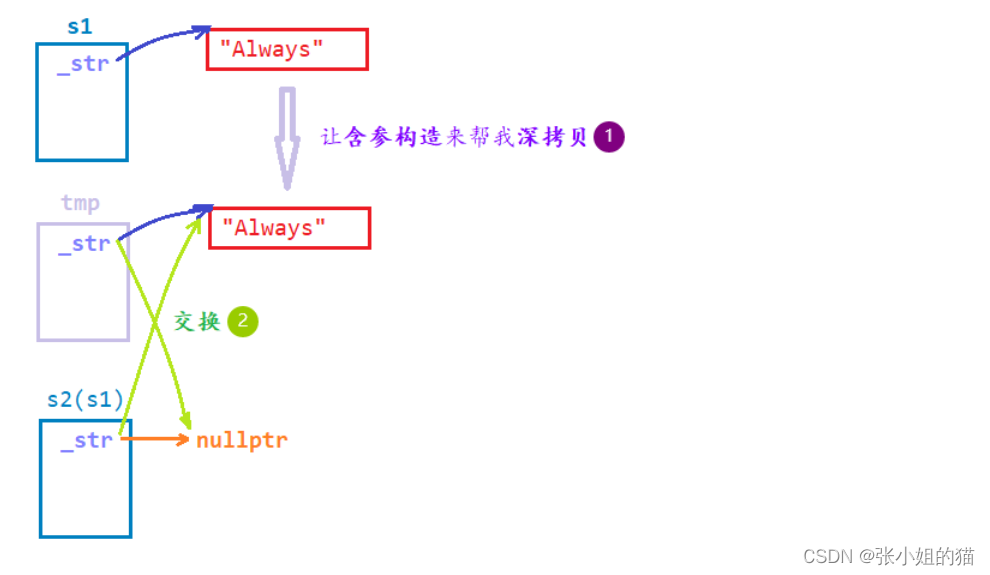
注意s2的_str必须给nullptr,如果不置空,会把随机值传给tmp,tmp是局部变量出作用域时调用析构函数,会崩溃
//现代写法 —— 复用构造 —— 找替死鬼
string(const string& s)
:_str(nullptr)
,_size(0)
,_capacity(0)
{
string tmp(s._str);
swap(tmp);//this -> swap(tmp)
}
🌍3.赋值重载
同样复用拷贝构造进行深拷贝,
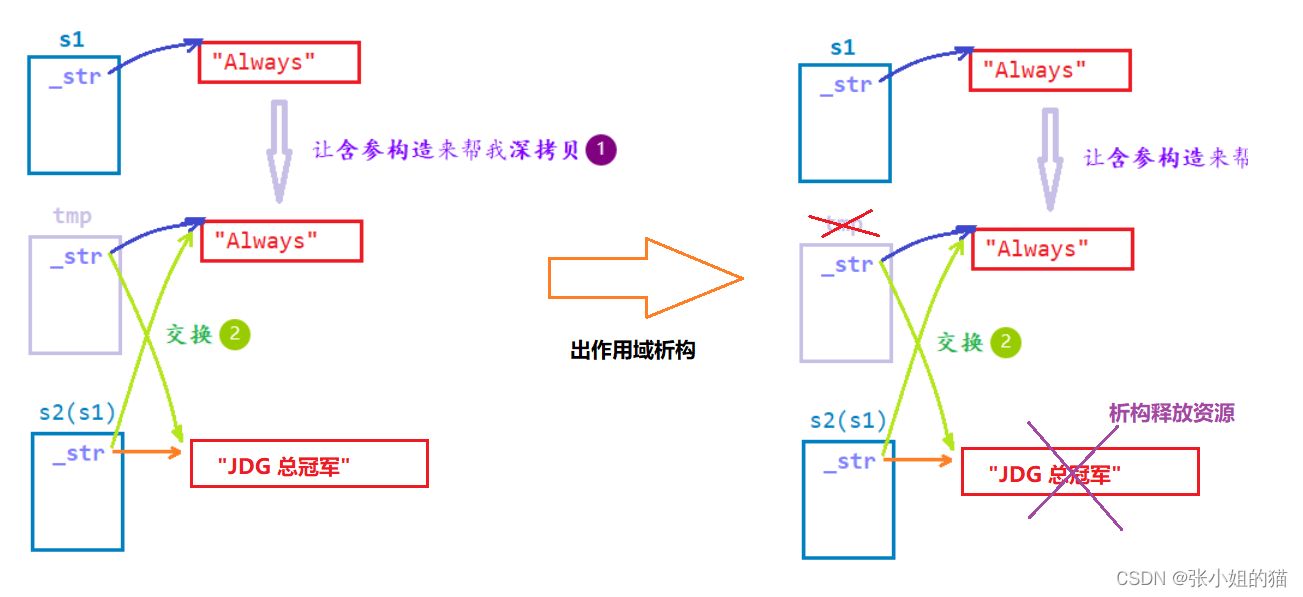
string& operator=(const string& s)
{
if (this != &s)
{
string tmp(s._str);
swap(tmp); //this ->swap(tmp)
return *this;
}
}
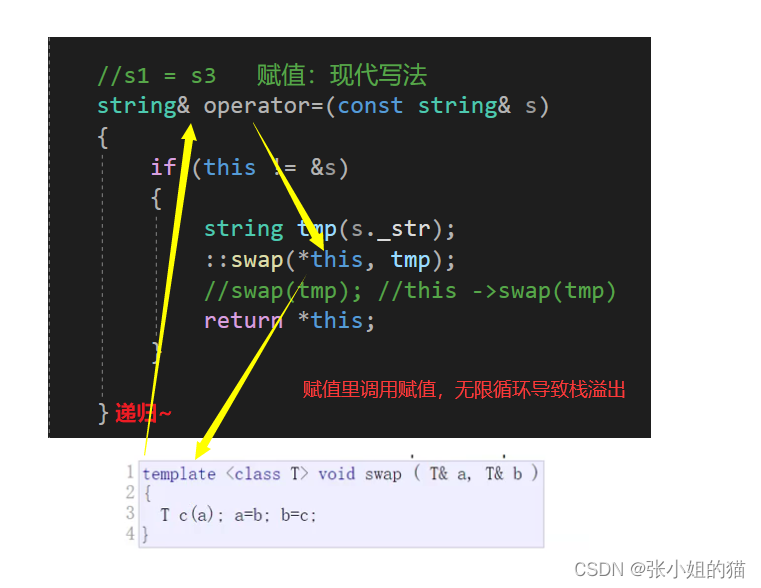
更加剥削的版本:形参s同样是局部变量,出作用域也会调用析构函数 ——
// s1 = s3;
//s传参时顶替tmp当打工人,s就是s3的深拷贝
string& operator=(string s)
{
swap(s);
return *this;
}
🎨swap的区别
string的标准库中提供了一个swap,全局也有一个swap的模板函数(适用于内置类型),底层都是对两个对象的成员进行交换,结果相同,那为什么还要有呢string类中的?
std::string s1("hello");
std::string s2("one and only");
s1.swap(s2);
swap(s1, s2);
注意:二者不构成函数重载!!都不在一个域(函数重载的前提)
string类的中的成员函数仅仅是对对成员函数进行交换,效率高,而全局的swap则进行了三次深拷贝(一次拷贝+两次赋值),空间损耗很大
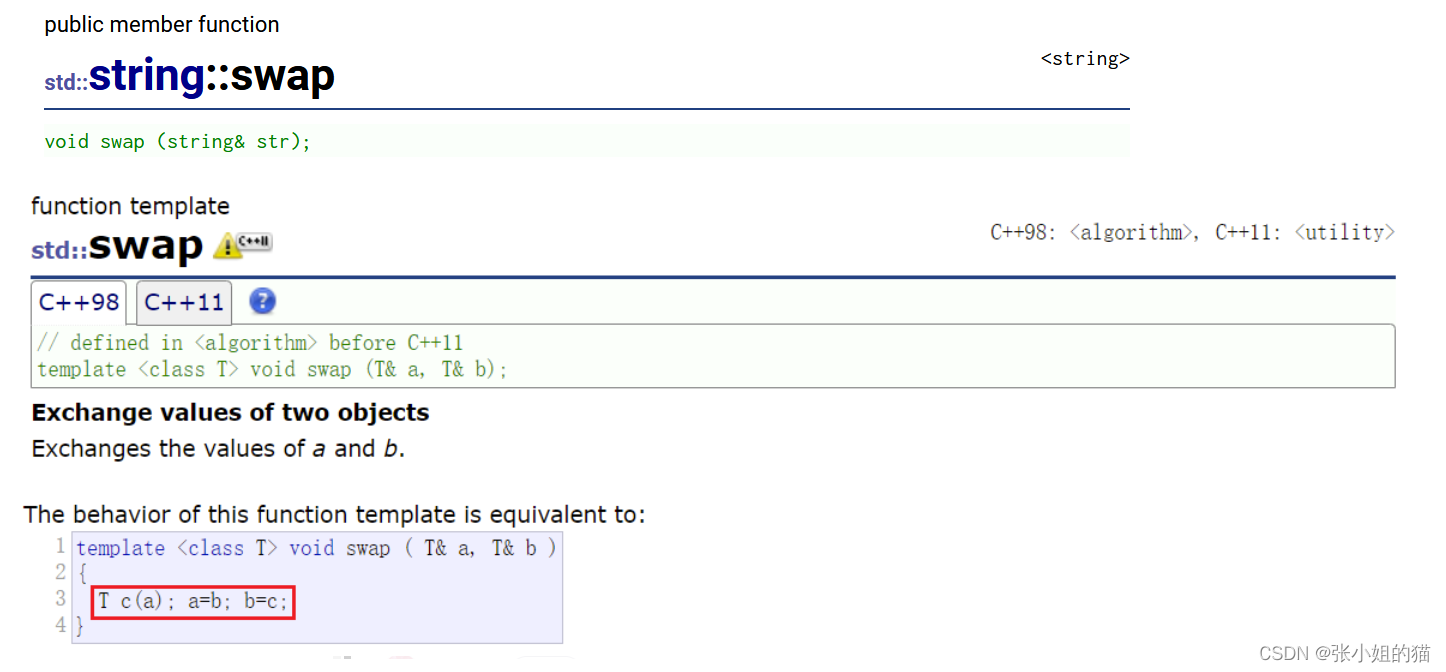
我们要交换三个成员,于是封装了一个swap,为了避免命名冲突,swap中的swap要指定库中的作用域,不然是先从局部开始找,发现参数不匹配就会报错
void swap(string& tmp)
{
std:: swap(_str, tmp._str);
std::swap(_size, tmp._size);
std::swap(_capacity, tmp._capacity);
}
如果在模拟赋值重载时用全局的swap,会发生栈溢出
二. 基本接口
一些常用的接口,实现不难,但要注意小细节
🌈size & capacity
size_t size() const
{
return _size;
}
size_t capacity() const
{
return _capacity;
}
🌈c_str
const char* c_str() const
{
return _str;//解引用找到'\0'
}
🌈[]
//可读可写
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
//const对象提供重载版本 - 可读不可写
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
🌈迭代器
- 普通迭代器
const迭代器:const对象优先调用最匹配的const成员函数,可读不可写

typedef char* iterator;
typedef const char* const _iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const _iterator begin() const
{
return _str;
}
const _iterator end() const
{
return _str + _size;
}
迭代器实现出来了,范围for🍬还会远吗??
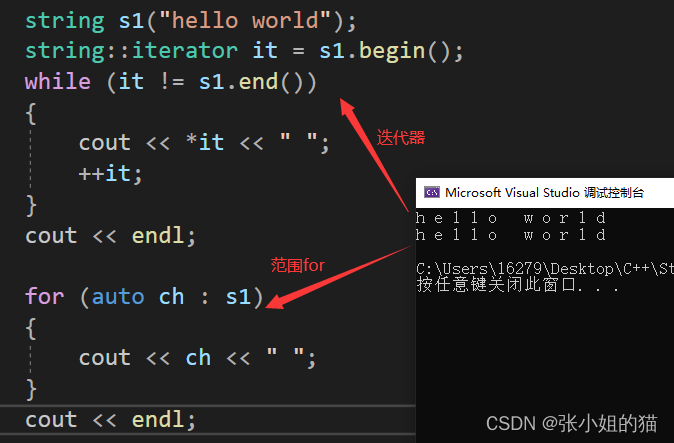
三. 增
⚡reserve & resize
插入字符串要考虑扩容
💦reserve
开新的空间,拷贝过去,释放旧空间
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];//考虑'\0'
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
💦resize
要考虑多种情况

- 插入数据:如果是将元素个数增多,默认用
\0来填充多出的元素空间,也可指定字符来填充 - 删除数据:如果是将元素个数减少,要把多出size的字符抹去
//"helloxxxxxxxxx"
void resize(size_t n, char ch = '\0')
{
if (n > _size)
{
//插入数据
reserve(n);
for (size_t i = _size; i < n; ++i)
{
_str[i] = ch;
}
_str[n] = '\0';
_size = n;
}
else
{
//删除数据
_str[n] = '\0';
_size = n;
}
}
⚡push_back & append
⚡push_back
- 满了就扩容,注意如果
capacity是0的情况要判断一下 - 注意处理
'\0'
void push_back(char ch)
{
//满了就扩容
if (_size = _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
⚡append
不能又一味的开两倍空间,要重新计算串的长度
void append(const char* str)
{
size_t len = strlen(str);
//超了就扩容
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str+_size, str);
_size += len;
}
strcat也能实现,但是每次都要找'\0',效率很低(个人认为是失败的设计)
⚡+=
+= 可插入字符/字符串,复用push_back和append即可
string& operator+= (char ch)
{
push_back(ch);
return *this;
}
string& operator += (const char* str)
{
append(str);
return *this;
}
⚡insert
任意位置的插入,可插入字符\字符串,这里有点绕,要画图理解
🌊插入字符
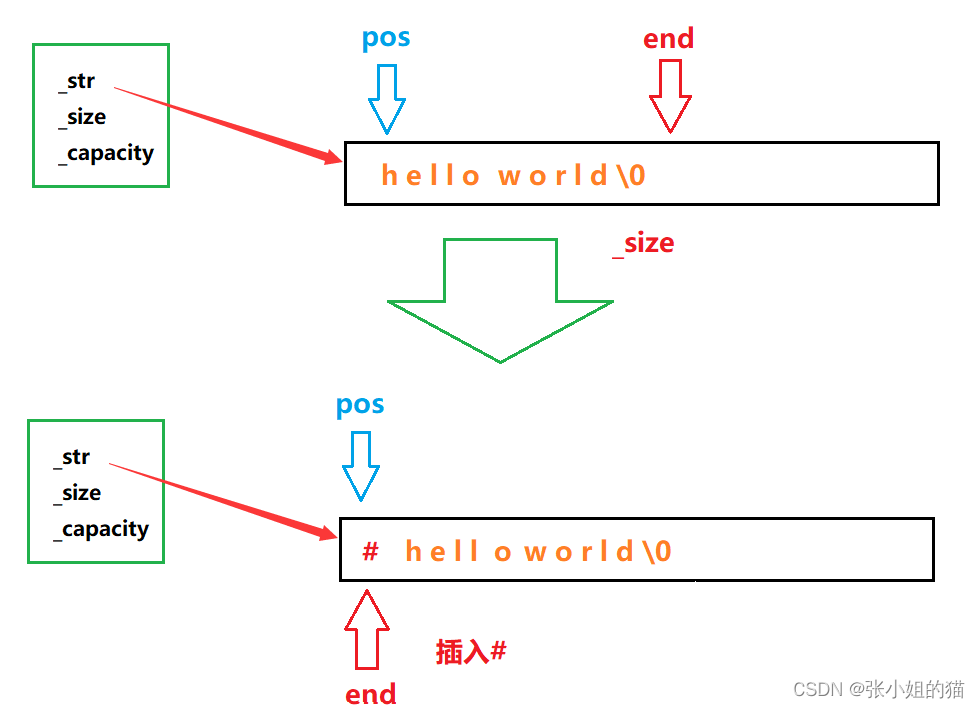
- 此处有一个很经典的越界问题,就是pos=0时,end会减减变成-1(实际上是整数的最大值此处可以对end进行强转:
(int)end,但是pos的类型还是size_t ,会发生整形提升,所以把end=size+1就不但心越界问题了
string& insert(size_t pos, char ch)
{
assert(pos < _size);
//满了就扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4:_capacity * 2);
}
//挪动数据
size_t end = _size+1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
🌊插入字符串
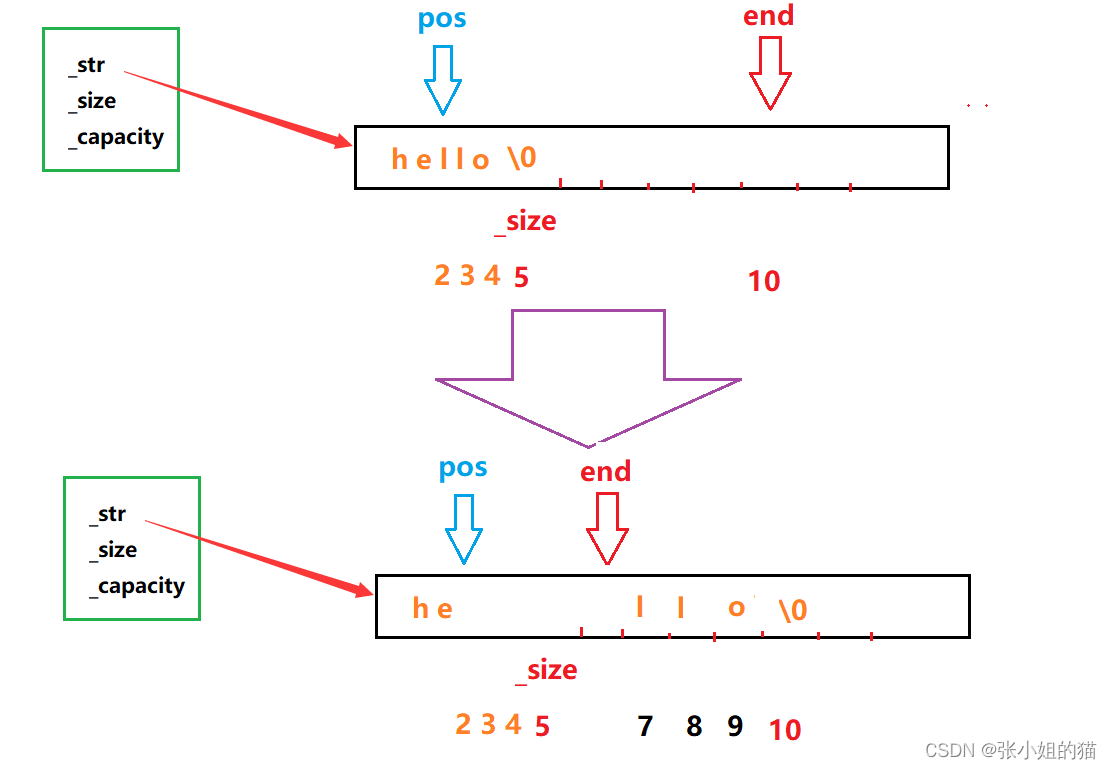
- 把要插入的字符串拷贝过来,但是注意不能拷贝
\0,因此要用strncpy - 有点难理解就要画图
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
//挪动数据
size_t end = _size + len;
while(end >= pos + len)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
四. 删
🌌erase
- npos是string类的静态成员变量,必须在类外的全局定义
size_t string::npos = -1;//类外定义
ps:唯独一个特例:const静态成员变量可以在声明时定义
private:
size_t _size;
size_t _capacity;
char* _str;
//特例:const static 可以在声明时定义
const static size_t npos = -1;//类里声明
情况1️⃣:len足够长,可以删完pos后的
情况2️⃣:删一点点,要挪动数据
void erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
//情况1:不够删
if(len == npos || pos +len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
//删一点点,要挪动数据
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
🌌clear
void clear()
{
_str[0] = '\0';
_size = 0;
}
六、find & substr
💚find
从pos位置开始查找字符或字符串。找到了就返回下标;没找到,返回npos
- 查找字符串复用了
strstr
size_t find(char ch, size_t pos = 0)
{
assert(pos < _size);
size_t i = pos;
for (i = 0; i < _size; ++i)
{
if (ch == _str[i])
{
return i;
}
}
return npos;
}
//"hello world"
size_t find(const char* sub, size_t pos = 0)
{
//strstr
const char* ptr = strstr(_str + pos, sub);
if(ptr == nullptr)
{
return npos;
}
else
{
return ptr - _str;//指针-指针
}
}
💚substr
//"hello world bit" [0, 10},右开减左闭就是真实长度
string substr(size_t pos, size_t len = npos) const
{
assert(pos < _size);
size_t realLen = len;//取真实长度
if (len == npos || pos + len > _size)
{
realLen = _size - pos;
}
string sub;
for (size_t i = 0; i < realLen; ++i)
{
sub +=_str[pos + i];
}
return sub;
}
七、运算符重载
🐋大小运算符的比较
- 任何类的比较大小都只需要实现两个:> ==,其他的复用即可
- 借助了c语言的
strcmp函数,比较ascll码,谁大就谁大,
bool operator>(const string& s) const
{
return strcmp(_str, s._str) > 0;
}
bool operator==(const string& s) const
{
return strcmp(_str, s._str) == 0;
}
bool operator>=(const string& s) const
{
return *this > s || *this == s;
}
bool operator<=(const string& s) const
{
return !(*this > s);
}
bool operator<(const string& s) const
{
return !(*this >= s);
}
bool operator!=(const string& s) const
{
return !(*this == s);
}
🐋 >> & <<
流插入&流提取因为流对象和对象抢占左操作数的位置所以必须重载成全局。但不一定是友元吗?关键看是否需要访问私有成员
🔥输出<<
- 遍历输出
- 不能
out << s.c_str() << endl,这样关注的就是'\0',而我们的要关注的是_size
ostream& operator<<(ostream& out, const string& s)
{
for (size_t i = 0; i < s.size(); ++i)
{
out << s[i];
}
return out;
}
🔥输入>>
- cin的特性和scanf一样,编译器以为是分隔符,是获取不到
' '和'\0',会被忽略掉 get函数登场:一个一个字符地读取- 不论s中是否有字符串,其实输入再打印是不会打出来的,需要先
clear清除所有数据
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch;
//in >> ch;
ch = in.get();
while (ch != ' ' && ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}
如果输入内容很长,不断+=,会频繁扩容,导致效率很低,怎么样优化呢?
- 开辟一个数组,缓冲区思路
//优化后
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch;
ch = in.get();
const size_t N = 32;
char buff[N];
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == N - 1)
{
buff[i] = '\0';
s += buff;
i = 0;//轮回
}
ch = in.get();
}
buff[i] = '\0';//不等于空格或者换行也要补'\0'
s += buff;
return in;
}
附源码:string.h & test.c
完整代码:现代写法+主要实现
String.h
#pragma once
#include<iostream>
#include<assert.h>
#include<string>
//为了和库里的string进行区分
namespace bit
{
class string
{
public:
//为什么不能给指针呢? c_str 解引用会出错
//string()
// : _str(nullptr)
// , _size(0)
// , _capacity(0)
//{}
//全缺省
//string(const char* str = "\0")
//不推荐
//string(const char* str= "")
// :_size(strlen(str))
// , _capacity(_size)
// ,_str(new char[_capacity + 1])
//{
// strcpy(_str, str);
//}
//string(const char* str)
// :_str(new char[strlen(str) + 1])//多开一个空间
// , _size(strlen(str))
// , _capacity(strlen(str))
//{
// strcpy(_str, str);
//}
//构造
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
//s2(s1) 拷贝构造
string(const string& s)
:_str(new char[s._capacity+1])
,_size(s._size)
,_capacity(s._capacity)
{
strcpy(_str, s._str);
}
// s1 = s3
//string& operator=(const string& s)
//{
// if (this != &s)
// {
// delete[] _str;
// _str = new char[strlen(s._str)];
// strcpy(_str, s._str);
// _size = s._size;
// _capacity = s._capacity;
// return *this;
// }
//}
//传统写法:优化后
//string& operator=(const string& s)
//{
// if (this != &s)
// {
// char* tmp = new char[s._capacity + 1];
// strcpy(tmp, s._str);
// delete[] _str;
// _str = tmp;
// _size = s._size;
// _capacity = s._capacity;
// }
//}
//现代写法:—————— 资本家思维
//s2(s1)
//string(const string& s)
// :_str(nullptr)
// ,_size(0)
// ,_capacity(0)
//{
// string tmp(s._str);
// swap(tmp);//this -> swap(tmp)
//}
void swap(string& tmp)
{
::swap(_str, tmp._str);
::swap(_size, tmp._size);
::swap(_capacity, tmp._capacity);
}
s1 = s3 赋值:现代写法
//string& operator=(const string& s)
//{
// if (this != &s)
// {
// string tmp(s);
// ::swap(*this, tmp);
// //swap(tmp); //this ->swap(tmp)
// return *this;
// }
//}
//最简洁
string& operator=(string s)
{
swap(s);
return *this;
}
//析构
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
//c_str
const char* c_str() const
{
return _str;//解引用找到'\0'
}
//size
size_t size() const
{
return _size;
}
//capacity
size_t capacity() const
{
return _capacity;
}
//[]
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
//const对象
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
//迭代器
typedef char* iterator;
typedef const char* const _iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const _iterator begin() const
{
return _str;
}
const _iterator end() const
{
return _str;
}
//保留
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];//考虑'\0'
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
//"helloxxxxxxxxx"
void resize(size_t n, char ch = '\0')
{
if (n > _size)
{
//插入数据
reserve(n);
for (size_t i = _size; i < n; ++i)
{
_str[i] = ch;
}
_str[n] = '\0';
_size = n;
}
else
{
//删除数据
_str[n] = '\0';
_size = n;
}
}
void push_back(char ch)
{
//满了就扩容
if (_size = _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
//insert(_size , ch);
}
void append(const char* str)
{
size_t len = strlen(str);
//超了就扩容
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str+_size, str);
_size += len;
//insert(_size, str);
}
string& operator+= (char ch)
{
push_back(ch);
return *this;
}
string& operator += (const char* str)
{
append(str);
return *this;
}
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
//满了就扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4:_capacity * 2);
}
//挪动数据
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
//挪动数据
size_t end = _size + len;
while (end >= pos + len)
{
_str[end] = _str[end - len];
--end;
}
strncpy( _str + pos, str, len);
_size += len;
return *this;
}
void erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
//情况1:不够删
if(len == npos || pos +len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
void clear()
{
_str[0] = '\0';
_size = 0;
}
size_t find(char ch, size_t pos = 0)
{
assert(pos < _size);
size_t i = pos;
for (i = 0; i < _size; ++i)
{
if (ch == _str[i])
{
return i;
}
}
return npos;
}
//"hello world"
size_t find(const char* sub, size_t pos = 0)
{
//strstr
const char* ptr = strstr(_str + pos, sub);
if(ptr == nullptr)
{
return npos;
}
else
{
return ptr - _str;
}
}
//"hello world bit" [0, 10},右开减左闭就是真实长度
string substr(size_t pos, size_t len = npos) const
{
assert(pos < _size);
size_t realLen = len;//取真实长度
if (len == npos || pos + len > _size)
{
realLen = _size - pos;
}
string sub;
for (size_t i = 0; i < realLen; ++i)
{
sub +=_str[pos + i];
}
return sub;
}
bool operator>(const string& s) const
{
return strcmp(_str, s._str) > 0;
}
bool operator==(const string& s) const
{
return strcmp(_str, s._str) == 0;
}
bool operator>=(const string& s) const
{
return *this > s || *this == s;
}
bool operator<=(const string& s) const
{
return !(*this > s);
}
bool operator<(const string& s) const
{
return !(*this >= s);
}
bool operator!=(const string& s) const
{
return !(*this == s);
}
private:
size_t _size;
size_t _capacity;
char* _str;
public:
//特例:const static 可以在声明时 可以定义
const static size_t npos = -1;//类里声明
};
//size_t string::npos = -1;//类外定义
//注意流插入不一定是友元,没有访问私有成员函数
ostream& operator<<(ostream& out, const string& s)
{
for (size_t i = 0; i < s.size(); ++i)
{
out << s[i];
}
return out;
}
//istream& operator>>(istream& in, string& s)
//{
// //输入内容很长,不断+=,会频繁扩容,效率很低
// char ch;
// //in >> ch;
// ch = in.get();
// while (ch != ' ' && ch != '\n')
// {
// s += ch;
// ch = in.get();
// }
// return in;
//}
//优化后
istream& operator>>(istream& in, string& s)
{
char ch;
ch = in.get();
const size_t N = 32;
char buff[N];
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == N - 1)
{
buff[i] = '\0';
s += buff;
i = 0;//轮回
}
ch = in.get();
}
buff[i] = '\0';
s += buff;
return in;
}
//测试流插入流提取运算符重载
void testString7()
{
//string s;
string s("Always");
cin >> s;
cout << s << endl;
// 不能以字符串形式输出,测试标准库
string s1("more than");
s1 += '\0';
s1 += "words";
cout << s1 << endl;
cout << s1.c_str() << endl;
}
// 测试比较大小运算符重载
void testString6()
{
string s1("abcd");
string s2("abcd");
cout << (s1 <= s2) << endl;
string s3("abcd");
string s4("abcde");
cout << (s3 <= s4) << endl;
string s5("abcde");
string s6("abcd");
cout << (s5 <= s6) << endl;
}
// 测试insert和erase
void testString5()
{
string s(" lumos maxima");
s.insert(0, "lumos");
cout << s.c_str() << endl;
s.insert(5, '!');
cout << s.c_str() << endl;
s.erase(0, 7);
cout << s.c_str() << endl;
s.erase(6);
cout << s.c_str() << endl;
}
// 测试查找
void testString4()
{
string s("lumos maxima");
cout << s.find('m') << endl;
cout << s.find("max") << endl;
}
// 测试resize
void testString3()
{
string s("lumos maxima"); // capacity - 12
s.resize(5);
cout << s.c_str() << endl;
s.resize(7, '!');
cout << s.c_str() << endl;
s.resize(20, '~');
cout << s.c_str() << endl;
}
// 测试尾插字符及字符串push_back/append,同时测试reserve
void testString2()
{
string s("more than words");
s.push_back('~');
s.push_back(' ');
cout << s.c_str() << endl;
s.append("is all you have to do to make it real");
cout << s.c_str() << endl;
s += '~';
s += "then you wouldn't have to say that you love me, cause I'd already know";
cout << s.c_str() << endl;
}
// 测试现代写法的成员函数
void testString1()
{
string s0;
string s1("Always");
string s2(s1);
cout << s2.c_str() << endl;
string s3("more than words");
s3 = s1;
cout << s3.c_str() << endl;
s3 = s3;
}
}
test.c
#include<iostream>
#include<string>
using namespace std;
#include "string.h"
int main()
{
try
{
bit::testString1();
//bit::testString2();
//bit::testString3();
//bit::testString4();
//bit::testString5();
//bit::testString6();
}
catch (const exception& e)
{
cout << e.what() << endl;
}
return 0;
}
😀说在最后
JDG加油