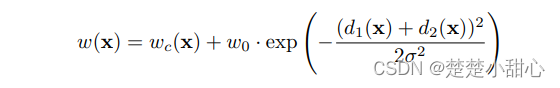至此篇,已经完成高级生产应用,至此只剩“码需求”了。
开篇
Watermark这一块国内中文相关资料没有一篇是写完整或者写对的。源于:官网的watermark理论是对的,中文相关博客的代码和公式是错的。
很有可能是写第一篇Watermark中文博客者的手敲错了一个符号或者是根本没有理解或者上过生产环境给到了业界以误导!
因此我们结合实际生产环境,做了一个现实例子,以纠正这个犯了近4年的错误同时补足国内这一块知识的空白。
不提高深的原理先看生产需求
我们按照一个人的正常思维模式,一定是先要有:感性认识再到理性认识的指导方法论来说,先要让程序员的眼睛看得到一样东西它是怎么跑的、一步步如何分解出来结果才能有“总结”,因此我把Watermark那些晦涩难懂看似高大上的理论放在最后。先从实际生产环境需求入手说这个问题。
需求
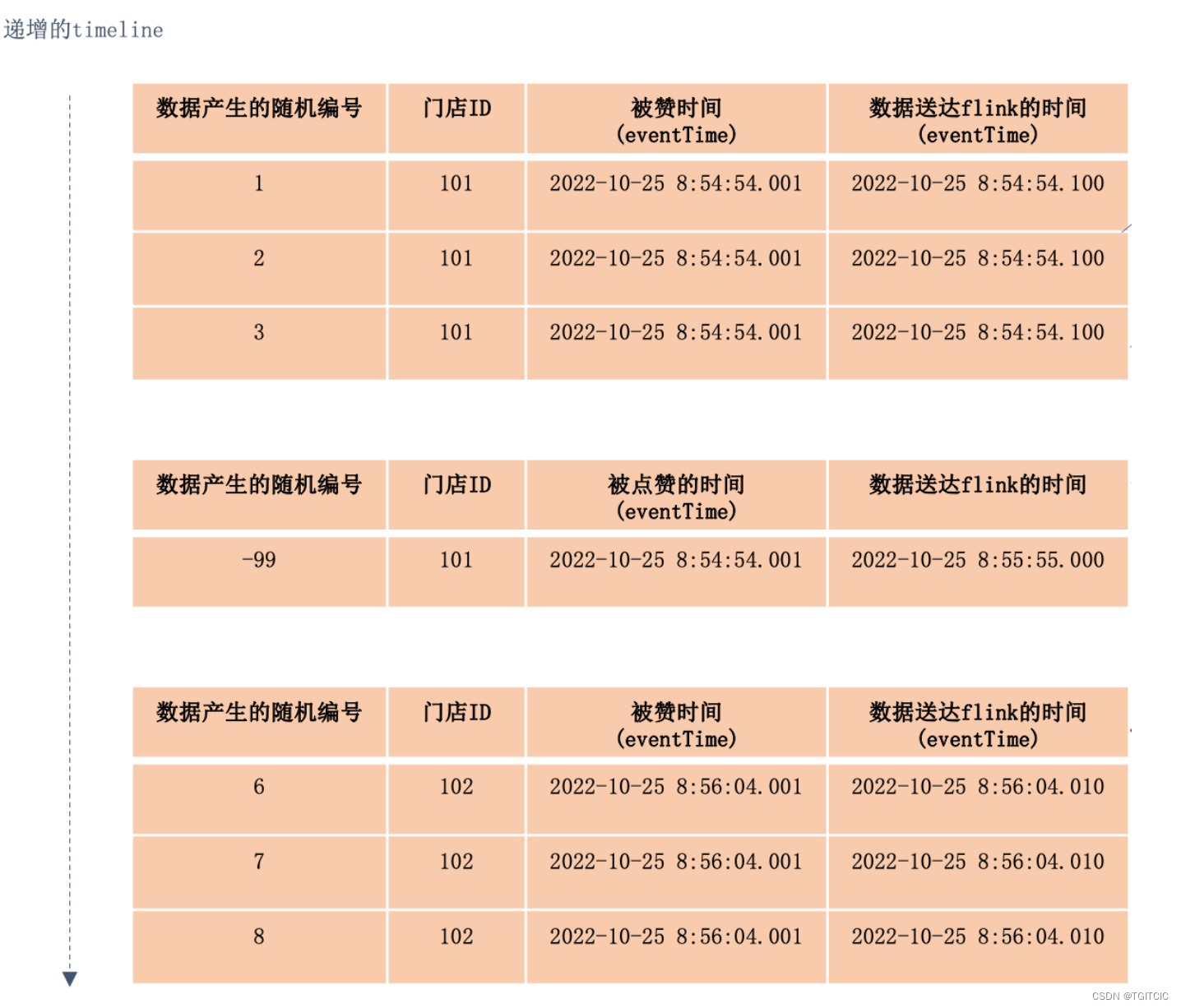
我们有数据是按照如下情况到达我们的Flink需要做“基于时间窗口的聚合”。但是往往实际生产环境会出现“生成数据的时间是对的,到达FLINK或者下游的时间上有偏差”的情况,如下所示:
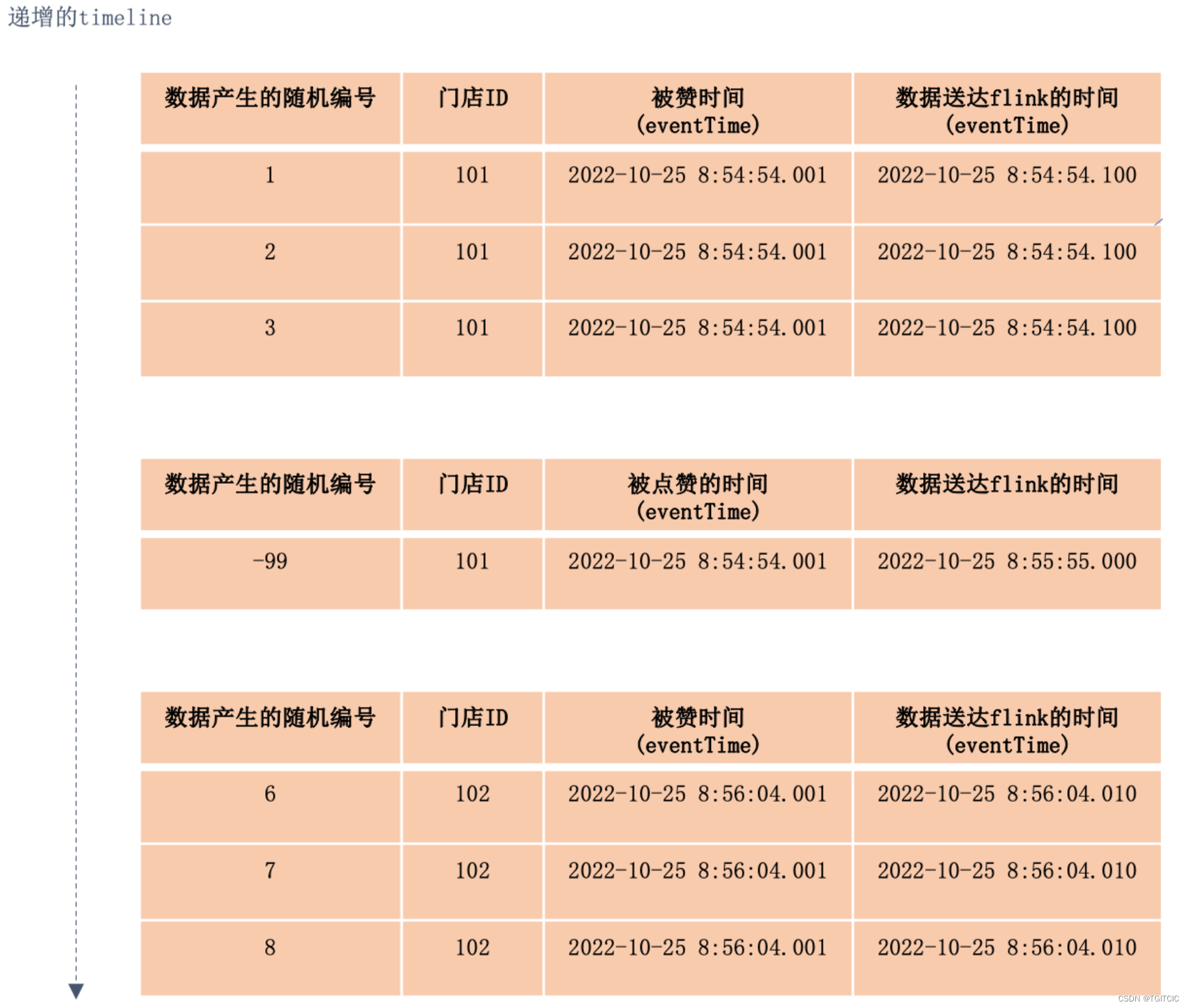
这是一个门店点赞排行榜,业务需要按照门店ID归并在同一个时间内被点赞的集合。
于是从系统上看:
- 我们可以看到用户在前端APP或者是小程序去点这个“赞👍”的时间即:eventTime分为“两批”,2022-10-25 8:54:54..001秒实际有4条数据,只是随机数据编号-99这一条数据比前3条101门店晚到了6秒钟送到flink(这个晚到是经常的,因为在做数据类型转换或者是网络波动情况下势必发生)。
- 第二批数据被点赞👍的时间即:eventTime为一批,共计3条数据,于2022-10-25 8:56:04.001秒被触发,于2022-10-25 8:56:04.010被送到Flink。
业务需求:是把这3波数据合并成:
- 2022-10-25 8:54:54.000时可以看到:101门店,被点赞👍了(4)次;
- 2022-10-25 8:55:59.000时可以看到:102门店,被点赞👍了(3)次;
然后每隔5秒,每个门店的点赞次数按照数据到达的窗口进行滚动的显示。
按照需求进行设计开发
从系统角度看这3波数据要按照“业务需要按照门店ID归并在同一个时间内被点赞的集合”,实际数据呢它是有延迟即:乱序到达。于是很多程序员一拍脑袋,哦。。。用Flink的Watermark不是就可以解决了吗?
对!
是用Watermark来解决上述的问题,而且flink的Watermark分成:
- 自带Watermark生成器,适用于大都简单场景;
- 自定义eventTime生成Watermark;
我们一看第2点,不错,这个“自定义eventTime生成Watermark“,不正是我们需要的吗?好。。。开始编码了,于是我们这样来开发这个代码,网上全是这个代码,所有的中文网站甚至连官网都是这个代码,各位看一下,是不是!我先告诉你们:是错的。
注意一(高度重要,敲黑板了):
- 如果要用Watermark,你必须在flink里使用“TumblingEventTimeWindows.of(Time.seconds(窗口多久一刷新))”这个窗口,TumblingEventTimeWindows就是和Watermark连在一起使用的,这边的Event指的就是Watermark的到达触发了这个Window。
注意二(高度重要,敲黑板了):
官网的原话对于:Watermark触发TumblingEventTimeWindow需要满足的条件(是对的,错不在官网错在所有中文博客博主没有理解或者是一时手误导致了这个长达近4年的错误信息的传导上):
- watermark>窗口结束时间;
- 并且窗口内有数据到达;
以上两点都满足的情况下,会触发TumblingEventTimeWindow进行一次计算。
于是我们来看截止这篇博客网上所有的著名的错的解决方案
错误的解决方案的代码
long windowInterval = 5000L;
SerializableTimestampAssigner<StoreRanking> timestampAssigner = new SerializableTimestampAssigner<StoreRanking>() {
@Override
public long extractTimestamp(StoreRanking element, long recordTimestamp) {
long watermarkTime = element.getEventTime()*1000L; //因为我们的Watermark是用秒来打的因此要把毫秒变成秒否则窗口连一次都不会被触发
}
};
KafkaSource<StoreRanking> source = KafkaSource.<StoreRanking>builder()
.setBootstrapServers(paras.get("kafka.bootstrapservers")).setTopics(paras.get("kafka.topic"))
.setGroupId("test01").setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new StoreRankingJSONDeSerializer())).build();
DataStream<StoreRanking> kafkaDS = env
.fromSource(source,
WatermarkStrategy.<StoreRanking>forBoundedOutOfOrderness(Duration.ofSeconds(windowInterval))
.withTimestampAssigner(timestampAssigner).withIdleness(Duration.ofSeconds(5)),
"Kafka Source");
DataStream<Tuple2<String, Integer>> ds = kafkaDS
.flatMap(new FlatMapFunction<StoreRanking, Tuple2<String, Integer>>() {
public void flatMap(StoreRanking store, Collector<Tuple2<String, Integer>> collector)
throws Exception {
StoreRanking s = new StoreRanking();
s.setStoreId(store.getStoreId());
s.setStoreNo(store.getStoreNo());
s.setEventTime(store.getEventTime());
logger.info(">>>>>>storeNo->" + store.getStoreNo() + " storeId->" + store.getStoreId());
collector.collect(new Tuple2<String, Integer>(store.getStoreId(), 1));
}
});
ds.keyBy(value -> value.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))).sum(1).print();
env.execute();以上代码很简单,根据一个传入的Bean:StoreRanking中的eventTime(被点赞👍)时间以及门店ID进行归并:
package org.mk.demo.flink;
import java.io.Serializable;
public class StoreRanking implements Serializable {
public StoreRanking() {
}
public StoreRanking(String storeId, long eventTime) {
this.storeId = storeId;
this.eventTime = eventTime;
}
long eventTime = 0;
String storeId = "";
int storeNo = 0;
public int getStoreNo() {
return storeNo;
}
public void setStoreNo(int storeNo) {
this.storeNo = storeNo;
}
public long getEventTime() {
return eventTime;
}
public void setEventTime(long eventTime) {
this.eventTime = eventTime;
}
public String getStoreId() {
return storeId;
}
public void setStoreId(String storeId) {
this.storeId = storeId;
}
}样就可以把8:54:84.100秒这3条和8:55:55.000秒这一条组合在一起变成4条一起做一次归并计算,以得到:101门店被点赞👍了4次:
而实际代码运行后,99%的人没有发觉这个问题:是因为测试时用的数据是“流式”的、源源不断的、像Matrix里的黑屏绿字那样不断“滚动”着,因此看不出其中的细微差别。因此我们先把这4条包括-99延迟数据做成一批往Flink送进去,我们来看发生了什么事:
模拟kafka送数据
// 发3条数据
for (int i = 0; i < 3; i++) {
StoreRanking stores = new StoreRanking("101", ascendingEventTime);
stores.setStoreNo(i + 1);
storeRankingKafka.send(TOPIC, stores);
Thread.sleep(50);
}
// 发一条:延时数据
Thread.sleep(4000);
StoreRanking delayStore = new StoreRanking("101", ascendingEventTime);
delayStore.setStoreNo(-99);
storeRankingKafka.send(TOPIC, delayStore);送过去后flink端的显示

嘿嘿嘿嘿嘿!
前面一共发了两波,第一波准时到达第二波延时到达但是在逻辑上第一波和第二波应该归并成一波数据。
然后我们送第三波数据,即:门店编号102的数据有三条
public void sendStoreRankingWithTimestamp() {
long ascendingEventTime = System.currentTimeMillis();
try {
// 发5条数据
for (int i = 0; i < 3; i++) {
StoreRanking stores = new StoreRanking("102", ascendingEventTime);
stores.setStoreNo(i + 1);
storeRankingKafka.send(TOPIC, stores);
Thread.sleep(50);
}
//Thread.sleep(4000);
// 发一条:延时数据
//StoreRanking delayStore = new StoreRanking("101", ascendingEventTime);
//delayStore.setStoreNo(-99);
//storeRankingKafka.send(TOPIC, delayStore);
} catch (Exception e) {
logger.error(">>>>>>sendStoreRankingWithTimestamp error: " + e.getMessage(), e);
}
} 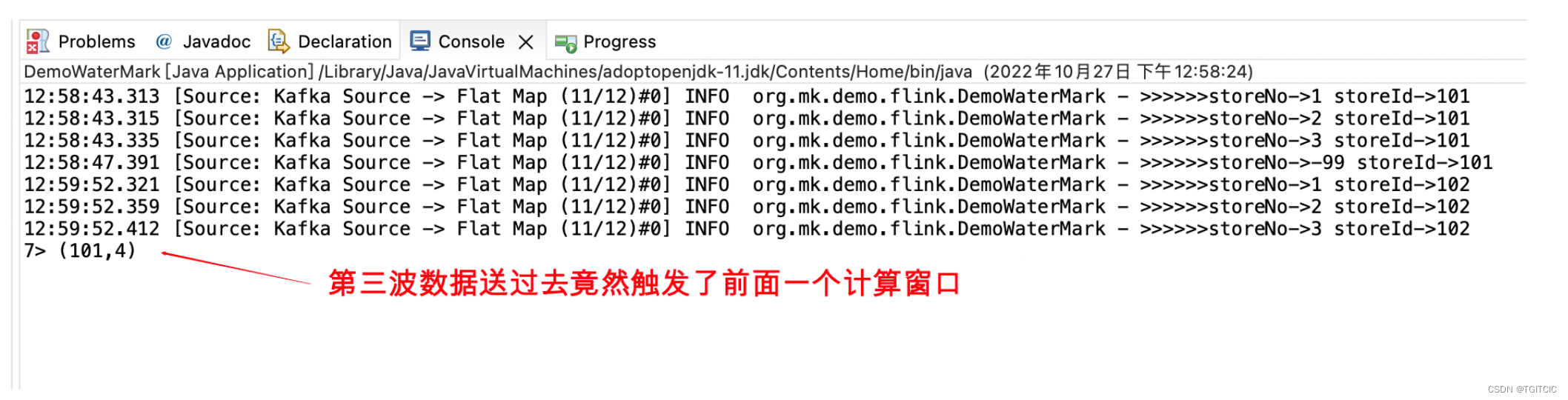
咦,102号门店没有被计算,但计算了前面那个101号门店的归并计算了,4条,没错!因为我们按照eventTime如果一致就算一批。
于是我们等了10多分钟,看看网上说的withIdleness也设上了,可是窗口没有在我们设想的等5秒钟应该自动再触发一下完成102门店的点赞计算呀。
env.fromSource(source,
WatermarkStrategy.<StoreRanking>forBoundedOutOfOrderness(Duration.ofSeconds(windowInterval))
.withTimestampAssigner(timestampAssigner).withIdleness(Duration.ofSeconds(5)),
"Kafka Source");我们再送一批数据,103号门店的数据同样按照102号门店那样送过去。
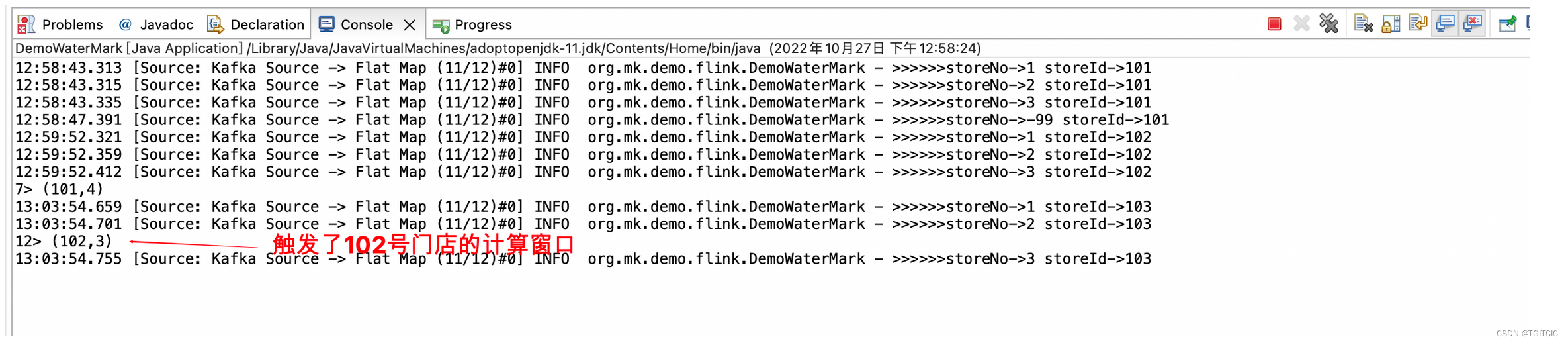
我们发觉103号门店送过去却触发了102号门店的这个计算窗口。此时更夸张的事开始来了。。。生产上103号门店是最后一批数据后续没有数据再送过来了,然后。。。103号门店的这一批本来应该有3条被点赞👍的结果就永远等不到了。卡死了!
于是网上又出现了很多千篇一律的”使用自定义Watermark解决最后一个窗口数据的问题“,代码是长这样的(我这边给的代码是能用的而这一块目前网上的代码竟然没有一个可以用只有理念对了,我自己根据1.15.2版纠正了一堆错误)。但我这边先告诉大家,写完了依旧没有用。
注意(高度注意,敲黑板了):
这一块代码也没有错,错误的原因我会在文章下面部分会给出。
没有错的原因是:因为这的确是属于”最后一个窗口“并且再也没有后续数据到达了,因此此时如果你不自动给它一个”定时触发“去生成这个Watermark,因此我们需要使用自定义Watermark里的:public void onPeriodicEmit(WatermarkOutput watermarkOutput) 不断的去贴合着窗口内的endtime,以使得Watermark可以贴合着Watermark公式:Watermark必须>窗口endtime。否则就永无法不会触发窗口计算。
long windowInterval = 5000L;
SerializableTimestampAssigner<StoreRanking> timestampAssigner = new SerializableTimestampAssigner<StoreRanking>() {
@Override
public long extractTimestamp(StoreRanking element, long recordTimestamp) {
return element.getEventTime()*1000L;
}
};
KafkaSource<StoreRanking> source = KafkaSource.<StoreRanking>builder()
.setBootstrapServers(paras.get("kafka.bootstrapservers")).setTopics(paras.get("kafka.topic"))
.setGroupId("test01").setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new StoreRankingJSONDeSerializer())).build();
DataStream<StoreRanking> kafkaDS = env
.fromSource(source,
WatermarkStrategy.<StoreRanking>forBoundedOutOfOrderness(Duration.ofSeconds(windowInterval))
.withTimestampAssigner(timestampAssigner).withIdleness(Duration.ofSeconds(5)),
"Kafka Source");
DataStream watermarkDS = kafkaDS.assignTimestampsAndWatermarks(new WatermarkStrategy<StoreRanking>() {
private final long maxOutOfOrderness = windowInterval;
private long currentMaxTimestamp = System.currentTimeMillis() + 1000l;
@Override
public WatermarkGenerator<StoreRanking> createWatermarkGenerator(
WatermarkGeneratorSupplier.Context context) {
return new WatermarkGenerator<StoreRanking>() {
@Override
public void onEvent(StoreRanking event, long l, WatermarkOutput watermarkOutput) {
logger.info(">>>>>>onEvent->" + event.getStoreId() + " " + event.getStoreNo());
currentMaxTimestamp = Math.max(currentMaxTimestamp, event.getEventTime());
Date dt1 = new Date(currentMaxTimestamp);
SimpleDateFormat sd = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String currentMaxTimeStr = sd.format(dt1);
Date dt2 = new Date(event.getEventTime());
String eventTimeStr = sd.format(dt2);
logger.info(">>>>>>onEvent currentMaxTimestamp->" + currentMaxTimeStr + " eventTimeStr->"
+ eventTimeStr);
}
@Override
public void onPeriodicEmit(WatermarkOutput watermarkOutput) {
Date dt = new Date(currentMaxTimestamp);
SimpleDateFormat sd = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String timeStr = sd.format(dt);
// logger.info(">>>>>>onPeriodicEmit currentMaxTimestamp->" + timeStr +
// "maxOutOfOrderness->"
// + maxOutOfOrderness);
long newWatermarkTime = (currentMaxTimestamp - maxOutOfOrderness - 1) * 1000L;
watermarkOutput.emitWatermark(new Watermark((System.currentTimeMillis() + 100) * 1000L));
}
};
}
});
DataStream<Tuple2<String, Integer>> ds = watermarkDS
.flatMap(new FlatMapFunction<StoreRanking, Tuple2<String, Integer>>() {
public void flatMap(StoreRanking store, Collector<Tuple2<String, Integer>> collector)
throws Exception {
StoreRanking s = new StoreRanking();
s.setStoreId(store.getStoreId());
s.setStoreNo(store.getStoreNo());
s.setEventTime(store.getEventTime());
logger.info(">>>>>>storeNo->" + store.getStoreNo() + " storeId->" + store.getStoreId());
collector.collect(new Tuple2<String, Integer>(store.getStoreId(), 1));
}
});
ds.keyBy(value -> value.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))).sum(1).print();
env.execute();然后运行后这次就算第二波、第三波数据被不断的送到flink这,然而其结果却变成了一直不触发窗口进行计算了。这个搞得更大了!
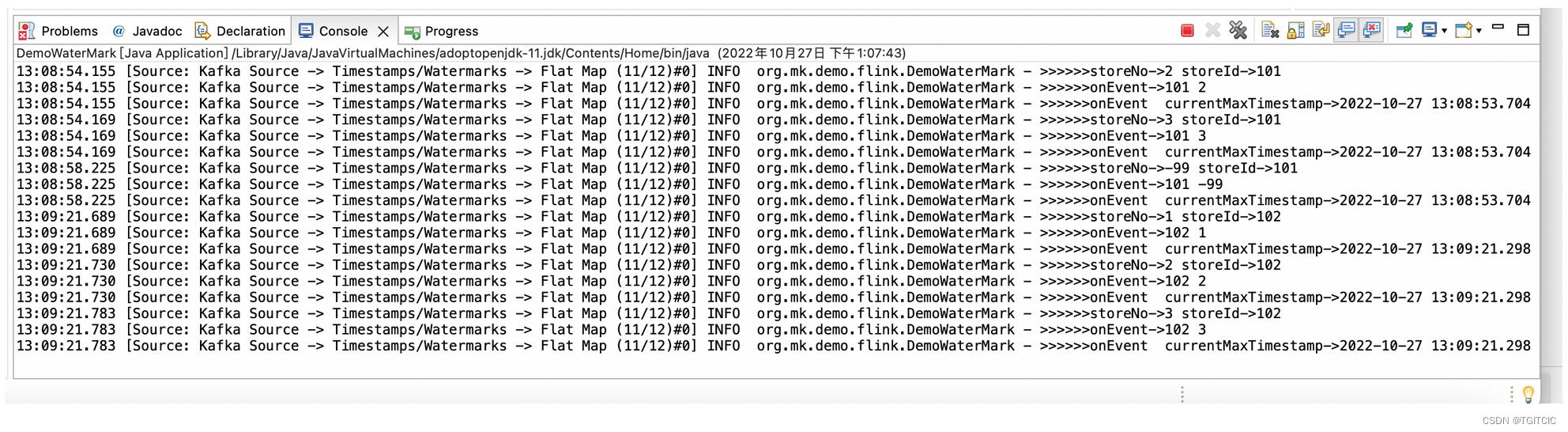
不要急一起来分析问题
我们把3批数据的“被点赞👍”时间、送达flink的时间、窗口的计算时间全部用图画出来。表示成如下这样的一张图。
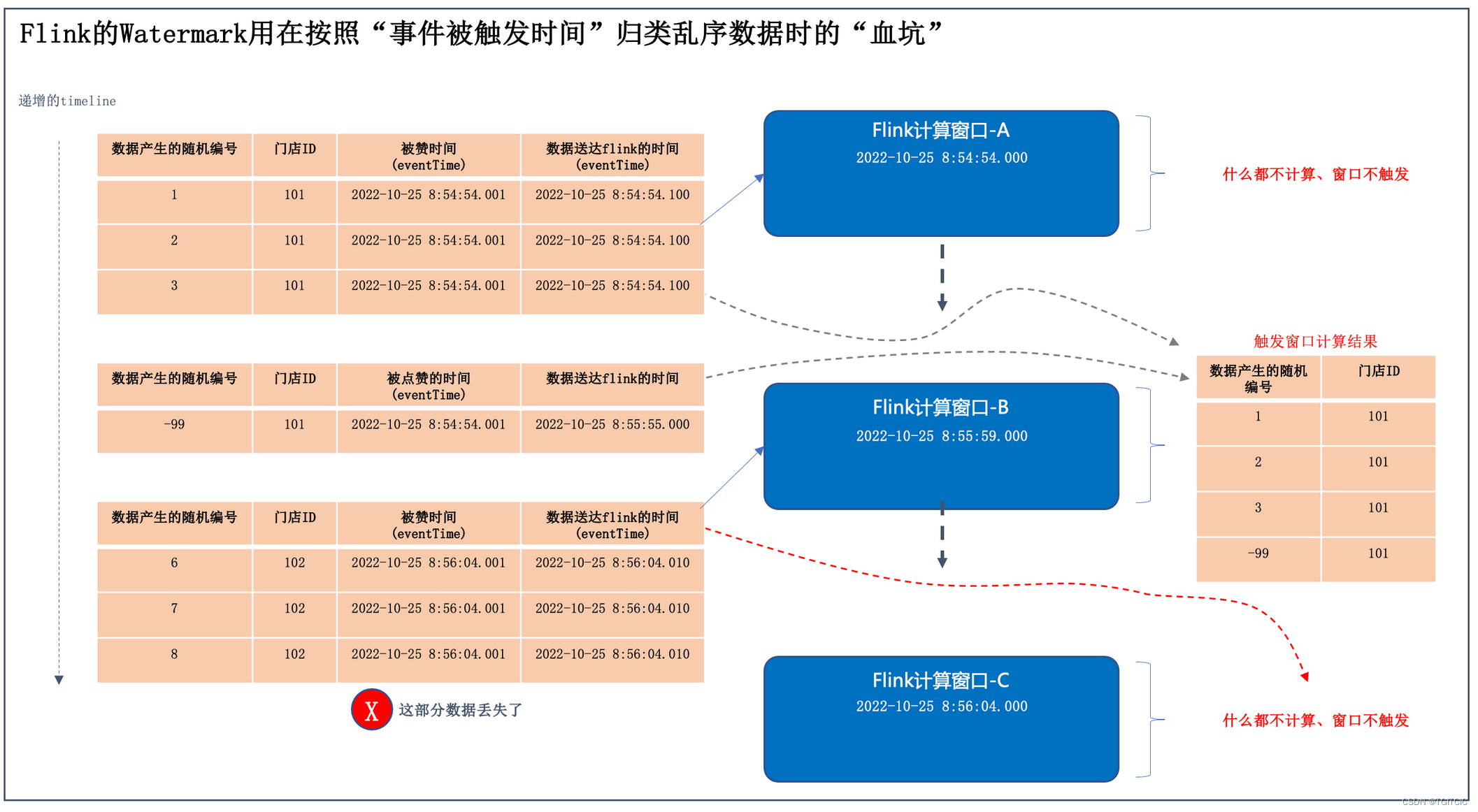
看着这个图我们同时来看flink官网的对于Watermark的理论公式,公式有两个点,这两个点满足那么窗口才会被触发
- Watermark的时间>窗口的endtime;
- 并且在这段窗口内要有数据;
所以网上所有资料的问题在于两个层次递进的发生的:
- 第一块代码里,我们没上自定义watermark时由于我们使用了“业务触发时间”去做的Watermark以满足按照时间+门店ID做归并的业务需求,因此数据到达flink时,造成了这个被我们打上的Watermark永远<了窗口的endtime,因此导致了,只有当下一批数据送到并且下一批的数据的eventTime(就是Watermark)>了当前flink的窗口时,才被触发了上一个窗口内的计算,因此才会出现送101店过去不显示计算结果,再送102店过去才触发了101门店的结果即:下一批数据触发了前一批数据的计算窗口;
- 第二块代码里,我们虽然正确做了自定义Watermark(这块代码网上都没有,理论是有的或者只有<flink 1.12版之前的代码),但是这个emit发出的Watermark始终<了我们的窗口的end time并且又由于第一块代码里的错误导致了连一次窗口都不会被触发;
以上两点就是全部错误的原因,按照上文中所叙述,错误不在第二块代码因此第二块代码我们保留,而实际错在第一块代码,错在哪?喏,在下面:
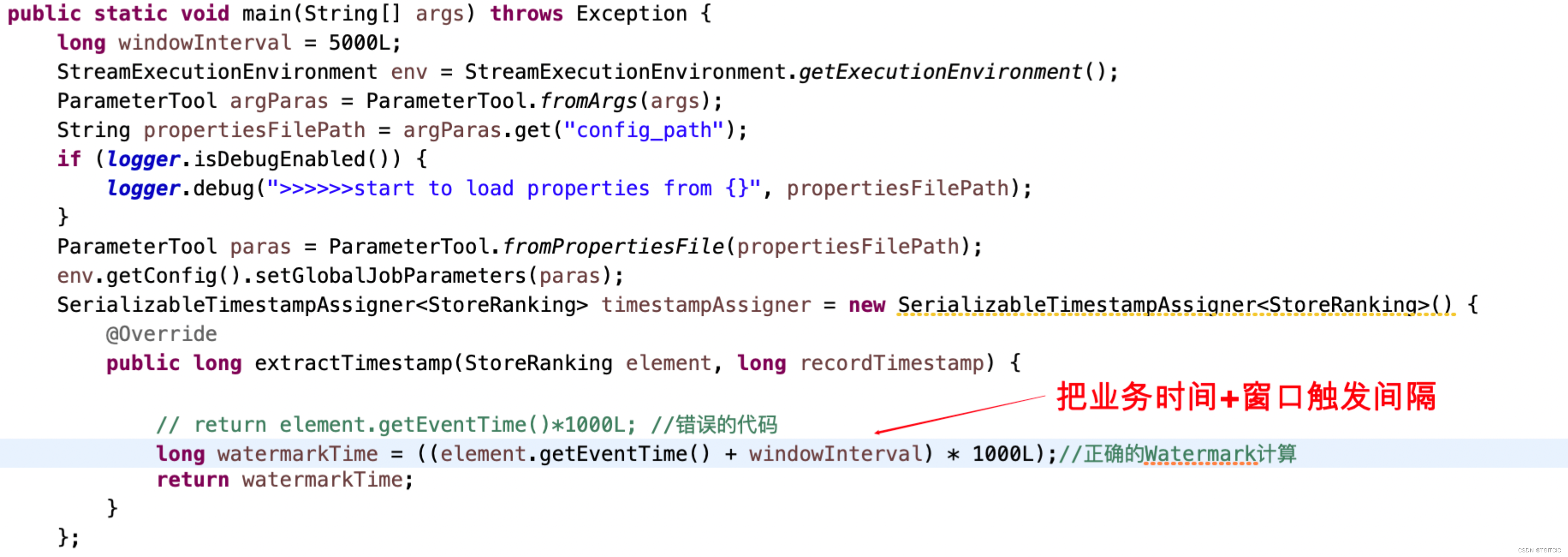
就这么改一下就行了?天哪!这么简单?
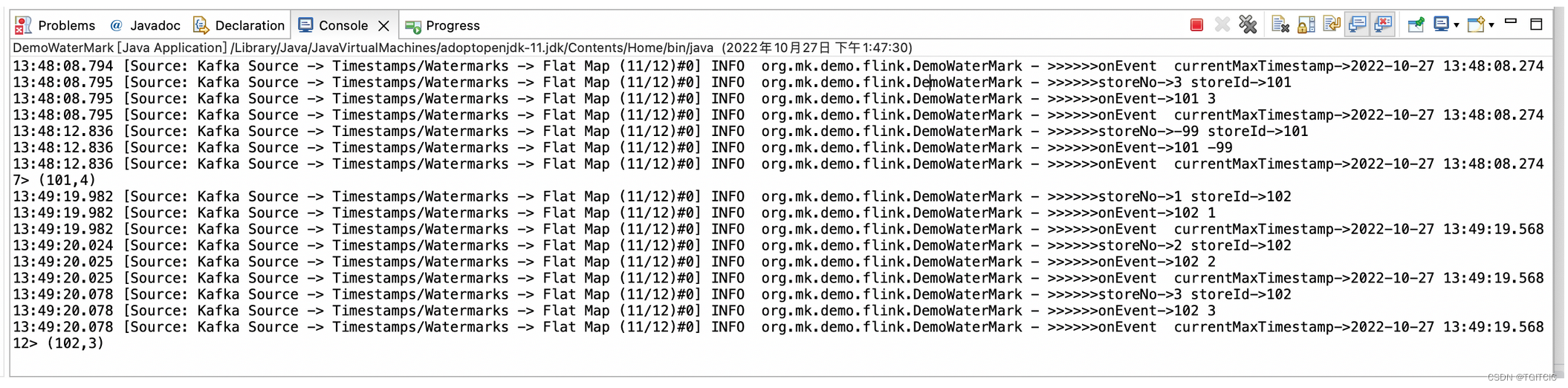
不信是吧?来看结果:
第一批数据送过去,看。。。结果出来了,4条,4个赞👍。

再送第二批数据3条数据,看。。。结果出来了,3条,3个赞👍。
高大上的实际生产级应用的理论
到此整个Watermark到底怎么用?为什么要用Watermark以及如何正确使用Watermark全部讲完了,全代码我附在最后。
而实际在生产环境我们很多时候如果仅仅靠flink自带的Watermark机制是不能满足我们的需求的,大量场景我们会使用“业务时间”来做Watermark以实现数据的归并,来应对“延迟”到达的数据。
而仅仅只有Watermark来应对“延迟到达”的数据只是第一道防线,依然会有漏过的有延时的数据。因此此时在我们的Window里还有一个成员函数它是:window(TumblingEventTimeWindows.of(Time.seconds(10))).allowedLateness(Time.seconds(5))来形成第二道防线,继续对漏过Watermark的延迟数据进行最后的捕捉以尽量满足业务数据的精准要求。
所以整个flink窗口它在正常的时候按照一个固定的duration进行滚动,以Watermark来做数据补偿,以allowedLateness来做漏过Watermark的延迟数据的进一步补偿。这样的话从“用户端客户侧”我们就可以达到以下这样的显示效果:
第一秒我看到的数据可能会有一定的小偏差,然后在一秒不到内发觉这个数据被修正了(Watermark触发了窗口补偿)但此时还差那么个0.01%偏差,但是又过了一秒不到我发觉:哈哈,这次是准了。
就是这么么一种“短促渐变式的体验”,这个体验其实用这么一个例子来做比喻或许会更加恰当吧:手机上的图片逐步加载清晰。一开始你在手机上看到一个图有一点模糊,在1秒内这个图片自己开始一点点变清晰这么一种过程的感觉。
这也符合实时计算的特性,因为实时、实时,它由于是异步的,不可能做到像直连HTTP连接、RESTFUL API一来一回这么准时,但是我们需要在实时计算中使用这么两道修正,来及时把这个数据修正成精准的,这正是实时计算中的一个非常至关重要的“设计理念”。
有人这边如果说要抬杠:其实如果只是看板,我们不需要这么精准。
那么我告诉你,这一系列文章我写下的目的不仅仅只是针对三产一类的商业应用,它们要面对的是全行业,譬如说:工业行业中的实时计算应用,我们需要在2秒内把气压阀值偏差控制在0.1%内如果可以到达0.01%那么会延长设备的使用设备(如:涡轮发电机),那么第一道防线我就要先到达偏差值在0.1%,第二道防线我反这个精准度降到0.01%,这样我的一个涡轮发电机转子的寿命本来正常情况下只能使用5年,现在我可以使用8年,这就是巨大的一笔成本上的节省。这就是一个典型的工控上的例子。
附:全代码(git地址-flinkdemo: flink基于1.15.2 JAVA版生产级应用DEMO)
package org.mk.demo.flink;
import java.text.SimpleDateFormat;
import java.time.Duration;
import java.util.Date;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.TimestampAssignerSupplier;
import org.apache.flink.api.common.eventtime.Watermark;
import org.apache.flink.api.common.eventtime.WatermarkGenerator;
import org.apache.flink.api.common.eventtime.WatermarkGeneratorSupplier;
import org.apache.flink.api.common.eventtime.WatermarkOutput;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.TimestampAssigner;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.alibaba.fastjson.JSON;
public class DemoWaterMark {
private final static Logger logger = LoggerFactory.getLogger(DemoWaterMark.class);
public static class StoreRankingJSONDeSerializer implements KafkaDeserializationSchema<StoreRanking> {
private final String encoding = "UTF8";
@Override
public TypeInformation<StoreRanking> getProducedType() {
return TypeInformation.of(StoreRanking.class);
}
@Override
public boolean isEndOfStream(StoreRanking nextElement) {
return false;
}
@Override
public StoreRanking deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) throws Exception {
if (consumerRecord != null) {
try {
String value = new String(consumerRecord.value(), encoding);
StoreRanking store = JSON.parseObject(value, StoreRanking.class);
return store;
} catch (Exception e) {
logger.error(">>>>>>deserialize failed : " + e.getMessage(), e);
}
}
return null;
}
}
public static void main(String[] args) throws Exception {
long windowInterval = 5000L;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool argParas = ParameterTool.fromArgs(args);
String propertiesFilePath = argParas.get("config_path");
if (logger.isDebugEnabled()) {
logger.debug(">>>>>>start to load properties from {}", propertiesFilePath);
}
ParameterTool paras = ParameterTool.fromPropertiesFile(propertiesFilePath);
env.getConfig().setGlobalJobParameters(paras);
SerializableTimestampAssigner<StoreRanking> timestampAssigner = new SerializableTimestampAssigner<StoreRanking>() {
@Override
public long extractTimestamp(StoreRanking element, long recordTimestamp) {
// return element.getEventTime()*1000L; //错误的代码
long watermarkTime = ((element.getEventTime() + windowInterval) * 1000L);//正确的Watermark计算
return watermarkTime;
}
};
KafkaSource<StoreRanking> source = KafkaSource.<StoreRanking>builder()
.setBootstrapServers(paras.get("kafka.bootstrapservers")).setTopics(paras.get("kafka.topic"))
.setGroupId("test01").setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new StoreRankingJSONDeSerializer())).build();
DataStream<StoreRanking> kafkaDS = env
.fromSource(source,
WatermarkStrategy.<StoreRanking>forBoundedOutOfOrderness(Duration.ofSeconds(windowInterval))
.withTimestampAssigner(timestampAssigner).withIdleness(Duration.ofSeconds(5)),
"Kafka Source");
DataStream watermarkDS = kafkaDS.assignTimestampsAndWatermarks(new WatermarkStrategy<StoreRanking>() {
private final long maxOutOfOrderness = windowInterval; // 3.5 秒
private long currentMaxTimestamp = System.currentTimeMillis() + 1000l;
@Override
public WatermarkGenerator<StoreRanking> createWatermarkGenerator(
WatermarkGeneratorSupplier.Context context) {
return new WatermarkGenerator<StoreRanking>() {
@Override
public void onEvent(StoreRanking event, long l, WatermarkOutput watermarkOutput) {
logger.info(">>>>>>onEvent->" + event.getStoreId() + " " + event.getStoreNo());
currentMaxTimestamp = Math.max(currentMaxTimestamp, event.getEventTime());
Date dt1 = new Date(currentMaxTimestamp);
SimpleDateFormat sd = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String currentMaxTimeStr = sd.format(dt1);
Date dt2 = new Date(event.getEventTime());
String eventTimeStr = sd.format(dt2);
logger.info(">>>>>>onEvent currentMaxTimestamp->" + currentMaxTimeStr + " eventTimeStr->"
+ eventTimeStr);
}
@Override
public void onPeriodicEmit(WatermarkOutput watermarkOutput) {
Date dt = new Date(currentMaxTimestamp);
SimpleDateFormat sd = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String timeStr = sd.format(dt);
// logger.info(">>>>>>onPeriodicEmit currentMaxTimestamp->" + timeStr +
// "maxOutOfOrderness->"
// + maxOutOfOrderness);
long newWatermarkTime = (currentMaxTimestamp - maxOutOfOrderness - 1) * 1000L;
watermarkOutput.emitWatermark(new Watermark((System.currentTimeMillis() + 100) * 1000L));
}
};
}
});
DataStream<Tuple2<String, Integer>> ds = watermarkDS
.flatMap(new FlatMapFunction<StoreRanking, Tuple2<String, Integer>>() {
public void flatMap(StoreRanking store, Collector<Tuple2<String, Integer>> collector)
throws Exception {
StoreRanking s = new StoreRanking();
s.setStoreId(store.getStoreId());
s.setStoreNo(store.getStoreNo());
s.setEventTime(store.getEventTime());
logger.info(">>>>>>storeNo->" + store.getStoreNo() + " storeId->" + store.getStoreId());
collector.collect(new Tuple2<String, Integer>(store.getStoreId(), 1));
}
});
ds.keyBy(value -> value.f0).window(TumblingEventTimeWindows.of(Time.seconds(10))).sum(1).print();
env.execute();
}
}