目录
(一)前言
(二)经典漏洞的代码审计
1、SQL注入
漏洞原理:
连接数据库的方式:
代码审计
2、XXE(XML外部实体注入)
漏洞原理
代码审计:
3、xss
漏洞原理
XSS漏洞分类
代码审计
4、反序列化
反序列化漏洞原理
反序列化漏洞的必要条件
代码审计
5、CSRF漏洞
漏洞原理
在测试CSRF漏洞时的三种方法
代码审计
6、文件上传漏洞
漏洞原理
7、逻辑漏洞
漏洞原理:
代码审计
8、SSRF漏洞
漏洞原理:
代码审计:
9、命令执行漏洞
漏洞原理
代码审计
(一)前言
要懂java代码审计要满足两个要求:
Java基础:这是有技术层面需求的,不仅仅需要明确理解Java的基本编程语言,还需要熟悉并理解Java的主要程序框架,比如Spring。Spring框架在许多中大型网站的后端开发中被广泛应用,因为它能提供方便的数据库事务管理服务,简化了离散技术的集成,并且可以有效地帮助开发人员焦点集中在实质性的业务开发上。
理解漏洞的原理:这是从安全层面的需求。需要理解漏洞是如何发生的,它们的致命性质是什么,以及怎样的代码实践会导致它们。知道漏洞的原理,了解漏洞产生的原因,只要在审计的时候,重点关注这些原因,就很容易找到漏洞
(二)经典漏洞的代码审计
1、SQL注入
漏洞原理:
SQL注入(SQL Injection)是因为程序未能正确对用户的输入进行检查,将用户的输入以拼接的方式带入SQL语句中,导致了SQL注入的产生
连接数据库的方式:
在java中,有两种方式连接数据库:JDBC和mybatis框架
JDBC:JDBC 是 Java 提供的一种标准数据库连接API。它允许开发者通过编写 SQL 语句和 Java 代码来连接和操作数据库。
MyBatis:MyBatis 是一个开源的持久层框架,它简化了在 Java 应用程序中使用 JDBC 的过程。它提供了一种将 SQL 和 Java 代码分离的方式,通过 XML 或注解来配置 SQL 语句和映射关系,减少了代码冗余和复杂性。
MyBatis只是简化java使用JDBC过程,可以更加方便使用,底层还是使用JDBC连接数据库,而JDBC连接数据库有两种方法:
直接拼接:直接拼接是通过使用 Statement对象来执行 SQL 语句,是在 Java 代码中直接将变量值嵌入到 SQL 语句中,然后将整个 SQL 语句作为字符串传递给数据库执行。这种方法如果变量值没有经过适当的处理,就容易产生SQL注入漏洞
预编译:预编译是通过使用 PreparedStatement 对象来执行 SQL 语句。在预编译阶段,SQL 语句会被发送到数据库进行编译,同时还可以将变量作为占位符传递进去。这种方法是不容易产生SQL注入
代码审计
1直接拼接造成SQL注入
JDBC拼接造成SQL注入
在执行sq语句时候,使用Statement对象执行,造成参数直接拼接到SQL语句中造成SQL注入
技巧:在项目中,直接搜索Statement,可以快速找到
MyBatis拼接造成SQL注入:
在MyBatis中直接使用${},造成参数直接拼接SQL语句,造成SQl注入漏洞
<select id="queryAll" resultMap="resultMap"> SELECT * FROM NEWS WHERE ID = #{id} // #{}使用预编译,安全 SELECT * FROM NEWS WHERE ID = ${id} // ${}使用拼接SQL,不安全 </select>
2、使用in语句之的多个参数
in之后多个id查询时,容易导致SQL注入,在一些删除语句中容易出现,由于无法确定参数个数,而使用直接拼接方式,就容易造成SQL注入:delete from news where id in("+ids+")在in这种情况中,哪怕使用预编译,比如在mybits框架,也容易出现SQL注入
Select * from news where id in (#{ids})对于 IN 语句,如果直接使用
#进行参数绑定,那么在拼接 SQL 语句时会将整个参数值作为一个整体拼接进去,而不会将参数值当作多个独立的值对待
3、使用like语句进行模糊查询LIKE 运算符用于在 WHERE 子句中进行模糊匹配,很容易出现拼接情况,就容易造成SQL注入
String sql = "select * from users where password like '%" + con + "%'"在mybaits框架中:
Select * from news where title like ‘%#{title}%’ 这种写法是错误,会报错,而正确的写法是: Select * from news where title like '%${title}%' 这就容易造成SQl注入4、Order by、from等无法预编译,
使用order by语句时是无法使用预编译的,因为数据库需要在执行查询之前知道如何进行排序。这意味着无法使用预编译语句中的
?占位符来代表列名,所以就需要采用拼接方式Select * from news where title =?" + "order by '" + time + "' asc

2、XXE(XML外部实体注入)
漏洞原理
XXE漏洞发生在应用程序解析XML输入时,没有禁止外部实体的加载,导致可加载恶意外部文件,造成文件读取、命令执行、内网端口扫描、攻击内网网站、发起dos攻击等危害。
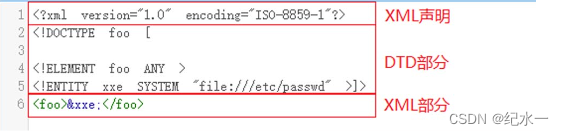
在xml文件中,分为三个部分:XML声明、DTD部分,XML部分
在DTD中,可以分为"内部声明实体"和”引用外部实体“,他们分别的作用是:内部声明实体:
引用外部实体
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE example [ 内部声明实体internalEntity <!ENTITY internalEntity "This is an internal entity"> //引用外部实体xternalEntity <!ENTITY externalEntity SYSTEM "http://www.example.com/externalEntity.xml"> ]> <example> <content> &internalEntity; and &externalEntity; </content> </example>所以XXE(XML外部实体引用)原理就是,没有禁用DTD部分中外部实体引用,导致攻击者可以加载外部的XML文件,造成敏感信息泄露等后果
代码审计:
要对java代码审计xxe漏洞,更加具体的话,就是从两个方面出发
- 对于没有使用xml外部实体的网站,查看是否禁用xml外部实体
- 对于引用xml外部实体的网站,查看使用使用xml文件的相关配置,是否安全
1、查看是否禁用XML外部实体
在Java中,XML外部实体(XXE)是默认开启的,所以如果没有特意进行配置,就是已经允许加载XMl外部实体,可以去检查解释器的配置,是否禁用
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); try { //禁止解析XML文档声明的doctype部分: factory.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true); //禁止解析XML文档中的外部通用实体: factory.setFeature("http://xml.org/sax/features/external-general-entities", false); //禁止解析XML文档中的外部参数实体: factory.setFeature("http://xml.org/sax/features/external-parameter-entities", false); //设置启用安全处理特性 factory.setFeature("http://javax.xml.XMLConstants/feature/secure-processing", true); //禁止XInclude的支持 factory.setXIncludeAware(false); //禁止XML文档解析器扩展实体引用 factory.setExpandEntityReferences(false); DocumentBuilder builder = factory.newDocumentBuilder(); builder.parse(new InputSource(new StringReader("<!DOCTYPE foo [<!ENTITY xxe SYSTEM 'file:///etc/passwd' >]><foo>&xxe;</foo>"))); System.out.println("External Entities are enabled!"); } catch (Exception e) { System.out.println("External Entities are disabled!"); }2、查看引用XML相关配置的接口,是否安全
在java中,常用于解析XML的接口和类有:
javax.xml.parsers.DocumentBuilderFactory是用于创建 DOM 文档解析器的工厂类。
javax.xml.parsers.SAXParser是用于创建 SAX 解析器的解析类。
javax.xml.transform.TransformerFactory是用于创建转换器的工厂类,它可以将一个 XML 文档转换成另一个 XML 文档。
javax.xml.validation.Validator是用于验证 XML 文档的验证器。
javax.xml.validation.SchemaFactory是用于创建 XML Schema 的工厂类。
javax.xml.transform.sax.SAXTransformerFactory是用于创建 SAX 转换器工厂类。
javax.xml.transform.sax.SAXSource是用于将 SAX 解析器的结果作为输入源的类。
org.xml.sax.XMLReader是一个接口,作为 SAX 解析器的标准输入。
org.xml.sax.helpers.XMLReaderFactory是用于创建 SAX 解析器的工厂类。
org.dom4j.io.SAXReader是一个用于解析 XML 的轻量级的 Java 库,它是基于 SAX 解析器实现的。
org.jdom.input.SAXBuilder和org.jdom2.input.SAXBuilder都是用于创建 JDOM 文档对象的 SAX 构建器。
javax.xml.bind.Unmarshaller是用于将 XML 文档反序列化为 Java 对象的类。
javax.xml.xpath.XpathExpression是用于解析和查询 XML 文档中的内容的类。
javax.xml.stream.XMLStreamReader是用于将 XML 文档中的数据读入到内存中的接口。
org.apache.commons.digester3.Digester是一个较为流行的基于 SAX 的 XML 解析器,可以用于将 XML 解析成 Java Object
3、xss
漏洞原理
XSS(跨站脚本攻击),通过注入恶意代码(一般是JavaScript)到网页中,嵌入到网页语言中成为网页的一部分,当进入网页,就会加载响应代码,此时就会连同恶意代码一起被执行。
XSS漏洞产生的原理是,没有对用户输入参数进行过滤和检查,导致参数显示到网页中的时候,攻击者在参数中的恶意代码就嵌入到了网页,成功执行
XSS漏洞分类
XSS漏洞分为三类
- 反射型XSS:非持久化,通过注入js代码,返回页面的时候,融合到前端页面中,当用户去点击链接会能触发XSS代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面
- 存储型XSS:持久化,通过注入js代码,存储在服务器中的,如在个人信息或发表文章等地方,插入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。这种XSS比较危险,容易造成蠕虫,盗窃cookie
- DOM型XSS:通过修改页面的DOM节点形成的XSS
DOM型和反射型的区别:
- 漏洞利用位置不同:DOM型XSS利用的是客户端中的DOM(文档对象模型),反射型XSS利用的是服务器端返回的响应结果
- 攻击方式:DOM型XSS:攻击通过修改DOM结构来触发,利用JavaScript来修改DOM元素内容或属性,从而插入恶意脚本。反射型XSS通过构造恶意的请求来触发,通常通过修改URL参数或表单数据,将恶意脚本注入到页面中
- 影响范围:DOM型XSS影响范围主要取决于恶意脚本的执行位置和访问权限,反射型XSS影响范围主要取决于用户是否点击了恶意构造的URL或提交了恶意构造的表单
代码审计
关于java代码审计检测xss漏洞大致步骤如下:从两个方面出发
- 从后端源代码出发,重点检测后端接收和处理参数的方式:只测试从前端接受的参数,如果参数返回前端,就测试反射型xss,如果参数保存下来,就测试存储型xss
- 从前端出发,根据功能点,查看哪些参数传递到了后端,如果参数传递到后端,又返回到前端,就测试反射型xss,如果没有返回前端,去后端查看该参数是否保存,如果保存了,就可以测试存储型xss。此外查看前端的DOM操作,测试XSS漏洞
具体漏洞的审计方法:存储型XSS和反射型XSS漏洞的审计方法是一样:
- 有没有验证:后端接收参数后,查看有没有进行输入验证或转义,对长度限制、特殊字符过滤、类型检验
长度限制:这要根据功能来过滤,一般输入的长度要在数据据字段长度范围内
特殊字符过滤:看有没有过滤< > / " ’等这些HTML常用 标签或者 JavaScript 代码- 没有对其转义:存储型XSS是查看对于存储的数据没有用转义,反射型XSS是查看返回前端的数据没有转义
比如以下代码,存在反射型XSS,在接受参数之后,没有进行检测,在返回前端的时候,没有进行转义
<% //部署在服务器端 //从请求中获得“name”参数 String name = request.getParameter("name"); //从请求中获得“学号”参数 String studentId = request.getParameter("sid"); //直接接受参数,没有检测和过滤 out.println("name = "+name); out.println("studentId = "+studentId);//直接输出到前端,没有转义 %>DOM型XSS漏洞:
- 审查前端代码中使用到的DOM操作方法,特别关注用户输入是否直接插入到DOM中,以及是否没有进行适当的过滤或转义。
以下代码,从url中截取#之后的值,写入到网页中,然后当作JavaScript 代码执行
<script> var pos = document.URL.indexOf("#")+1; var name = document.URL.substring(pos, document.URL.length); document.write(name); eval("var a = " + name); </script>利用以下POC,成功出发DOM型XSS
http://localhost:8080/dom-xss.jsp#1;alert(/xss/)

4、反序列化
反序列化漏洞原理
序列化是将对象转换为字节流的过程,而反序列化则是将字节流转换回对象的过程。
反序列化漏洞的原理是:在反序列化的过程中,攻击者通过劫持数据,植入字节数据,应用程序没有对验证和过滤,其解析恶意数据并创建对象。如果恶意代码被执行,攻击者可以获取敏感信息、执行远程命令等
反序列化漏洞的必要条件
成功利用反序列化漏洞通常需要满足两个条件:
利用链(exploit chain):利用链是指攻击者构建的一系列恶意对象或操作,通过利用不同的触发点、中继点和执行点来实现攻击的目的。攻击者需要理解目标应用程序中的反序列化过程,构建特定的序列化数据和对象,使得在反序列化过程中触发恶意行为并达到执行恶意代码的目的。
触发点(trigger po int):触发点是指在应用程序的反序列化过程中,攻击者注入的恶意数据在反序列化操作中首次被解析和使用的位置。攻击者需要确定目标应用程序中的触发点,并构造恶意数据,以触发漏洞并启动利用链的执行。
代码审计
1、原生的Java反序列化:
在 Java 中,要实现对象的序列化和反序列化,对象必须实现 Serializable 接口或 Externalizable 接口:
Serializable 接口:实现了 Serializable 接口的类可以通过 Java 的默认机制进行序列化和反序列化,该接口是一个标记接口,不包含任何方法,只是作为序列化和反序列化的标志。
Externalizable 接口:与 Serializable 接口不同,实现 Externalizable 接口的类需要显式地实现 writeExternal() 和 readExternal() 两个方法
进行反序列化过程需要用到输入输出流来实现序列化和反序列化
- java.io.ObjectOutputStream 类的 writeObject() 方法可以实现序列
- java.io.ObjectInputStream 类的 readObject() 方法用于实现反序列化
import java.io.*; // 学生类 class Student implements Serializable { private String name; private int age; // 构造函数 public Student(String name, int age) { this.name = name; this.age = age; } // Getter 和 Setter 方法 public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } // 序列化和反序列化示例 public class SerializationExample { public static void main(String[] args) { // 序列化示例 try { Student student = new Student("Tom", 20); FileOutputStream fileOut = new FileOutputStream("student.ser"); ObjectOutputStream out = new ObjectOutputStream(fileOut); out.writeObject(student); out.close(); fileOut.close(); System.out.println("对象已序列化到 student.ser 文件"); } catch (IOException e) { e.printStackTrace(); } // 反序列化示例 try { Student student = null; FileInputStream fileIn = new FileInputStream("student.ser"); ObjectInputStream in = new ObjectInputStream(fileIn); student = (Student) in.readObject(); in.close(); fileIn.close(); System.out.println("从 student.ser 文件反序列化得到对象:" + student.getName() + " " + student.getAge()); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }2、与框架相关的Java反序列化:
Apache Struts 反序列化漏洞(CVE-2017-5638):该漏洞影响 Apache Struts 框架,攻击者可以通过构造特殊的 Content-Type 标头来注入恶意的 OGNL 表达式,从而执行远程命令。
Apache Commons Collections 反序列化漏洞(CVE-2015-6420):Apache Commons Collections 库中存在漏洞,攻击者可以构造恶意的序列化数据来触发远程代码执行。
Jackson 反序列化漏洞:Jackson 是用于处理 JSON 数据的流行 Java 库。曾经发现过多个 Jackson 反序列化漏洞,例如 Jackson-databind 反序列化漏洞(CVE-2017-7525、CVE-2018-19362),攻击者可以通过构造恶意 JSON 数据来执行任意代码。
JBoss Seam 反序列化漏洞(CVE-2010-1871):JBoss Seam 是一个用于开发 Java EE 应用程序的框架,曾出现反序列化漏洞,攻击者可以通过精心构造的序列化数据实现远程代码执行。
WebLogic 反序列化漏洞(CVE-2017-10271):该漏洞影响 Oracle WebLogic Server,攻击者可以通过发送恶意的 T3 协议请求,利用 WebLogic 进行远程代码执行
这些漏洞都是典型反序列化漏洞了,网上有现场的检测工具,只需要那工具检测就得出结果
5、CSRF漏洞
漏洞原理
攻击者盗用了用户的身份,以用户的名义发起恶意请求,服务器没有对身份进行识别,会认为这请求是用户发起,会根据请求进行响应 ,CSRF漏洞的本质就是通过欺骗用户去访问自己设置的地址
在测试CSRF漏洞时的三种方法
以为CSRF漏洞是盗用用户身份凭借,去访问执行某个操作,而这个操作就是访问某个接口,基于这样的情况,我发现关于CSRF漏洞的测试分为三类:
拿到用户身份凭据:这种情况下,攻击者已经获得了用户的登录凭据,可以模拟用户的请求来执行某个操作。
拿不到用户身份凭据,诱导用户访问接口:这种情况下,攻击者无法直接获取用户的身份凭据,但可以通过诱导用户点击恶意链接或者访问恶意网站来执行攻击。攻击者利用用户已经登录的状态,诱导用户主动发起指定请求,从而执行攻击。这属于钓鱼、社会工程学手段
拿不到用户身份凭据,劫持原网站接口:这种情况下,攻击者无法直接获取用户的身份凭据,但可以通过劫持原网站中的功能接口来替换成其他接口来执行攻击。
比如在一些评论功能中,可以点击查看用户的头像,在点击头像就会,访问该图像的地址,如果把这个图像的地址换成退出登录接口,这样就造成:只要一打开图片,就退出登录
代码审计
查看是否检测referer、token等参数
检查referer、token是防御CSRF漏洞的常用方法,如果网站没有检测,或是检测不严,就可能存在CSRF漏洞
检测Referer:Referer是HTTP请求头字段,它指示了当前请求页面的来源页面的URL。在CSRF攻击中,攻击者通常无法伪造请求的Referer字段,因为Referer字段由浏览器自动生成并发送。因此,服务器可以检查Referer字段来验证请求的来源是否合法。如果Referer字段为空或与当前页面的来源不匹配,服务器可以拒绝请求。
使用Token:Token是一种随机生成的令牌,它可以防止CSRF攻击。服务器在生成页面时,将Token嵌入到页面中(通常是作为隐藏表单字段的一部分)。当用户提交表单时,服务器会检查表单中的CSRF Token与服务器生成的Token是否匹配。如果不匹配,服务器会拒绝请求
比如以下,只是判断referer的值是否为空,判断是否是www.testdomain.com开头,都是则继续执行,否则就返回首页,只要构造POC:www. testdomain.com.hacker.com。就可以绕过检测,造成CSRF漏洞
HttpServletResponse resp, Object handler) throws Exception { //从用户的请求头中取得 Referer 值,判断其是否为空 String referer=request.getHeader("Referer"); //Referer 值非空,而且referer要www.testdomain.com 开头,若不是,则跳转至首页 if((referer!=null) &&(referer.trim().startsWith("www.testdomain.com"))){ chain.doFilter(request, response); }else{ request.getRequestDispatcher("index.jsp").forward(request,response); } }
6、文件上传漏洞
漏洞原理
文件上传漏洞是指由于程序员在对用户文件上传部分的控制不足或者处理缺陷,而导致的用户可以越过其本身权限向服务器上上传可执行的动态脚本文件。这里上传的文件可以是木马,病毒,恶意脚本或者WebShell等。“文件上传”本身没有问题,有问题的是文件上传后,服务器怎么处理、解释文件。如果服务器的处理逻辑做的不够安全,则会导致严重的后果。
代码审计:
预防文件上传,要对文件上传严格的验证和过滤,这就分前后端进行,有些是采用第三方库来进行文件上传,查看他们的历史版本是否存在文件上传
1、查看前端的文件过滤,
查看文件类型、文件大小、文件名称(之所以除了查看类型之外,还查看大小,文件名,是防其他漏洞):
文件类型验证:防文件上传,防攻击者上传webshell文件
文件大小验证:防DOS攻击,大量上传超大内存文件,会造成dos
文件名称验证:防XSS攻击,文件名插入XSS的payload会造成xss攻击
以下代码只是由前端进行验证,之查看文件类型,利用白名单方式进行验证是否是jpg等图片类型,是的话就运行上传,这样很容易绕过,只要随便输入符合的文件类型,然后进行抓包修改文件类型为其他,就成功绕过<script type="text/javascript"> function checkUploadFile() { var file = document.getElementById("file").value; if (file == null || file==""){ alert("未选定文件") return false; } var allow_ext = ".jpg|.png|.gif|.jpeg"; var ext_name = file.substring(file.lastIndexOf(".")); if (allow_ext.indexOf(ext_name)==-1){ var errMsg = "该类型文件不允许上传"; alert(errMsg); return false; } } </script>2、查看后端的文件过滤
后端处理和前端一样,要查看类型、大小、文件名,还要验证文件内容、存储路径,是否返回信息
- 文件类型验证:检查是否在后端对文件类型进行了验证。
- 文件内容验证:检查是否对文件内容进行了验证。查看内容是否由恶意代码
- 文件名验证:检查是否对上传的文件名进行了验证。特别是文件扩展名部分,
- 存储路径:检查是否对文件的存储路径进行了合理设置,防止目录遍历漏洞出现。
- 文件重命名:为防止文件覆盖,采用唯一命名方式(如UUID)是一种常见的做法。
- 返回信息:注意返回给前端的信息,比如,返回上传文件的绝对路径,可能导致路径泄露。
//文件类型验证:只能上传jpg、png public boolean isValidFileType(MultipartFile file) { String extension = FilenameUtils.getExtension(file.getOriginalFilename()); // 根据业务需求设置允许的文件类型,比如只允许上传图片文件(如jpg、png) List<String> allowedExtensions = Arrays.asList("jpg", "png"); return allowedExtensions.contains(extension.toLowerCase()); } //文件内容验证:查看内容是否包含<script> public boolean isValidFileContent(MultipartFile file) { try { String fileContent = IOUtils.toString(file.getInputStream(), StandardCharsets.UTF_8); // 根据业务需求,检查文件内容是否包含恶意代码或符合特定的要求 return !fileContent.contains("<script>"); } catch (IOException e) { e.printStackTrace(); return false; } } //文件名验证: public boolean isValidFileName(MultipartFile file) { String extension = FilenameUtils.getExtension(file.getOriginalFilename()); // 根据业务需求,检查文件名是否符合要求,如不允许特殊字符或限制长度等 return !file.getOriginalFilename().contains("..") && extension != null; } //存储路径设置和文件重命名: public String saveUploadedFile(MultipartFile file) { try { String fileName = UUID.randomUUID().toString(); // 使用UUID作为文件名 String storagePath = "/path/to/storage/"; // 设置文件存储路径 String savePath = storagePath + fileName; File destination = new File(savePath); file.transferTo(destination); // 保存上传文件 return fileName; } catch (IOException e) { e.printStackTrace(); return null; } } //返回信息安全处理 public String getSafeFilePath(String fileName) { String storagePath = "/path/to/storage/"; // 设置文件存储路径 return storagePath + fileName; }3、查看历史版本
许多Java应用会使用Apache Commons FileUpload一类的库处理文件上传,那么需要关注这些库的使用方式和版本,查看是否存在已知的安全漏洞
7、逻辑漏洞
漏洞原理:
逻辑漏洞指的是在软件或系统设计过程中存在的错误或疏忽,导致潜在的安全风险和漏洞。这些漏洞通常是由于开发人员未正确处理输入、验证用户身份、授权访问等造成的。
代码审计
逻辑漏洞的产生并不是在代码上,而是在实现功能的逻辑上存在逻辑缺陷,所以要从代码上找到漏洞,首先要深刻理解业务实现的逻辑,再以此为出发点测试
以下是常遇见的逻辑漏洞1、验证码
验证码爆破:通过尝试多次猜测验证码的值来进行暴力破解,(原因没有对次数进行限制,或者验证码有效时间)
验证码回显:网页不正确地处理验证码的回显,将验证码的值返回前端验证
验证码与手机未绑定认证关系:验证码发送到用户手机上进行验证,但验证过程中没有对手机号与验证码进行有效绑定,
修改返回包绕过验证码:修改返回包,使系统绕过验证码验证,从而获得未经验证码验证的访问权限。
验证码转发:在发送包中的手机号之后用逗号隔开,新增一个手机号,两个手机号同时获取到验证码(原因后台可能使用数组接受手机验证码)
phone=12311111 => phone=12311111,12322222任意验证码登录:随便输入一个验证就可以(原因:开发时为了方便,之后没有修改回来)
验证码为空登录:系统没有对验证码为空的情况进行有效的处理,导致攻击者可以不输入验证码而直接登录。
固定验证码登录:验证码在系统中是固定的,攻击者可以在多次登录尝试中使用相同的验证码进行验证。
验证码轰炸:攻击者通过大量的请求发送大量的验证码,对系统造成压力甚至拒绝服务。
2、支付
任意金额修改:抓包可以修改其中金额,可以实现0元购
负数购买:抓包把金额修改为负数,最终导致商家还向客户钱
越权支付:伪造支付请求或者修改支付参数,绕过验证,实现支付,或者把用户身份id改为其他用户,让其他用户给自己买单
修改运费价格:修改订单中的运费价格费用。
优惠券修改:攻击者可能通过修改优惠券参数,增多优惠卷个数或者增大优惠卷金额,或者通过优惠卷id号,遍历未授权的优惠卷给自己用
四舍五入漏洞:在计算支付金额或者折扣金额时,把金额修到小数点三位,比如充值0.019,最终得到0.02(原因,系统只能只能识别小数点两位数)
无限利用优惠券漏洞:这是针对那种“包月套餐,首月低价”
用A手机登录账号A,点击业务自动续费功能,进入支付页面,但不要支付,
用B手机登录账号A,点击业务自动续费功能,进入支付页面,但不要支付
两个手机同时支付,就可以两次使用首月低价整数溢出:把修改金额改为无限大,最终支付金额会修改为其他,(原因是超过后台数据类型的接受范围)比如int类型的范围是 -2,147,483,648 到 2,147,483,647,把金额改为2,147,483,648(只比int数据类型大1),这样的话,就超过了int的最大值,就会循环计算,可能最终支付-2,147,483,648,或者支付1
3、并发(条件竞争)
并发是多个并发操作下可能出现的安全问题,产生的原因是后台没有使用锁功能,什么场景都可能存在并发比如:这里只是列举两点
- 点赞时的并发漏洞:一个用户只能点一次赞,并发却能一次多个站,导致疯狂刷赞
- 领取优惠卷并发:领取优惠卷时候,进行并发,就获取到多张优惠卷
4、越权
越权就是做了不属于自己做事情,这样的漏洞其实很多,可能大量存在各个系统和功能点中
找到用户识别身份的参数,比如id、uid、name、role、email、appid、invoice_id这些参数,在操作时候修改参数的值,就造成了越权,比如:
- 删除评论:删除评论时候抓包,把用户身份id改为其他人,造成删除其他人的评论
- 用户登出:登录登录时候抓包,把用户身份name参数改为其他人,造成让其他人退出登录
- 查看他人信息:在查看个人信息时候抓包,把用户身份name参数改为其他人,就获取到其他人的身份信息
还有很多例子,这里只是简单列举,想要仔细了解的话,这是一位大佬的关于如何挖越权漏洞的文章:
https://mp.weixin.qq.com/s/C6NuprrVSAx2Nh0fPXidwA
8、SSRF漏洞
漏洞原理:
攻击者会伪造服务器发出请求,向内部网络或者其他受保护资源请求,服务器没有进行识别,没有对目标地址做过滤与限制,会认为是服务器请求,会正常响应
代码审计:
1)快速找到SSRF 可能存在区域,就是找到HTTP请求操作函数,
以下是常用于处理HTTP请求库:HttpURLConnection.getInputStream HttpURLConnection.connect URLConnection.getInputStream HttpClient.execute HttpClient.executeMethod Request.Get.execute Request.Post.execute URL.openStream ImageIO.read OkHttpClient.newCall.execute HttpServletRequest BasicHttpRequest2)测试是否存在SSRF漏洞:构造不同的输入方法,查看是否可以访问内部
- 使用不同的URL协议:HTTP、HTTPS、FTP、FILE协议等
- 使用本地环回地址:
http://127.0.0.1和http://localhost,- 尝试使用内部IP地址进行访问:
http://192.168.0.1或http://10.0.0.1- 使用不同域名和路径:更改原本访问地址,是否可以访问其他地址,或者目录穿越
9、命令执行漏洞
漏洞原理
在目标应用或设备开发时对执行函数没有过滤,对用户输入的命令安全监测不足,导致攻击上传的恶意代码得以执行
代码审计
1)快速找到常用执行命令函数:
System.exec():Java中用于启动外部进程的方法。getRuntime().exec():获取Java运行时对象并使用其执行外部命令的方法。Runtime.exec():Java中用于执行外部命令的方法。ProcessBuilder:Java中创建和管理进程的类。ShellExecute:与Windows平台上执行外部命令相关的函数。wsystem():与Windows平台上执行外部命令相关的函数。/bin/sh、/bin/bash、cmd:常见的命令行Shell解释器路径2)测试命令执行漏洞
- 首先通过代码审计,找到前端代码中调用后端接口的位置,是哪些接口请求最终调用了这些命令执行函数
- 其次对请求接口的参数进行测试:测试是否可以通过修改请求参数来触发命令执行漏洞