LCM(Latent Consistency Models)可以通过很少的迭代次数就可以生成高清晰度的图片,目前只可以使用一个模型Dreamshaper_v7,基于SD版本Dreamshaper微调而来的。
LCM模型下载:
https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7![]() https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7
https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7
项目源码:
GitHub - luosiallen/latent-consistency-model: Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step InferenceLatent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference - GitHub - luosiallen/latent-consistency-model: Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference![]() https://github.com/luosiallen/latent-consistency-model
https://github.com/luosiallen/latent-consistency-model
安装依赖库
pip install --upgrade diffusers # make sure to use at least diffusers >= 0.22
pip install transformers accelerate运行模型
文生图
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7")
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
num_inference_steps = 4
images = pipe(prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=8.0, lcm_origin_steps=50, output_type="pil").images
images[0].save("image.png")图生图
from diffusers import AutoPipelineForImage2Image
import torch
import PIL
pipe = AutoPipelineForImage2Image.from_pretrained("SimianLuo/LCM_Dreamshaper_v7")
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
prompt = "High altitude snowy mountains"
image = PIL.Image.open("./snowy_mountains.png")
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
num_inference_steps = 4
images = pipe(prompt=prompt, image=image, num_inference_steps=num_inference_steps, guidance_scale=8.0).images
images[0].save("image.png")在线demo
https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model![]() https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model
https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model
将LCM集成到Stable Diffusion WebUI中
SD WebUI 的 LCM 插件源码
GitHub - 0xbitches/sd-webui-lcm: Latent Consistency Model for AUTOMATIC1111 Stable Diffusion WebUILatent Consistency Model for AUTOMATIC1111 Stable Diffusion WebUI - GitHub - 0xbitches/sd-webui-lcm: Latent Consistency Model for AUTOMATIC1111 Stable Diffusion WebUI![]() https://github.com/0xbitches/sd-webui-lcm选择“Extensions”->“Install from URL”,安装LCM插件。
https://github.com/0xbitches/sd-webui-lcm选择“Extensions”->“Install from URL”,安装LCM插件。
生成的图片将会保存到outputs/txt2img-images/LCM
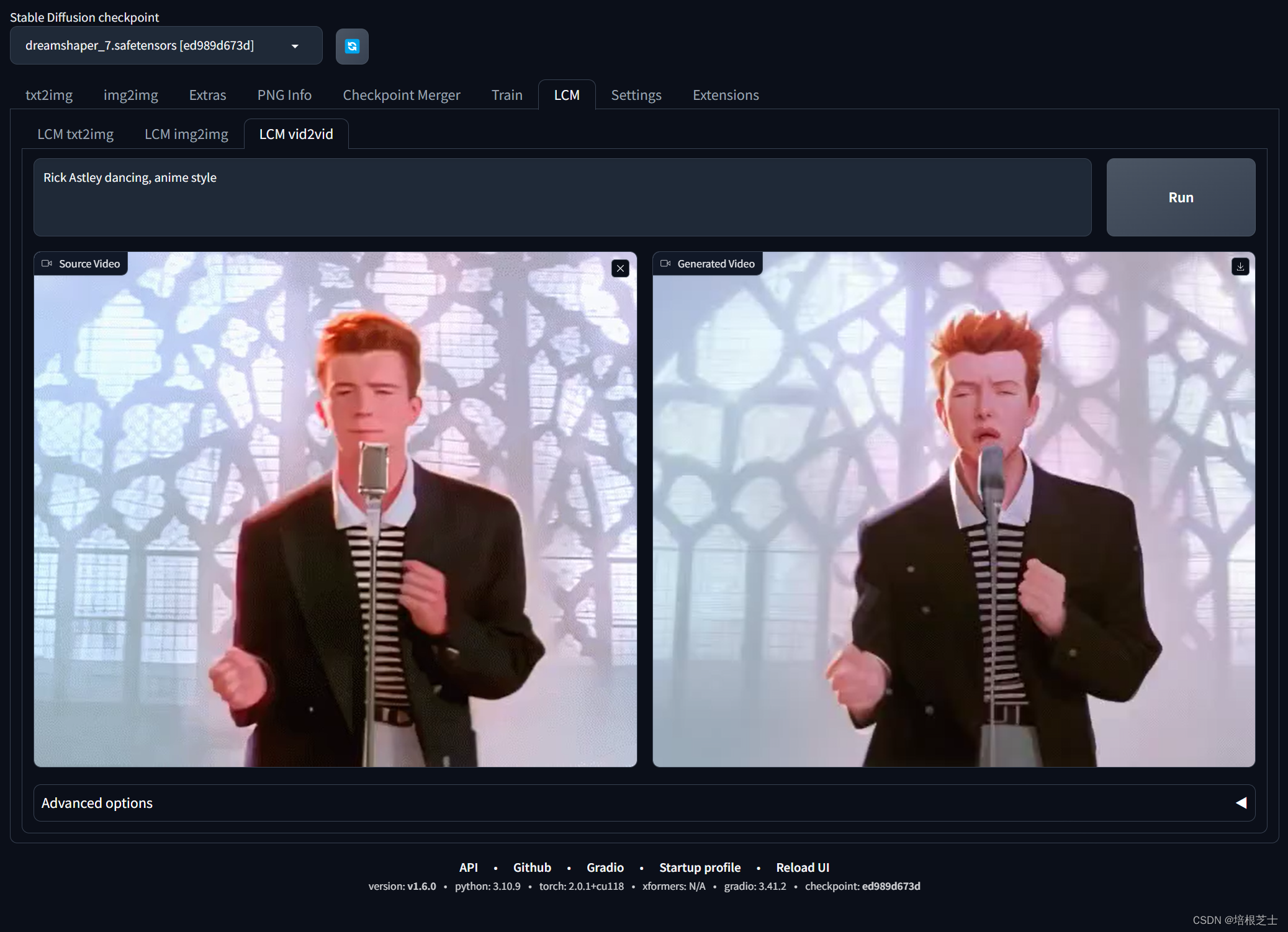
LCM插件提供了txt2img、img2img、vid2vid三个选项卡。
Img2Img和Vid2Vid的输出高度和宽度将与输入相同,目前不可更改。
生成的视频将保存到outputs/LCM-vid2vid