【Linux基础IO篇】深入理解文件系统、动静态库
目录
- 【Linux基础IO篇】深入理解文件系统、动静态库
- 再次理解文件系统
- 操作系统内存管理模块(基础)
- 操作系统如何管理内存
- Linux中task_struct源码结构
- 动态库和静态库
- 动静态库介绍:
- 生成静态库
- 库搜索路径
- 生成动态库
- 使用动态库
- 运行动态库
- 使用外部库
- 库文件名称和引入库的名称
作者:爱写代码的刚子
时间:2023.11.10
前言:进一步理解文件系统,以及动静态库的原理和使用
再次理解文件系统
- 无法对目录建立硬链接(只有系统可以,root用户也不可以,因为可能会存在对目录建立硬链接的环路问题)
- 每个目录都有.和…这样的硬链接文件
操作系统内存管理模块(基础)
- 物理内存的基本单位是1KB,4GB内存有2^32个地址,操作系统将物理内存以4KB为基本单位划分为多个区域(同时我们的可执行程序在磁盘中也以4KB为基本单位划分为多个数据块)我们将物理内存中这个4KB大小的空间叫做页框,将磁盘中的4KB叫做页帧,所以数据交换的单位即为4KB。
【问题】为什么是4KB?
-
减少IO的次数(减少访问外设的次数)(硬件上)
-
操作系统中存在基于局部性原理的预加载机制(软件上)
-
从硬件上和软件上,在对磁盘进行防问时对系统进行提速
【问题】当数据小于4KB时是否造成内存的浪费?
- 不会,因为文件的属性(文件的大小)会规定内存的大小
操作系统如何管理内存
先描述,再组织!
Linux下会存在struct page结构体对象
struct page
{
//page页必要的属性信息
}
32位操作系统下4GB内存中存在100万个页
所以我们会得到一个struct page的数组:
struct page mem_array[1048576];
对内存的管理变成了对数组的增删查改,该数组的下标叫做页号
【问题】如何将将物理地址转化为页号?
- 将物理地址&0xFFFF F000
我们要访问一个内存,我们只需要先找到这个4KB对应的Page,就能在系统中找到对应的物理页框。
所有申请内存的动作,都是在访问内存page数组
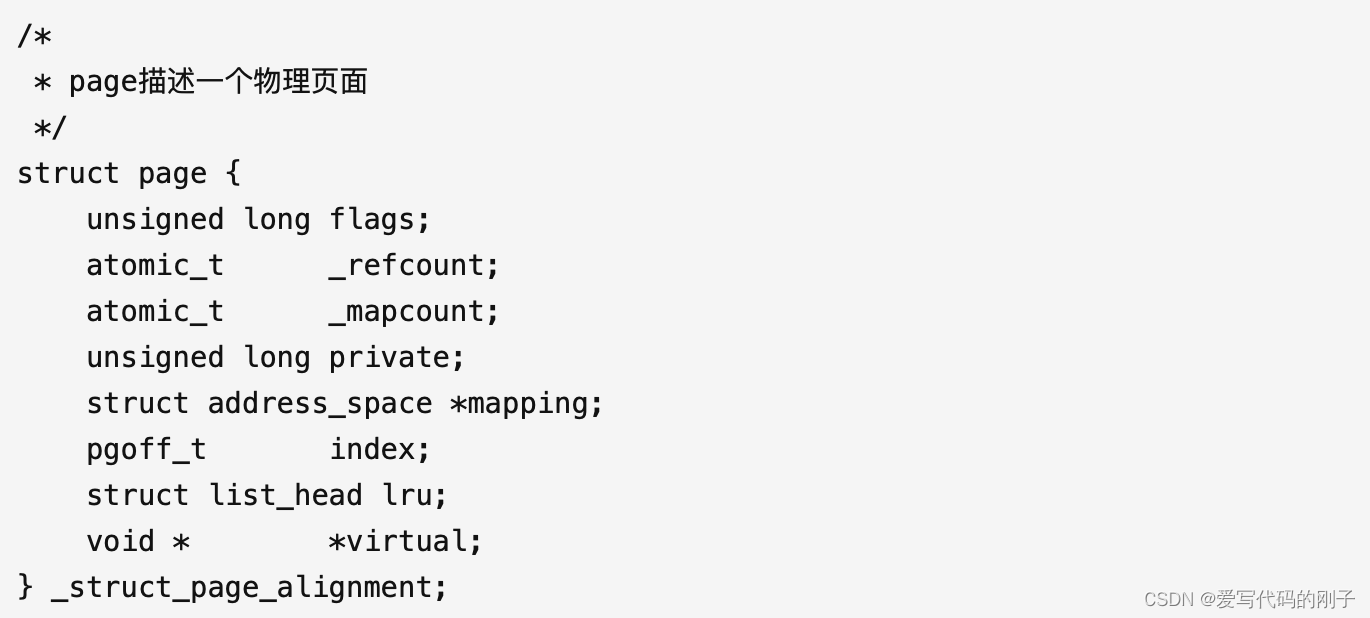
- 其中flags表示page的使用状态
所以操作系统申请内存的操作就是将flags里面的比特位(is_used)进行修改(置1)
- _refcount表示引用计数,写时拷贝是以4KB进行拷贝的。
- lru表示最近最常使用的数据,想被刷新或者可以刷新的数据可以维护在lru中。
附加了解:
- 对大块内存申请的伙伴系统算法,对小块内存处理的slab分派器
Linux中task_struct源码结构
linux源码下载
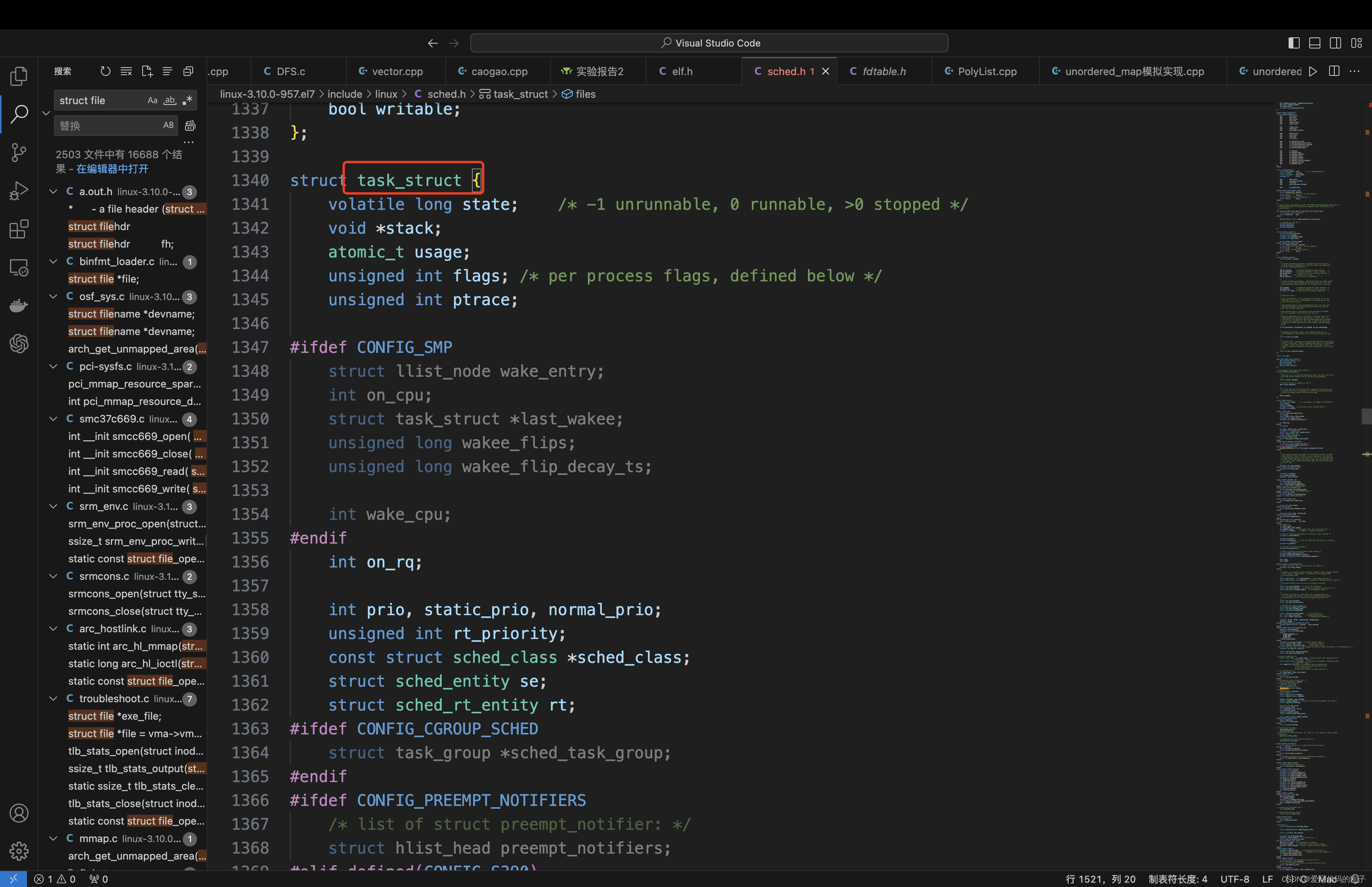
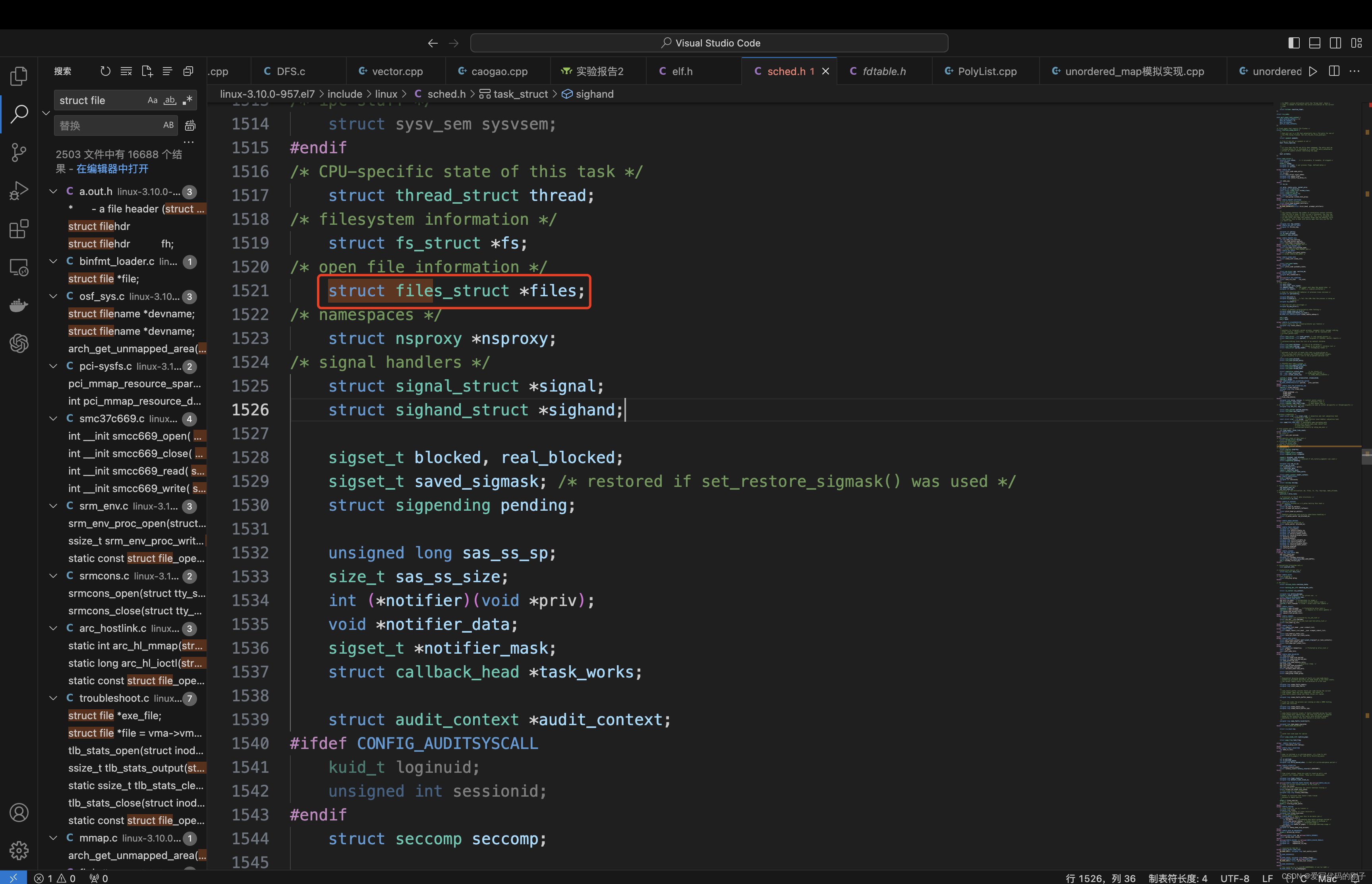
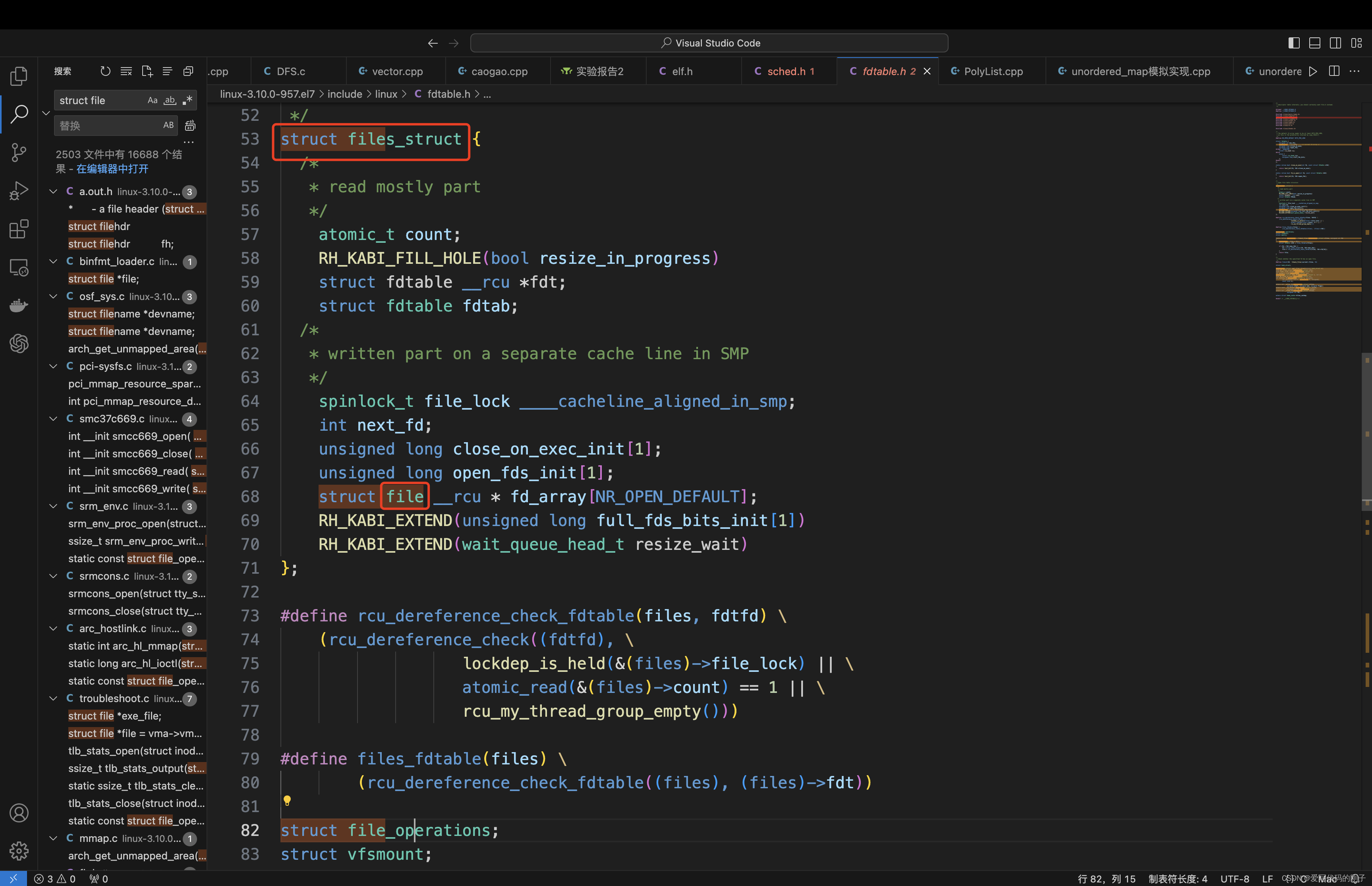
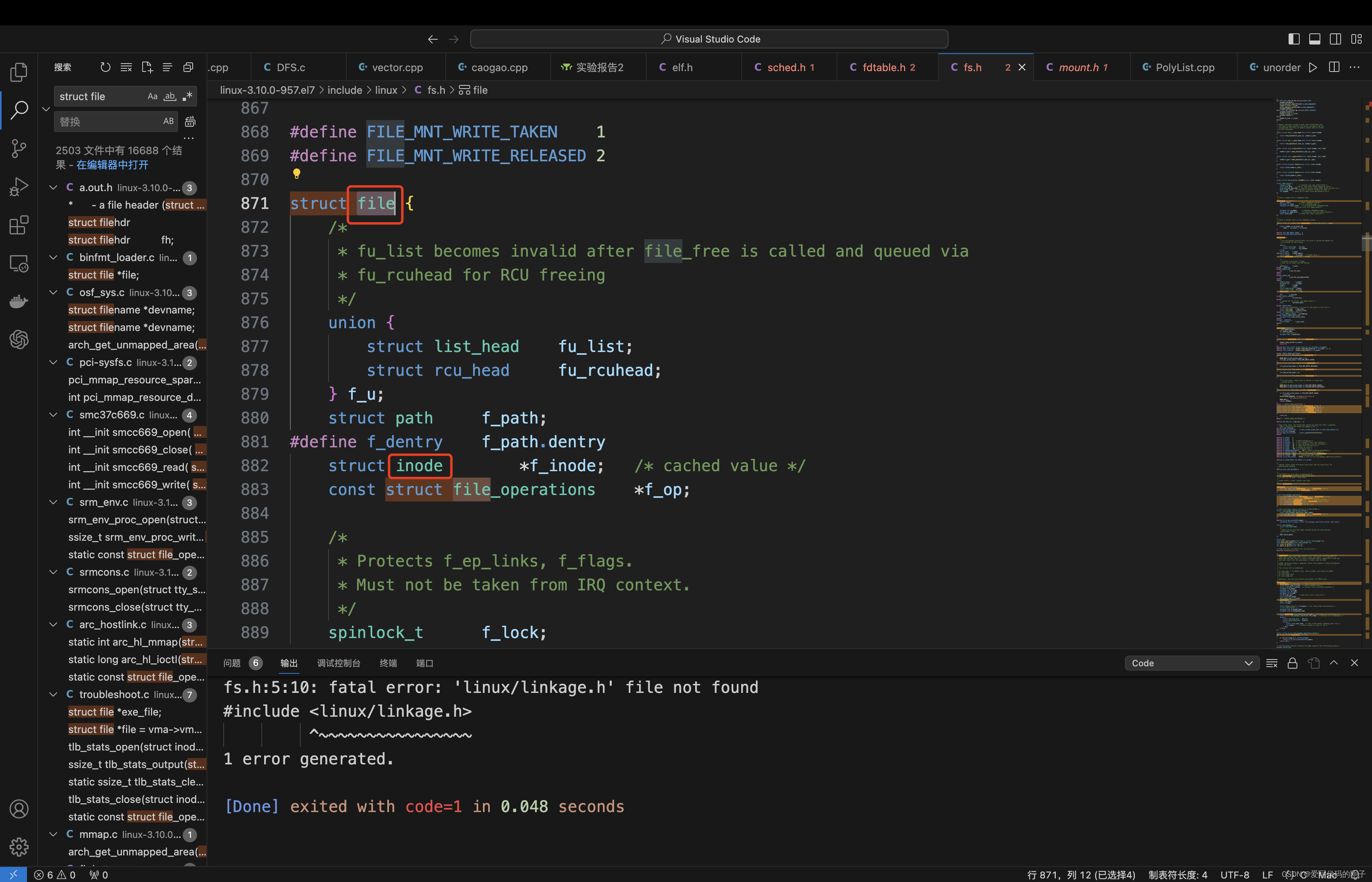
- inode中包含了文件的属性,要想找到文件的内容,需要找到struct file中的address_space
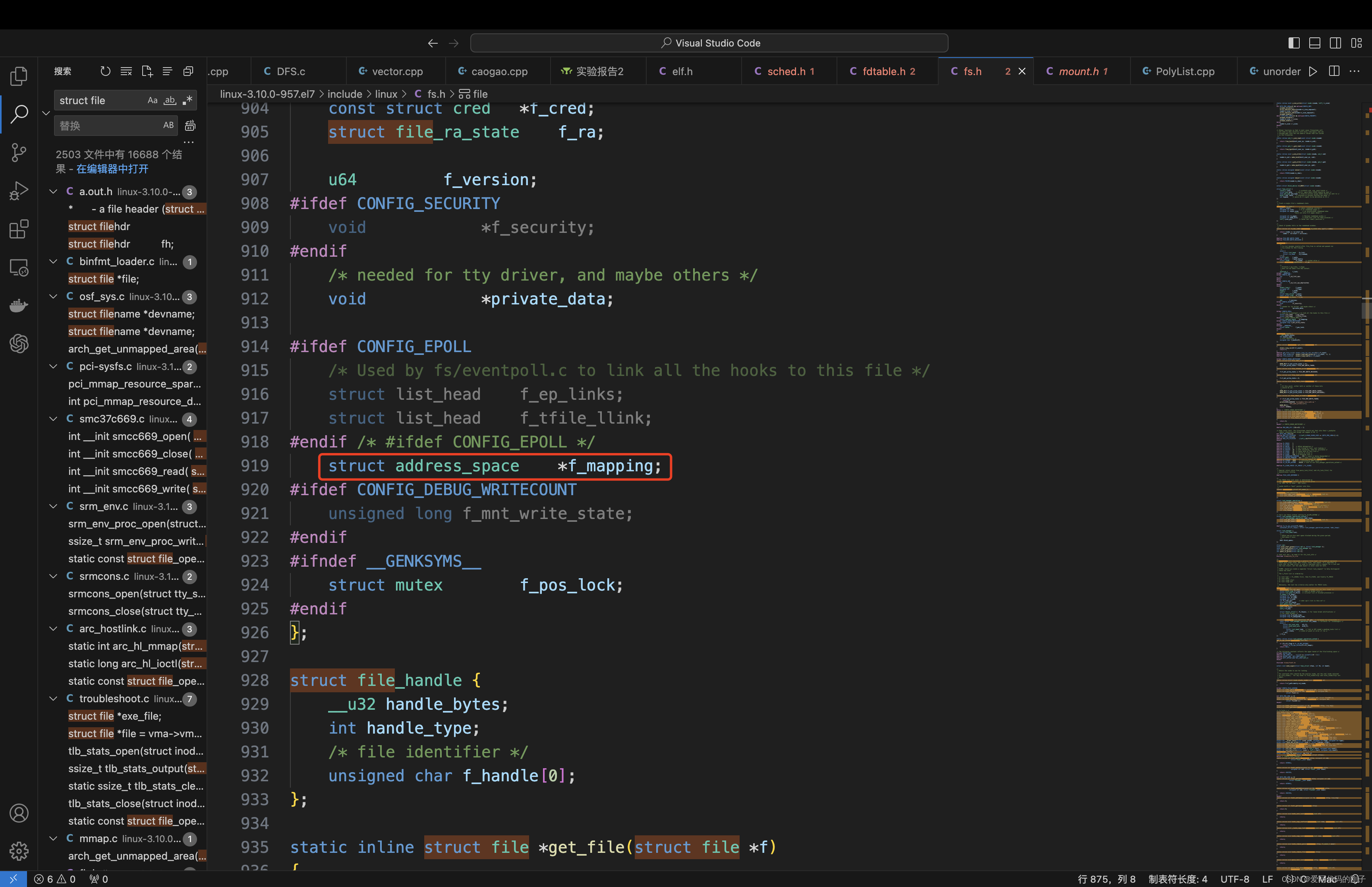
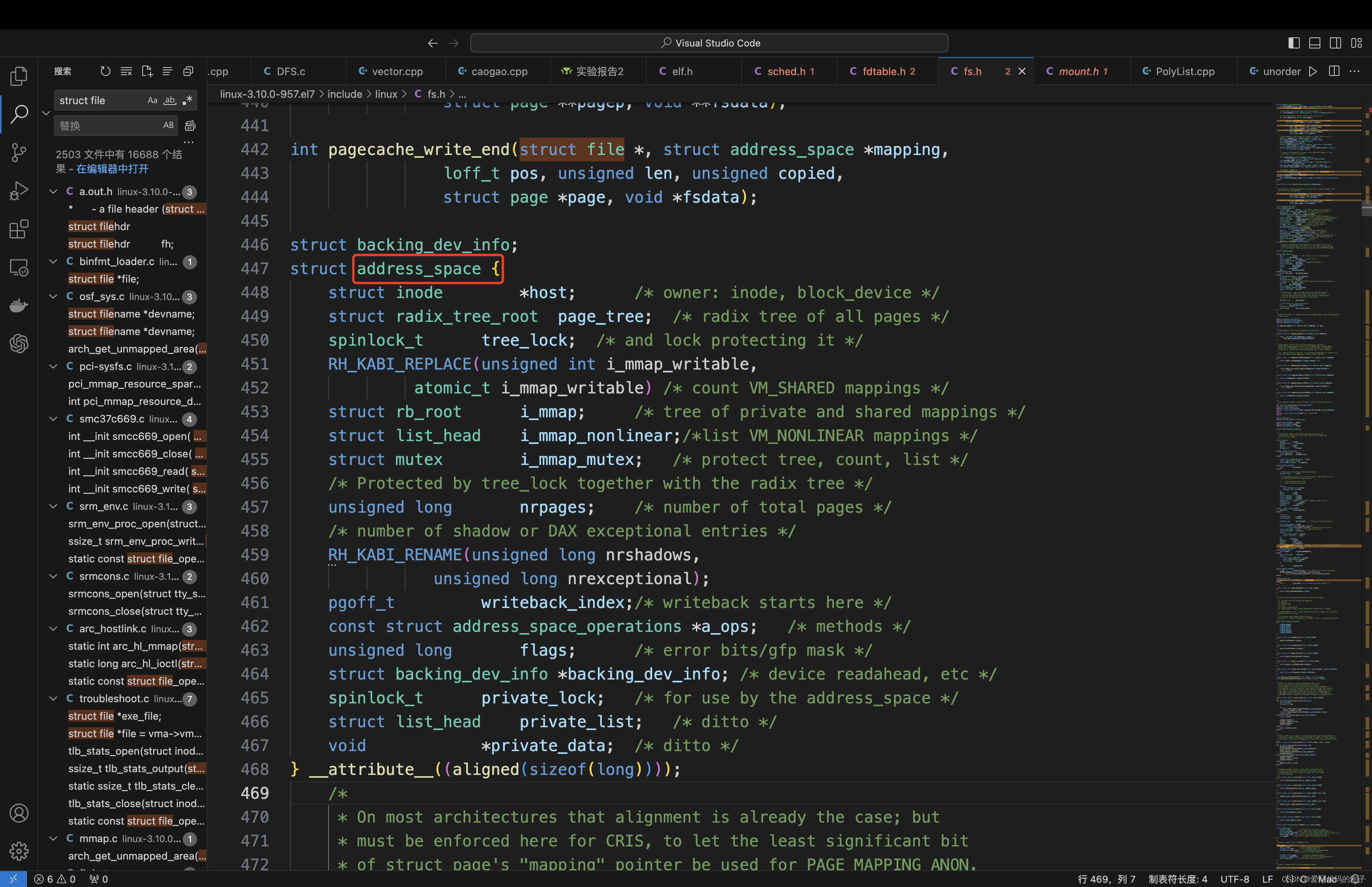
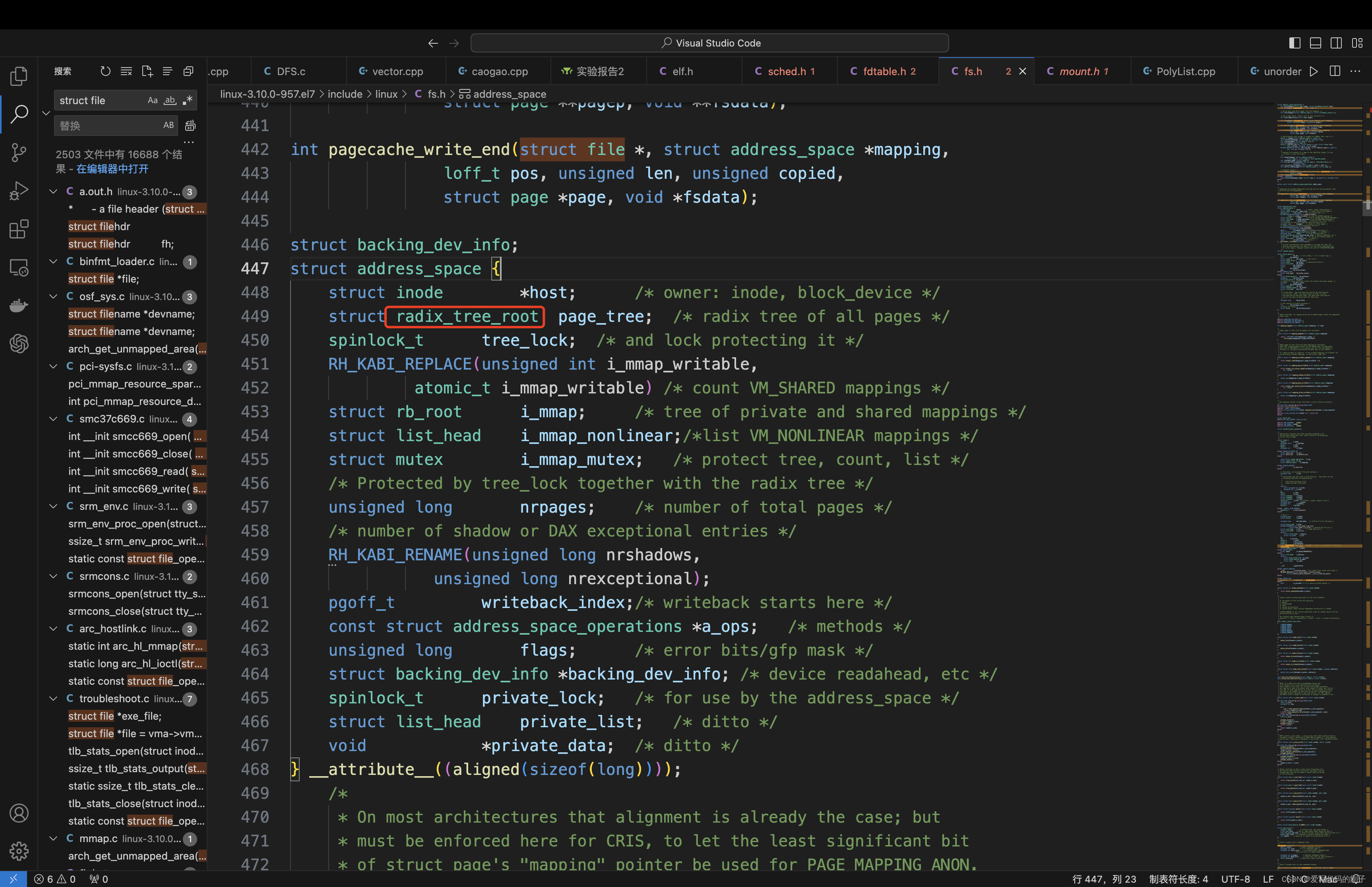
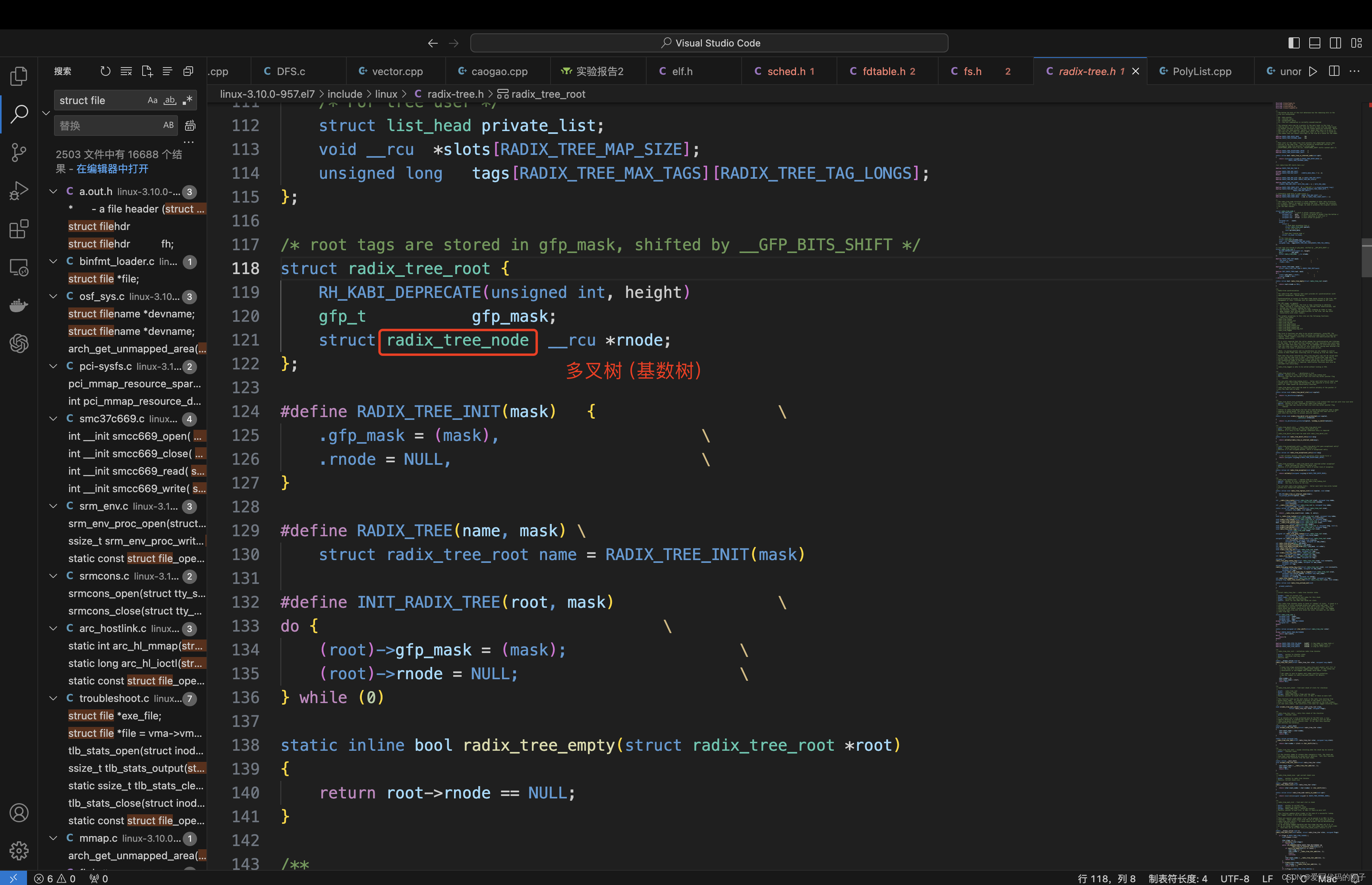
基数树(基树):或称压缩前缀树,是一种更节省空间的Trie(前缀树)。对于基数树的每个节点,如果该节点是确定的子树的话,就和父节点合并。
-
Linux内核中该基数树的叶子结点都会指向一个个的page对象(4kb),这个结构也叫做文件的页缓冲区
-
文件的内容按照4kb是有偏移量的,每一个数据块相当于有了编号,得到一个int类型的偏移量,其中int里面的32个比特位可以用16进制表示,得到一个地址,将该地址按照字典序到基数树中进行查找,即得到了偏移量和page之间的映射关系。(当我们得到了文件中对应数据的偏移量,即可转化为对应的地址,再从基数树中找到对应的page,将数据保存在page中,未来就可以根据page和偏移量,来确定page的刷新次序)
所以Linux中,每一个进程打开的每一个文件都要有自己的inode属性和自己的文件页缓冲区(radix_tree_root结构),需要定期将page中的数据刷新到Date blocks中(刷新机制(IO子系统)较为复杂,因为操作系统中存在非常多的IO请求,进程并不关心page中数据的刷新,这个为驱动层面的知识)
(操作系统会将IO请求用struct request结构管理起来,struct request会将与该请求相关的page放进来,还可以在request写入访问哪个磁盘以及相应的位置(逻辑地址),然后将request请求打给磁盘驱动,由磁盘驱动进行执行,就可以将数据从内存写到磁盘了)
所以操作系统中会存在大量的request队列,IO也需要排队(文件相关的page构建成struct request,再将其封装到IO_request_queue里,所谓的刷新就是将该队列里的struct request一个个地提交给对应的磁盘)
当然,为了磁盘能够高效地读取,我们也需要进行IO排序,再进行IO合并,以达到以最少的次数来访问磁盘。
以上由操作系统自动操作,操作系统有一堆线程来进行周期性执行对物理内存中的数据刷新的工作。
动态库和静态库
动静态库介绍:
- 静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静 态库
- 动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
- 一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文 件的整个机器码
- 在可执行文件开始运行以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)
- 动态库可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间。
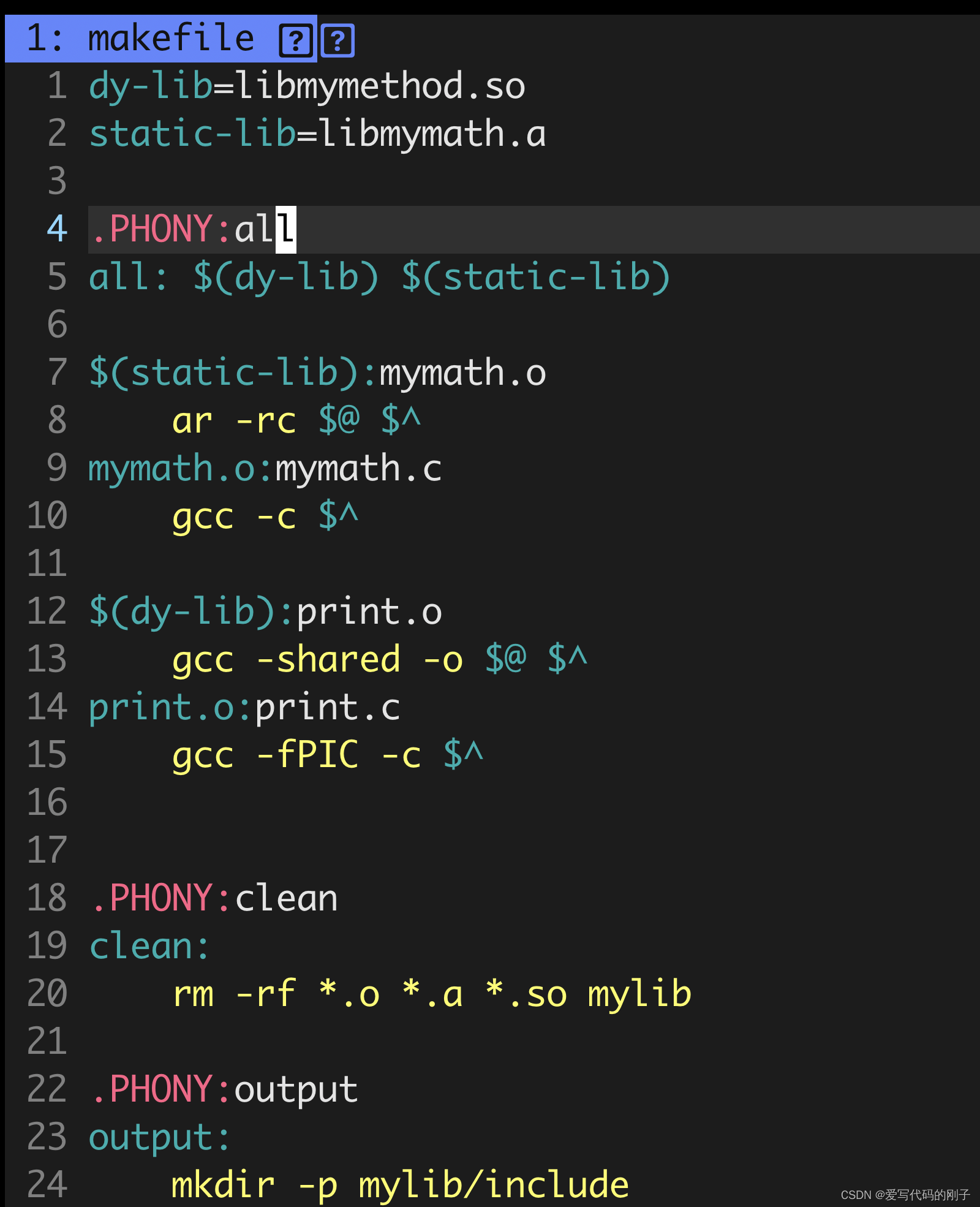
生成静态库
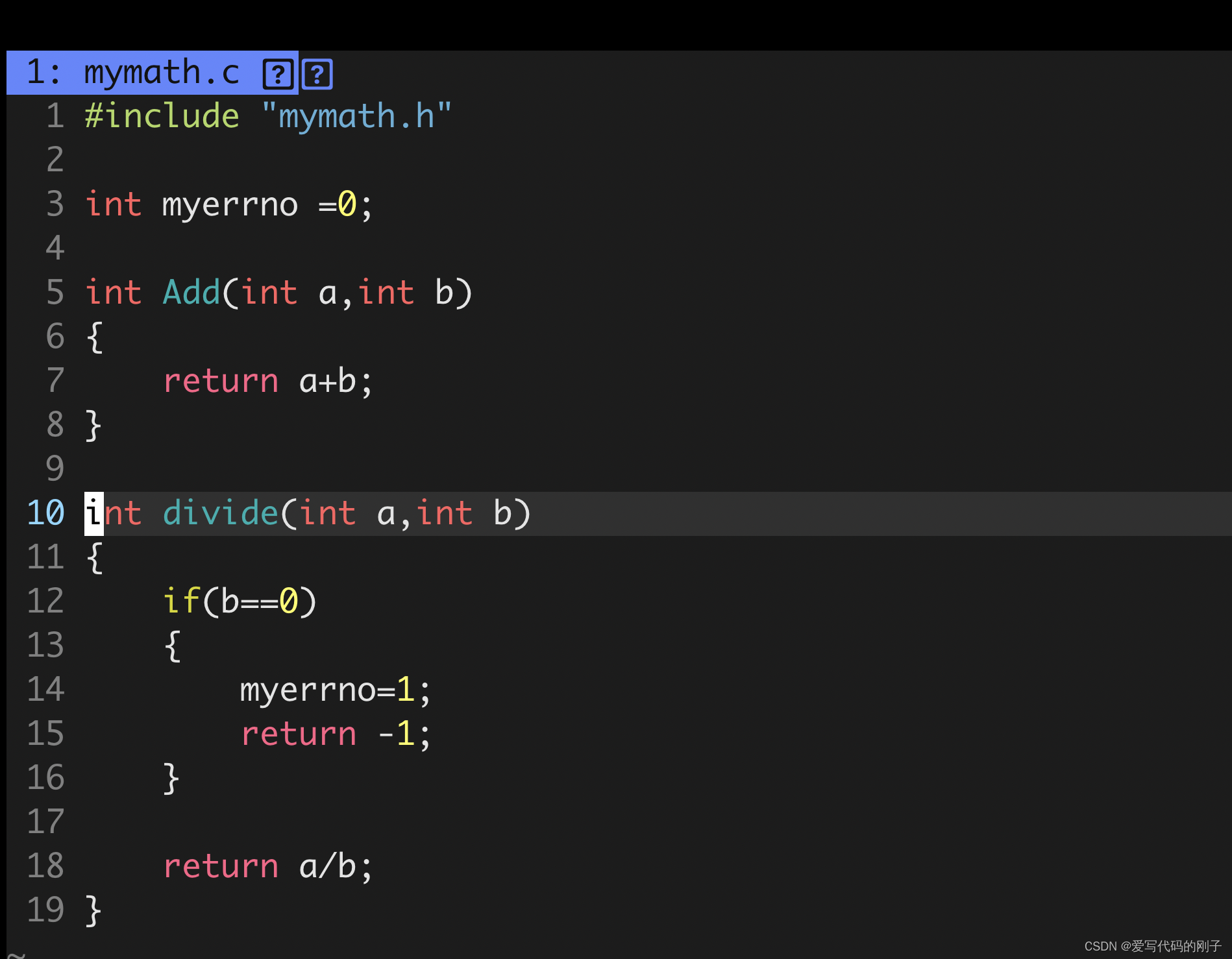
以mymath.c和mymath.h举例:
makefile文件:
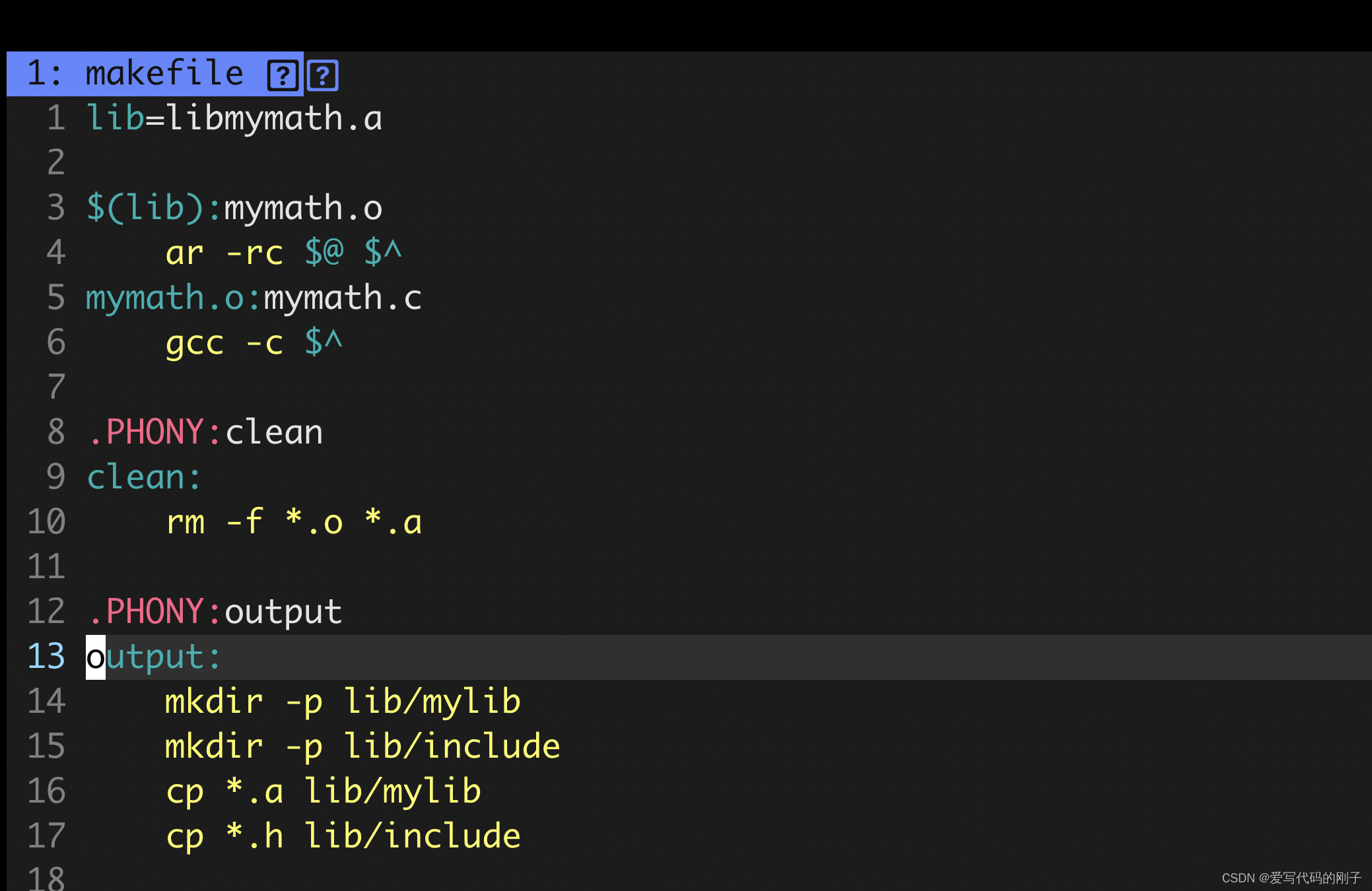
make output后会形成lib目录,之后拷贝目录给使用者即可。
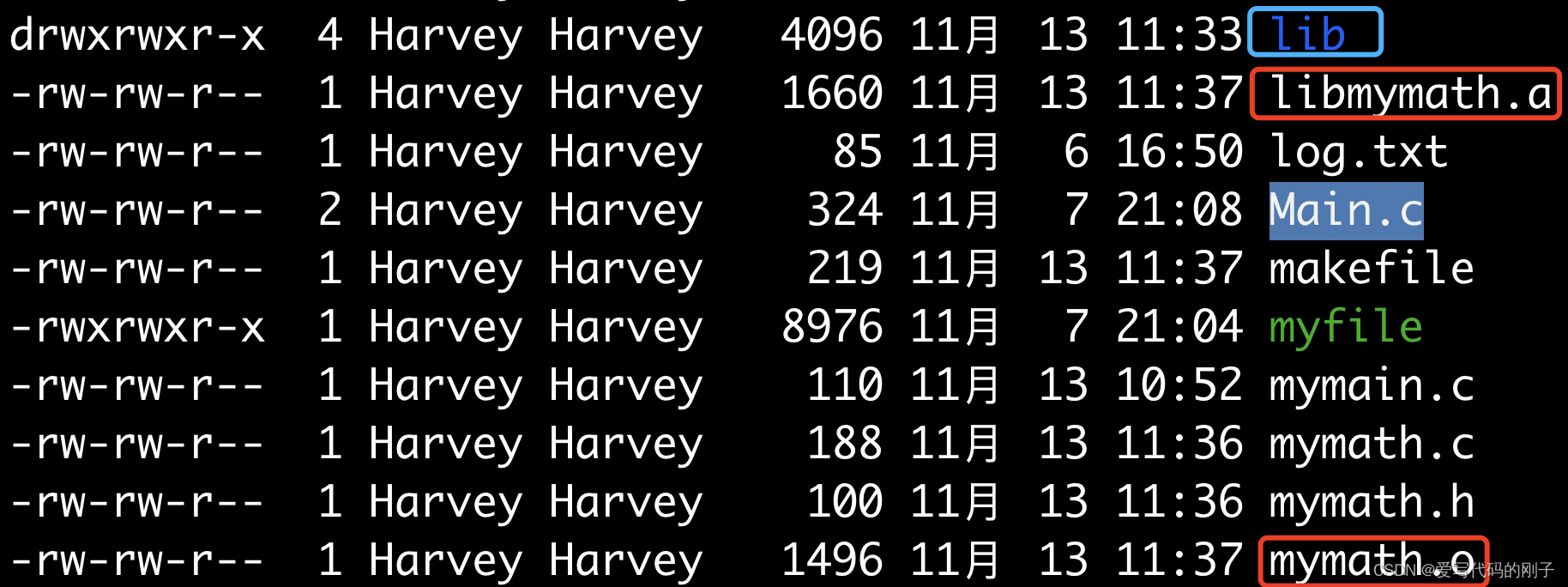
但是我们发现,使用gcc编译时发生错误:
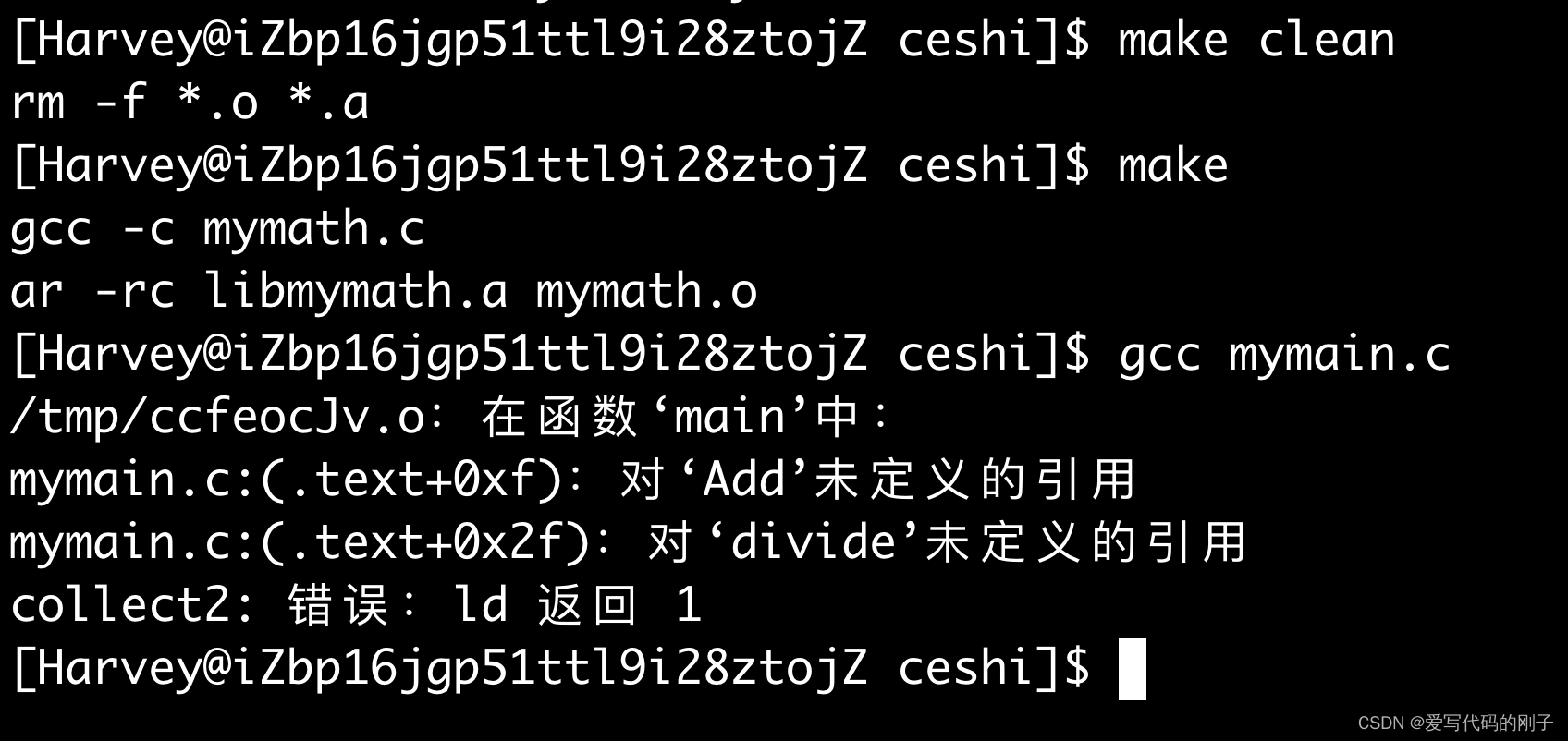
原因是gcc只会在系统指定的路径下进行搜索或者当前目录(必须和源代码在同一级,在目录里的不算),因为我们系统中不存在我们创建的lib目录,所以发生报错
gcc mymain.c -I +指定目录让编译器在指定目录里面寻找头文件(推荐),或者可以在mymain.c文件中把头文件的地址都带上

但是我们发现,上面发生了报错,找不到我们定义的Add函数,很明显是链接报错
从下面的图片中我们可以看出如果我们以-c选项进行编译,能编译通过

为什么?因为编译器找不到静态库,gcc会从系统路径下或者当前路径寻找静态库,由于我们的静态库在lib里面,编译器找不到。
【解决】:
指定静态库的名字:
错误写法:

==为什么还会出错?==因为库的真实名字为去掉前缀和后缀后剩下的名字!
【正确使用】:

-I :指定头文件的位置,不需要带头文件名字
-L :指定静态库库的文件目录
-l :指定相应的静态库名字(库名字为去掉后缀和前缀,-l最好紧跟名字)
似乎操作有点繁琐,那有没有其他的方法来解决这个问题呢?
既然gcc会自动从系统目录里寻找对应的文件,那我们是否可以将文件拷贝到系统路径下?
- 对头文件和静态库建立软链接,将它们分别放入系统对应的路径下
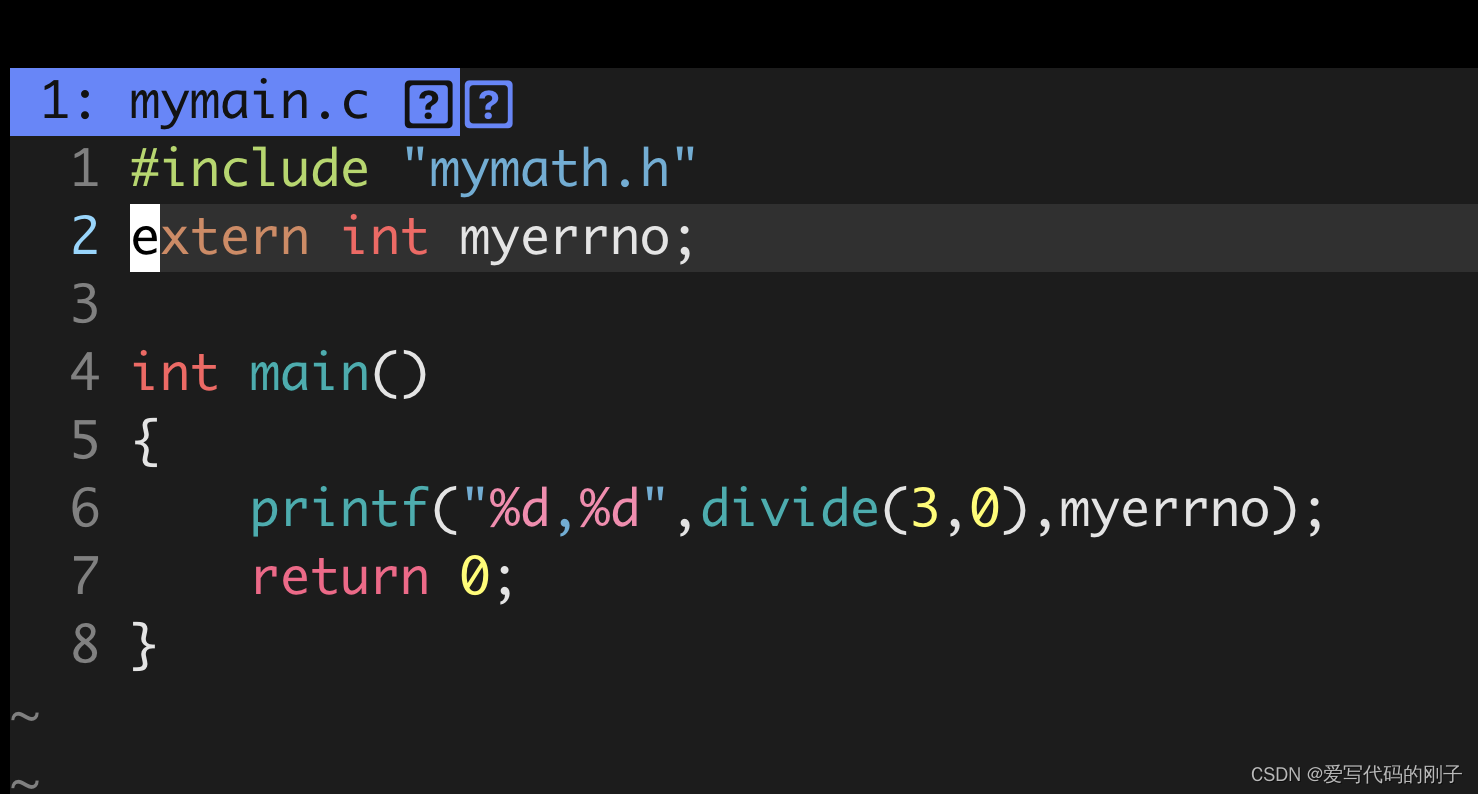
【问题】:按理来说myerrno应该等于1,为什么依旧是0呢?

【解释】:C语言是按照从右向左进行形参实例化的。
第三方库,往后使用的时候,必定要用gcc -l
errno的的本质是了解出错的原因
ldd +可执行文件查看文件的动静态链接
【问题】:为什么我们看不到mymath这样的静态库?
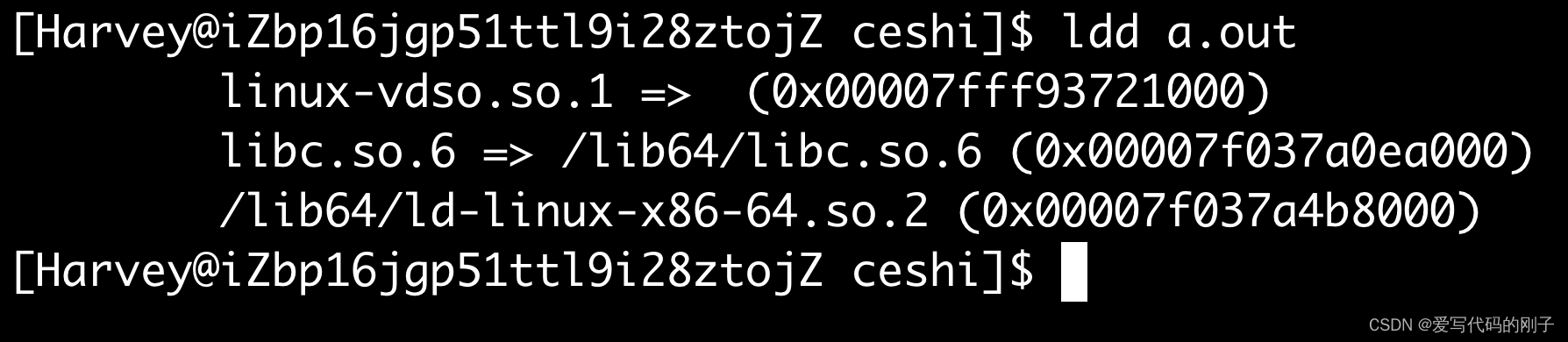
【解释】:gcc编译时默认选择动态链接
如果系统中只提供静态链接,gcc则只能对该库进行静态链接,动静态库也可以混合链接
如果系统中需要链接多个库,则gcc可以链接多个库
库搜索路径
- 从左到右搜索-L指定的目录
- 由环境变量指定的目录(LIBRARY_PATH)
- 由系统指定的目录(/usr/lib或者/usr/local/lib)
知道了系统库的搜索路径,我们可以选择将我们库的头文件和静态库拷贝至系统搜索路径下。

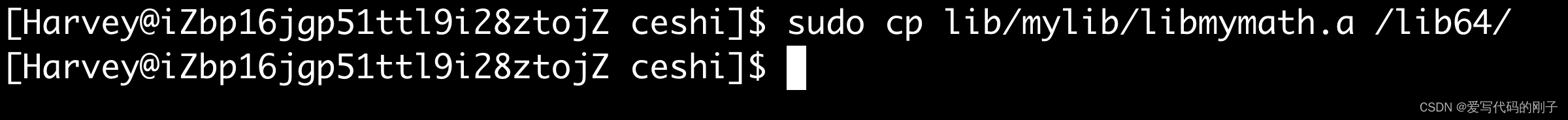
这两个操作叫做库的安装
拷贝成功:

但是还是出现了问题:
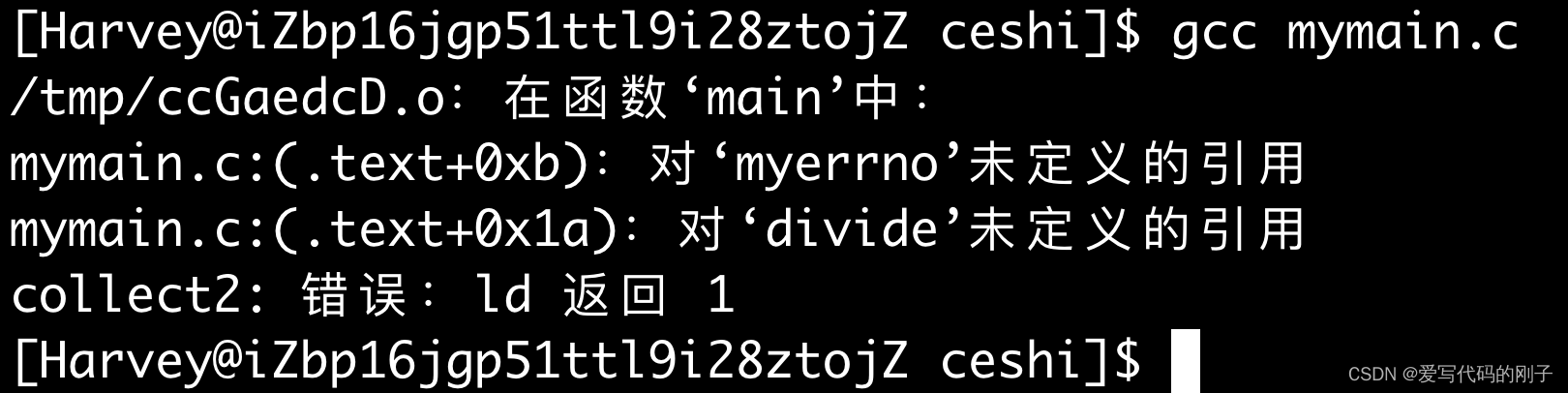
为什么编译仍然不会通过?
【解释】:虽然我们将自己的静态库拷贝至系统的路径下,但是gcc只认识系统调用接口和C/C++自己的标准库,所以我们在使用自己的库时还是需要指定名字:
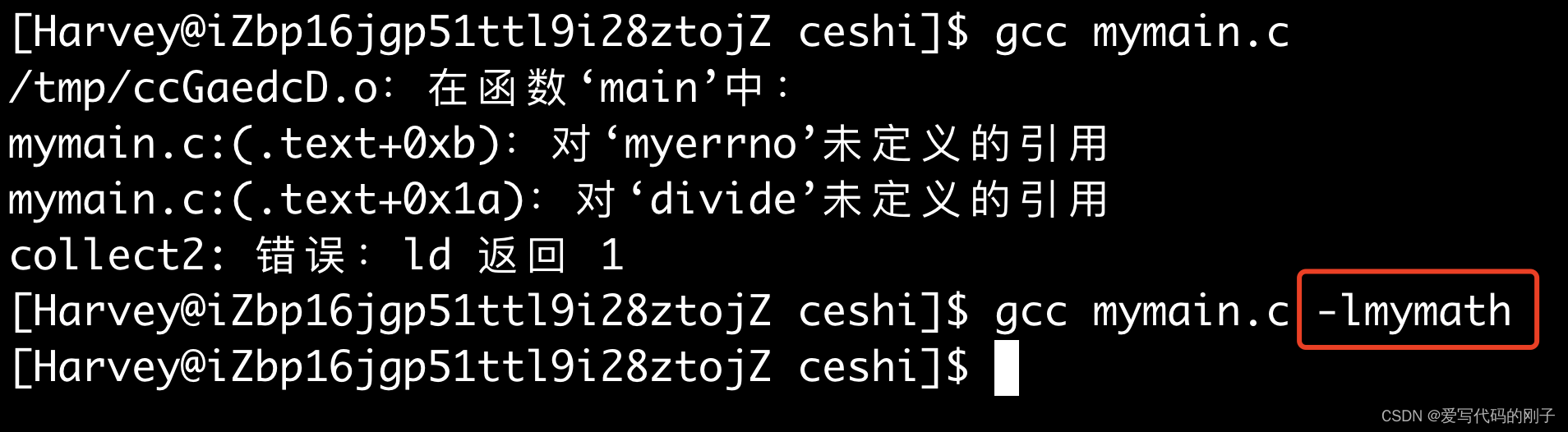
- 当然,我们还可以使用软链接的方式(但安装别人的库时并不推荐):



生成动态库
- shared: 表示生成共享库格式
- fPIC:产生位置无关码(position independent code)
- 库名规则:libxxx.so


【问题】:为什么动态库具有可执行权限?
因为动态库不像静态库那样不用加载到内存,==动态库需要像可执行程序那样先加载到内存中!==所以可执行权限的真正意义是:是否像可执行程序那样加载到内存,虽然本身文件不能执行,但是需要其他文件来使用它。
- 生成静态库和动态库:
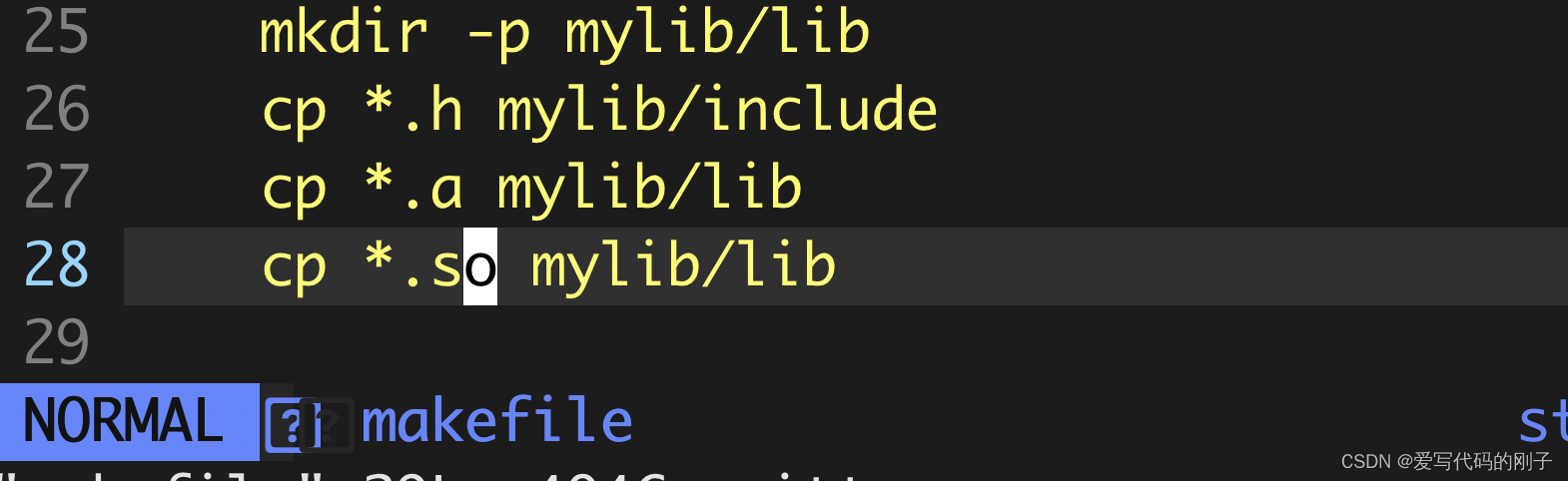
成功:
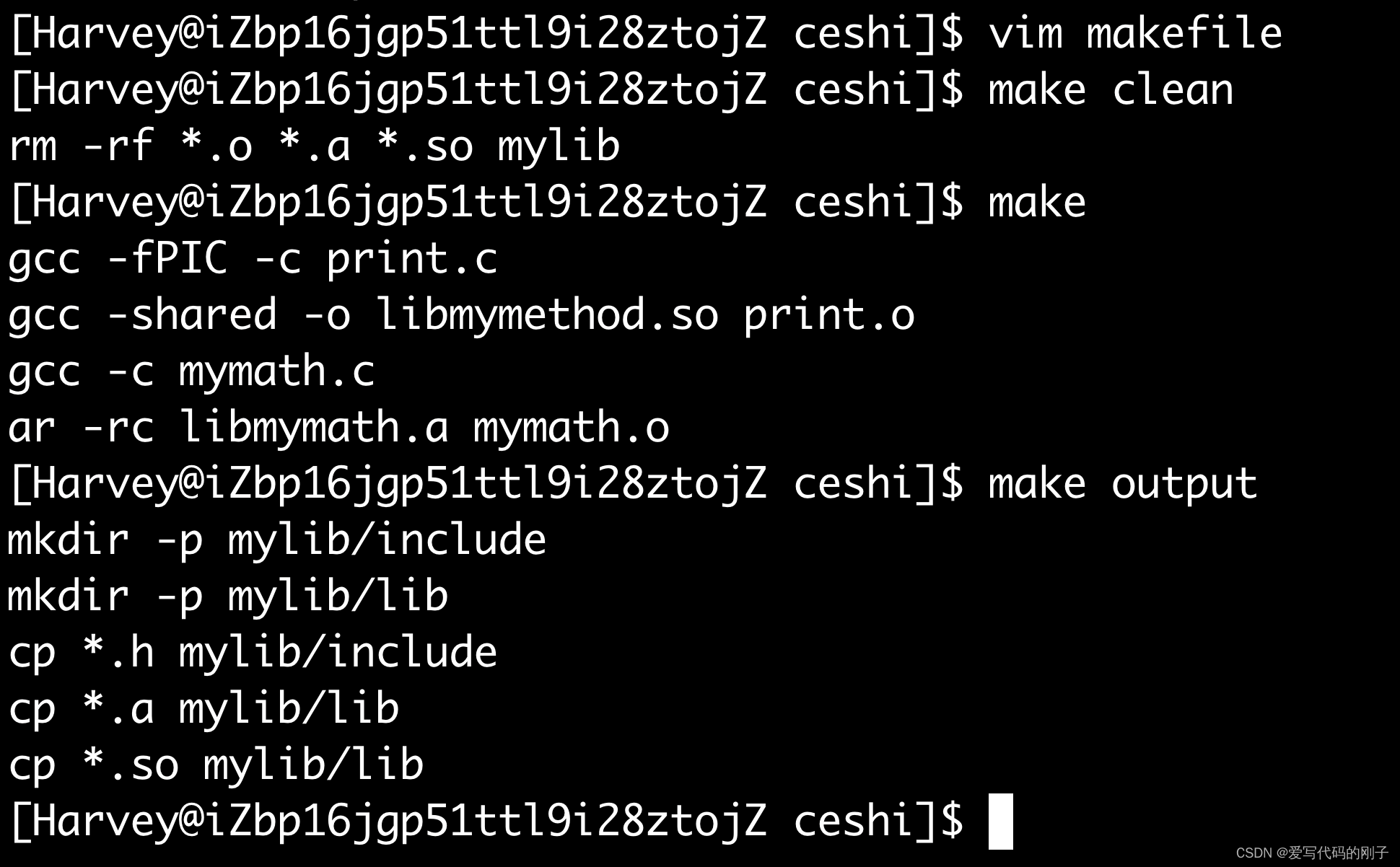
使用动态库
编译选项
- l:链接动态库,只要库名即可(去掉lib以及版本号)
- L:链接库所在的路径
与静态库类似的使用方法:

如果还想链接静态库可以-l静态库名字:

运行动态库
动态库在运行时可能还是会遇到找不到文件的问题!
【解释】:我们只告诉了编译器动态库的位置,但是我们没有告诉操作系统(加载器),所以加载的时候找不到了
【解决】:
- 在系统目录下建立软链接:

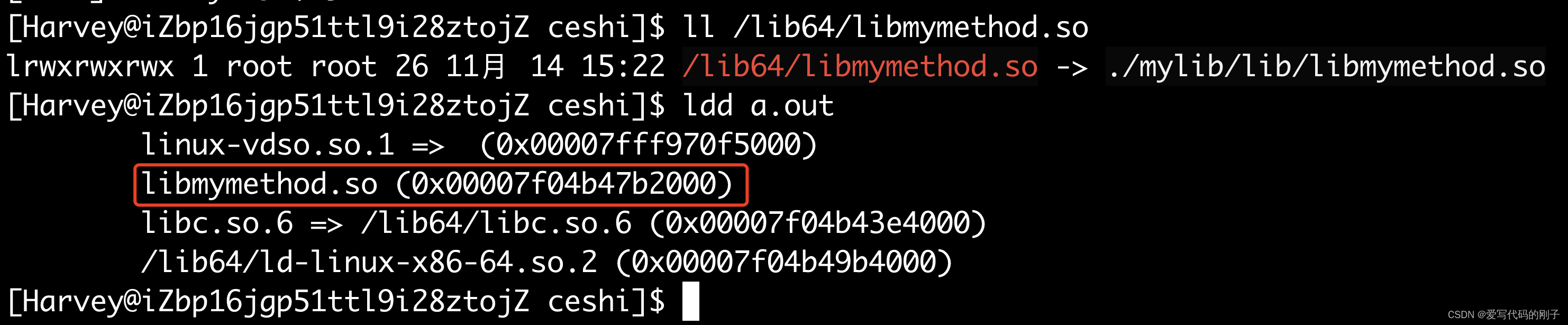
(或者直接拷贝动态库进系统的共享路径下)
2、导入环境变量:

(注意不要覆盖掉之前的环境变量,并且不需要加入具体的文件名,只要目录就行了)
还有没有更简单的方法?
ldconfig 配置/etc/ld.so.conf.d/,ldconfig更新

(系统的配置文件,里面存放的是路径)

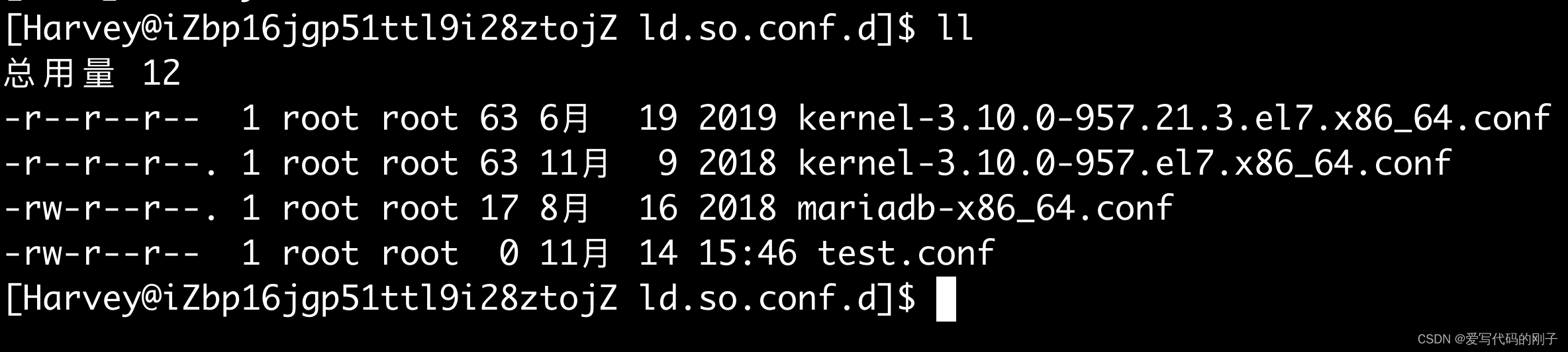
切换成root用户修改test.conf :
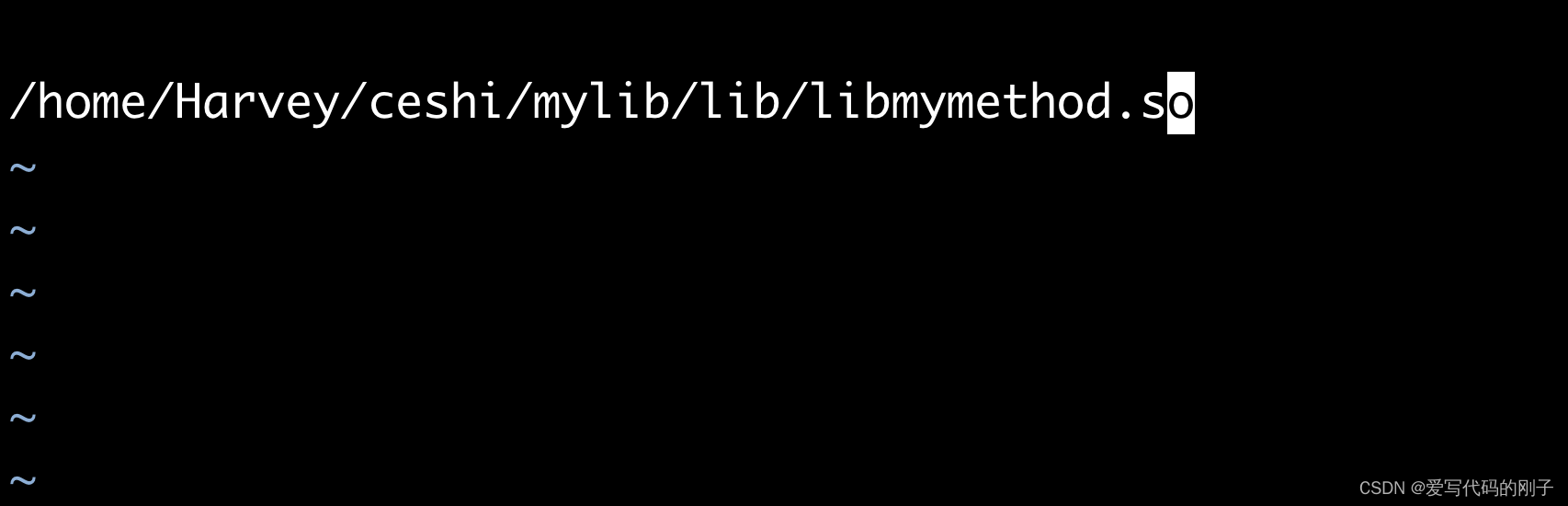
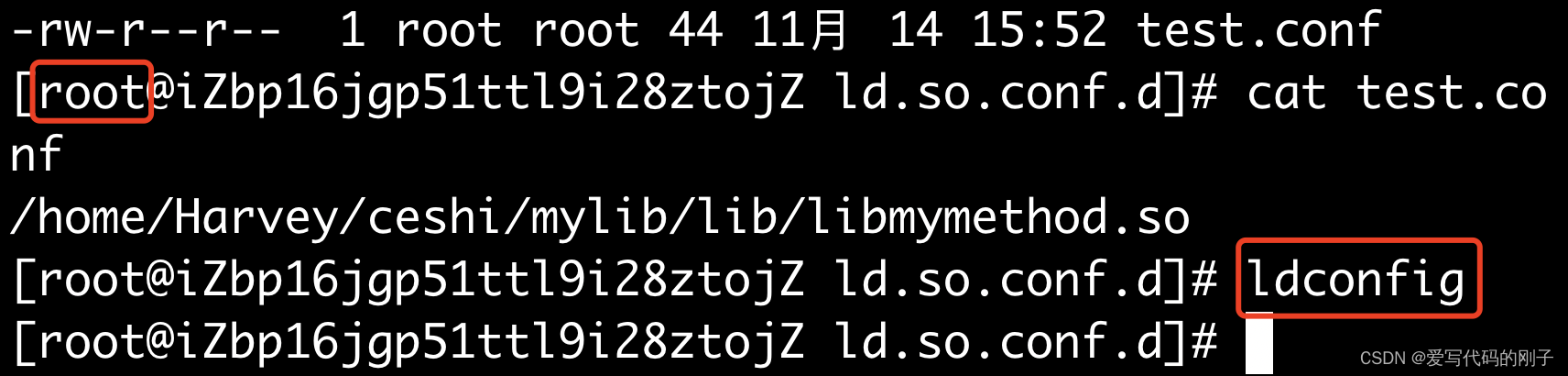
链接成功!:
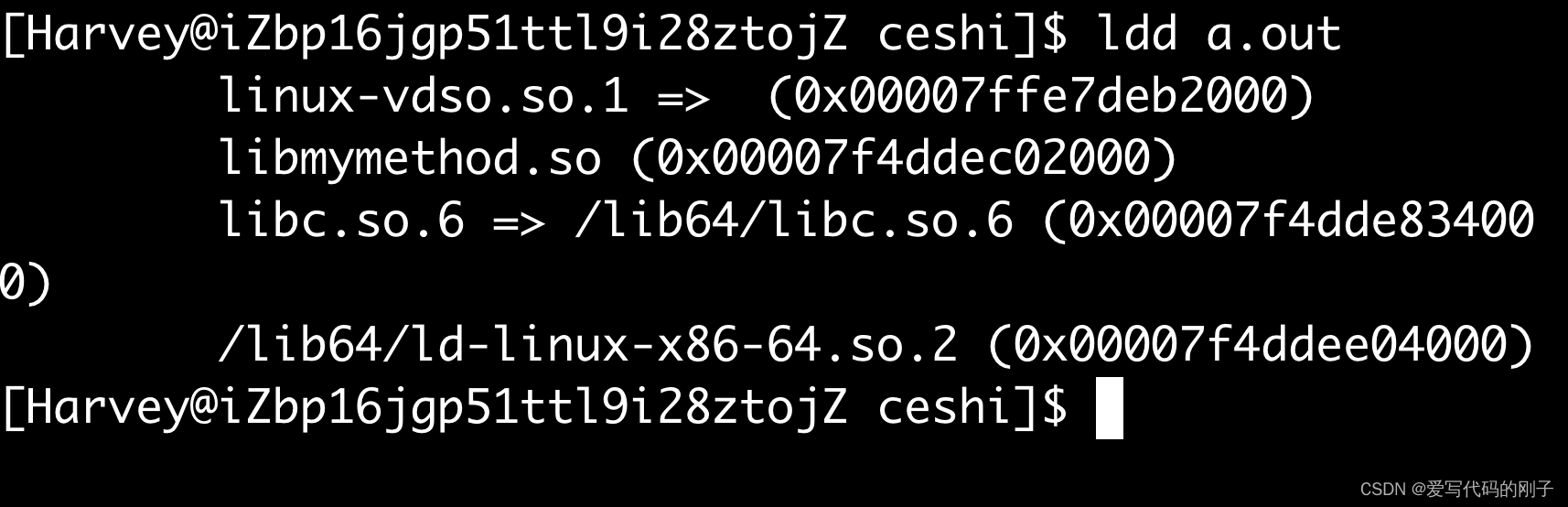
(系统全局范围内,永久有效,重新打开服务器也是有效的!)
总结:
1、拷贝.so文件到系统共享库路径下, 一般指/usr/lib 或/lib64(常用)
2、在系统默认路径的库路径 /usr/lib64/下建立软链接 /lib64
3、更改 LD_LIBRARY_PATH
4、/etc/ld.so.conf.d/ 建立自己的动态库路径配置文件,然后重新ldconfig
实际上我们用的库都是别人成熟的库,都采用直接安装到系统的方式。
使用外部库
系统中其实有很多库,它们通常由一组互相关联的用来完成某项常见工作的函数构成。比如用来处理屏幕显示情况的函数(ncurses库)
ncurses库:基于终端的文本图形和用户交互的库
官网链接
#include <math.h>
#include <stdio.h>
int main(void)
{
double x = pow(2.0, 3.0);
printf("The cubed is %f\n", x);
return 0;
}
gcc -Wall calc.c -o calc -lm
-lm表示要链接libm.so或者libm.a库文件
库文件名称和引入库的名称
如:libc.so -> c库,去掉前缀lib,去掉后缀.so,.a
小总结:
- 动态库在进程运行的时候是要被加载的(静态库没有)
- 常见的动态库被所有的可执行程序(动态链接的),都要使用动态库(共享库)
所以动态库在系统中加载之后会被所有进程共享!
如何加载?
【解释】:动态库会被加载到进程地址空间的共享区,当代码需要动态链接时直接跳转到共享区,将执行结果返回即可。
【结论】:
-
建立映射(磁盘中的动态库数据加载到物理内存,在用页表映射到虚拟内存),从此往后,我们执行到任何代码都是在我们的进程地址空间中执行的!
-
系统在运行中一定会存在多个动态库(OS管理,先描述再组织,系统中所有库的加载情况操作系统非常清楚)
【问题】:libc.so中可能会存在errno这样的全局变量,如果有进程修改了errno那是否会影响其他进程使用该动态库呢?
不会,因为会发生写实拷贝(这个库一旦被多个人共享,它所在的页就会,引用计数变成2,如果发现是被多个人共享的直接发生写实拷贝)