哈喽大家好,我是静姐,今天来给大家介绍在Python中使用selenium进行自动化操作
定义
Selenium是一个用于Web应用程序测试的自动化测试工具。使用Selenium可以驱动浏览器执行特定的动作,如点击、下拉等操作,还可以获取页面信息,断言页面是否如预期。在工作中我们可以用它来做基于web浏览器的UI自动化测试,也可以用它来做一些固定的页面操作,减少我们重复的手动操作。
准备工作
在使用selenium库时先使用pip命令下载
pip install selenium
selenium库安装完后还需要安装对应得了浏览器驱动,Selenium支持多种浏览器,如Chrome、Firefox等。本篇文章中就以Chrome举例说明。
python使用selenium自动化操作浏览器需要chromedriver驱动,但是浏览器每隔一段时间就自动更新版本,或者换一台电脑运行是就会报错。出现驱动版本和浏览器版本不对应的错误信息,所以这里我们直接在代码中自动下载与当前浏览器版本匹配的驱动。代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import chromedriver_autoinstaller
import os
def func():
# 获取当前文件所在目录的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 设置存放chromedtriver驱动的目录
driver_path = os.path.join(current_dir, "driver")
os.makedirs(driver_path, exist_ok=True)
# 自动安装符合当前浏览器的驱动目录
chromedriver_autoinstaller.install(path=driver_path)
chromedriver_path = os.path.join(driver_path, chromedriver_autoinstaller.get_chrome_version())
# 创建一个对象传入chromedriver路径
service = Service(chromedriver_path)
# 启动浏览器时使用传入的驱动路径
driver = webdriver.Chrome(service=service)
func()
再上面的代码中我们直接使用脚本程序去下载我们浏览器对应匹配的chromedriver版本,就直接避免了浏览器升级后导致之前下载的驱动版本不对应的问题,避免重复下载这一步骤。

不过上面的代码可以优化,在下载前去做一个判断,因为每次运行前都会去重复下载一次,所以需要再运行前去找driver_path下面有没有文件,如果有的话就不用下载,直接使用已有的路径,如果没有再去下载就行了,这个就自行优化哈~~~
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:110685036【暗号:csdn999】
开始使用
1.打开浏览器定位页面
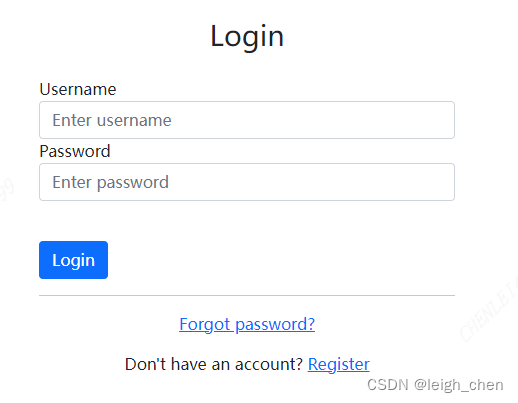
准备工作都完成后,接下来是打开浏览器了,这里我们以百度为例。
# 这里的驱动路径上面准备工作中已经说明了,就不阐述了
driver=webdriver.Chrome(service="你的chromedriver路径")
# 打开chrome浏览器后跳转到百度首页
# driver.get("http//:www.baidu.com")
上面使用webdriver.Chrome()方法打开浏览器,然后使用get()方法根据传入的URL地址跳转到对应网页,实现效果如下:

这样就完成了第一步打开浏览器,不过这里打开浏览器后不是全屏的状态,我们需要在打开浏览器后使用driver.maximize_window()方法让浏览器全屏就好了。
# 这里的驱动路径上面准备工作中已经说明了,就不阐述了
driver=webdriver.Chrome(service="你的chromedriver路径")
# 浏览器全屏
driver.maximize_window()
# 打开chrome浏览器后跳转到百度首页
# driver.get("http//:www.baidu.com")
2.元素查找
在selenium中,主要通过webdriver实例的find_element()或find_elements()方法来查找页面元素。常用的查找方式有:
-
id查找:
find_element(By.ID, 'elementId') 这种方法唯一确定一个元素,速度很快。 -
name属性值查找:
find_element(By.NAME, 'elementName'): name属性通常用于表单元素。 -
class name查找:
find_element(By.CLASS_NAME, 'elementClassName'): 根据CSS类名查找元素,注意类名不唯一。 -
tag name查找:
find_element(By.TAG_NAME, 'elementTagName'): 可以根据标签名称查找,如input、div等。 -
链接文本查找:
find_element(By.LINK_TEXT, 'elementLinkText'): 需要完全匹配链接文本。 -
部分链接文本查找:
find_element(By.PARTIAL_LINK_TEXT, 'elementLinkText'): 可以根据部分链接文本查找。 -
XPath查找:
find_element(By.XPATH, 'elementXPath'): XPath可以非常灵活地查找元素,是最强大的查找方式。 -
CSS选择器查找:
find_element(By.CSS_SELECTOR, 'elementCSSSelector'): 使用CSS选择器语法来查找元素。
以上方法都是直接使用By类进行查找元素的,使用By类进行元素定位时,需要将定位方式作为第一个参数,定位表达式作为第二个参数进行传递。在上面的查找方式中,其中id、class_name、css、xpath是用的比较多的,这个可以根据个人选择使用哪个方法。
3元素的操作方式
-
send_keys()
-
解释:用于向输入框等可输入元素中发送文本内容
-
用法:
element = driver.find_element(By.ID, "input")
element.send_keys("hello")
-
click()
-
解释:用于单击可点击的元素,如按钮、链接等
-
用法:
button = driver.find_element(By.NAME, "submit")
button.click()
-
clear()
-
解释:用于清空输入框的内容
-
用法:
element = driver.find_element(By.ID, "input")
element.clear()
-
submit()
-
解释:用于提交表单
-
用法:
login_form = driver.find_element(By.TAG_NAME, "form")
login_form.submit()
-
get_attribute()
-
解释:用于获得元素的属性值
-
用法:
element = driver.find_element(By.CSS_SELECTOR, "p.class")
value = element.get_attribute("class")
-
text
-
解释:用于获得元素的文本内容
-
用法:
element = driver.find_element(By.XPATH, "//p[1]")
text = element.text
这些是selenium中最常用的元素操作方式,可以通过它们实现页面的各种交互。
由于文章限制,本文就先介绍一下关于selenium框架一些基础知识,在后面我会接着将如何实际的去操作元素、以及如何查看页面html中源码元素,以及一些页面滑动、时间等待、内嵌页切换、浏览器窗口切换、结合unittest/pytest框架搭建一套通用的关键字驱动、数据驱动框架。
其实有很多同学都知道这个库,也能做一些简单的自动化,但是无法落实到实际的工作当中,如果有小伙伴对这一块的知识特别感兴趣的话留言区扣selenium,我统计下需要的小伙伴有多少,人数如果多的话我就加快更新这个系列的教程。
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。





![半平面求交 - 洛谷 - P3194 [HNOI2008] 水平可见直线](https://img-blog.csdnimg.cn/2020121310235323.png#pic_center)