目录
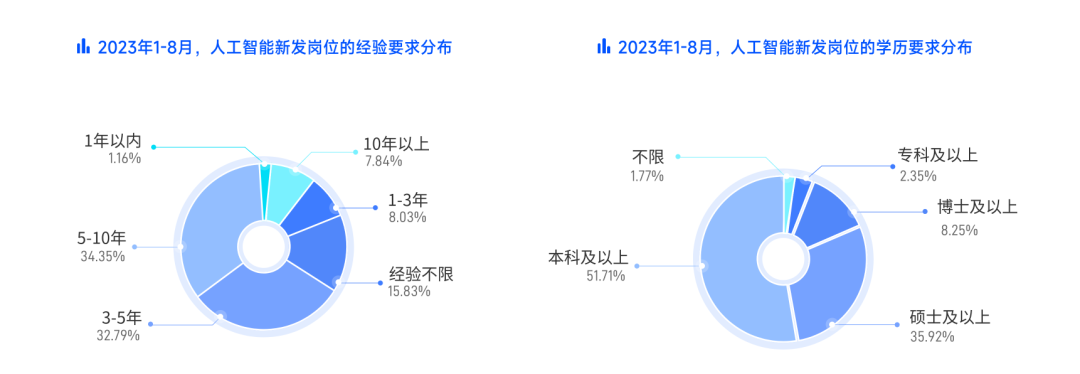
1、内存和磁盘
2、磁盘API
3、磁盘结构
4、访问磁盘页面
5、磁盘 vs SSD
5、磁盘空间管理
6、Files, Pages, Records
7、选择文件类型
8、堆文件
1)链表实现
2)页面目录实现
9、排序文件
10、关于计算标题页的注意事项
11、记录类型
12、页面格式
1)具有固定长度记录的页面
2)具有可变长度记录的页面
13、字段类型
14、一些练习题
1、内存和磁盘
每当数据库使用数据时,该数据都必须存在于内存中。 访问这些数据相对较快,但是一旦数据变得非常大,就不可能将所有数据放入内存中,这时候就要用到了磁盘。
磁盘用于轻易地存储数据库的所有数据,但磁盘读写数据成本高。
2、磁盘API
磁盘的基本 API 包括 READ 和 WRITE,分别代表将“页”数据从磁盘传输到 RAM 和将 “页” 数据从 RAM 传输到磁盘。 请注意,由于磁盘的结构,这两个 API 调用都非常慢。
3、磁盘结构
盘片通常以 15000 rpm 左右的速度旋转。 臂组件移入或移出以将磁头定位在磁头下方的所需轨道上并形成“圆柱体”。 任何一个时间只有一个磁头读/写块/页大小是(固定)扇区大小的倍数。
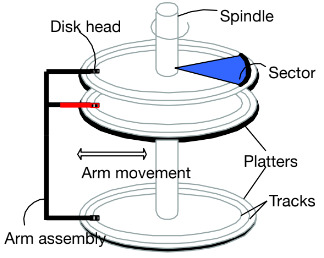
4、访问磁盘页面
访问(读/写)磁盘块的时间列出如下:
• 寻道时间(移动磁臂将磁盘头定位在磁道上); 平均 2-3 毫秒
• 旋转延迟(等待方块在头下旋转); 0-4 毫秒(15000 RPM)
• 传输时间(实际将数据移入/移出磁盘表面); 每 64KB 页 0.25 毫秒
5、磁盘 vs SSD
固态硬盘 (SSD) 或闪存是另一种存储数据的介质。 与磁盘不同,SSD 被组织成单元,并支持快速随机读取。 请注意,与 SSD 相比,硬盘在随机读取方面的性能非常差,因为空间局部性对于磁盘很重要,而顺序读取速度要快得多。 SSD 支持细粒度读取(4-8K读取)和粗粒度写入。 然而,SSD 中的单元在一定次数的写入擦除后往往会磨损(故障前仅擦除 2k-3k 次)。 为了解决这个问题,它使用一种称为“磨损均衡”的技术来不断移动写入单元,以确保没有单个单元被重复写入。 SSD 通常也比硬盘贵。 (1-2MB writes)

5、磁盘空间管理
磁盘空间管理是 DBMS 的最低层。 它负责管理磁盘空间。 其主要用途包括将页面映射到磁盘上的位置、将页面从磁盘加载到内存以及将页面保存回磁盘并确保写入。
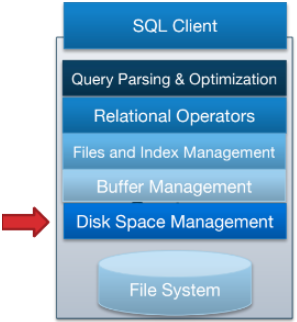
6、Files, Pages, Records
关系数据库的数据的基本单位是记录(行)。 这些记录被组织成关系(表),并且可以在内存中修改、删除、搜索或创建。
磁盘数据的基本单位是页,是从磁盘到内存传输的最小单位,反之亦然。 为了以一种与磁盘兼容的格式表示关系数据库,每个关系都存储在自己的文件中,并且其记录被组织到文件中的页面中。
根据关系的架构和访问模式,数据库将确定:(1) 使用的文件类型,(2) 文件中的页面如何组织,(3) 每页上的记录如何被组织,(4) 每条记录如何被格式化。

7、选择文件类型
有两种主要的文件类型:堆文件和排序文件。 对于每个关系,数据库根据关系访问模式的 I/O 成本选择要使用的文件类型。 1 个 I/O 相当于从磁盘读取 1 页或向磁盘写入 1 页,并且根据每种文件类型的访问模式中的插入、删除和扫描操作进行 I/O 计算。 选择 I/O 成本较低的文件类型。
8、堆文件
堆文件是一种没有特定页面顺序或页面记录顺序的文件类型,有两种主要实现方式。
1)链表实现
在链表实现中,每个数据页包含记录、可用空间跟踪器以及指向下一页和上一页的指针(字节偏移量)。 有一个标头页充当文件的开头,并将数据页分为完整页和空闲页。
当需要空间时,会分配空页并将其附加到列表的空闲页部分。
当空闲数据页变满时,它们从空闲空间部分移动到链表的满页部分的前面。 我们将其移到前面,这样我们就不必遍历整个整页部分来附加它。
另一种方法是在标题页中保留指向该列表末尾的指针。
我们使用哪种实现的细节对于本课程(基础学习我们只需要有一个印象即可)来说并不重要。
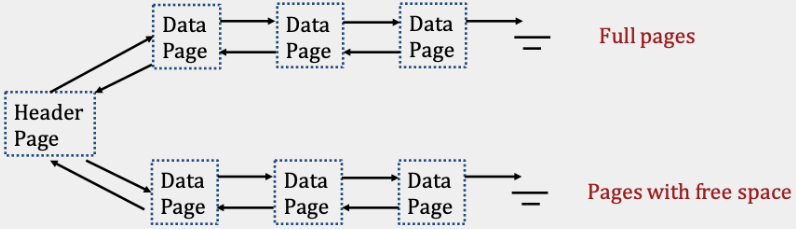
2)页面目录实现
页目录实现与链表实现的不同之处在于仅使用标题页的链表。
每个标头页都包含一个指向下一个标头页的指针(字节偏移量),其条目既包含指向数据页的指针,也包含该数据页内剩余的可用空间量。
由于标头页的条目存储指向每个数据页的指针,因此数据页本身不再需要存储指向相邻页的指针。

页目录相对于链表的主要优点是插入记录通常更快。为了在链表实现中找到具有足够空间的页面,可能需要读取标题页面和空闲部分中的每个页面。
相反,页目录实现只需要读取最多所有的标题页,因为它们包含有关文件中每个数据页上剩余多少空间的信息。
为了强调这一点,请考虑以下示例,其中堆文件被实现为链表和页目录。 每页有 30 字节,一条 20 字节的记录被插入到文件中:

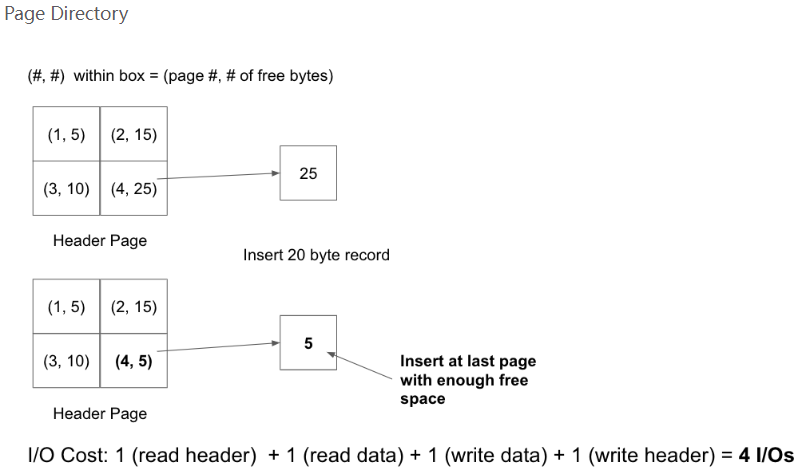
这只是一个小例子,随着页面数量的增加,这样的场景会导致在链表中插入比在页目录中插入要昂贵得多。
无论使用哪种实现方式,堆文件都比排序文件(下面讨论)提供更快的插入速度,因为记录可以添加到任何具有可用空间的页面,并且找到具有足够可用空间的页面通常非常便宜。 但是,在堆文件中搜索记录每次都需要进行完整扫描。 必须查看每页上的每条记录,因为记录是无序的,导致每次搜索操作的 N 个 I/Os 线性成本。 我们将看到排序的文件在搜索记录方面要好得多。
9、排序文件
排序文件是一种文件类型,其中页面被排序,同时每个页面中的记录被按键排序。
这些文件使用页面目录(Page Directories)实现,并通过基于记录排序方式对数据页面进行排序。在排序文件中搜索需要进行 logN 次 I/O 操作,其中 N 为页面数量,因为可以使用二分搜索找到包含记录的页面。与此同时,平均情况下插入需要 logN + N 次 I/O 操作,因为需要使用二分搜索找到要写入的页面,并且插入的记录可能导致所有后续记录都向后推移一个位置。平均而言,需要推移 N / 2 个页面,这涉及到每个页面的读取和写入 I/O 操作,从而导致 N 次 I/O 操作。
以下示例说明了最坏的情况。每个数据页面最多可以存储 2 条记录,因此在数据页面 1 中插入一条记录需要对其后的所有页面进行读取和写入,因为其余记录都需要被推后。

10、关于计算标题页的注意事项
在计算操作的 I/O 成本时,一个常见的困惑点是是否包括访问文件头页面的成本。当问题未提供底层文件实现时,请忽略读取/写入文件头页面的 I/O 成本。另一方面,当问题中提供了特定的文件实现(即使用链表或页面目录实现的堆文件)时,我们必须包括与读取/写入文件头页面相关的 I/O 成本。
11、记录类型
记录类型完全由关系模式确定,分为两种类型:固定长度记录(FLR)和可变长度记录(VLR)。FLR 仅包含固定长度字段(整数、布尔、日期等),具有相同模式的 FLR 由相同数量的字节组成。与此同时,VLR 既包含固定长度字段,也包含可变长度字段(例如varchar),导致具有相同模式的每个 VLR 可能具有不同数量的字节。VLR 在变长字段之前存储所有固定长度字段,并使用包含指向可变长度字段末尾的指针的记录标头。

无论格式如何,每个记录都可以通过其记录 ID([页码,页上的记录号])唯一标识。
12、页面格式
1)具有固定长度记录的页面
包含 FLR 的页面总是使用页面标头来存储当前页面上的记录数。
如果页面是紧凑的,那么记录之间就没有间隙。这使得插入变得简单,因为我们可以使用现有记录的数量和每个记录的长度计算页面内的下一个可用位置。一旦计算出这个值,我们就在计算出的偏移位置插入记录。删除稍微复杂,因为它需要将删除记录后的所有记录向页面顶部移动一个位置,以保持页面的紧凑性。
如果页面是非紧凑的,页面标头通常存储一个附加的位图,将页面分成插槽并跟踪哪些插槽是打开的或已占用的。

使用位图,插入涉及查找第一个开放的位,将新记录设置在相应的插槽中,然后设置该插槽的位。在删除时,我们清除已删除记录的相应位,以便未来的插入可以覆盖该插槽。
2)具有可变长度记录的页面
可变长度记录和固定长度记录之间的主要区别在于我们不再对每个记录的大小有保证。为了解决这个问题,每个页面使用一个页面页脚,其中包含一个跟踪插槽计数、自由空间指针和条目的插槽目录。页脚从页面底部开始而不是页面顶部,以便在插入记录时插槽目录有空间增长。
插槽计数跟踪总插槽数,包括已填充和空插槽。自由空间指针指向页面内的下一个空闲位置。插槽目录中的每个条目包含一个[记录指针,记录长度]对。
如果页面是非紧凑的,删除涉及查找插槽目录中记录的条目,并将记录指针和记录长度都设置为null。

对于将来的插入,记录将被插入到页面的自由空间指针处,并在任何可用的 null 条目中设置新的[指针,长度]对。如果没有 null 条目,将为该记录在插槽目录中添加一个新条目。插槽计数用于确定新插槽条目应添加到的偏移量,然后递增插槽计数。定期地,记录将被重新组织为紧凑状态,其中删除的记录被删除以为将来的插入腾出空间。
如果页面是紧凑的,删除涉及将插槽目录中记录的条目设置为 null。此外,删除记录后的记录必须向页面的顶部移动一个位置,并将相应的插槽目录条目向页面的底部移动一个位置。请注意,我们只在记录被删除的页面内移动记录。我们不会为文件跨页面重新整理记录。对于插入,记录将插入到自由空间指针,并且如果所有插槽都已满,每次都会添加一个新条目。
13、字段类型
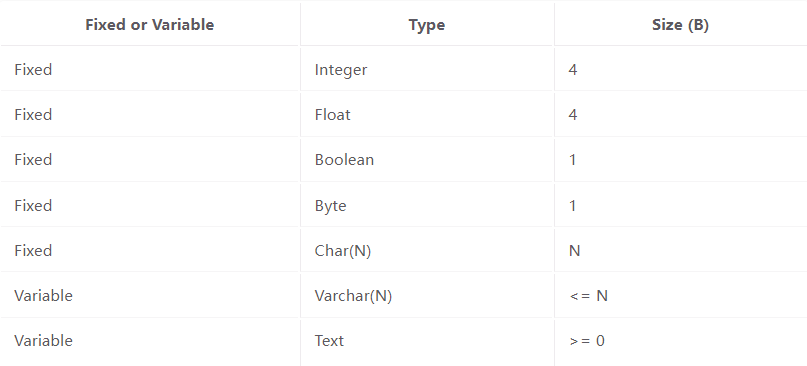
不同的数据类型在磁盘上占用不同的空间。CS186使用下表中显示的标准约定。
14、一些练习题
1、作为一个Page Directory实现的堆文件,在最坏情况下插入一条记录的 I/O 成本是多少?该目录包含 4 个页头页和每个页头页有 3 个数据页。假设至少有一个数据页有足够的空间来容纳该记录。
在最坏情况下,唯一具有足够空闲空间的数据页面位于最后一个页头页面上。因此,成本为7次 I/O。
4(读取页头页)+ 1(读取数据)+ 1(写入数据)+ 1(写入最后一个页头)= 7
2、以下模式中,一条记录的最小大小(以字节为单位)是多少?假设记录头部是5字节。(布尔值 = 1字节,日期 = 8字节)
name VARCHAR
student BOOLEAN
birthday DATE
state VARCHAR
VLR 的最小大小为 14 字节,当 name 和 state 都为 null 时发生。
5(记录头)+ 1(布尔值)+ 8(日期)= 14
3、在给定前面问题中的模式的情况下,可以存储在1 KB(1024字节)页面上的记录的最大数量是多少?
为了最大化可以存储的记录数量,我们将考虑当所有记录的大小都是最小值时的情况。在前面的问题中,记录的最小大小被计算为14字节。此外,我们还需要考虑插槽目录条目和页面页脚的其余部分,其中包含一个自由空间指针和一个插槽计数。插槽计数为4字节,自由空间指针为4字节,插槽目录条目为每个记录8字节。
因此,可以存储的最大记录数为 floor( (1024 - 8) / (14 + 8) )。
4、以下模式中,一条记录的最大大小(以字节为单位)是多少?假设记录头部是5字节。(布尔值 = 1字节,日期 = 8字节)
name VARCHAR(12)
student BOOLEAN
birthday DATE
state VARCHAR(2)
最大记录将要求每个可变长度字段(即定义为VARCHAR(x)的字段)达到其最大尺寸。
5(记录头)+ 12(VARCHAR(12))+ 1(BOOLEAN)+ 8(DATE)+ 2(VARCHAR(2))= 28
5、插入了4个VLRs(可变长度记录)到一个空白页面。插槽目录的大小是多少?(int = 4字节)假设插槽目录最初没有插槽。
插槽目录包含插槽计数、自由空间指针和条目,这些条目是记录指针、记录大小的对。由于指针只是页面内的字节偏移量,因此目录的大小为40字节。
4 (slot count) + 4 (free space) + (4 (record pointer) + 4 (record size)) * 4 (# records) = 40
6、假设你有一个堆文件,实现为链表结构,其中头部页面连接到两个链表:一个包含满页面的链表,一个包含有空闲空间的页面的链表。有10个满页面和5个有空闲空间的页面。在最坏情况下,你需要读取多少个页面来查看是否有足够空间存储一些给定大小的记录?
在最坏的情况下需要读取页头页,然后读取所有 5 个页面。因此,成本是 6 次 I/O。
7、真或假:假设你正在使用页面目录实现,在最坏情况下,必须检查所有数据页面以找到足够空闲空间插入新记录的页面。
错误;页面目录实现可以利用存储在页头页中的元数据,以确定哪些数据页面有足够的空闲空间。而页头页中的条目包含指向数据页的指针以及该特定数据页的剩余空闲空间量。
以上,SQL note2:DIsks and Files
祝好。