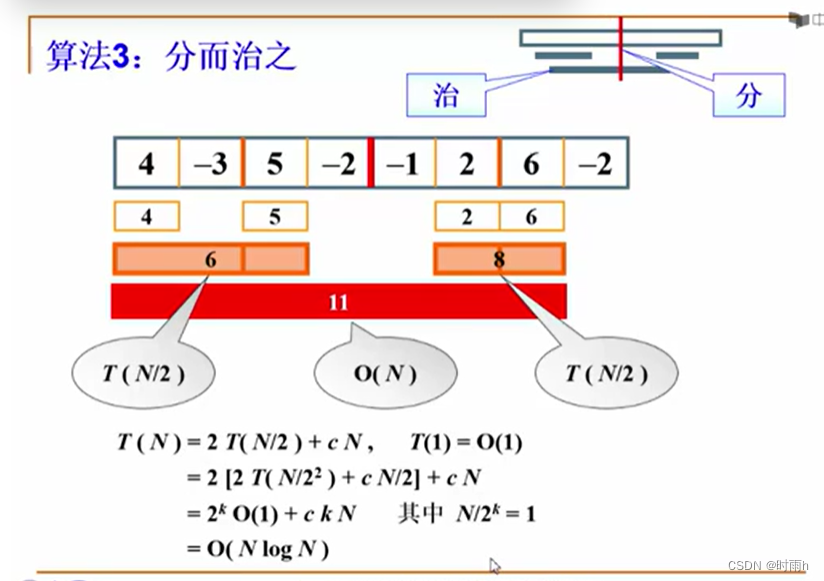
上周,发了一篇关于大语言模型+图数据库技术相结合的文章,引起了很多朋友的兴趣。当然了,这项技术本身就让俺们很兴奋,比如我就是从事图研发的,当然会非常关注它在图领域的应用与相互促就啦。
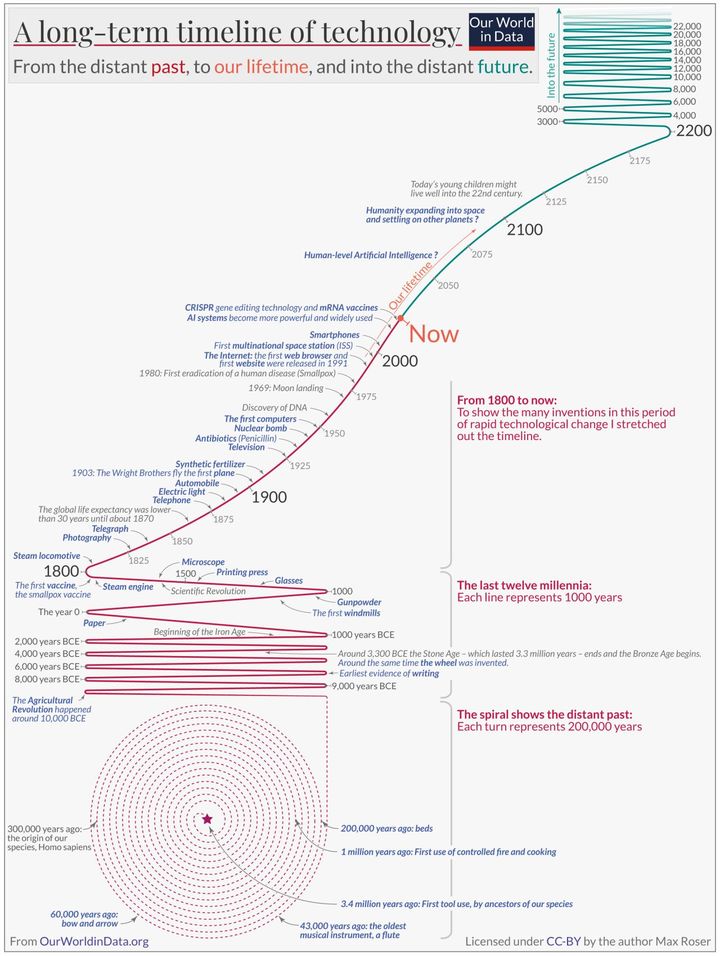
纵观人类文明历史,从第一次工业革命之后,技术成为了改变世界进程的引擎,生产力和生产关系进入了一个全新的时期。如从美索不达比亚第一株被驯服的小麦,人类从原始狩猎采集转为种植和定居,蒸汽机改变了人类对能源的依赖模式,人类从此步入城市化和工业化。时至今日,我们又在经历一个新的创新周期——人工智能驱动的数字化时代(虽然很多人都在担心智能伦理方面的问题,但并没有影响各界对该技术的热情和关注。)
本文围绕以下几点聊聊,当是对前一篇文章《LLM+Graph:大语言模型与图数据库技术的协同》的一个前传吧。
· 啥是生成式人工智能
· 生成式人工智能的历史
· 法学硕士又是神马东西?
· 生成式人工智能都有啥类型和关键特征?
· 有什么局限性? 和图数据库技术的结合
一、啥是生成式人工智能
生成式人工智能是一种先进技术,能够生成文本、语音、视觉甚至合成数据形式的内容。
它利用深度学习模型和大型语言模型来完成创建新颖内容的任务。
它绝对不仅仅是进行上下文对话,还包括定制建议、直观的解决方案等等。其应用广泛分布在从高科技到农业和消费品的各个行业。
Gartner将生成式 AI 置于 2023 年新兴技术成熟度曲线期望最高的位置
德勤估计,到 2032 年,生成式人工智能的市场规模将达到 200B 美元。这占人工智能总支出的约 20%,高于目前的约 5%
二、生成式人工智能的历史

其历史至少可以追溯到 70 年前,当时人类真正开始怀疑机器是否有能力像人类一样思考和处理。
20 世纪 50 年代:文本分析 — 人工智能的黎明
20世纪50年代至60年代初,人工智能(AI)领域仍处于起步阶段。研究人员正在探索创造能够模拟人类智能的机器的可能性。这个方向最早的努力之一是文本分析。这个时代见证了用于处理和分析文本数据的基本计算机程序的发展。早期的文本分析系统主要专注于信息检索和关键字提取等简单任务。这个想法是让计算机能够以类似于人类理解的方式理解和操作文本。虽然这些努力在当时具有开创性,但它们的能力有限,并且缺乏我们今天与人工智能相关的复杂程度。
20 世纪 60 年代:基于规则的系统和知识库
在 20 世纪 60 年代后半叶和整个 70 年代,人工智能研究转向基于规则的系统和知识库。研究人员试图使用明确的规则和逻辑推理将人类知识和专业知识编码到计算机程序中。这种方法导致了专家系统的发展,该系统能够通过遵循预定义的规则来解决特定问题。专家系统标志着人工智能向前迈出了重要一步,因为它们证明计算机可以执行需要人类专业知识的任务。然而,它们受到大量手动规则编写的需要和对新领域的有限适应性的限制。
20 世纪 80 年代:自然语言处理出现
20 世纪 80 年代和 90 年代见证了自然语言处理 (NLP) 的出现,这是人工智能中的一个关键领域,旨在使机器能够理解和生成人类语言。研究人员开始开发更先进的技术来解析和分析文本,为机器翻译、语音识别和情感分析等应用铺平道路。NLP 系统在很大程度上仍然是基于规则的,依赖于语法和句法规则。这些系统能够处理比早期文本分析更复杂的语言任务,但它们距离实现人类水平的语言理解还很远。
2000 年代:机器学习和大数据革命
世纪之交标志着随着机器学习的兴起和大量数字数据的出现,人工智能研究发生了重大转变。事实证明,机器学习算法,特别是神经网络,在解决各种人工智能任务(包括与文本和语言相关的任务)方面非常有效。这个时代催生了“大数据”的概念和大规模数据分析的发展。随着深度学习等技术的出现和海量数据集的出现,人工智能模型越来越能够理解和生成人类语言。
2020 年代:GPT-3 和生成式 AI 的突破
2020年代,世界见证了GPT-3(生成式预训练变压器3),这是一种革命性的人工智能模型,标志着人工智能和自然语言处理领域的一个重要里程碑。GPT-3 在大量文本数据上进行了预训练,可以生成高度连贯且上下文相关的文本。
GPT 的发展仍在继续,推出了运行 ChatGPT 的 GPT 3.5 和最新版本的 GPT 4。
三、法学硕士又是神马东西?
如果不了解大型语言模型,那么关于生成式人工智能的讨论就是不完整的,人们简称为法学硕士。大型语言模型是在具有大量参数的大型未标记数据集上进行训练的。GPT-3 经过超过 1750 亿个参数的训练!
值得一提的是,LLM(语言模型)和生成式人工智能是相关的概念,但它们在侧重点、能力和应用方面存在明显差异。
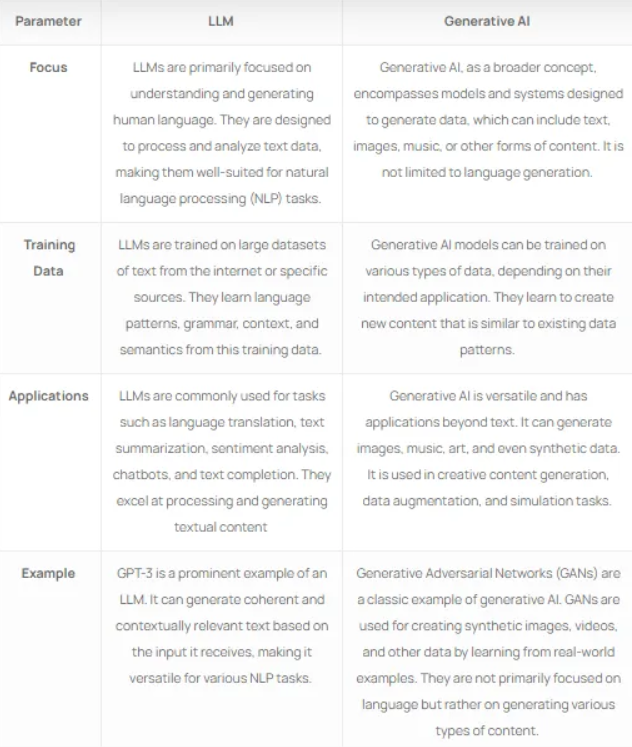
一些众所周知的法学硕士是:
Open AI 的 GPT 3、3.5 和 4
谷歌的 LaMDA 和 PaLM
Meta 的 LLaMA
NVidia 的 NeMO 法学硕士
在这个列表中,Meta 的 LLaMA 是一个开源 LLM,世界各地的开发人员都可以利用它来创建可定制的私有模型。
四、生成式人工智能都有啥类型和关键特征?
生成式 AI 模型是人工智能 (AI) 模型的一个子集,旨在生成与现有数据相似或遵循现有数据中的模式的新数据。生成式 AI 模型不同于其他专注于分类、预测或强化学习的 AI 模型。
以下是生成式人工智能模型的一些关键特征和类型:
数据生成:生成式人工智能模型能够创建模仿训练数据中观察到的模式或风格的新内容。该内容可以采用多种形式,包括文本、图像、音乐等。
无监督学习:许多生成模型采用无监督学习技术,模型在没有明确标签或目标的情况下学习数据中的模式和结构。这使它们能够生成数据,而不需要应生成的具体示例。
可变性:生成模型通常以其产生不同输出的能力为特征。如它们可以生成不同风格的艺术,以不同方式重新表述相同的文本段落,或者图像的多个版本。
一些常见类型的生成人工智能模型:
生成对抗网络(GAN):GAN 由两个处于竞争关系的神经网络(生成器和判别器)组成。生成器创建数据,而鉴别器评估该数据的真实性。这种对抗性过程导致生成器提高了创建真实数据的能力。GAN 已广泛用于图像生成、风格迁移和内容创建。
变分自动编码器 (VAE):VAE 是基于概率建模原理的生成模型。他们的目标是了解数据的潜在概率分布。VAE 通常用于图像生成、数据压缩和图像重建。
循环神经网络 (RNN):RNN 是一种专门为序列数据(例如文本和时间序列数据)设计的神经网络架构。它们用于文本生成、机器翻译和语音识别。然而,传统的 RNN 在捕获长期依赖性方面存在局限性。
长短期记忆 (LSTM) 网络:LSTM 是一种特殊类型的 RNN,可以捕获顺序数据中的长程依赖性。事实证明,它们在自然语言处理任务中非常有效,包括语言建模、文本生成和情感分析。
生成式预训练 Transformer (GPT):GPT 模型是生成人工智能领域的最新突破。这些模型利用 Transformer 架构和对文本数据的大规模预训练来生成连贯且上下文相关的文本。他们擅长各种自然语言理解和生成任务,包括聊天机器人、内容生成、翻译等。
五、有什么局限性? 和图数据库技术怎么结合?
以下是大模型局限性的几个表现列举:
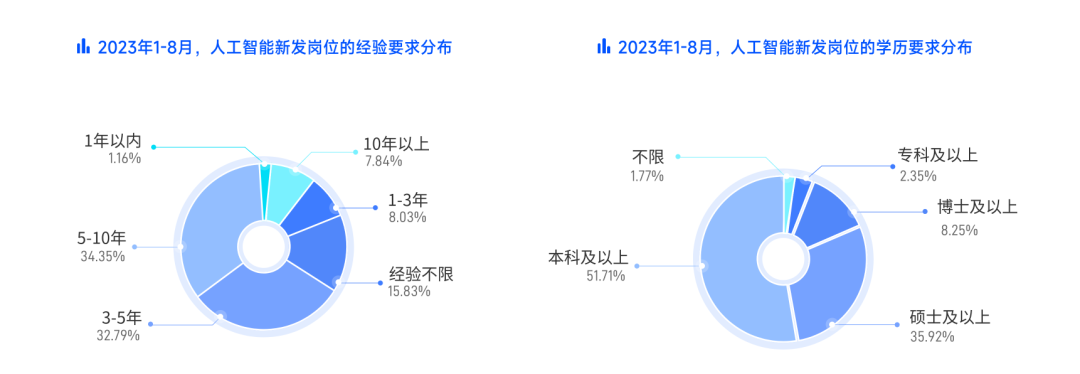
模型的知识受限于它所训练的数据。见下图:
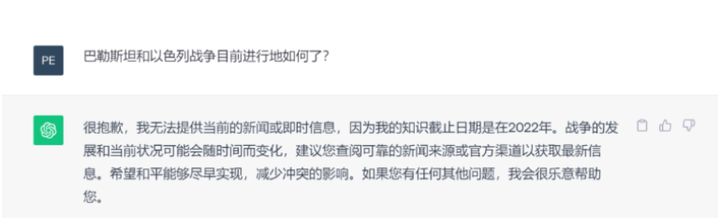
黑盒化,不可解释性:大模型作为黑盒模型,它们以参数的形式隐式地表示知识。由于大模型生成的结果中没有包含任何来源或参考,我们很难解释或验证其可信度。这严重影响了大模型的应用,尤其是在医疗诊断、金融咨询和法律判断等高风险的场景中。另一个挑战在于,大模型是为了一般用途而训练的,企业专有、保密或敏感的未公开数据并不在它们的知识范围内。
……
下面的配图直观的展示了现有大模型的局限性,以及图数据库如何增强大模型。

大模型无法实现(或替代)图数据库的深层检索
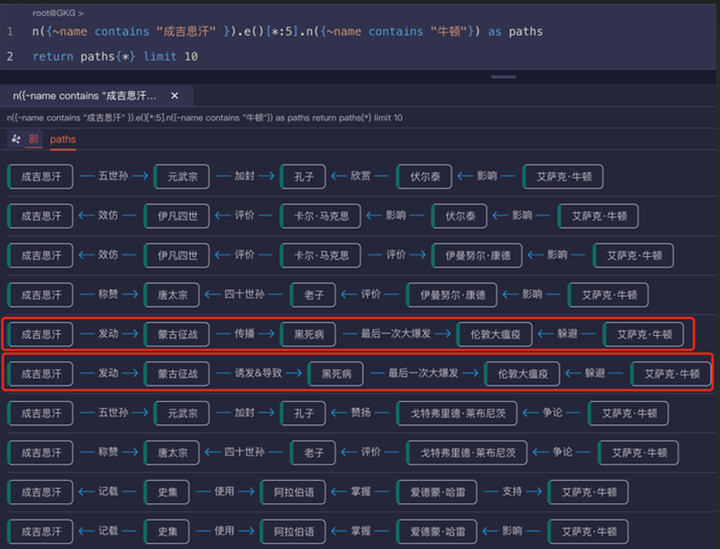
图数据库的海量结构化(深度、精准、白盒化)查询可以直接增强 LLM大模型能力
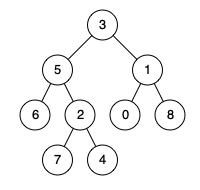
与Graph相协同后,这个关联成吉思汗和牛顿的4跳因果关系横跨东西方,跨越了400年的历史。通过图的深度穿透和因果关系搜索,生动地呈现在我们眼前了,见下图:
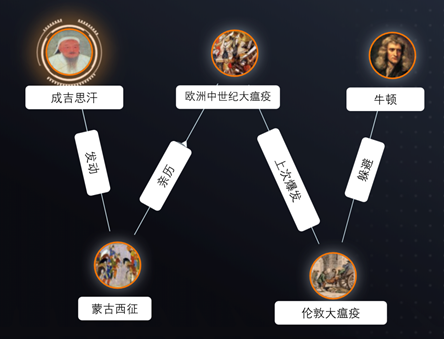
时至今日,很多研究人员已经认识到大模型和图技术之间固有的互补性。通过结合大模型的文本理解能力和图的结构化推理能力,能够整体增强AI系统的功能性、智能性和可解释性。 更多大模型与“图”的实践应用,本文不多赘述,感兴趣的盆友,可以阅读文章——嬴图 | LLM+Graph:大语言模型与图数据库技术的协同 - Ultipa Graph
文/Emma