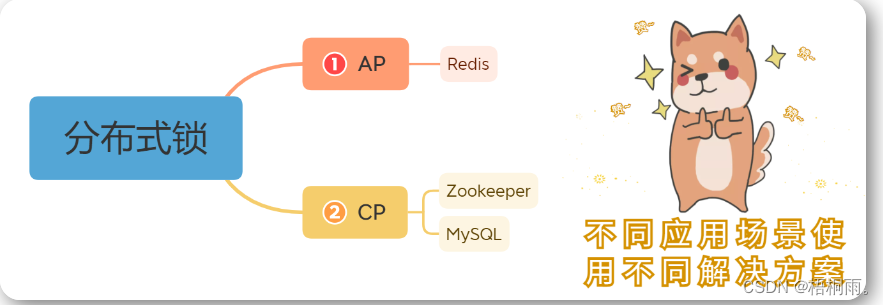
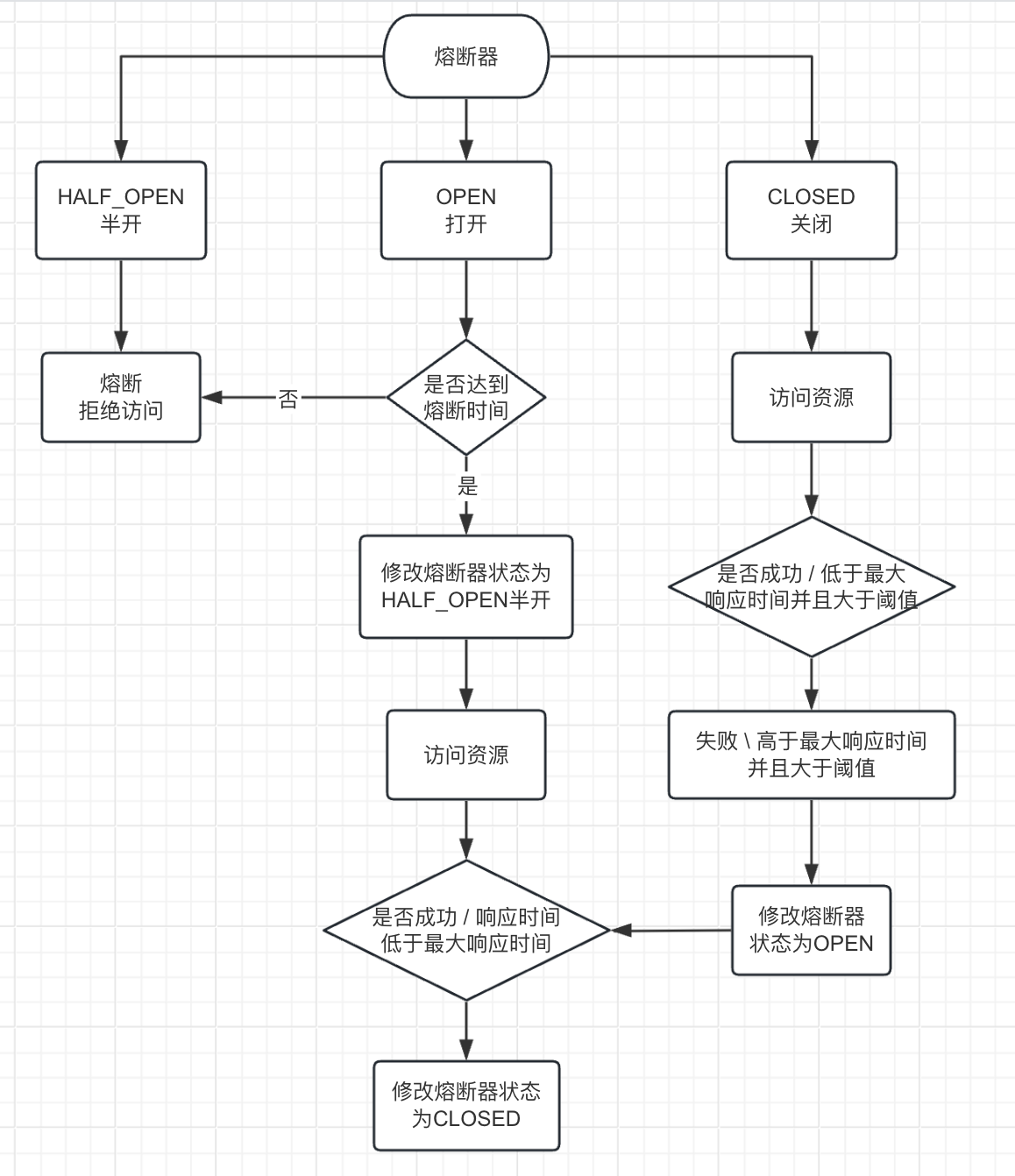
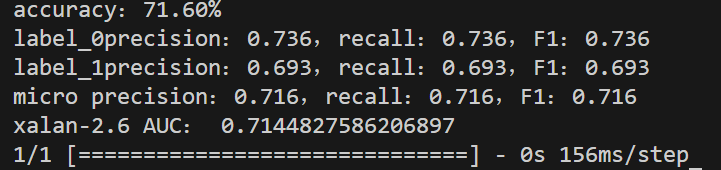
为什么需要分布式锁

在单机部署的系统中,使用线程锁来解决高并发的问题,多线程访问共享变量的问题达到数据一致性,如使用synchornized、ReentrantLock等。

但是在后端集群部署的系统中,程序在不同的JVM虚拟机中运行,且因为synchronized或ReentrantLock都只能保证同一个JVM进程中保证有效,所以这时就需要使用分布式锁了。
什么是分布式锁
分布式锁其实就是,控制分布式系统不同进程共同访问共享资源的一种锁的实现。如果不同的系统或同一个系统的不同主机之间共享了某个临界资源,往往需要互斥来防止彼此干扰,以保证一致性。

分布式锁的特点

分布式锁主要解决共享资源的原子性的问题问题
分布式锁特点的是互斥性 高性能 自解锁