据不完全统计,地球上有超过7000多种语言,而现在的大语言模型仅仅只涉及到了主流的100多种语言。相对全球7000多种语言来讲,这仅仅只是其中的一小部分。如何让全球的人获益,把大语言模型扩展到更多的语言上,一直是大语言模型研究的重点。Meta发布了涵盖 1406 种语言的预训练 wav2vec 2.0 模型、针对 1107 种语言的单一多语言自动语音识别模型、针对相同数量语言的语音合成模型以及针对 4017 种语言的语言识别模型。如此庞大的语言模型,Meta也是开源了相关模型与代码。
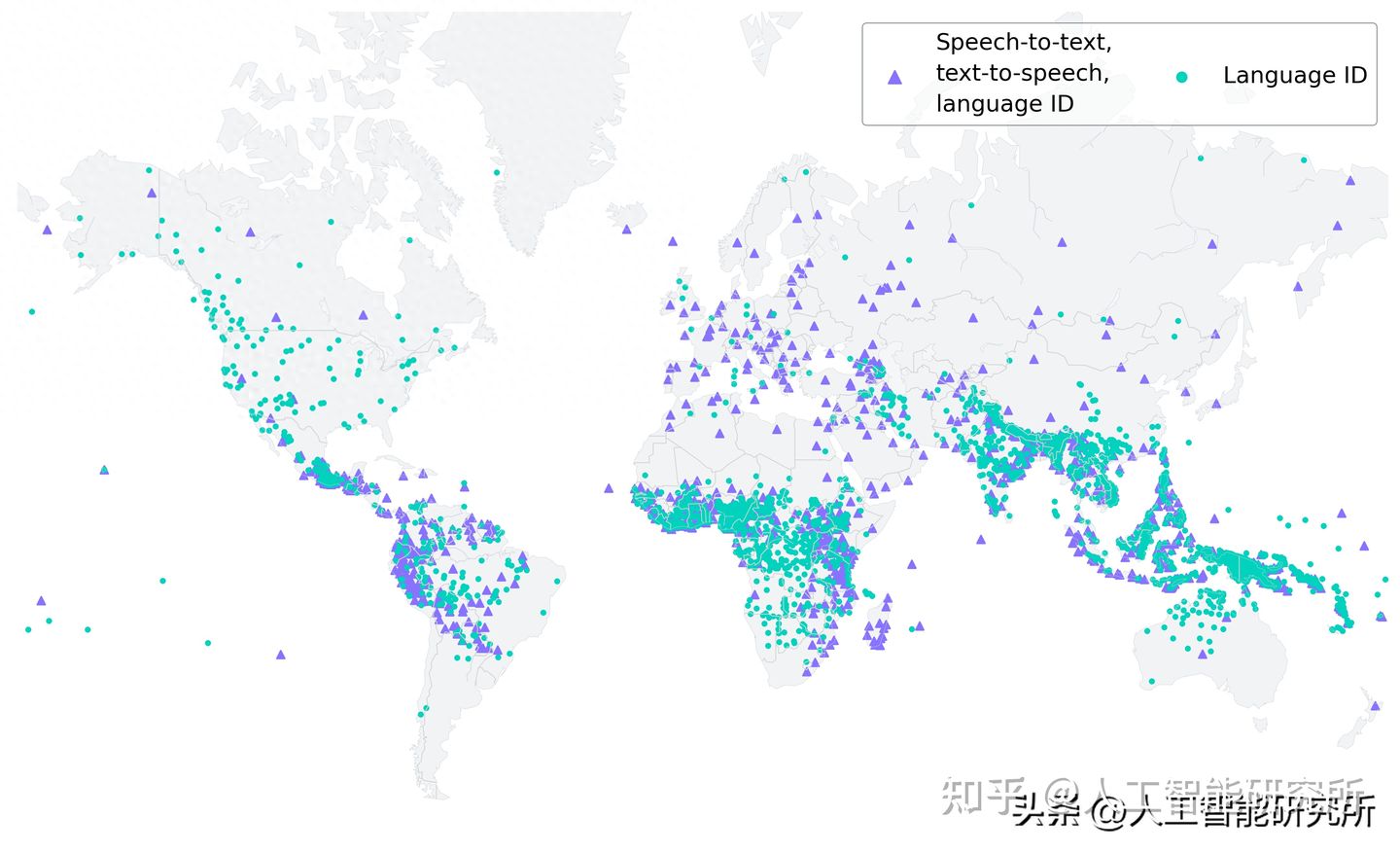
为了更好地了解在大规模多语言语音数据上训练的模型表现,Meta在现有的基准数据集(例如FLEURS)上对其进行了评估。模型使用 1B 参数 wav2vec 2.0 模型训练了 1100 多种语言的多语言语音识别模型。随着语言数量的增加,性能确实会下降,但幅度很小:从 61 种语言增加到 1107 种语言,字符错误率仅增加了约 0.4%,但语言覆盖率却增加了 18 倍以上。
在与OpenAI 的 Whisper 的同类模型比较中,此模型在大规模多语言语音数据上训练的模型实现了一半的单词错误率,但比其它大规模多语言语音覆盖的语言多了 11 倍。这表明,与当前最好的语音模型相比,此模型的表现特别出色。