1. 图上的公平性问题
图在现实世界中无处不在,例如知识图谱,社交网络和生物网络。近年来,图神经网络( graph neural networks,GNNs ) 在图结构数据建模方面表现出了强大的能力。一般地,GNNs采用消息传递机制,通过迭代地聚合邻居节点的表示来更新节点的表示。得到的表示同时保留了节点属性和局部图结构信息,便于各种下游任务,如节点分类和链接预测。尽管GNNs表现优异,但最近的研究表明,GNNs倾向于从训练数据中继承偏见,这可能导致对敏感属性的偏见预测,例如年龄、性别和种族。此外,GNNs的消息传递机制和图结构会放大偏见。例如,在社交网络中,同一种族的节点更有可能相互连接。GNNs的消息传递会使链接节点的表示相似,导致节点表示与种族高度相关,从而产生有偏预测。有偏预测引起了伦理和社会角度的关注,这严重限制了GNNs在高风险决策系统中的应用,如求职者排名和犯罪预测。因此,近年来许多工作致力于解决图上的公平性问题。
2. 相关工作介绍
2.1 Say No to the Discrimination: Learning Fair Graph Neural Networks with Limited Sensitive Attribute Information
论文来源:2021年 ACM International Conference on Web Search and Data Mining(CCF-B)
论文代码:https://github.com/EnyanDai/FairGNN
Motivation
- 现有公平性的研究主要针对的是独立同分布的数据,由于没有同时考虑节点属性和图结构的偏差,因此无法直接应用于图数据。
- 现有工作很少考虑敏感属性中稀疏标注的实际场景。
研究在敏感属性信息有限的情况下学习公平GNNs的问题
Contribution
- 研究了有限敏感信息下学习公平GNNs的一个新问题;
- 提出FairGNN,通过预测用户的敏感属性来解决对抗性去偏和公平性约束中敏感属性的不足问题;
- 理论分析表明,即使估计敏感属性,公平性也能达到最优值;
- 在不同数据集上的大量实验证明了FairGNN在保持GNN高准确性的同时消除了歧视的有效性。
Method
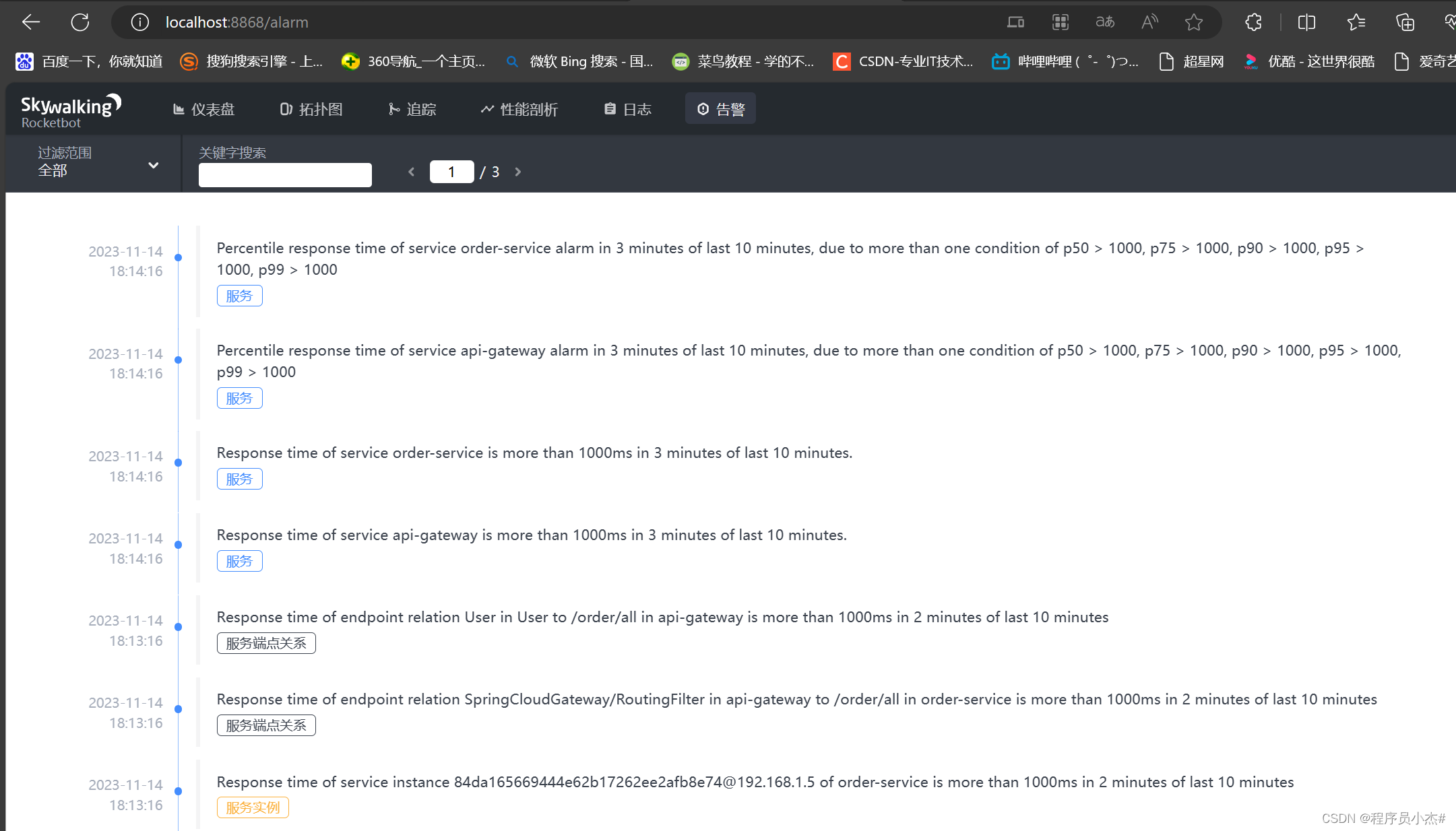
FairGNN整体框架图
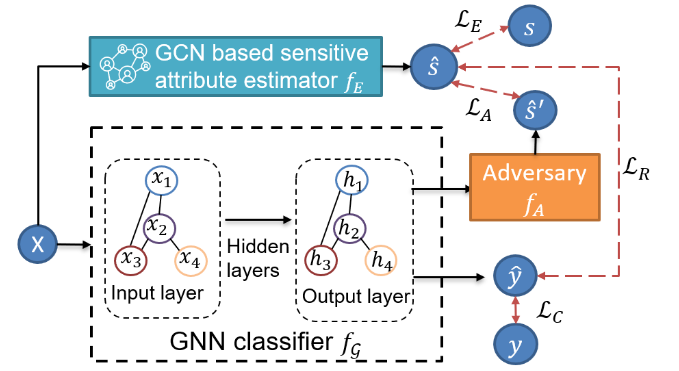
整体框架由四部分组成:一个GNN分类器 f G f_{\mathcal G} fG,一个基于GCN的敏感属性估计器 f E f_{E} fE 以及一个对手 f A f_A fA 。对手 f A f_A fA 旨在从 f G f_{\mathcal G} fG学习到的节点表示中预测已知或估计的敏感属性。 f G f_{\mathcal G} fG 旨在学习可以欺骗对手 f A f_A fA 做出错误预测的公平节点表示。 f E f_{E} fE 旨在为敏感属性未知的节点预测其敏感属性。
-
GNN分类器 f G f_{\mathcal G} fG:利用 G \mathcal G G作为输入进行节点分类
min θ G L C = − 1 ∣ V L ∣ ∑ v ∈ V L [ y v log y ^ v + ( 1 − y v ) log ( 1 − y ^ v ) ] \min\limits_{\theta_\mathcal{G}}\mathcal{L}_C=-\dfrac{1}{|\mathcal{V}_L|}\sum_{v\in\mathcal{V}_L}[y_v\log\hat{y}_v+(1-y_v)\log{(1-\hat{y}_v)}] θGminLC=−∣VL∣1v∈VL∑[yvlogy^v+(1−yv)log(1−y^v)] -
基于GCN的敏感属性评估器 f E f_{E} fE:为敏感属性未知的节点预测其敏感属性
min θ E L E = − 1 ∣ V S ∣ ∑ v ∈ V S [ s v log s ^ v + ( 1 − s v ) log ( 1 − s ^ v ) ] \min\limits_{\theta_E}\mathcal{L}_E=-\dfrac{1}{|\mathcal{V}_S|}\sum_{v\in\mathcal{V}_S}[s_v\log\hat{s}_v+(1-s_v)\log{(1-\hat{s}_v)}] θEminLE=−∣VS∣1v∈VS∑[svlogs^v+(1−sv)log(1−s^v)] -
对手 f A f_A fA旨在通过从节点表示 f G f_{\mathcal G} fG 中预测已知或估计的敏感属性 f E f_E fE。给定节点 v v v的表示 h v h_v hv 作为 f A ( h v ) f_A(h_v) fA(hv),对手 f A f_A fA 试图预测其敏感属性 s ^ v \widehat{s}_{v} s v ;而 f G f_{\mathcal G} fG 旨在学习节点表示 h v h_v hv,使对手 f A f_A fA 无法区分节点 v v v 属于哪个敏属性感组。
min θ G max θ A L A = E h ∼ p ( h ∣ s ^ = 1 ) [ log ( f A ( h ) ) ] + E h ∼ p ( h ∣ s ^ = 0 ) [ log ( 1 − f A ( h ) ) ] \min\limits_{\theta_\mathcal{G}}\max\limits_{\theta_A}\mathcal{L}_A=\mathbb{E}_{\mathrm{h}\sim p(\mathrm{h}|\hat{\mathrm{s}}=1)}[\log(f_A(\mathrm{h}))]\text{+}\mathbb{E}_{\mathrm{h}\sim p(\mathrm{h}|\hat{\mathrm{s}}=0)}[\log(1-f_A(\mathrm{h}))] θGminθAmaxLA=Eh∼p(h∣s^=1)[log(fA(h))]+Eh∼p(h∣s^=0)[log(1−fA(h))] -
协方差约束:进一步提升对抗去偏过程的稳定性。最小化用户敏感属性之间的绝对协方差和用户特征到公平线性分类器决策边界的符号距离。
L R = ∣ Cov ( s ^ , y ^ ) ∣ = ∣ E [ ( s ^ − E ( s ^ ) ) ( y ^ − E ( y ^ ) ) ] ∣ \mathcal L_R=|\operatorname{Cov}(\hat s,\hat y)|=|\mathbb E[(\hat s-\mathbb E(\hat s))(\hat y-\mathbb E(\hat y))]| LR=∣Cov(s^,y^)∣=∣E[(s^−E(s^))(y^−E(y^))]∣
2.2 Towards a Unified Framework for Fair and Stable Graph Representation Learning
论文来源:2021年 International Conference on Uncertainty in Artificial Intelligence(CCF-B)
论文代码:https://github.com/HongduanTian/NIFTY
Motivation
最近的研究将GNN中的公平性和稳定性视为独立的问题,并提出了独立的解决方案。因此,现有工作都是独立研究公平性或稳定性的问题,并没有探究它们之间更深层次的联系。
探究一个统一的框架来共同优化GNNs的公平性和稳定性
Contribution
- 首次确定反事实公平与稳定性之间的关键联系。
- 利用上述联系提出了NIFTY,它可以与任何现有的GNN模型一起使用,以学习公平且稳定的节点表示。
- 利用利普希茨常数进行分层权归一化,提出了一种改进神经信息传递的新方法。
- 我们介绍并实验了三个新的图形数据集,包括刑事司法中的关键决策以及金融借贷等领域。
Method
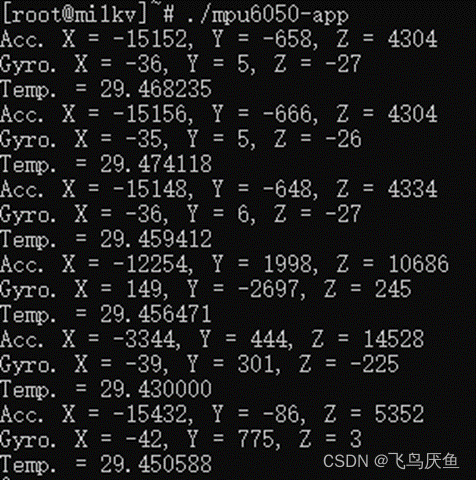
NIFTY整体框架图
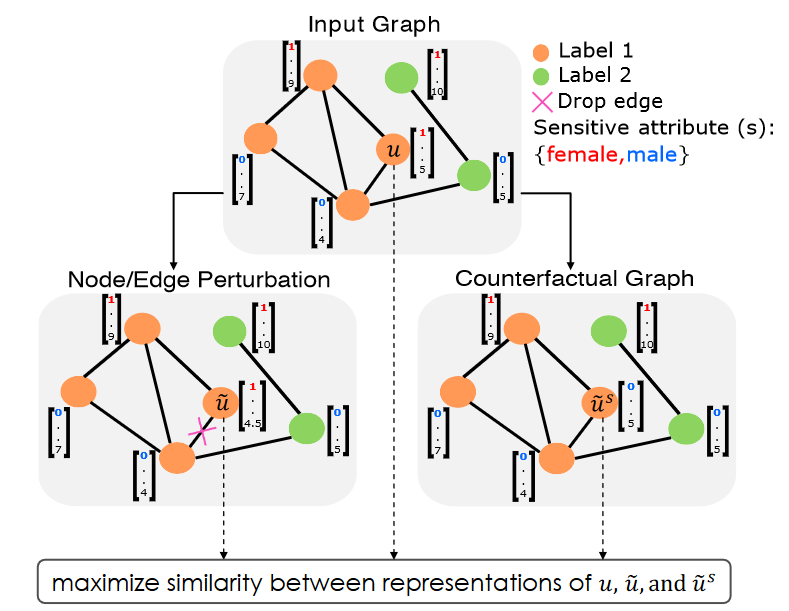
NIFTY通过最大化来自不同增广视图的表示之间的相似性来学习公平且稳定的节点表示。
反事实公平性的定义:对于任意给定的节点
u
u
u,如果满足以下条件,则编码器函数
E
N
C
ENC
ENC 满足反事实公平性:
E
N
C
(
u
)
=
E
N
C
(
u
~
s
)
\mathrm{ENC}(u)\,=\,\mathrm{ENC}(\tilde{u}^{s})
ENC(u)=ENC(u~s)
其中,
u
~
s
\tilde{u}^{s}
u~s 是增广图中的一个节点,它是通过修改/翻转节点
u
u
u 的敏感属性
s
s
s 的值而生成的,同时保持其他所有内容不变。
稳定性的定义:根据利普希茨连续性的概念,如果满足以下条件,编码器函数
E
N
C
ENC
ENC 被认为是稳定的:
∣
∣
E
N
C
(
u
~
)
−
E
N
C
(
u
)
∣
∣
p
≤
L
∣
∣
b
~
u
−
b
u
∣
∣
p
||\mathrm{ENC}(\tilde{u})-\mathrm{ENC}(u)||_p\leq L||\tilde{\mathbf{b}}_u-\mathbf{b}_u||_p
∣∣ENC(u~)−ENC(u)∣∣p≤L∣∣b~u−bu∣∣p
其中,
u
~
\tilde{u}
u~ 是通过扰动
u
u
u 的属性值和/或关联边生成的增广图中的一个节点,
b
~
u
\tilde{\mathbf{b}}_u
b~u 和
b
u
b_u
bu 分别捕获节点
u
~
\tilde{u}
u~ 和
u
u
u 的属性和关联边信息,
L
L
L 为Lipschitz常数。
在分别构造用于公平性与稳定性的增广视图后,为了学习公平且稳定的节点表示,基于Siamese网络,设计如下Loss函数来最大化来自不同增广视图的表示之间的相似性:
L
s
=
E
u
[
1
2
(
D
(
t
(
z
u
)
,
s
g
(
z
~
u
)
)
+
D
(
t
(
z
~
u
)
,
s
g
(
z
u
)
)
)
]
\mathcal{L}_{s}=\mathbb{E}_{u}\bigl[\frac{1}{2}\bigl(D(t(\mathbf{z}_{u}),\mathbf{sg}(\tilde{\mathbf{z}}_{u})\bigr)+D(t(\tilde{\mathbf{z}}_{u}),\mathbf{sg}(\mathbf{z}_{u})\bigr)\bigr)\bigr]
Ls=Eu[21(D(t(zu),sg(z~u))+D(t(z~u),sg(zu)))]
为了进一步确保下游任务的性能,在增加二元交叉熵损失函数 L c \mathcal{L}_c Lc,最终整体loss如下:
min θ E N C , θ t , θ f E u [ ( 1 − λ ) L c ] + λ L s \min _{\theta_{\mathrm{ENC}}, \theta_t, \theta_f} \mathbb{E}_u\left[(1-\lambda) \mathcal{L}_c\right]+\lambda \mathcal{L}_s θENC,θt,θfminEu[(1−λ)Lc]+λLs
其中,正则化系数 λ λ λ 控制下游节点分类损失 L c \mathcal{L}_c Lc 和 公平稳定目标损失 L s \mathcal{L}_{s} Ls 之间的权衡。
为了进一步在GNN结构中强制公平与稳定,对每层消息传递网络执行层级归一化:
W
~
a
k
=
W
a
k
/
σ
(
W
a
k
)
\tilde{\mathbf{W}}_a^k=\mathbf{W}_a^k / \sigma\left(\mathbf{W}_a^k\right)
W~ak=Wak/σ(Wak)
2.3 Learning Fair Node Representations with Graph Counterfactual Fairness
论文来源:2022年 ACM International Conference on Web Search and Data Mining(CCF-B)
论文代码:https://github.com/jma712/GEAR
Motivation
现有的反事实公平仅仅简单考虑翻转敏感属性的值来生成反事实样本,忽视了两个可能导致偏见的事实:
- 每个节点的敏感属性可能因果地影响当前节点的预测;
- 当前节点的敏感属性可能因果地影响其它特征或者图结构
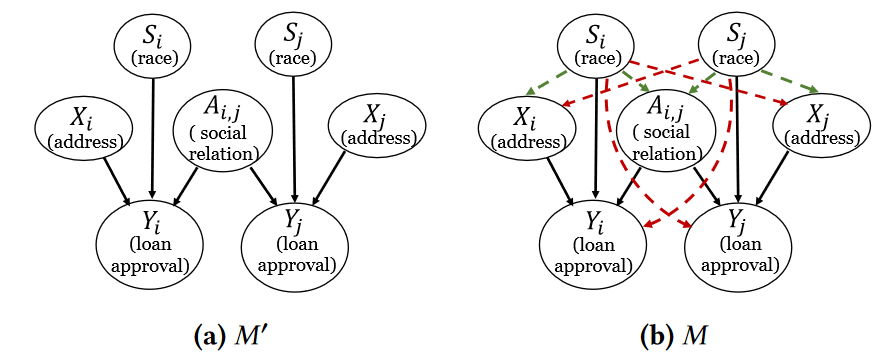
研究考虑上述两种偏见(即每个节点及其邻居的敏感属性的潜在偏见以及敏感属性对非敏感属性的因果效应所导致的偏见)的图反事实公平表示学习
Contribution
- 提出了一个新的公平概念——图反事实公平,它考虑了从敏感属性到图模型预测的不同因果路径所带来的潜在偏差。
- 提出了GEAR来学习图反事实公平性的节点表示。具体来说,对于每个节点,我们最小化了从原始数据中学习到的表示与具有不同敏感属性值的增广反事实之间的差异。
- 在合成图和真实世界图上进行了广泛的实验。结果表明,所提出的方法在多个公平性概念上优于现有的基线,并且在下游任务中取得了可比的预测性能。
Method
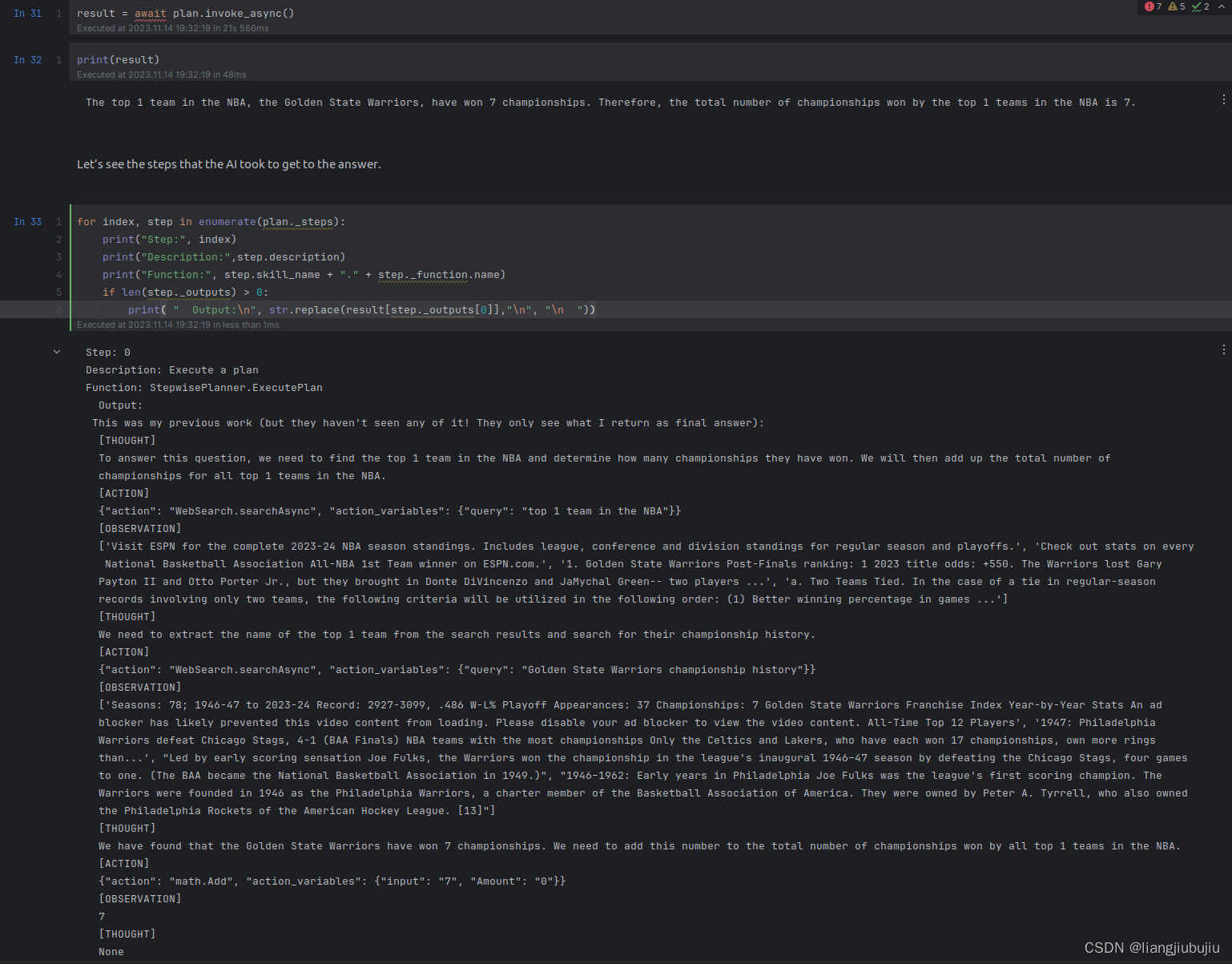
GEAR整体框架图
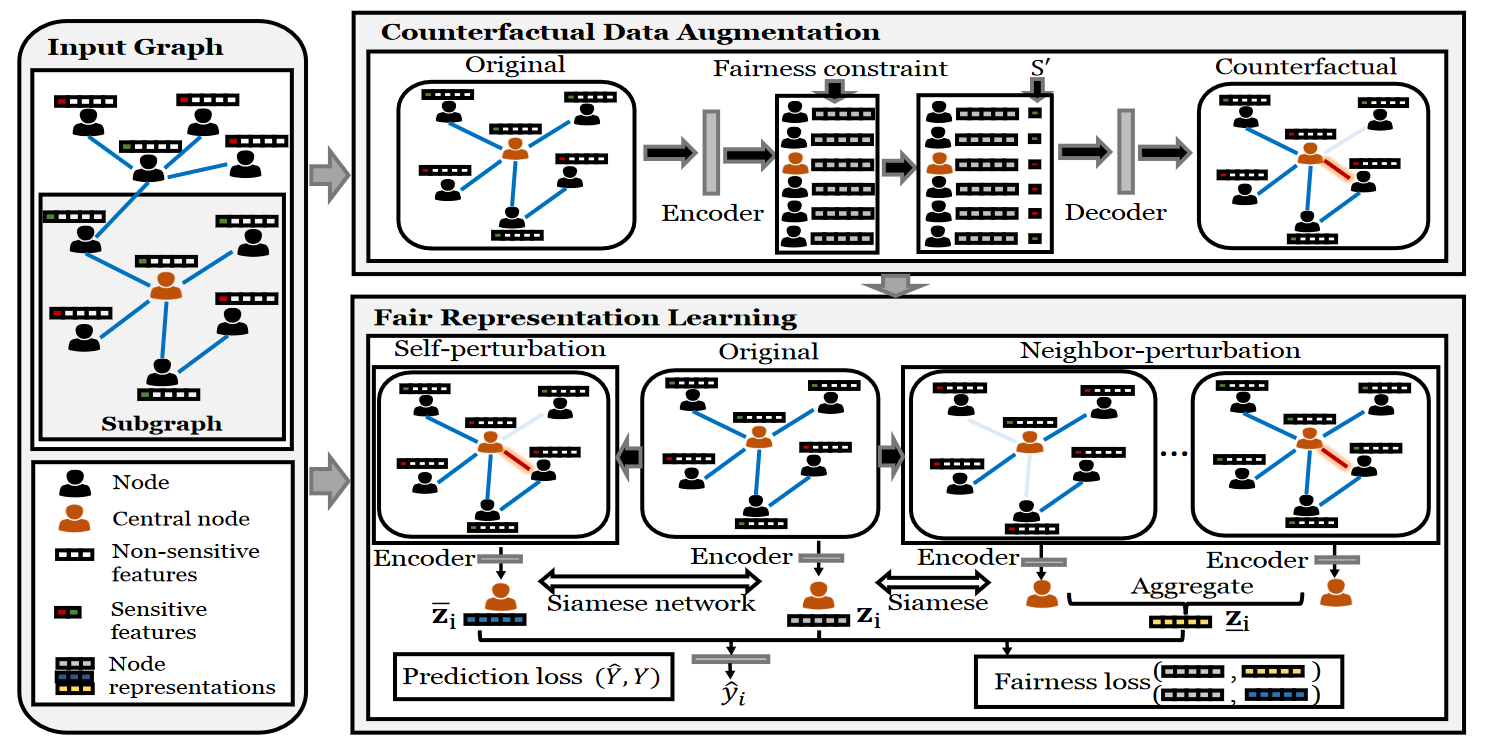
GEAR旨在学习图反事实公平性的节点表示。如图所示,GEAR主要包括三个关键部分:(1)子图生成;(2)反事实数据增广;(3)公平表示学习。在子图生成中,GEAR为每个节点提取一个上下文子图,该子图包含节点本身(中心节点)及其最近邻居的局部图结构。在反事实数据增广中,GEAR生成这些子图中节点的敏感属性被扰动的反事实。基于增广的反事实,公平表示学习组件利用Siamese网络来最小化从原始数据中学习到的表示与同一节点的反事实之间的距离。
子图生成
G
(
i
)
=
{
V
(
i
)
,
E
(
i
)
,
X
(
i
)
}
=
{
A
(
i
)
,
X
(
i
)
}
V
(
i
)
=
TOP
(
R
i
,
:
,
k
)
A
(
i
)
=
A
V
(
i
)
,
V
(
i
)
,
X
(
i
)
=
X
V
(
i
)
,
:
\begin{gathered} \mathcal{G}^{(i)}=\left\{\mathcal{V}^{(i)}, \mathcal{E}^{(i)}, \mathrm{X}^{(i)}\right\}=\left\{\mathrm{A}^{(i)}, \mathrm{X}^{(i)}\right\} \\ \mathcal{V}^{(i)}=\operatorname{TOP}\left(\mathrm{R}_{i,:}, k\right) \\ \mathrm{A}^{(i)}=\mathrm{A}_{\mathcal{V}^{(i)}, \mathcal{V}^{(i)}}, \mathrm{X}^{(i)}=\mathrm{X}_{\mathcal{V}^{(i)},:} \end{gathered}
G(i)={V(i),E(i),X(i)}={A(i),X(i)}V(i)=TOP(Ri,:,k)A(i)=AV(i),V(i),X(i)=XV(i),:
反事实数据增广
L
a
=
L
r
+
β
L
d
\mathcal{L}_a=\mathcal{L}_r+\beta \mathcal{L}_d
La=Lr+βLd
L r = E q ( H ∣ X , A ) [ − log ( p ( X , A ∣ H , S ) ) ] + K L [ q ( H ∣ X , A ) ∥ p ( H ) ] \mathcal{L}_r=\mathbb{E}_{q(H \mid \mathbf{X}, \mathrm{A})}[-\log (p(\mathbf{X}, \mathrm{A} \mid H, \mathrm{~S}))]+\mathrm{KL}[q(H \mid \mathbf{X}, \mathrm{A}) \| p(H)] Lr=Eq(H∣X,A)[−log(p(X,A∣H, S))]+KL[q(H∣X,A)∥p(H)]
L d = ∑ b ∈ [ B ] E [ log ( D ( H , b ) ) ] \mathcal{L}_d=\sum_{b \in[B]} \mathbb{E}[\log (D(\mathbf{H}, b))] Ld=b∈[B]∑E[log(D(H,b))]
公平表示学习
L
=
L
p
+
λ
L
f
+
μ
∥
θ
∥
2
\mathcal{L}=\mathcal{L}_p+\lambda \mathcal{L}_f+\mu\|\theta\|^2
L=Lp+λLf+μ∥θ∥2
L p = 1 n ∑ i ∈ [ n ] l ( f ( z i ) , y i ) \mathcal{L}_p=\frac{1}{n} \sum_{i \in[n]} l\left(f\left(\mathrm{z}_i\right), y_i\right) Lp=n1i∈[n]∑l(f(zi),yi)
L f = 1 ∣ V ∣ ∑ i ∈ V ( ( 1 − λ s ) d ( z i , z ‾ i ) + λ s d ( z i , z ‾ i ) ) \mathcal{L}_f=\frac{1}{|\mathcal{V}|} \sum_{i \in \mathcal{V}}\left(\left(1-\lambda_s\right) d\left(\mathrm{z}_i, \overline{\mathrm{z}}_i\right)+\lambda_s d\left(\mathrm{z}_i, \underline{\mathbf{z}}_i\right)\right) Lf=∣V∣1i∈V∑((1−λs)d(zi,zi)+λsd(zi,zi))
z i = ( ϕ ( X ( i ) , A ( i ) ) ) i z ‾ i = AGG ( { ( ϕ ( X S i ← 1 − s i ( i ) , A S i ← 1 − s i ( i ) ) ) i } ) z ‾ i = AGG ( { ( ϕ ( X S ¬ i ( i ) ← S M P ( S ¬ i ( i ) ) ( i ) , A S ¬ i ( i ) ← S M P ( S ¬ i ( i ) ) ( i ) ) ) i } ) \begin{gathered} \mathbf{z}_i=\left(\phi\left(\mathbf{X}^{(i)}, \mathbf{A}^{(i)}\right)\right)_i \\ \overline{\mathbf{z}}_i=\operatorname{AGG}\left(\left\{\left(\phi\left(\mathbf{X}_{S_i \leftarrow 1-s_i}^{(i)}, \mathbf{A}_{S_i \leftarrow 1-s_i}^{(i)}\right)\right)_i\right\}\right) \\ \underline{\mathbf{z}}_i=\operatorname{AGG}\left(\left\{\left(\phi\left(\mathbf{X}_{S_{\neg i}^{(i)} \leftarrow \mathrm{SMP}\left(\mathrm{S}_{\neg i}^{(i)}\right)}^{(i)}, \mathbf{A}_{S_{\neg i}^{(i)} \leftarrow \mathrm{SMP}\left(\mathrm{S}_{\neg i}^{(i)}\right)}^{(i)}\right)\right)_i\right\}\right) \end{gathered} zi=(ϕ(X(i),A(i)))izi=AGG({(ϕ(XSi←1−si(i),ASi←1−si(i)))i})zi=AGG({(ϕ(XS¬i(i)←SMP(S¬i(i))(i),AS¬i(i)←SMP(S¬i(i))(i)))i})
2.4 Learning Fair Graph Representations via Automated Data Augmentations
论文来源:2023年 International Conference on Learning Representations
论文代码:https://github.com/divelab/DIG
Motivation
现有方法总是依赖于对公平图数据属性的某些假设,以设计固定的数据增广策略。然而,公平图数据的确切属性在不同情况下可能会有很大差异,所以这些方法并不能在所有数据集上始终如一地取得良好的性能。因此,启发式设计的增广可能并不总是在不同的应用场景中生成公平的图形数据。
研究自动化的图数据增广来学习公平的表示。
Contribution
- 提出了一种用于公平图表示学习的自动图增广框架Graphair。
- 为了提升模型的公平性,采用对手模型从增广图数据中预测敏感属性。为了确保下游性能,利用对比学习来保留原始图中的有用信息,以最大限度地提高原始图和增广图之间的一致性。
- 实验结果表明,在多个节点分类数据集上,Graphair在公平-准确性权衡性能方面始终优于许多基线。
Method
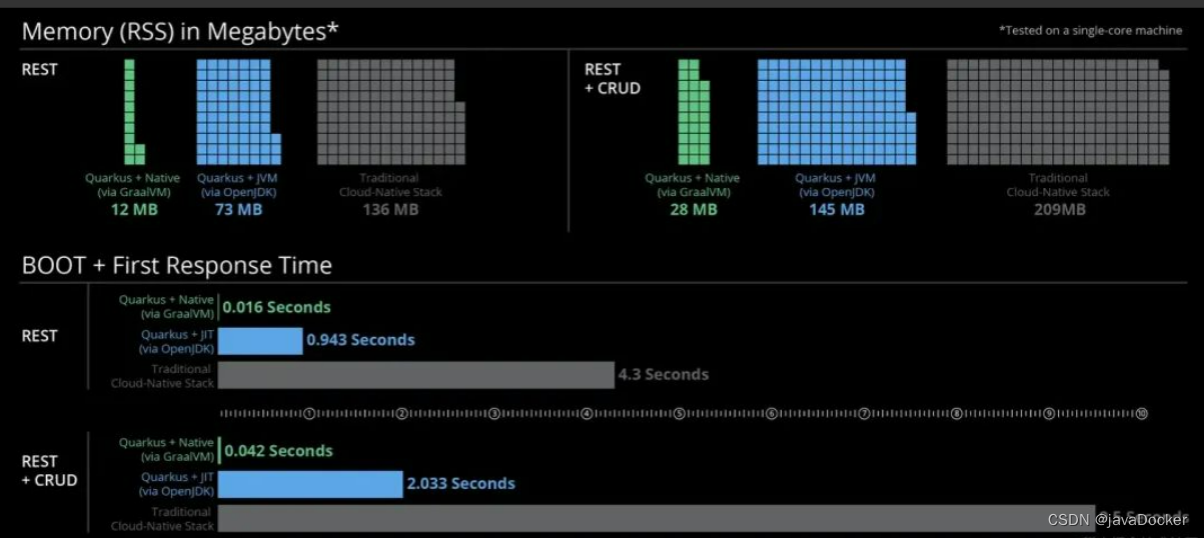
Graphair整体框架图
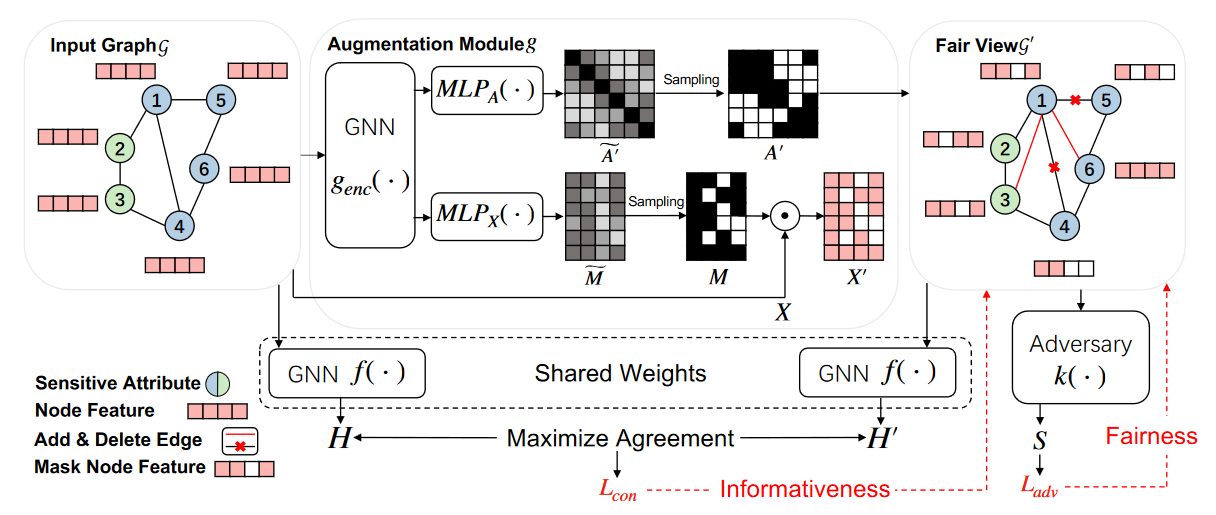
包括三个可学习的模型,分别是GNN编码器
f
f
f, 数据增广模型
g
g
g 以及对手模型
k
k
k,整体优化目标如下:
min
f
,
g
max
k
L
=
min
f
,
g
max
k
α
L
adv
+
β
L
con
+
γ
L
reconst
\min\limits_{f,\mathcal{g}}\max\limits_{k}L=\min\limits_{f,\mathcal{g}}\max\limits_{k}\alpha L_{\text{adv}}+\beta L_{\text{con}}+\gamma L_{\text{reconst}}
f,gminkmaxL=f,gminkmaxαLadv+βLcon+γLreconst
数据增广模型 g g g:
-
对边的扰动:
Z A = ML P A ( Z ) , A ′ ~ = σ ( Z A Z A T ) , A i j ′ ∼ Bernoulli ( A ′ ~ i j ) for i , j = 1 , ⋯ , n Z_A=\operatorname{ML}P_A(Z),\quad\widetilde{A'}=\sigma\left(Z_AZ_A^T\right),\quad A'_{ij}\sim\operatorname{Bernoulli}\left(\widetilde{A'}_{ij}\right)\operatorname{for}i,j=1,\cdots,n ZA=MLPA(Z),A′ =σ(ZAZAT),Aij′∼Bernoulli(A′ ij)fori,j=1,⋯,n -
对节点特征屏蔽:
Z X = ML P X ( Z ) , M ~ = σ ( Z X ) , M i j ∼ Bernoulli ( M ~ i j ) for i , j = 1 , ⋯ , n , X ′ = M ⊙ X Z_X=\operatorname{ML}P_X(Z),\widetilde M=\sigma(Z_X),M_{ij}\sim\operatorname{Bernoulli}\left(\widetilde M_{ij}\right)\operatorname{for}i,j=1,\cdots,n,X'=M\odot X ZX=MLPX(Z),M =σ(ZX),Mij∼Bernoulli(M ij)fori,j=1,⋯,n,X′=M⊙X
对手模型
k
k
k:
k
k
k 被优化以最大化敏感属性的预测精度,而
g
g
g 被优化以减轻
A
′
A'
A′ 和
X
′
X'
X′ 中的偏差,使得对手模型
k
k
k 难以从
A
′
A'
A′ 和
X
′
X'
X′ 中识别出敏感属性信息。
min
g
max
k
L
adv
=
min
g
max
k
1
n
∑
i
=
1
n
[
S
i
log
S
^
i
+
(
1
−
S
i
)
log
(
1
−
S
^
i
)
]
\min\limits_{g}\max\limits_{k}L_{\text{adv}}=\min\limits_{g}\max\limits_{k}\dfrac{1}{n}\sum\limits_{i=1}^{n}\left[S_i\log\hat{S}_i+(1-S_i)\log\left(1-\hat{S}_i\right)\right]
gminkmaxLadv=gminkmaxn1i=1∑n[SilogS^i+(1−Si)log(1−S^i)]
仅使用对抗性训练可能会导致增强模型
g
g
g 崩溃为平凡的解决方案。例如,
g
g
g 可以学习总是生成一个完全图,并将所有节点特征设置为零,其中不包含偏差,因为所有节点都是等效的。这种增广图根本没有信息量,因为它们失去了输入图中的所有信息。为了在生成的图中保留输入图中信息量最大的部分,在训练过程中还使用了对比学习目标,对比目标的节点对损失函数如下:
l
(
h
i
,
h
i
′
)
=
−
log
exp
(
sin
(
h
i
,
h
i
′
)
/
τ
)
∑
j
=
1
n
exp
(
sin
(
h
i
,
h
j
′
)
/
τ
)
+
∑
j
=
1
n
1
[
j
≠
i
]
exp
(
sin
(
h
i
,
h
j
)
/
τ
)
l(h_i,h'_i)=-\log\dfrac{\exp\left(\sin(h_i,h'_i)/\tau\right)}{\sum_{j=1}^n\exp\left(\sin(h_i,h'_j)/\tau\right)+\sum_{j=1}^n1_{[j\neq i]}\exp\left(\sin(h_i,h_j)/\tau\right)}
l(hi,hi′)=−log∑j=1nexp(sin(hi,hj′)/τ)+∑j=1n1[j=i]exp(sin(hi,hj)/τ)exp(sin(hi,hi′)/τ)
L con = 1 2 n ∑ i = 1 n [ l ( h i , h i ′ ) + l ( h i ′ , h i ) ] L_{\text{con}}=\dfrac{1}{2n}\sum_{i=1}^n\left[l(h_i,h_i')+l(h_i',h_i)\right] Lcon=2n1i=1∑n[l(hi,hi′)+l(hi′,hi)]
为了防止增强模型
g
g
g 生成的图与输入图偏差过大,在整体训练目标中添加了一个基于重构的正则化项,基于重建的正则化项损失函数如下:
L
r
e
c
o
n
s
t
=
L
B
C
E
(
A
,
A
′
~
)
+
λ
L
M
S
E
(
X
,
X
′
)
=
−
∑
i
=
1
n
∑
j
=
1
n
[
A
i
j
log
(
A
′
~
i
j
)
+
(
1
−
A
i
j
)
log
(
1
−
A
′
~
i
j
)
]
+
∥
X
−
X
′
∥
F
2
,
L_{\mathrm{reconst}}= L_{\mathrm{BCE}}(A,\widetilde{A'})+\lambda L_{\mathrm{MSE}}(X,X') \\ =-\sum_{i=1}^n\sum_{j=1}^n\Big[A_{ij}\log\Big(\widetilde{A'}_{ij}\Big)+(1-A_{ij})\log\Big(1-\widetilde{A'}_{ij}\Big)\Big]+\|X-X'\|_F^2,
Lreconst=LBCE(A,A′
)+λLMSE(X,X′)=−i=1∑nj=1∑n[Aijlog(A′
ij)+(1−Aij)log(1−A′
ij)]+∥X−X′∥F2,
3. 总结
- 大部分工作主要关注一种敏感属性,每种敏感属性也只考虑两种模态,并没有考虑数值敏感属性的情况。
- 同时考虑不同敏感属性需要进一步研究。调查交叉公平性并不意味着提高每个属性的模型公平性,而是同时适应几个敏感属性,如年龄和性别,我们需要确保模型对像年轻女性这样的子群体也是公平的。
- 现有方法主要针对的是同质图上的公平性问题,对于像异质图与二部图等图结构是否也存在公平性问题需要进一步探索。
- 大多数公平性方法都要求修改GNNs的模型参数,对于大图模型来说并不高效。两类方法可以参考:(1)以数据集为中心的方法:在数据集层面做一定的预处理,以消除大规模数据集自身存在的偏见,从而避免大图模型学习到其中的偏见。(2)参数高效的微调:对于训练好的大图模型,利用prompt tuning、adapter tuning等参数高效的方法去提高其公平性。