7.5 一种自动反射消息类型的Protobuf网络传输方案
本节假定读者了解Google Protocol Buffers是什么,这不是一篇Protobuf入门教程。本节的示例代码位于examples/protobuf/codec。
本节要解决的问题是:通信双方在编译时就共享proto文件(用于定义数据结构和消息格式,以便进行数据的序列化和反序列化)的情况下,接收方在收到Protobuf二进制数据流之后,如何自动创建具体类型的Protobuf Message对象,并用收到的数据填充该Message对象(即反序列化)。“自动”的意思是:当程序中新增一个Protobuf Message类型时,这部分代码不需要修改,不需要自己去注册消息类型。其实,Google Protobuf本身具有很强的反射(reflection)功能,可以根据type name创建具体类型的Message对象,我们直接利用即可(Protobuf C++库的反射能力不止于此,它可以在运行时读入并解析任意proto文件,然后分析其对应的二进制数据)。
7.5.1 网络编程中使用Protobuf的两个先决条件
Google Protocol Buffers(简称Protobuf)是一款非常优秀的库,它定义了一种紧凑(compact,相对XML和JSON而言)的可扩展二进制消息格式,特别适合网络数据传输。
它为多种语言提供binding,大大方便了分布式程序的开发,让系统不再局限于用某一种语言来编写。
在网络编程中使用Protobuf需要解决以下两个问题:
1.长度,Protobuf打包的数据没有自带长度信息或终结符,需要由应用程序自己在发生和接收的时候做正确的切分。
2.类型,Protobuf打包的数据没有自带类型信息,需要由发送方把类型信息传给接收方,接收方创建具体的Protobuf Message对象,再做反序列化。
Protobuf这么设计的原因见下文。这里第一个问题很好解决,通常的做法是在每个消息前面加个固定长度的length header,例如上文中实现的“LengthHeaderCodec”。第二个问题也很好解决,Protobuf对此有内建的支持。但是奇怪的是,从网上简单搜索的情况看,作者发现了很多“山寨”的做法。
“山寨”做法
以下均为在Protobuf data之前加上header,header中包含消息长度和类型信息。类型信息的“山寨”做法主要有两种:
1.在header中放int typeId,接收方用switch-case来选择对应的消息类型和处理函数。
2.在header中放string typeName,接收方用look-up table来选择对应的消息类型和处理函数。
这两种做法都有问题。
第一种做法要求保持typeId的唯一性,它和Protobuf message type一一对应。如果Protobuf message的使用范围不广,比如接收方和发送方都是自己维护的程序,那么typeId的唯一性不难保证,用版本管理工具即可。如果Protobuf message的使用范围很大,比如全公司都在用,而且不同部门开发的分布式程序可能相互通信,那么就需要一个公司内部的全局机构来分配typeId,每次增加新message type都要去注册一下,比较麻烦。
第二种做法稍好一点。typename的唯一性比较好办,因为可以加上package name(也就是用message的fully qualified type name),各个部门事先分好namespace,不会冲突与重复。但是每次新增消息类型的时候都要去手工修改look-up table的初始化代码,也比较麻烦。
其实,不需要自己重新发明轮子,Protobuf本身已经自带了解决方案。
7.5.2 根据type name反射自动创建Message对象
Google Protobuf本身具有很强的反射(reflection)功能,可以根据type name创建具体类型的Message对象。但是奇怪的是,其官方教程里没有明确提及这个用法,作者估计还有很多人不知道这个用法,所以觉得值得谈一谈。
以下是作者绘制的Protobuf class diagram:
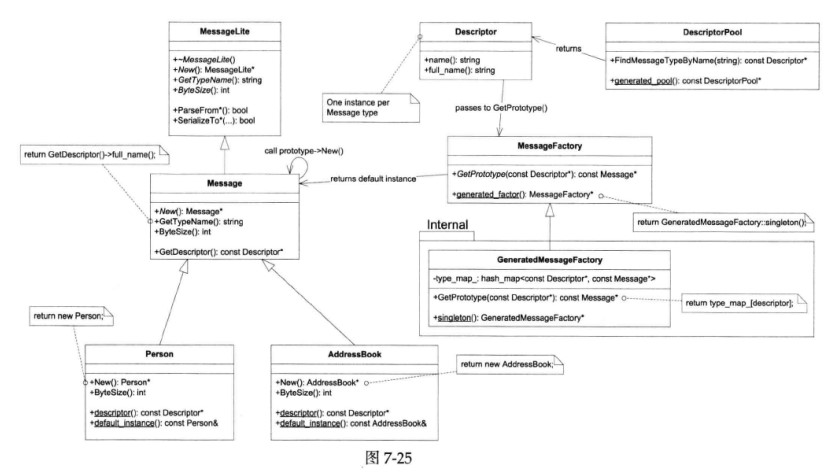
放大上图:
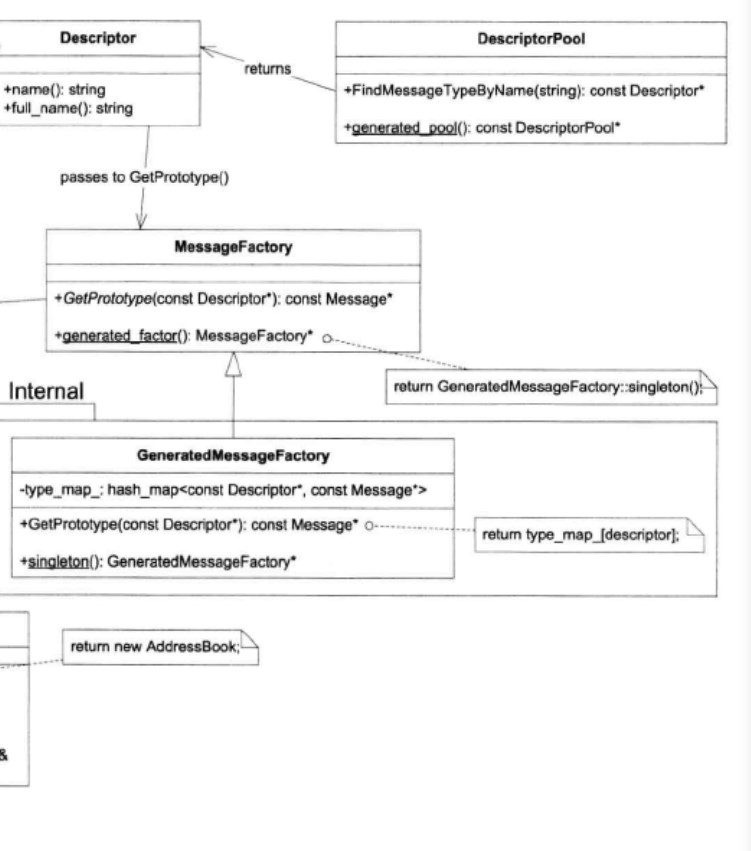
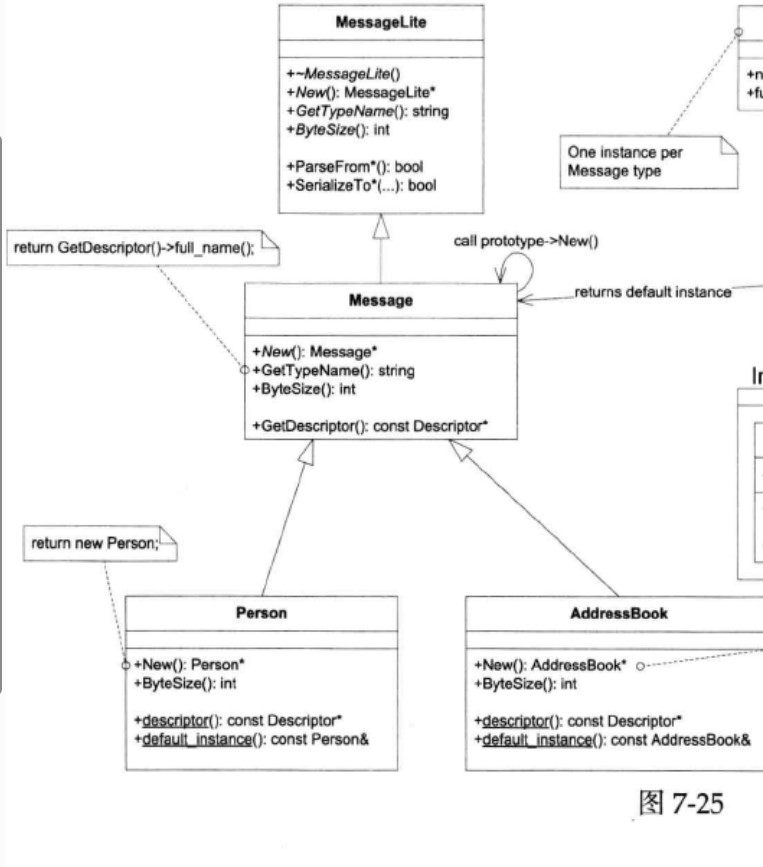
作者估计大家通常关心和使用的是这个类图的左半部分:MessageLite、Message、Generated Message Types(person、AddressBook)等,而较少注意到右半部分:Descriptor、DescriptorPool、MessageFactory。
上图中,起关键作用的是Descriptor class,每个具体Message type对应一个Descriptor对象。尽管我们没有直接调用它的函数,但是Descriptor在“根据type name创建具体类型的Message对象”中扮演了重要的角色,起了桥梁作用。上图中的→箭头描述了根据type name创建具体Message对象的过程,后文会详细介绍。
原理简述
Protobuf Message class采用了Prototype pattern(一种设计模式,避免了显式使用构造函数来创建对象,这种设计模式用于创建对象的新实例,核心思想是通过复制现有对象来创建新对象,而不是从头开始构造,这有助于减少重复的初始化工作,提高性能,并使代码更具灵活性),Message class定义了New()虚函数,用以返回本对象的一份新实体,类型与本对象的真实类型相同。也就是说,拿到Message *指针,不用知道它的具体类型,就能创建和其类型一样的具体Message type的对象。
每个具体Message type都有一个default instance,可以通过ConcreteMessage:;default_instance()获得,也可以通过MessageFactory::GetPrototype(const Descriptor *)来获得。所以,现在问题转变为:1.如何拿到MessageFactory;2.如何拿到Descriptor *。
当然,ConcreteMessage::descriptor()返回了我们想要的Descriptor *,但是,在不知道ConcreteMessage的时候,如何调用它的静态成员函数呢?这似乎是个鸡与蛋的问题。
我们的英雄是DescriptorPool,它可以根据type name查到Descriptor *,只要找到合适的DescriptorPool,再调用DescriptorPool::FindMessageTypeByName(const string &type_name)即可。看到图7-25是不是眼前一亮?
在最终解决问题之前,先简答测试一下,看看作者上面说得对不对。
验证思路
本文用于举例的proto文件:
package muduo;
message Query {
required int64 id = 1;
reqiered string questioner = 2;
repeated string question = 3;
}
message Answer {
requered int64 id = 1;
required string questioner = 2;
required string answerer = 3;
repeated string solution = 4;
}
message Empty {
optional int32 id = 1;
}
其中Query.questioner和Answer.answerer是9.4提到的“分布式系统中的进程标识”。
以下代码(recipes/protobuf/descriptor_test.cc)验证ConcreteMessage::default_instance()、ConcreteMessage::descriptor()、MessageFactory::GetPrototype()、DescriptorPool::FindMessageTypeByName()之间的不变式(invariant),注意其中的assert:
typedef muduo::Query T;
std::string type_name = T::descriptor()->full_name();
cout << type_name << endl;
const Descriptor *descriptor = DescriptorPool::generated_pool()->FindMessageTypeByName(type_name);
assert(descriptor == T::descriptor());
cout << "FindMessageTypeByName() = " << descriptor << endl;
cout << "T::descriptor() = " << T::descriptor() << endl;
cout << endl;
const Message *prototype = MessageFactory::generated_factory()->GetPrototype(descriptor);
assert(prototype == &T::default_instance());
cout << "GetPrototype() = " << prototype << endl;
cout << "T::default_instance() = " << &T::default_instance() << endl;
cout << endl;
T *new_obj = dynamic_cast<T *>(prototype->New());
assert(new_obj != NULL);
assert(new_obj != prototype);
// typeid操作符用于获取一个表达式的类型信息
// 它通常与RTTI(Run-Time Type Information,运行时类型信息)一起使用,在运行时确定对象的实际类型
assert(typeid(*new_obj) == typeid(T::default_instance()));
cout << "prototype->New() = " << new_obj << endl;
cout << endl;
delete new_obj;
程序运行结果如下:

根据type name自动创建Message的关键代码
好了,万事俱备,开始行动:
1.用DescriptorPool::generated_pool()找到一个DescriptorPool对象,它包含了程序编译的时候所链接的全部Protobuf Message types。
2.根据type name用DescriptorPool::FindMessageTypeByName()查找Descriptor。
3.再用MessageFactory::generated_factory()找到MessageFactory对象,它能创建程序编译的时候所链接的全部Protobuf Message types。
4.然后,用MessageFactory::GetPrototype()找到具体Message type的default instance。
5.最后,用prototype->New()创建对象。
示例代码如下:
Message *createMessage(const std::string &typeName)
{
Message *message = NULL;
const Descriptor *descriptor = DescriptorPool::generated_pool()->FindMessageTypeByName(typeName);
if (descriptor)
{
const Message *prototype = MessageFactory::generated_factory()->GetPrototype(descriptor);
if (prototype)
{
message = prototype->New();
}
}
return message;
}
调用方式:
Message *newQuery = createMessage("muduo.Query");
assert(newQuery != NULL);
assert(typeid(*newQuery) == typeid(muduo::Query::default_instance()));
cout << "createMessage(\"muduo.Query\") = " << newQuery << endl;
确实能从消息名称创建消息对象,古之人不余欺也:-)。
注意,createMessage()返回的是动态创建的对象的指针,调用方有责任释放它,不然就会使内存泄漏。在muduo里,作者用shared_ptr<Message>来自动管理Message对象的生命期。
拿到Message *之后怎么办呢?怎么调用这个具体消息类型的处理函数?这就需要消息分发器(dispatcher)出马了,且听下回分解。
Google的文档说,我们用到的那几个MessageFactory和DescriptorPool都是线程安全的,Message::New()也是线程安全的。并且它们都是const member function。关键问题解决了,那么剩下的工作就是设计一种包含长度和消息类型的Protobuf传输格式。
7.5.3 Protobuf传输格式
作者设计了一个简单的格式,包含Protobuf data和其对应的长度与类型信息,消息的末尾还有一个check sum。格式如下图所示,图中方块的宽度是32-bit:
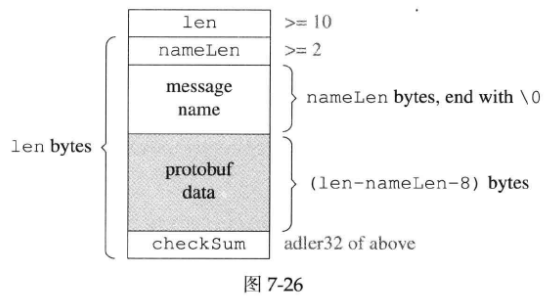
上图显示checkSum是用Adler32算法计算的校验和。
用C struct伪代码描述:
// __attribute__((__packed__))是一个编译器特定的属性
// 它告诉编译器不要在字段之间插入额外的填充字节,以确保结构体在内存中按照字段的定义顺序连续存储
// 这对于与其他系统交互或进行网络传输很重要,它确保了数据的布局是一致的,不会受到编译器的优化或对齐方式的影响
struct ProtobufTransportFormat __attribute__ ((__packed__))
{
int32_t len;
int32_t nameLen;
char typeName[nameLen];
char protobufData[len - nameLen - 8];
int32_t checkSum; // adler32 of numLen, typeName and protobufData
};
注意,这个格式不要求32-bit对齐,我们的decoder会自动处理非对齐的消息。
例子
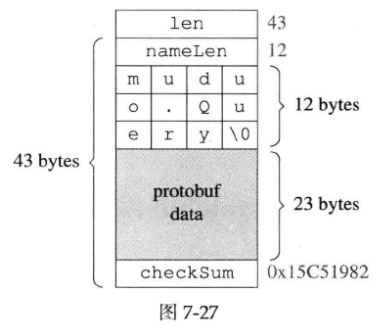
用这个格式打包一个muduo.Query对象的结果如下图所示:
设计决策
以下是作者在设计这个传输格式时的考虑:
1.signed int。消息中的长度只使用了signed 32-bit int,而没有使用unsigned int,这是为了跨语言移植性,因为Java语言没有unsigned类型。另外,Protobuf一般用于打包小于1MB的数据,unsigned int也没用。
2.check sum。虽然TCP是可靠传输协议,虽然Ethernet有CRC-32校验,但是网络传输必须要考虑数据损坏的情况,对于关键的网络应用,check sum是必不可少的。见A.1.13 “TCP的可靠性有多高”。对于Protobuf这种紧凑的二进制格式而言,肉眼看不出数据有没有问题,需要用check sum。
3.adler32算法。作者没有选常见的CRC-32,而是选用了adler32,因为它的计算量小、速度比较快,强度和CRC-32差不多。另外,zlib和java.unit.zip都直接支持这个算法,不用我们自己实现。
4.type name以’\0’结束。这是为了方便troubleshooting,比如通过tcpdump抓下来的包可以用肉眼很容易看出type name,而不用根据nameLen去一个个数字节。同时,为了方便接收方处理,加入了nameLen,节省了strlen(),这是以空间换时间的做法。
5.没有版本号。Protobuf Message的一个突出优点是用optional fields来避免协议的版本号(凡是在Protobuf Message里放版本号的人都没有理解Protobuf的设计,甚至可能没有仔细阅读Protobuf的文档),让通信双方的程序能各自升级,便于系统演化。如果作者设计的这个传输格式又把版本号加进去,那就画蛇添足了。
Protobuf可谓是网络协议格式的典范,值得作者单独花一节篇幅讲述其思想,见9.6.1 “可扩展的消息格式”。
7.6 在muduo中实现Protobuf编解码器与消息分发器
本节是前一节的自然延续,介绍如何将前文介绍的打包方案与muduo::net::Buffer结合,实现Protobuf codec和dispatcher。
在介绍codec和dispatcher之前,先讲讲前文的一个未决问题。
为什么Protobuf的默认序列化格式没有包含消息的长度与类型
Protobuf是经过深思熟虑的消息打包方案,它的默认序列化格式没有包含消息的长度与类型,自然有其道理。哪些情况下不需要在Protobuf序列化得到的字节流中包含消息的长度和(或)类型?作者能想到的答案有:
1.如果把消息写入文件,一个文件存一个消息,那么序列化结果中不需要包含长度和类型,因为从文件名和文件长度中可以得知消息的类型与长度。
2.如果把消息写入文件,一个文件存多个消息,那么序列化结果中不需要包含类型,因为文件名就代表了消息的类型。
3.如果把消息存入数据库(或者NoSQL),以VARBINARY字段保存,那么序列化结果中不需要包含长度和类型,因为从字段名和字段长度中可以得知消息的类型与长度。
4.如果把消息以UDP方式发送给对方,而且对方一个UDP port只接收一种消息类型,那么序列化结果中不需要包含长度和类型,因为从port和UDP packet长度中可以得知消息的类型与长度。
5.如果把消息以TCP短连接方式发给对方,而且对方一个TCP port只接收一种消息类型,那么序列化结果中不需要包含长度和类型,因为从port和TCP字节流长度中可以得知消息的类型与长度。
6.如果把消息以TCP长连接方式发给对方,但是对方一个TCP port只接收一种消息类型,那么序列化结果中不需要包含类型,因为port代表了消息的类型。
7.如果采用RPC方式通信,那么只需要告诉对方method name,对方自然能推断出Request和Response的消息类型,这些可以由protoc(Google Protocol Buffers的官方编译器,用于将Protocol Buffers(.proto 文件) 转换为特定编程语言的源代码文件,以便在应用程序中使用Protocol Buffers数据格式)生成的RPC stubs(用于创建客户端和服务器之间通信的代码,以便进行远程方法调用)自动搞定。
对于以上最后一点,比方说sudoku.proto的定义是:
// proto文件中,service关键字用于定义一个服务
// 服务通常包含一组可以远程调用的方法
service SudokuService {
// 该服务包含名为Solve的RPC方法,参数类型是SudokuRequest,返回类型是SudokuResponse
rpc Solve (SudokuRequest) returns (SudokuResponse);
}
那么RPC method SudokuService.Solve对应的请求和响应分别是SudokuRequest和SudokuResponse。在发送RPC请求的时候,不需要包含SudokuRequest的类型,只需要发送method name SudokuService.Solve,对方自然知道应该按照SudokuRequest来解析(parse)请求。
对于上述这些情况,如果Protobuf无条件地把长度和类型放到序列化的字节串中,只会浪费网络带宽和存储。可见Protobuf默认不发送长度和类型是正确的决定。Protobuf为消息格式的设计树立了典范,哪些该自己搞定,哪些留给外部系统去解决,这些都考虑得很清楚。
只有在使用TCP长连接,且在一个连接上传递不止一种消息的情况下(比方同时发Heartbeat和Request/Response),才需要作者前文提到的那种打包方案(为什么要在一个连接上同时发Heartbeat和业务消息?见9.3)。这时候我们需要一个分发器dispatcher,把不同类型的消息分给各个消息处理函数,这正是本节的主题之一。
以下均只考虑TCP长连接这一应用场景。先谈谈编解码器。
7.6.1 什么是编解码器(codec)
编解码器(codec)是encoder和decoder的缩写,这是一个软硬件领域都在使用的术语,这里作者借指“把网络数据和业务消息之间相互转换”的代码。
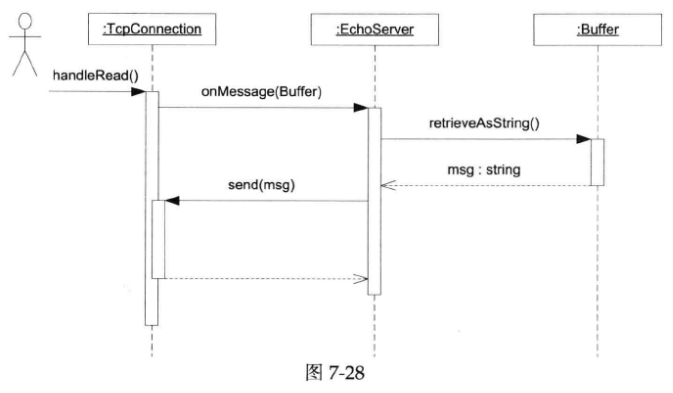
在最简单的网络编程中,没有消息(message),只有字节流数据,这时候是用不到codec的。比如我们前面讲过的echo server,它只需要把收到的数据原封不动地发送回去,而不必关心消息的边界(也没有“消息”的概念),收多少就发多少,这种情况下它干脆直接使用muduo::net::Buffer,取到数据再交给TcpConnection发送回去,如下图所示:
non-trival的网络服务程序通常会以消息为单位来通信,每条消息有明确的长度与界限。程序每次收到一个完整的消息的时候才开始处理,发送的时候也是把一个完整的消息交给网络库。比如前面讲过的asio chat服务,它的一条聊天记录就是一条消息。为此我们设计了一个简单的消息格式,即在聊天记录前面加上4字节的length header,LengthHeaderCodec代码及解说见上文。
codec的基本功能之一是做TCP分包:确定每条消息的长度,为消息划分界限。在non-blocking网络编程中,codec几乎是必不可少的。如果只收到了半条消息,那么不会触发消息事件回调,数据会停留在Buffer里(数据已经读到Buffer中了),等待收到一个完整的消息再通知处理函数。既然这个任务太常见,我们干脆做一个utility class,避免服务端和客户端程序都要自己处理分包,这就有了LengthHeaderCodec。这个codec的使用有点奇怪,不需要继承,它也没有基类,只要把这个类对象当成普通data member来用,把TcpConnection的数据“喂”给它,然后向它注册onXXXMessage()回调,代码见asio chat示例。muduo里的codec都是这样的风格:通过boost::function黏合到一起。
codec是一层间接性,它位于TcpConnection和ChatServer之间,拦截处理收到的数据(Buffer),在收到完整的消息之后,解出消息对象(std::string),再调用ChatServer对应的处理函数。注意ChatServer::onStringMessage()的参数是std::string,不再是muduo::net::Buffer,也就是说LengthHeaderCodec把Buffer解码成了string。另外,在发送消息的时候,ChatServer通过LengthHeaderCodec::send()来发送string,LengthHeaderCodec负责把它编码成Buffer。这正是“编解码器”名字的由来。消息流程如下图所示:
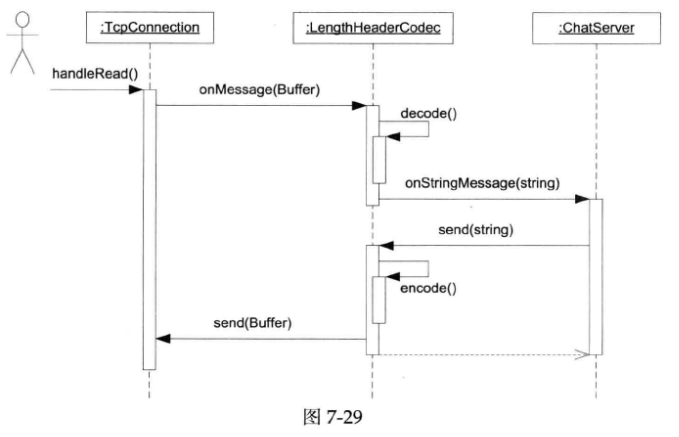
Protobuf codec与此非常类似,只不过消息类型从std::string变成了protobuf::Message。对于只接收处理Query消息的QueryServer来说,用ProtobufCodec非常方便,收到protobuf::Message之后向下转型成Query来用就行(见下图)。
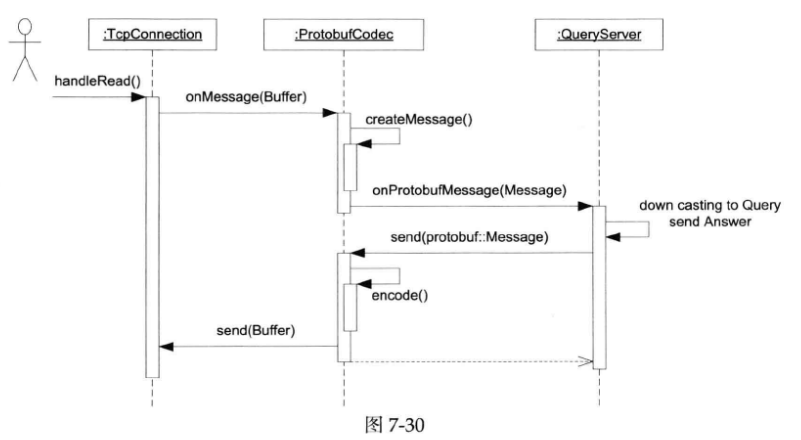
如果要接受处理不止一种消息,ProtobufCodec恐怕还不能单独完成工作,请继续阅读下文。
7.6.2 实现ProtobufCodec
Protobuf的打包方案已经在前一节中讲过。编码算法很直截了当,按照前文定义的消息格式一路打包下来,最后更新一下首部长度即可。代码位于examples/protobuf/codec/codec.cc中的ProtoBufCodec::fillEmptyBuffer()。
编码算法有几个要点:
1.protobuf::Message是new出来的对象,它的生命期如何管理?muduo采用shared_ptr<Message>来自动管理对象生命期,与整体风格保持一致。
2.出错如何处理?比方说长度超出范围、check sum不准确、message type name不能识别、message parse出错等等。ProtoBufCodec定义了ErrorCallback,用户代码可以注册这个回调。如果不注册,默认的处理是断开连接,让客户重连重试。codec的单元测试里模拟了各种出错情况。
3.如何处理一次收到半条消息、一条消息、一条半消息、两条消息等等情况?这是每个non-blocking网络程序中的codec都要面对的问题,在上文的示例代码中我们已经解决了这个问题。
ProtobufCodec在实际使用中有明显的不足:它只负责把Buffer转换为具体类型的Protobuf Message,每个应用程序拿到Message对象之后还要再根据其具体类型做一次分发。我们可以考虑做一个简单通用的分发器dispatcher,以简化客户代码。
此外,目前PrtobufCodec的实现非常初级,它没有充分利用ZeroCopyInputStream和ZeroCopyOutputStream,而是把收到的数据作为byte array交给Protobuf Message去解析,这给性能优化留下了空间。Protobuf Message不要求数据连续(像vector那样),只要求数据分段连续(像deque那样),这给buffer管理带来了性能上的好处(避免重新分配内存,减少内存碎片),当然也使代码变得更为复杂。muduo::net::Buffer非常简单,它内部是vector<char>,作者目前不想让Protobuf影响muduo本身的设计,毕竟muduo是个通用的网络库,不是为Protobuf RPC而特制的。
7.6.3 消息分发器(dispatcher)有什么用
前面提到,在使用TCP长连接,且在一个连接上传递不止一种Protobuf消息的情况下,客户代码需要对收到的消息按类型做分发。比方说,收到Login消息就交给Query::onLogon()去处理,收到Query消息就交给QueryServer::onQuery()去处理。这个消息分派机制可以做得稍微有点通用性,让所有muduo+Protobuf程序受益,而且不增加复杂性。
换句话说,又是一层间接性,ProtobufCodec拦截了TcpConnection的数据,把它转换为Message,ProtobufDispatcher拦截了ProtobufCodec的callback,按消息具体类型把它分派给多个callbacks,如下图所示:
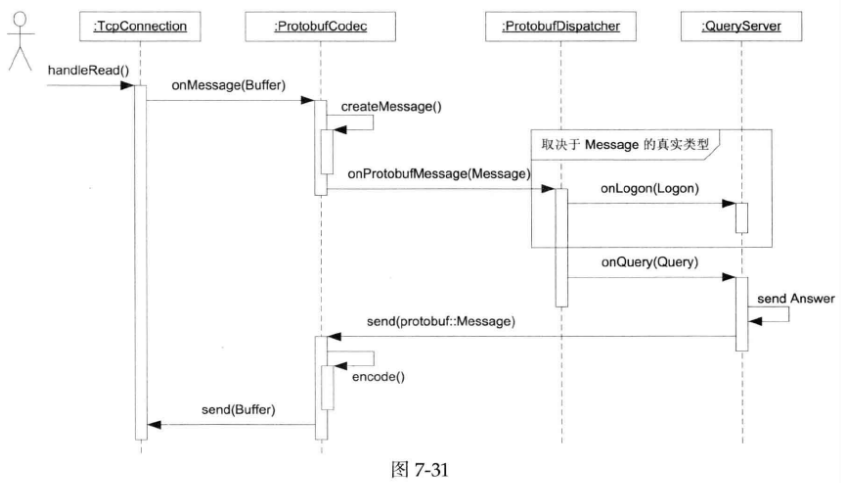
7.6.4 ProtobufCodec与ProtobufDispatcher的综合运用
作者写了两个示例代码,client和server,把ProtobufCodec和ProtobufDispatcher串联起来使用。server响应Query消息,发送回Answer消息,如果收到未知消息类型,则断开连接。client可以选择发送Query或Empty消息,由命令行控制。这样可以测试unknown message callback。
为节省篇幅,这里就不列出代码了,见examples/protobuf/codec/{client,server}.cc。
在构造函数中,通过注册回调函数把四方(TcpConnection、codec、dispatcher、QueryServer)结合起来。
7.6.5 ProtobufDispatcher的两种实现
要完成消息分发,其实就是对消息做type-switch,这似乎是一个bad smell(在代码中进行大量类型判断是不太好的编程实践),但是Protobuf Message的Discriptor没有留下定制点(比如暴露一个boost::any成员,该成员可在运行时存储不同类型的对象,并且可以在需要的时候安全地检索和转换这些值),我们只好硬来了(用不太优雅的方式实现)。
先定义ProtobufMessageCallback回调:
// ProtobufMessageCallback是一个可调用对象,返回void,参数是Message *
typedef boost::function<void (Message *)> ProtobufMessageCallback;
注意,本节出现的不是muduo dispatcher的真实代码,仅为示意,突出重点,便于画图。
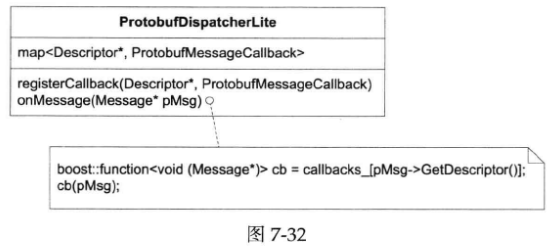
protobufDispatcherLite的结构非常简单(见下图),它有一个map<Descriptor *, ProtobufMessageCallback>成员,客户代码可以以Descriptor *为key注册回调(回想:每个具体消息类型都有一个全局的Descriptor对象,其地址是不变的,可以用来当key)。在收到Protobuf Message之后,在map中找到对应的ProtobufMessageCallback,然后调用之。如果找不到,就调用defaultCallback。
不过,它的设计也有小小的缺陷,那就是ProtobufMessageCallback限制了客户代码只能接受基类Message,客户代码需要自己做向下转型(down cast),如下图所示:
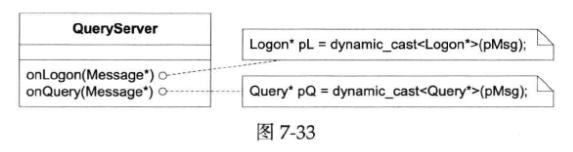
如果希望QueryServer这么设计:不想每个消息处理函数自己做down cast,而是交给dispatcher去处理,客户代码拿到的就已经是想要的具体类型。接口如下图所示:
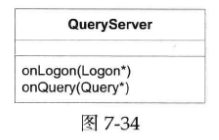
那么该如何实现ProtobufDispatcher呢?它如何与多个未知的消息类型合作?做down cast需要知道目标类型,难道我们要用一长串模板类型参数吗(指将ProtobufDispatcher作为模板类)?
有一个办法,把多态与模板结合,利用templated derived class来提供类型上的灵活性。设计如下图所示(图中画的是dynamic_cast,代码实际上自定义了down_cast转换操作,在Debug编译时会检查动态类型,而在NDEBUG编译时会退化为static_cast,没有RTTI开销):
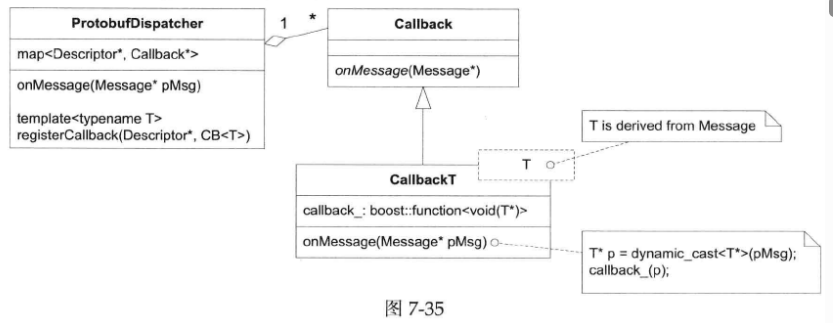
ProtobufDispatcher有一个模板成员函数,可以接受注册任意消息类型T的回调,然后它创建一个模板化的派生类CallbackT<T>,这样消息的类型信息就保存在了CallbackT<T>中,做down cast就简单了。
比方说,我们有两个具体消息类型Query和Answer(见下图)。
然后我们这样注册回调:
dispatcher_.registerMessageCallback<muduo::Query>(boost::bind(&QueryServer::onQuery,
this, _1, _2, _3));
dispatcher_.registerMessageCallback<muduo::Answer>(boost::bind(&QueryServer::onAnswer,
this, _1, _2, _3));
这样会具现化(instantiation)出两个CallbackT实体,如下图所示。
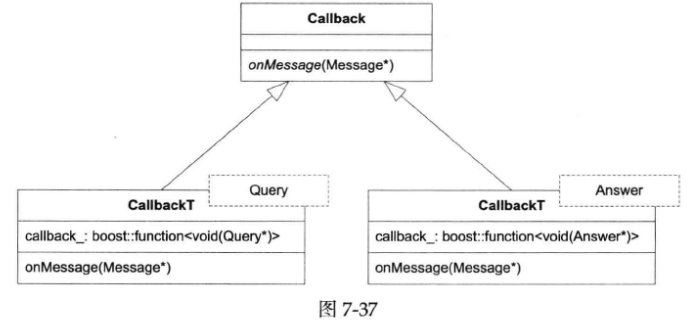
以上设计参考了shared_ptr的deleter,Scott Meyers(《Effective C++》系列作者)也谈到过(http://www.artima.com/cppsource/top_cpp_aha_moments.html)。
7.6.6 ProtobufCodec和ProtobufDispatcher有何意义
ProtobufCodec和ProtobufDispatcher把每个直接收发Protobuf Message的网络程序都会用到的功能提炼出来做成了公用的utility,这样以后新写Protobuf网络程序就不必为打包分包和消息分发劳神了。它俩以库的形式存在,是两个可以拿来就当data member的class。它们没有基类,也没有用到虚函数或者别的什么面向对象特征,不侵入muduo::net或者你的代码。如果不这么做,那将来每个Protobuf网络程序都要自己重新实现类似的功能,徒增负担。
9.7 “分布式程序的自动化回归测试”会介绍利用Protobuf的跨语言特性,采用Java为C++服务程序编写test harness(测试工具)。
这种编码方案的Java Netty示例代码见http://github.com/chenshuo/muduo-protorpc中的com.chenshuo.muduo.codec package。
7.7 限制服务器的最大并发连接数
本节以大家都熟悉的EchoServer为例,介绍如何限制TCP服务器的并发连接数。代码见examples/maxconnection/。
本节中的“并发连接数”是指一个服务端程序能同时支持的客户连接数,连接由客户端主动发起,服务端被动接受(accept(2))连接。(如果要限制应用程序主动发起的连接,则问题要简单地多,毕竟主动权和决定权都在程序本身)
7.7.1 为什么要限制并发连接数
一方面,我们不希望服务程序超载;另一方面,更因为file descriptor是稀缺资源,如果出现file descriptor耗尽,很棘手,跟“malloc()失败/new抛出std::bad_alloc”差不多同样棘手。
作者2010年10月在《分布式系统的工程化开发方法》演讲(http://blog.csdn.net/Solstice/article/details/5950190)中曾谈到libev的作者Marc Lehmann建议的一种应对“accept()时file descriptor耗尽”的办法(http://pod.tst.eu/http://cvs.schmorp.de/libev/ev.pod#The_special_problem_of_accept_ing_wh)。
在服务端网络编程中,我们通常用Reactor模式来处理并发连接。listening socket是一种特殊的IO对象,当有新连接到达时,此listening文件描述符变得可读(POLLIN),epoll_wait函数返回这一事件。然后我们用accept(2)系统调用获得新连接的socket文件描述符。代码主体逻辑如下(Python):
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serversocket.bind(('', 2007))
serversocket.listen(5)
serversocket.setblocking(0)
poll = select.poll() # epoll() should work the same
poll.register(serversocket.fileno(), select.POLLIN)
connections = {}
while True:
events = poll.poll(10000) # 2 # 10 seconds
for fileno, event in events:
if fileno == serversocket.fileno():
(clientsocket, address) = serversocket.accept() # 1
clientsocket.setblocking(0)
poll.register(clientsocket.fileno(), select.POLLIN)
connections[clientsocket.fileno()] = clientsocket
elif event & select.POLLIN
# ...
假如以上代码中注释1所在行的accept(2)函数返回EMFILE该如何应对?这意味着本进程的文件描述符已经达到上限,无法为新连接创建socket文件描述符。但是既然没有socket文件描述符来表示这个连接,我们就无法close(2)它。程序继续运行,回到注释2所在行再一次调用epoll_wait。这时候epoll_wait会立刻返回,因为新连接还等待处理,listening fd还是可读的。这样程序立刻就陷入了busy loop,CPU占用率接近100%。这既影响同一event loop上的连接,也影响同一机器上的其他服务。
该怎么办呢?Marc Lehmann提到了几种做法:
1.调高进程的文件描述符数目。治标不治本,因为只要有足够多的客户端,就一定能把一个服务进程的文件描述符用完。
2.死等。鸵鸟算法。
3.退出程序。似乎小题大做,为了这种暂时的错误而中断现有的服务似乎不值得。
4.关闭listening fd。那么什么时候重新打开呢?
5.改用edge trigger。如果漏掉了一次accept(2),程序再也不会收到新连接。
6.准备一个空闲的文件描述符。遇到这种情况,先关闭这个空闲文件,获得一个文件描述符的名额;再accept(2)拿到新socket连接的描述符;随后立刻close(2)它,这样就优雅地断开了客户端连接;最后重新打开一个空闲文件,把“坑”占住,以备再次出现这种情况时使用。
第2、5两种做法会导致客户端认为连接已建立,但无法获得服务,因为服务端程序没有拿到连接的文件描述符。
muduo的Acceptor是用第6种方案实现的,见muduo/net/Acceptor.cc。但是,这个做法在多线程下不能保证正确,会有race condition。
其实有另外一种比较简单的办法:file descriptor是hard limit,我们可以自己设一个稍低一点的soft limit,如果超过soft limit就主动关闭新连接,这样就可避免触发“file descriptor耗尽”这种边界条件。比方说当前进程的max file descriptor是1024,那么我们可以在连接数达到1000的时候进入“拒绝新连接”状态,这样就可留给我们足够的腾挪空间。
7.7.2 在muduo中限制并发连接数
在muduo中限制并发连接数的做法简单得出奇,以第六章中的EchoServer为例,只需要为它增加一个int成员,表示当前的活动连接数。(如果是多线程程序,应该用muduo::AtomicInt32)
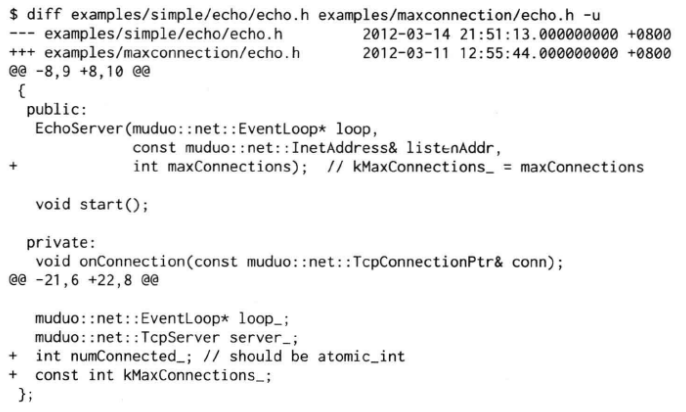
然后,在EchoServer::onConnection()中判断当前活动连接数。如果超过最大允许数,则踢掉连接。

这种做法可以积极地防止耗尽file descriptor。
另外,如果是有业务逻辑的服务,则可以在shutdown()之前发送一个简单的响应,表明本服务程序的负载能力已经饱和,提示客户端尝试下一个可用的server(当然,下一个可用的server地址不一定要在这个响应里给出,客户端可以自己去name service查询),这样方便客户端快速failover。
7.10将介绍如何处理空闲连接的超时:如果一个连接长时间(若干秒)没有输入数据,则踢掉此连接。办法有很多种,作者用timing wheel解决。
7.8 定时器
从本节开始的三节内容都与非阻塞网络编程中的定时任务有关。
7.8.1 程序中的时间
程序中对时间的处理是个大问题,在这一节中先简要谈谈与编程直接相关的内容,把更深入的内容留给日后日期与时间专题文章(http://blog.csdb.net/solstice/article/category/790732),本书不再细述。
在一般的服务端程序设计中,与时间有关的常见任务有:
1.获取当前时间,计算时间间隔。
2.时区转换与日期计算;把纽约当地时间转换为上海当地时间;2011-02-05之后第100天是几月几号星期几;等等。
3.定时操作,比如在预定的时间执行任务,或者在一段延时之后执行任务。
其中第2项看起来比较复杂,但其实最简单。日期计算用Julian Day Number(http://blog.csdn.net/solstice/article/details/5814486)(儒略日数,起点是公元前4713年1月1日中午12:00(格里历,即公历),这个日期被定义为儒略日数0,儒略日数将给定的日期和时间转化为一个数字,包含一个整数部分和一个小数部分,整数部分表示天数,小数部分表示小时、分钟和秒等的分数,便于进行日期和时间的计算和比较),时区转换用tz database(http://cs.ucla.edu/~eggert/tz/tz-link.htm和http://www.iana.org/time-zones)(tz database是一个包含世界各个时区信息的数据库,其中记录了全球各个地区的时区规则、夏令时调整、和与标准时间的偏移等信息,以便计算和显示各种时区的时间);唯一麻烦一点的是夏令时,但也可以用tz database解决。这些操作都是纯函数,很容易用一套单元测试来验证代码的正确性。需要特别注意的是,用tzset(设置程序的时区)/localtime_r(将给定的UNIX时间戳转换为本地时区的tm结构)函数来做时区转换在多线程环境下可能会有问题(tzset函数本身是线程安全的,但它改变时区时有可能影响其他线程转换当前时间);对此,作者的解决办法是写一个TimeZone class(每个immutable instance对应一个时区),以避免影响全局,日后在日期与时间专题文章中会讲到,本书不再细述。下文不考虑时区,均为UTC时间。
真正麻烦的是第1项和第3项。一方面,Linux有一大把令人眼花撩乱的与时间相关的函数和结构体,在程序中该如何选用?另一方面,计算机中的时钟不是理想的计时器,它可能会漂移(指计时器的时间速度与真实时间的速度之间的微小差异)或跳变(指计时器突然发生较大的时间变化)。最后,民用的UTC时间与闰秒的关系也让定时任务变得复杂和微秒。当然,与系统当前时间有关的操作也让单元测试变得困难。
7.8.2 Linux时间函数
Linux的计时函数,用于获得当前时间:

还有gmtime(将unix时间戳转换为UTC时间的tm结构)/localtime(将unix时间戳转换为本地时区时间的tm结构)/timegm(非C库的一部分,用于将tm结构转换为UTC时间的unix时间戳)/mktime(用于将tm结构转换为本地时区时间的unix时间戳)/strftime(将tm结构转换为一个可读的,指定格式的字符串)/struct tm等与当前时间无关的时间格式转换函数。
定时函数,用于让程序等待一段时间或安排计划任务:

作者的取舍如下:
1.计时只使用gettimeofday(2)函数来获取当前时间。
2.定时只使用timerfd_*系列函数来处理定时任务。
gettimeofday(2)入选原因(这也是muduo::Timestamp class的主要设计考虑):
1.time(2)的精度太低,ftime(3)已被废弃;clock_gettime(2)精度最高,但是其系统调用的开销比gettimeofday(2)大。
2.在x86-64平台上,gettimeofday(2)不是系统调用,而是在用户态实现的,没有上下文切换和陷入内核的开销(http://lwn.net/Articles/446528/)。
3.gettimeofday(2)的分辨率(resolution)是1微秒,现在的实现确实能达到这个计时精度,足以满足日常计时的需要。muduo::Timestamp用一个int64_t来表示从Unix Epoch到现在的微秒数,其范围可达上下30万年。
timerfd_*入选的原因:
1.sleep(3)/alarm(2)/usleep(3)在实现时有可能用了SIGALRM信号,在多线程程序中处理信号是个相当麻烦的事情,应当尽量避免,见第四章。再说,如果主程序和程序库都使用SIGALRM,就糟糕了。
2.nanosleep(2)和clock_nanosleep(2)是线程安全的,但是在非阻塞网络编程中,绝对不能用让线程挂起的方式来等待一段时间,这样一来程序会失去响应。正确的做法是注册一个时间回调函数。
3.getitimer(2)和timer_create(2)也使用信号来deliver超时,在多线程程序中也会有麻烦。timer_create(2)可以指定信号的接收方是进程还是线程,算是一个进步,不过信号处理函数(signal handler)能做的事情实在很受限。
4.timerfd_create(2)把时间变成了一个文件描述符,该“文件”在定时器超时的那一刻变得可读,这样就能很方便地融入select(2)/poll(2)框架中,用统一的方式来处理IO事件和超时事件,这也正是Reactor模式的长处。作者在以前发表的《Linux新增系统调用的启示》(http://blog.csdn.net/Solstice/article/details/5327881)中也谈到了这个想法,现在把这个想法在muduo网络库中实现了。
5.传统的Reactor利用select(2)/poll(2)/epoll(4)的timeout来实现定时功能,但poll(2)和epoll_wait(2)的定时精度只有毫秒,远低于timerfd_settime(2)的定时精度。
必须要说明,在Linux这种非实时多任务操作系统中,在用户态实现完全精确可控的计时和定时是做不到的,因为当前任务可能会被随时切换出去,这在CPU负载大的时候尤为明显。但是,我们的程序可以尽量提高时间精度,必要的时候通过控制CPU负载来提高时间操作的可靠性,让程序在99.99%的时候都是按预期执行的。这或许比换用实时操作系统并重新编写及测试代码要经济一些。
关于时间的精度(accuracy)问题作者留到日期与时间专题文章中讨论,本书不再细述,它与分辨率(resolution)不完全是一回事儿。时间跳变和闰秒的影响与应对也不在此处展开讨论了。
7.8.3 muduo的定时器接口
muduo EventLoop有三个定时器函数:
typedef boost::function<void ()> TimerCallback;
class EventLoop : boost::noncopyable
{
public:
// ...
// timers
// Runs callback at 'time'.
TimerId runAt(const Timestamp &time, const TimerCallback &cb);
// Runs callback after @c delay seconds.
TimerId runAfter(double delay, const TimerCallback &cb);
// Runs callback every @c interval seconds.
TimerId runEvery(double interval, const TimerCallback &cb);
// Cancels the timer.
void cancel(TimerId timerId);
// ...
};
以上代码的注释中,@c用于文档或代码注释中的标记,表示后面跟着的内容是代码中的一个参数或变量,用于帮助程序员和文档生成工具自动提取和格式化文档,以便生成代码文档或API文档。
函数名很好地反映了其用途:
1.runAt在指定的时间调用TimerCallback。
2.runAfter等一段时间调用TimerCallback。
3.runEvery以固定的间隔反复调用TimerCallback。
4.calcel取消timer。
回调函数在EventLoop对象所属的线程发生,与onMessage()、onConnection()等网络事件函数在同一个线程。muduo的TimerQueue采用了平衡二叉树来管理未到期的timers,因此这些操作的时间复杂度是O(logN)。
7.8.4 Boost.Asio示例
Boost.Asio教程(http://www.boost.org/doc/libs/release/doc/html/boost_asio/tutorial.html)里以Timer和Daytime为例介绍Asio的基本使用,daytime在上文中介绍过,这里着重谈谈Timer。Asio有5个Timer示例,muduo把其中四个重新实现了一遍,并扩充了第5个示例。
1.阻塞式的定时,muduo不支持这种用法,无代码。
2.非阻塞定时,见examples/asio/tutorial/timer2。
3.在TimerCallback里传递参数,见examples/asio/tutorial/timer3。
4.以成员函数为TimerCallback,见examples/asio/tutorial/timer4。
5.在多线程中回调,用mutex保护共享变量,见examples/asio/tutorial/timer5。
6.在多线程中回调,缩小临界区,把不需要互斥执行的代码移出来,见examples/asio/tutorial/timer6。
为节省篇幅,这里只列出timer4。这个程序的功能是以1秒为间隔打印5个整数,乍看起来代码有点小题大做,但是值得注意的是定时器事件与IO事件是在同一线程发生的,程序就像处理IO事件一样处理超时事件。
class Printer : boost::noncopyable
{
public:
Printer(muduo::net::EventLoop *loop) : loop_(loop), count_(0)
{
loop_->runAfter(1, boost::bind(&Printer::print, this));
}
~Printer()
{
std::cout << "Final count is " << count_ << "\n";
}
void print()
{
if (count_ < 5)
{
std::cout << count_ << "\n";
++count_;
loop_->runAfter(1, boost::bind(&Printer::print, this));
}
else
{
loop_->quit();
}
}
private:
muduo::net::EventLoop *loop_;
int count_;
};
int main()
{
muduo::net::EventLoop loop;
Printer printer(&loop);
loop.loop();
}
最后再强调一遍,在非阻塞服务端编程中,绝对不能用sleep()或类似的办法来让程序原地停留等待,这会让程序失去响应,因为主事件循环被挂起了,无法处理IO事件。这就像在Windows编程中绝对不能在消息循环里执行耗时的代码是一个道理,这会让程序界面失去响应。Reactor模式的网络编程确实有些类似传统的消息驱动的Windows编程。对于“定时”任务,把它变成一个特定的消息,到时候触发相应的消息处理函数就行了。
Boost.Asio的timer示例只用到了EventLoop::runAfter,再举一个EventLoop::runEvery的例子。
7.8.5 Java Netty示例
Netty是一个非常好的Java NIO网络库,它附带的示例程序有echo和discard两个简单网络协议。与前文介绍的不同,Netty版的echo和discard服务端有流量统计功能,这需要用到固定间隔的定时器(EventLoop::runEvery)。
其client的代码类似前文的chargen,为节省篇幅,请阅读源码examples/netty/discard/client.cc。
这里列出discard server的完整代码。代码整体结构上与第六章的EchoServer差别不大,这算是简单网络服务器的典型模式了。
DiscardServer可以配置成多线程服务器,muduo Tcpserver有一个内置的one loop per thread多线程IO模型,可以通过setThreadNum()来开启。
int numThreads = 0;
class DiscardServer
{
public:
DiscardServer(EventLoop *loop, const InetAddress &listenAddr) : loop_(loop),
server_(loop, listenAddr, "DiscardServer"), oldCounter_(0), startTime_(Timestamp::now())
{
server_.setConnectionCallback(boost::bind(&DiscardServer::onConnection, this, _1));
server_.setMessageCallback(boost::bind(&DiscardServer::onMessage, this, _1, _2, _3));
server_.setThreadNum(numThreads);
loop->runEvery(3.0, boost::bind(&DiscardServer::printThroughput, this));
}
构造函数注册了一个间隔为3秒的定时器,调用DiscardServer::printThroughput()打印出吞吐量。
消息回调只比前文的Discard服务器多两行,用于统计收到的数据长度和消息次数:
public:
void onMessage(const TcpConnectionPtr &conn, Buffer *buf, Timestamp)
{
size_t len = buf->readableBytes();
transferred_.add(len);
receivedMessages_.incrementAndGet();
buf->retrieveAll();
}
在每一个统计周期,打印数据吞吐量:
public:
void printThoughput()
{
Timestamp endTime = Timestamp::now();
int64_t newCounter = transferred_.get();
int64_t bytes = newCounter - oldCounter_;
int64_t msgs = receivedMessages_.getAndSet(0);
double time = timeDifference(endTime, startTime_);
printf("%4.3f MiB/s %4.3f Ki Msgs/s %6.2f bytes per msg\n",
static_cast<double>(bytes) / time / 1024 / 1024,
static_cast<double>(msgs) / time / 1024,
static_cast<double>(bytes) / static_cast<double>(msgs));
oldCounter_ = newCounter;
startTime_ = endTime;
}
以下是数据成员,注意用了整数的原子操作AtomicInt64来记录收到的字节数和消息数,这是为了多线程安全性:
public:
EventLoop *loop_;
TcpServer server_;
AtomicInt64 transferred_;
AtomicInt64 receivedMessages_;
int64_t oldCounter_;
Timestamp startTime_;
};
main()函数,有一个可选的命令行参数,用于指定线程数目:
int main(int argc, char *argv[])
{
LOG_INFO << "pid = " << getpid() << ", tid = " << CurrentThread::tid();
if (argc < 1)
{
numThreads = atoi(argv[1]);
}
EventLoop loop;
InetAddress listenAddr(2009);
DiscardServer server(&loop, listenAddr);
server.start();
loop.loop();
}
运行方法,在同一台机器的两个命令行窗口分别运行:

第一个窗口显示吞吐量:

改变第二个命令的最后一个参数(上面的256),可观察不同的消息大小对吞吐量的影响。
有兴趣的读者可以对比一下Netty的吞吐量,muduo应该能轻松取胜。
discard client/server测试的是单向吞吐量,echo client/server测试的是双向吞吐量。这两个服务端都支持多个并发连接,两个客户端都是单连接的。第六章实现了一个ping pong协议,客户端和服务端都是多连接,用来测试muduo在多线程大量连接情况下的性能表现。
7.9 测量两台机器的网络延迟和时间差
本节介绍一个简单的网络程序roundtrip,用于测量两台机器之间的网络延迟,即“往返时间(round trip time,RTT)”。其主要考察定长TCP消息的分包与TCP_NODELAY的作用。本节的代码见examples/roundtrip/roundtrip.cc。
测量round trip time的办法很简单:
1.host A发一条消息给host B,其中包含host A发送消息的本地时间。
2.host B收到之后立刻把消息echo回host A。
3.host A收到消息之后,用当前时间减去消息中的时间就得到了round trip time。
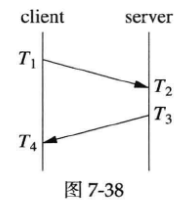
NTP协议的工作原理与之类似(NTP的原理是持续检测本机与时间服务器的时差,调整本机的时钟频率和时间offset,让修正后的本机时间与服务器时间尽量接近。NTP的核心是一个数字锁相环(Digital Phase-Locked Loop,简称DPLL,是一种电子电路,用于在数字领域中实现锁相环功能,锁相环(PLL)是一种控制系统,用于跟踪和调整输入信号的相位,使其与参考信号保持同步),这里的“相位”就是时间,频率是时钟快慢。NTP对时除了要拨表盘指针,还要调钟摆长短以控制钟的快慢),不过,除了测量round trip time,NTP还需要知道两台机器之间的时间差(clock offset),这样才能校准时间。
下图是NTP协议收发消息的协议,round trip time = (T
4
_{4}
4-T
1
_{1}
1)-(T
3
_{3}
3-T
2
_{2}
2),clock offset = (T
4
_{4}
4+T
1
_{1}
1)-(T
3
_{3}
3+T
2
_{2}
2)/2。NTP的要求是往返路径上的单程延迟要尽量相等,这样才能减少系统误差。偶然误差由单程延迟的不确定性决定。
在作者设计的roundtrip示例程序中,协议有所简化,如下图所示:
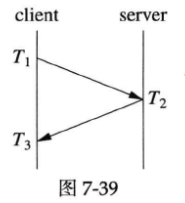
计算公式如下。
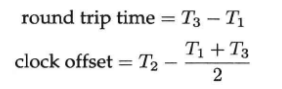
简化之后的协议少取一次时间,因为server收到消息之后立刻发送回client,耗时很少(若干微秒),基本不影响最终结果。
作者设计的消息格式是16字节定长消息,如下图所示:
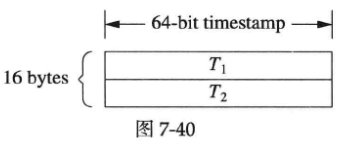
T1和T2都是muduo::Timestamp,成员是一个int64_t,表示从Unix Epoch到现在的微秒数。为了让消息的单程往返时间接近,server和client发送的消息都是16 bytes这样做到对称。由于是定长消息,可以不必使用codec,在message callback中直接用:
while (buffer->readableBytes() >= frameLen)
{
// ...
}
就能decode。如果把while换成if,如果一次到了多条消息,那么只能读到一条。
client程序以200ms为间隔发送消息,在收到消息之后打印round trip time和clock offset。一次运作实例如下图所示:
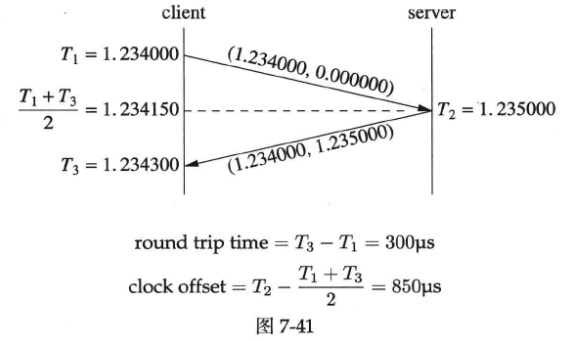
在这个例子中,client和server各自的本地时钟不是完全对准的,server的时间快了850微秒,用roundtrip程序能测量出这个时间差。有了这个时间差,就能校正分布式系统中测量得到的消息延迟。
比方说以上图为例,server在它本地1.235000s时刻发送了一条消息,client在它本地1.234300s收到这条消息,若直接计算的话延迟是-700us。这个结果肯定是错的,因为server和client不在一个时钟域(clock domain,这是数字电路中的概念),它们的时间直接相减无意义。如果我们已经测量得到server比client快850微秒,那么用这个数据做一次校正:-700+850=150us,这个结果就比较符合实际了。当然,在实际应用中,clock offset要经过一个低通滤波才能使用,不然偶然性太大(低通滤波是一种信号处理技术,用于去除高频噪声和快速变化的信号成分,从而保留信号的较慢变化部分,在这种情况下,低通滤波器允许通过慢速变化的时钟偏移,而滤除偶发或快速变化的时钟偏移。)。
这个程序在局域网中使用没有问题;如果在广域网使用,而且RTT大于200ms,那么受Nagle算法影响,测量结果是错误的。因为应用程序记录的发包时间与操作系统真正发出数据包的时间之差不再是一个可以忽略的小间隔。这时候我们需要设置TCP_NODELAY参数,让程序在广域网上也能正常工作。
7.10 用timing wheel踢掉空闲连接
一个连接如果若干秒没有收到数据,就被认为是空闲链接。本文的代码见examples/idleconnection。
在严肃的网络程序中,应用层的心跳协议是必不可少的。应该用心跳信息来判断对方进程是否能正常工作,“踢掉空闲连接”只是一时的权宜之计。
如果一个连接连续几秒(后文以8s)内没有收到数据,就把它断开,为此有两种简单、粗暴的做法:
1.每个连接保存“最后收到数据的时间lastReceiveTime”,然后用一个定时器,每秒遍历一遍所有连接,断开那些(now - connection.lastReceiveTime) > 8s的connection。这种做法全局只有一个repeated timer,不过每次timeout都要检查全部连接,如果连接数目比较大(几千上万),这一步可能会比较耗时。
2.每个连接设置一个one-shot timer,超时定为8s,在超时的时候就断开本连接。当然,每次收到数据就要去更新timer。这种做法需要很多个one-shot timer,会频繁地更新timers。如果连接数目比较大,可能对EventLoop的TimerQueue造成压力。
使用timing wheel能避免上述两种做法的缺点。timing wheel可以翻译为“时间轮盘”或“刻度盘”,本文保留英文。
连接超时不需要精确定时,只要大致8秒超时断开就行,多一秒、少一秒关系不大。处理连接超时可用一个简单的数据结构:8个桶组成的循环队列。第1个桶放1秒之后将要超时的连接,第2个桶放2秒之后将要超时的连接。每个连接一收到数据就把自己放到第8个桶,然后在每秒的timer里把第一个桶里的连接断开,把这个桶挪到队尾。这样大致可以做到8秒没有数据就超时断开连接。更重要的是,每次不用检查全部的连接,只要检查第一个桶里的连接,相当于把任务分散了。
7.10.1 timing wheel原理
《Hashed and hierarchical timing wheels: effcient data structures for implementing a timer facility》(http://www.cs.columbia.edu/~nahum/w6998/papers/sosp87-timing-wheels.pdf)这篇论文详细比较了实现定时器的各种数据结构,并提出了层次化的timing wheel与hash timing wheel等新结构。针对本节要解决的问题的特点,我们不需要实现一个通用的定时器,只用实现simple timing wheel即可。
simple timing wheel的基本结构是一个循环队列,还有一个指向队尾的指针(tail),这个指针每秒移动一格,就像钟表上的时针,timing wheel由此得名。
以下是某一时刻timing wheel的状态(下图左图),格子里的数字是倒计时,表示这个格子(桶子)中连接的剩余寿命。
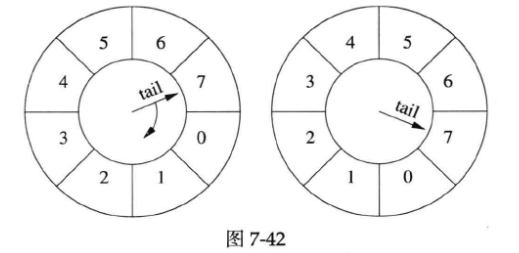
1秒以后(上图右图),tail指针移动一格,原来四点钟方向的各自被清空,其中的连接已被断开。
连接超时被踢掉的过程
假设在某个时刻,conn 1到达,把它放到当前tail指向的格子中,它的剩余寿命是7秒(下图左图)。此后conn 1上没有收到数据。1秒之后(下图右图),tail指向下一个格子,conn 1的剩余寿命是6秒。
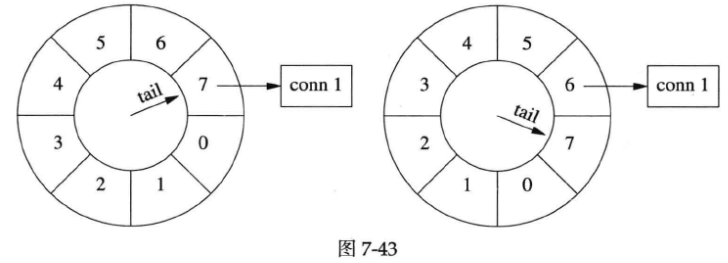
又过了几秒,tail指向conn 1之前的那个格子,conn 1即将被断开(下图左图)。下一秒(下图右图),tail重新指向conn 1原来所在的格子,清空其中的数据,断开conn 1连接。
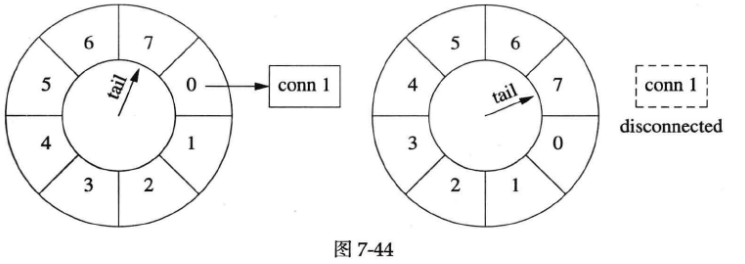
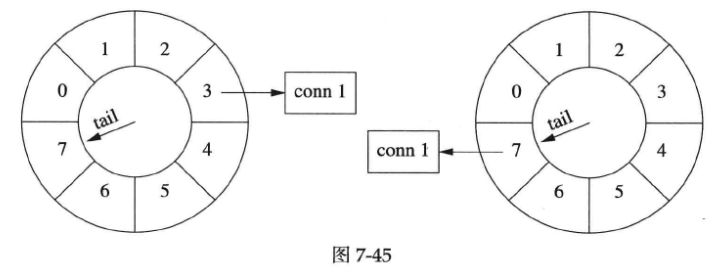
连接刷新
如果在断开conn 1之前收到数据,就把它移到当前tail指向的格子里。conn 1的剩余寿命是3秒(下图左图),此时conn 1收到数据,它的寿命恢复为7秒(下图右图)。
时间继续前进,conn 1寿命递减,不过它已经比第一种情况长寿了(见下图)。
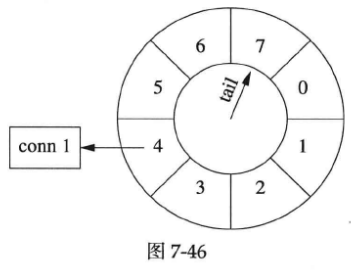
多个连接
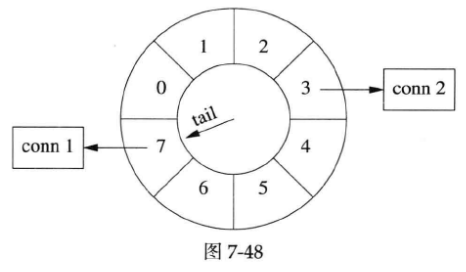
timing wheel中的每个格子是个hash set,可以容纳不止一个连接。
比如一开始,conn 1到达。随后,conn 2到达(见下图),这时候tail还没有移动,两个连接位于同一个格子中,具有相同的剩余寿命(下图中画成链表,代码中实际是哈希表)。
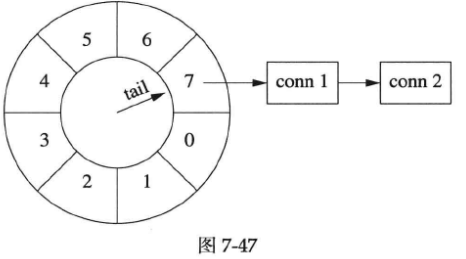
几秒之后,conn 1收到数据,而conn 2一直没有收到数据,那么conn 1被移到当前tail指向的各自中。这时conn 1的预期寿命比conn 2长(见下图)。
7.10.2 代码实现与改进
我们用以前多次出现的EchoServer来说明具体如何实现timing wheel。代码见examples/idleconnection。
在具体实现中,格子里放的不是连接,而是一个特制的Entry struct,每个Entry包含TcpConnection的weak_ptr。Entry的析构函数会判断连接是否还存在(用weak_ptr),如果还存在则断开连接。
数据结构:
struct Entry : public muduo::copyable // 这是一个type tag
{
explicit Entry(const WeakTcpConnectionPtr &weakConn) : weakConn_(weakConn)
{ }
~Entry()
{
muduo::net::TcpConnectionPtr conn = weakConn_.lock();
if (conn)
{
conn->shutdown();
}
}
WeakTcpConnectionPtr weakConn_;
};
typedef boost::shared_ptr<Entry> EntryPtr;
typedef boost::weak_ptr<Entry> WeakEntryPtr;
typedef boost::unordered_set<EntryPtr> Bucket;
typedef boost::circular_buffer<Bucket> WeakConnectionList;
在实现中,为了简单起见,我们不会真的把一个连接从一个格子移到另一个格子,而是采用引用计数的办法,用shared_ptr来管理Entry。如果从连接收到数据,就把对应的EntryPtr放到这个格子里,这样它的引用计数就递增了。当Entry的引用计数递减到零时,说明它没有在任何一个格子里出现,那么连接超时,Entry的析构函数会断开连接。
注意在头文件中我们自己定义了shared_ptr<T>的hash函数,原因是直到Boost 1.47.0之前,unordered_set<shared_ptr>`虽然可以编译通过,但是其hash_value是shared_ptr隐式转换为bool的结果。也就是说,如果不自定义hash函数,那么unordered_{set/map}会退化为链表。
timing wheel用boost::circular_buffer(循环缓冲区容器)实现,其中每个Bucket元素是个hash set of EntryPtr。
在构造函数中,注册每秒的回调(EventLoop::runEvery()注册EchoServer::onTimer()),然后把timing wheel设为适当的大小。
EchoServer::EchoServer(EventLoop *loop, const InetAddress &listenAddr, int idleSeconds)
: loop_(loop), server_(loop, listenAddr, "EchoServer"), connectionBuckets_(idleSeconds)
{
server_.setConnectionCallback(boost::bind(&EchoServer::onConnection, this, _1));
server_.setMessageCallback(boost::bind(&EchoServer::onMessage, this, _1, _2, _3));
loop->runEvery(1.0, boost::bind(&EchoServer::onTimer, this));
connectionBuckets_.resize(idleSeconds);
}
其中,EchoServer::onTimer()的实现只有一行:往队尾添加一个空的Bucket,这样circular_buffer会自动弹出队首的Bucket,并析构之。在析构Bucket的时候,会依次析构其中的EntryPtr对象,这样Entry的引用计数就不用我们去操心,C++的值语意会帮我们搞定一切。
void EchoServer::onTimer()
{
connectionBuckets_.push_back(Bucket());
}
在连接建立时,创建一个Entry对象,把它放到timing wheel的队尾。另外,我们还需要把Entry的弱引用保存到TcpConnection的context里,因为在收到数据的时候还要用到Entry。如果TcpConnection::setContext保存的是强引用EntryPtr,则会增加EntryPtr的引用计数,导致8秒到时不会被析构,从而连接不会断开。
void EchoServer::onConnection(const TcpConnectionPtr &conn)
{
LOG_INFO << "EchoServer - " << conn->peerAddress().toIpPort() << " -> "
<< conn->localAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
if (conn->connected())
{
EntryPtr entry(new Entry(conn));
connectionBuckets_.back().insert(entry);
WeakEntryPtr weakEntry(entry);
conn->setContext(weakEntry);
}
else
{
assert(!conn->getContext().empty());
WeakEntryPtr weakEntry(boost::any_cast<WeakEntryPtr>(conn->getContext()));
LOG_DEBUG << "Entry use_count = " << weakEntry.use_count();
}
}
在收到消息时,从TcpConnection的context中取出Entry的弱引用,把它提升为强引用EntryPtr,然后放到当前的timing wheel队尾。如果我们不保存上下文的Entry,而是再创建一个新Entry,放到timing wheel队尾,那么旧的Entry析构时,会关闭套接字,无法达到刷新寿命回8秒的效果。
void EchoServer::onMessage(const TcpConnectionPtr &conn, Buffer *buf, Timestamp time)
{
string msg(buf->retrieveAsString());
LOG_INFO << conn->name() << " echo " << msg.size()
<< " bytes at " << time.toString();
conn->send(msg);
assert(!conn->getContext().empty());
WeakEntryPtr weakEntry(boost::any_cast<WeakEntryPtr>(conn->getContext()));
EntryPtr entry(weakEntry.lock());
if (entry)
{
connectionBuckets_.back().insert(entry);
}
}
然后程序就完成了我们想要的功能。(完整的代码会调用dumpConnectionBuckets()来打印circular_buffer变化的情况)
改进
在现在的实现中,每次收到消息都会往队尾添加EntryPtr(当然,hash set会帮我们去重(deduplication))。一个简单的改进措施是,在TcpConnection里保存“最后一次往队列添加引用时的tail位置”,收到消息时先检查tail是否变化,若无变化则不重复添加EntryPtr,若有变化则把EntryPtr从旧的Bucket移到当前队尾Bucket。这样或许能提高空间和时间效率。
另一个思路是“选择排序”:使用链表将TcpConnection串起来,TcpConnection每次收到消息就把自己移到链表末尾,这样链表是按接收时间先后排序的。再用一个定时器定期从链表前端查找并踢掉超时的连接。代码示例位于同一目录。
7.11 简单的消息广播服务
本节介绍用muduo实现一个简单的topic-based消息广播服务,这其实是“聊天室”的一个简单扩展,不过聊天的不是人,而是分布式系统中的程序。本节代码见examples/hub。
在分布式系统中,除了常用的end-to-end通信,还有一对多的广播通信。一提到“广播”,或许会让人联想到IP多播或IP组播,这不是本节的主题。本节将要谈的是基于TCP协议的应用层广播。示意图如下图所示:
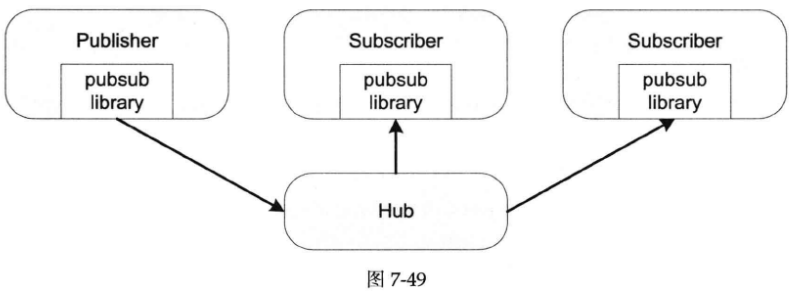
上图中的圆角矩阵代表程序,“Hub”是一个服务程序,不是网络集线器(它位于物理层,主要用于物理信号的传输,负责将数据从一个端口广播到其他所有端口,现代网络中,通常使用交换机(Switch)来代替集线器),它起到类似集线器的作用,故而得名。Publisher和Subscriber通过TCP协议与Hub程序通信。Publisher把消息发到某个topic上,Subscriber订阅该topic,然后就能收到消息。即Publisher借助Hub把消息广播给了一个或多个Subscriber。这种pub/sub结构的好处在于可以增加多个Subscriber而不用修改Publisher,一定程度上实现了“解耦”(也可以看成分布式的Observer pattern)。由于走的是TCP协议,广播是基本可靠的,这里的“可靠”指的是“比UDP可靠”,不是“完全可靠”(可靠广播是以replicated state machine(复制状态机,用于构建分布式系统,以确保多台服务器在执行相同的命令序列时保持一致的状态)方式实现可靠的分布式服务的基础,可靠广播涉及consensus算法,超出了本书的范围)。
为了避免串扰(cross-talk),每个topic在同一时间只应该有一个Publisher,Hub不提供compare-and-swap操作(一个原子操作,此处表示比较并在某些时候更新topic的publisher,如果提供compare-and-swap操作,可能造成串扰)。
应用层广播在分布式系统中的用处:
1.体育比分转播。在8片比赛场地正在进行羽毛球比赛,每个场地的计分程序把当前比分发送到各自的topic上(第1号场地发送到court1,第2号场地发送到court2,依此类推)。需要用到比分的程序(赛场的大屏幕显示、网上比分转播等)自己订阅感兴趣的topic,就能及时收到最新比分数据。由于本节实现的不是100%可靠广播,那么消息应该是snapshot,而不是delta(换句话说,消息的内容是“现在几比几”,而不是“刚才谁得分”,即全量而非增量数据)。
2.负载监控。每台机器上运行一个监控程序,周期性地把本机当前负载(CPU、网络、磁盘、温度)pulish到以hostname命名的topic上,这样需要用到这些数据的程序只要在Hub订阅相应的topic就能获得数据,无须与多台机器直接打交道。(为了可靠起见,监控程序发送的消息中应该包含时间戳,这样能防止过期(stale)数据,甚至一定程度上起到心跳的作用)沿着这个思路,分布式系统中的服务程序也可以把自己的当前负载发布到Hub上,供load balancer和monitor取用。
协议
为了简单起见,muduo的Hub示例采用以“\r\n”分界的文本协议,这样用telnet就能测试Hub。协议只有以下三个命令:
1.sub <topic>\r\n表示订阅<topic>,以后该topic有任何更新都会发给这个TCP连接。在sub的时候,Hub会把该<topic>上最近的消息发送给此Subscriber。
2.unsub <topic>\r\n表示退订<topic>。
3.pub <topic>\r\n<content>\r\n往<topic>发送消息,内容为<content>。所有订阅了此<topic>的Subscriber会收到同样的消息pub <topic>\r\n<content>\r\n。
代码
muduo示例中的Hub分为几个部分:
1.Hub服务程序,负责一对多的消息分发。它会记住每个client订阅了哪些topic,只把消息发给特定的订阅者。代码参见examples/hub/hub.cc。
2.pubsub库,为了方便编写使用Hub服务的应用程序,作者写了一个简单的client library,用来和Hub打交道。这个library可以订阅topic、退订topic、往指定的topic发布消息。代码参见examples/hub/pubsub.{h,cc}。
3.sub示例程序,这个命令行程序订阅一个或多个topic,然后等待Hub的数据。代码参见examples/hub/sub.cc。
4.pub示例程序,这个命令行程序往某个topic发布一条消息,消息内容由命令行参数指定。代码参见examples/hub/pub.cc。
一个程序可以既是Publisher又是Subscriber,而且pubsub库只用一个TCP连接(这样failover(故障切换,指主要组件或服务发生故障时,系统能够自动切换到备用组件或服务以保持连续性和可用性)比较简便)。使用范例如下所示:
1.开启4个命令行窗口。
2.在第一个窗口运行hub 9999。
3.在第二个窗口运行sub 127.0.0.1:9999 mytopic。
4.在第三个窗口运行sub 127.0.0.1:9999 mytopic court。
5.在第四个窗口运行pub 127.0.0.1:9999 mytopic "Hello world.",这时第二、三号都会打印mytopic: Hello world.,表明收到了mytopic这个主题上的消息。
6.在第四个窗口运行pub 127.0.0.1:9999 court "13:11",这时第三号窗口会打印court: 13:11,表明收到了court这个主题上的消息。第二号窗口没有订阅此消息,故无输出。
借助这个简单的pub/sub机制,还可以做很多有意思的事情。比如把分布式系统中的程序的一部分end-to-end通信改为通过pub/sub来做(例如,原来是A向B发一个SOAP request(Simple Object Access Protocol request,是基于XML的通信协议,通常用于客户端与Web服务之间的通信),B通过同一个TCP连接发回response(分析二者的通信只能通过查看log或用tcpdump截获);现在是A往topic_a_to_b上发布request,B在topic_b_to_a上发response),这样多挂一个monitoring subscriber就能轻易地查看通信双方的沟通情况,很容易做状态监控与trouble shooting。
多线程的高效广播
在上例中,Hub是个单线程程序。假如有一条消息要广播给1000个订阅者,那么只能一个一个地发,第1个订阅者收到消息和第1000个订阅者收到消息的时差可以长达若干毫秒。那么,有没有办法提高速度、降低延迟呢?我们当然会想到用多线程。但是简单的办法并不一定能奏效,因为一个全局锁就把多线程程序退化为单线程执行。为了真正提速,作者想到了用thread local的办法,比如把1000个订阅者分给4个线程,每个线程的操作基本都是无锁的,这样可以做到并行地发送消息。示例代码见examples/asio/chat/server_threaded_highperformance.cc。
7.12 “串并转换”连接服务器及其自动化测试
本节介绍如何用test harness来测试一个具有内部逻辑的网络服务程序。这是一个既扮演服务端,又扮演客户端的网络程序。代码见examples/multiplexer。
云风在他的博客中提到了网游连接服务器的功能需求(http://blog.codingnow.com/2010/11/go_prime.html中搜“练手项目”),作者用C++初步实现了这些需求,并为之编写了配套的自动化test harness,作为muduo网络库的示例。
注意:本节呈现的代码仅仅实现了基本的功能需求,没有考虑安全性,也没有特别优化性能,不适合用作真正的放在公网上运行的网游连接服务器。
功能需求
这个连接服务器把多个客户连接汇聚为一个内部TCP连接,起到“数据串并转换”的作用,让backend的逻辑服务器专心处理业务,而无须顾及多连接的并发性。系统的框图如下图所示:
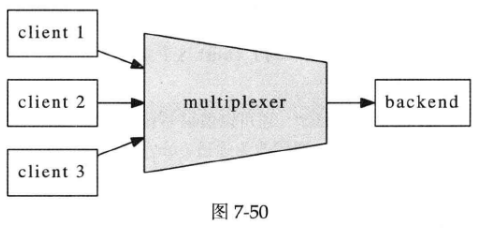
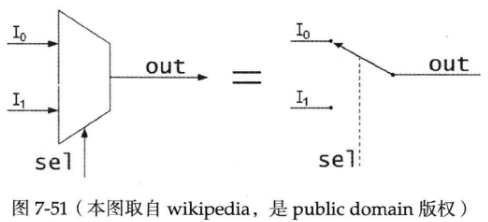
这个连接服务器的作用与数字电路中的数据选择器(multiplexer)类似(见下图),所以把它命名为multiplexer。(其实IO multiplexing也是取的这个意思,让一个thread-of-control能有选择地处理多个IO文件描述符)
实现
multiplexer的功能需求不复杂,无非是在backend connection和client connections之间倒腾数据。对每个新client connection分配一个新的整数id,如果id用完了,则断开新连接(这样通过控制id的数目就能控制最大连接数)。另外,为了避免id过快地被复用(有可能造成backend串话),multiplexer采用queue管理free id,每次从队列头部取id,用完之后放回queue尾部。具体来说,主要是处理四种事件:
1.当client connection到达或断开时,向backend发出通知。代码见onClientConnection()。
2.当从client connection收到数据时,把数据连同connection id一同发给backend。代码见onClientMessge()。
3.当从backend connection收到数据时,辨别数据是发给哪个client connection,并执行相应的转发操作。代码见onBackendMessage()。
4.如果backend connection断开连接,则断开所有client connections(假设client会自动重试)。代码见onBackendConnection()。
由上可见,multiplexer的功能与proxy颇为类似。multiplexer_simple.cc是一个单线程版的实现,借助muduo的IO multiplexing特性,可以方便地处理多个并发连接。多线程版的实现见multplexer.cc。
TcpConnection的id如何存放?
在实现的时候有以下两点值得注意:
1.当从backend收到数据,如何根据id找到对应的client connection?用std::map<int, TcpConnectionPtr> clientConns_保存从id到client connection的映射就行。
2.当从client connection收到数据,如何得知其id?可以用与问题1类似的办法解决,但作者想借此介绍一下muduo::net::TcpConnection的context功能。每个TcpConnection都有一个boost::any成员,可由客户代码自由支配(get/set),代码如下。这个boost::any是TcpConnection的context,可以用于保存与connection绑定的任意数据(如connection id、connection的最后数据到达时间、connection所代表的用户的名字等)。这样客户代码不必继承TcpConnection就能attach自己的状态,而且也用不着TcpConnectionFactory了(如果允许继承,那么必然要向TcpServer注入此factory)。
class TcpConnection : boost::noncopyable, public boost::enable_shared_from_this<TcpConnection>
{
public:
void setContext(const boost::any &context)
{
context_ = context;
}
const boost::any &getContext() const
{
return context_;
}
boost::any *getMutableContext()
{
return &context_;
}
// ...
private:
// ...
boost::any context_;
};
typedef boost::shared_ptr<TcpConnection> TcpConnectionPtr;
对于multiplexer,在onClientConnection()里调用conn->setContext(id),把id存到TcpConnection对象中。onClientMessage()从TcpConnection对象中取得id,连同数据一起发送给backend,完整实现如下:
void onClientMessage(const TcpConnectionPtr &conn, Buffer *buf, Timestamp)
{
if (!conn->getContext().empty())
{
// boost::any_cast用来将boost::any类型的数据转换为任意类型
int id = boost::any_cast<int>(conn->getContext());
sendBackendBuffer(id, buf);
}
else
{
buf->retrieveAll();
// error handling
}
}
TcpConnection的生命期如何管理?由于client connection是动态创建并销毁的,其生与灭完全由客户决定,如何保证backend想向它发送数据的时候,这个TcpConnection对象还活着?解决思路是用reference counting。当然,不用自己写,用boost::shared_ptr即可。TcpConnection是muduo中唯一默认采用shared_ptr来管理生命期的对象,盖由其动态生命期的本质决定。
multiplexer采用二进制协议,如何测试呢?
自动化测试
multiplexer是muduo网络编程示例中第一个具有non-trivial业务逻辑的网络程序,根据9.7 “分布式程序的自动化回归测试”的思路,作者为它编写了测试夹具(test harness,即测试工具)。代码见examples/multiplexer/harness/。
这个test harness采用Java编写,用的是Netty网络库。这个test harness要同时扮演clients和backend,也就是既要主动发起连接,也要被动接受连接。而且,test harness与multiplexer的启动顺序是任意的,如何做到这一点请阅读代码。结构如下图所示:
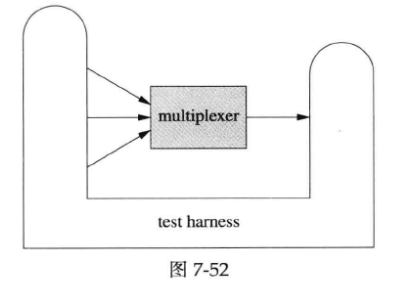
test harness会把各种event汇聚到一个blocking queue里边,方便编写test case。test case则操纵test harness,发起连接、发送数据、检查收到的数据,例如以下是其中一个test case:testcase/TestOneClientSend.java。
这里的几个test cases都是用Java直接写的,如果有必要,也可以采用Groovy(一种编程语言)来编写,这样可以在不重启test harness的情况下随时修改、添加test cases。具体做法见作者的博客《“过家家”版的移动离线计费系统实现》(http://www.cnblogs.com/Solstice/archive/2011/04/22/2024791.html)。
将来的改进
有了这个自动化的test harness,我们可以比较方便且安全地修改(甚至重新设计)multiplexer了。例如:
1.增加“backend发送指令断开client connection”的功能。有了自动化测试,这个新功能可以被单独测试(开发者测试),而不需要真正的backend参与进来。
2.将multiplexer改用多线程重写。有了自动化回归测试,我们不用担心破坏原有的功能,可以放心大胆地重写。而且由于test harness是从外部测试,不是单元测试,重写multiplexer的时候不用动test cases,这样保证了测试的稳定性。另外,这个test harness稍加改进还可以进行stress testing,既可用于验证多线程multiplexer的正确性,亦可对比其相对单线程版的效率提升。
7.13 socks4a代理服务器
本节介绍用muduo实现一个简单的socks4a代理服务器(examples/socks4a/)。
7.13.1 TCP中继器
在实现socks4a proxy之前,我们先写一个功能更简单的网络程序——TCP中继器(TCP relay),或者叫做穷人的tcpdump(poor man’s tcpdump,即简单的tcpdump)。
一般情况下,客户端程序直接连接服务端,如下图所示:

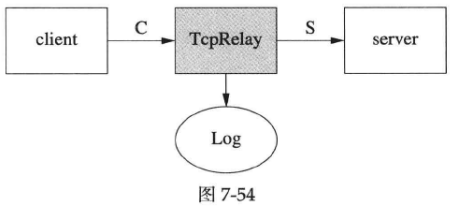
有时候,我们想在client和server之间放一个中继器(relay),把client和server之间的通信内容记录下来。这时用tcpdump是最方便省事的,但是tcpdump需要root权限,万一拿不到权限呢?穷人有穷人的办法,自己写一个TcpRelay,让client连接TcpRelay,再让TcpRelay连接server,如下图中的T型结构,TcpRelay扮演了类似proxy的角色。
TcpRelay是我们自己写的,可以动动手脚。除了记录通信内容外,还可以制造延时,或者故意翻转1 bit数据以模拟router硬件故障。
TcpRelay的功能(业务逻辑)看上去很简单,无非是把连接C上收到的数据发给连接S,同时把连接S上收到的数据发给连接C。但仔细考虑起来,细节其实不那么简单:
1.建立连接。为了真实模拟client,TcpRelay在accept连接C之后才向server发起连接,那么在S建立起来之前,从C收到数据怎么办?要不要暂存起来?
2.并发连接的管理。图7-54中只画出了一个client,实际上TcpRelay可以服务多个client,左右两边这些并发连接如何管理,如何防止串话(cross talk)?
3.连接断开。client和server都可能主动断开连接。当client主动断开连接C时,TcpRelay应该立刻断开S。当server主动断开连接S时,TcpRelay应立刻断开C。这样才能比较精确地模拟client和server的行为。在关闭连接的一刹那,又有新的client连接进来,复用了刚刚close的fd号吗,会不会造成串话?万一client和server几乎同时主动断开连接,TcpRelay如何应对?
4.速度不匹配。如果连接C的带宽是100kB/s,而连接S的带宽是10MB/s,不巧server是个chargen服务,会全速发送数据,那么会不会撑爆TcpRelay的buffer?如何限速?特别是在使用non-blocking IO和level-trigger polling的时候如何限制读取数据的速度?
在看muduo的实现之前,请读者思考:如果用Sockets API来实现TcpRelay,如何解决以上问题。(如果真要实现这样一个功能,可以试试splice(2)系统调用,splice函数允许内核在两个文件描述符之间直接传输数据,而无需将数据复制到用户空间,然后再传输,这种零拷贝操作可以显著提高数据传输的效率)
如果用传统多线程阻塞IO的方式来实现TcpRelay一点也不难,好处是自动解决了速度不匹配的问题,Python代码如下。这个实现功能上没有问题,但是并发度就高不到哪去了。注意以下代码会一个字节一个字节地转发数据,每两个字节之间间隔1ms,可以用于测试网络程序的消息解码功能(codec)是否完善。
#!/usr/bin/python
import socket, thread, time
listen_port = 3007
connect_addr = ('localhost', 2007)
sleep_per_byte = 0.0001
def forward(source, destination):
source_addr = source.getpeername()
while True:
data = source.recv(4096)
if data:
for i in data:
destination.sendall(i)
time.sleep(sleep_per_byte)
else:
print 'disconnect', source_addr
destination.shutdown(socket.SHUT_WR)
break
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serversocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
serversocket.bind(('', listen_port))
serversocket.listen(5)
while True:
(clientsocket, address) = serversocket.accept()
print 'accepted', address
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(connect_addr)
print 'connected', sock.getpeername()
thread.start_new_thread(forward, (clientsocket, sock))
thread.start_new_thread(forward, (sock, clientsocket))
真正的TcpRelay的实现很简单,只有几十行代码(examples/socks4a/tcprelay.cc),主要逻辑都在Tunnel class里(examples/socks4a/tunnel.h)。这个实现很好地解决了前三个问题,第四个问题的解法比较粗暴,用的是HighWaterMarkCallback,如果发送缓冲区堆积的数据大于10MiB就断开连接(更好的办法见8.9.3)。TcpRelay既是服务端,又是客户端,在阅读代码的时候要注意onClientMessage()处理的是从server发来的消息,表示它作为客户端(client)收到的消息,这与前面的multiplexer正好相反。
7.13.2 socks4a代理服务器
socks4a的功能与TcpRelay非常相似,也是把连接C上收到的数据发给连接S,同时把连接S上收到的数据发给连接C。它与TcpRelay的区别在于,TcpRelay固定连到某个server地址,而socks4a允许client指定要连哪个server。在accept连接C之后,socks4a server会读几个字节,以了解server的地址,再发起连接S。socks4a的协议非常简单,请参考维基百科(http://en.wikipedia.org/wiki/SOCKS#SOCKS_4a)。
muduo的socks4a代理服务器的实现在examples/socks4a/socks4a.cc,它也使用了Tunnel class。与TcpRelay相比,只多了解析server地址这一步骤。目前DNS地址解析这一步用的是阻塞的gethostbyname()函数,在真正的系统中,应该换成非阻塞的DNS解析,可参考7.15。muduo的socks4a是个标准的网络服务,可以供Web浏览器使用(作者正是这么测试它的)。
7.13.3 N:1与1:N连接转发
云风在《写了一个proxy用途你懂得》(http://blog.codingnow.com/2011/05/xtunnel.html)中写了一个TCP隧道tunnel,程序由三部分组成:N:1连接转发服务,1:N连接转发服务,socks代理服务。
作者仿照他的思路,用muduo实现了这三个程序。不同的是,作者没有做数据混淆,所以功能上有所减弱。
1.N:1连接转发服务就是7.12中的multiplexer(数据选择器)。
2.1:N连接转发服务是云风文中提到的backend,一个数据分配器(demultiplexer),代码在examples/multiplexer/demux.cc。
3.socks代理服务正是7.13.2实现的socks4a。
有兴趣的读者可以把这三个程序级联起来试一试。
7.14 短址服务
muduo内置了一个简陋的HTTP服务器,可以处理简单的HTTP请求。这个HTTP服务器是面向内网的暴露进程状态的监控端口,不是面向公网的功能完善且健壮的httpd,其接口与J2EE的HttpServlet有几分类似。我们可以拿它来实现一个简单的短URL转发服务,以简要说明其用法。代码位于examples/shorturl/shorturl.cc。
std::map<string, string> redirections; // URL转发表
void onRequest(const HttpRequest &req, HttpResponse *resp)
{
LOG_INFO << "Headers " << req.methodString() << " " << req.path();
// TODO: support PUT and DELETE to create new redirections on-the-fly.
std::map<string, string>::const_iterator it = redirections.find(req.path());
if (it != redirections.end()) // 如果找到了短址
{
// 状态码301表示永久重定向,此时响应头中会有Location字段,告诉客户资源的新URL地址
resp->setStatusCode(HttpResponse::k301MovedPermanently);
resp->setStatusMessage("Moved Permanently");
resp->addHeader("Location", it->second); // 转发到it->second地址
// resp->setCloseConnection(true);
}
// ...
}
int main()
{
redirections["/1"] = "http://chenshuo.com";
redirections["/2"] = "http://blog.csdn.net/Solstice";
EventLoop loop;
HttpServer server(&loop, InetAddress(8000), "shorturl");
server.setHttpCallback(onRequest);
server.start();
loop.loop();
}
muduo没有为短连接TCP服务优化,无法发挥多核优势。一种真正高效的优化手段是修改Linux内核,例如Google的SO_REUSEPORT内核补丁(原始的SO_REUSEPORT实现中,当有新连接进来时,内核会随机分配到一个监听套接字,并且无法保证分配的均衡性,而Google的补丁则允许内核以轮询的方式将新连接分配给已经准备好的监听套接字,从而实现负载均衡)。
读者可以试试建立一个loop转发,例如“/1”→“/2”→“/3”→“/1”,看看浏览器反应如何。
7.15 与其他库集成
前面介绍的网络应用例子都是直接用muduo库收发网络消息,也就是主要介绍TcpConnection、TcpServer、TcpClient、Buffer等class的使用。本节稍微深入其内部,介绍Channel class的用法,通过它可以把其他一些现成的网络库融入muduo的event loop中。
Channel class是IO事件回调的分发器(dispatcher),它在handleEvent()中根据事件的具体类型分别回调ReadCallback、WriteCallback等,代码见8.1.1。每个Channel对象服务于一个文件描述符,但不拥有fd,在析构函数中也不会close(fd)。Channel也使用muduo一贯的boost::function来表示函数回调,它不是基类(相关讨论见http://www.cppblog.com/Solstice/archive/2012/07/01/181058.aspx后面的评论)。这样用户代码不必继承Channel,也无须override虚函数。
class Channel : boost::noncopyable
{
public:
typedef boost::function<void()> EventCallback;
typedef boost::function<void(Timestamp)> ReadEventCallback;
Channel(EventLoop *loop, int fd);
~Channel(();
void setReadCallback(const ReadEventCallback &cb);
void setWriteCallback(const EventCallback &cb);
void setCloseCallback(const EventCallback &cb);
void setErrorCallback(const EventCallback &cb);
void enableReading();
// void disableReading(); // 暂时没有用到
void enableWriting();
void disableWriting();
void disableAll();
void handleEvent(Timestamp receiveTime); // 由EventLoop::loop()调用
// Tie this channel to the owner object managed by shared_ptr,
// prevent the owner object being destroyed in handleEvent.
void tie(const boost::shared_ptr<void> &); // tie()的例子见7.15.3
int fd() const; // obvious
void remove(); // loop_->removeChannel(this);
// ...
};
Channel与EventLoop的内部交互有两个函数EventLoop::updateChannel(Channel_ *)和EventLoop::removeChannel(Channel *)。客户需要在Channel析构前自己调用Channel::remove()。
后面将通过一些实例来介绍Channel class的使用。
7.15.1 UDNS
UDNS(http://www.corpit.ru/mjt/udns.html)是一个stub DNS解析器(stub的意思是只会查询一个DNS服务器,而不会递归地(recursive)查询多个DNS服务器,因此适合在公司内网使用),它能够异步地发起DNS查询,再通过回调函数通知结果。UDNS在设计的时候就考虑到了配合(融入)主程序现有的基于select/poll/epoll的event loop模型,因此它与muduo的配接相对较为容易。由于License限制,本节的代码位于单独的项目中:https://github.com/chenshuo/muduo-udns。
muduo-udns由三部分组成,一是udns-0.2源码(Ubuntu和Debian都不包含UDNS 0.2软件包,因此必须连同上游源码一起发布);二是UDNS与muduo的配接器(adapter),即Resolver class,位于Resolver.{h,cc};三是简单的测试dns.cc,展示Resolver的使用。前两部分构成了muduo-udns程序库。
先看Resolver class的接口(Resolver.h):
class Resolver : boost::noncopyable
{
public:
typedef boost::function<void (const InetAddress &)> Callback;
Resolver(EventLoop *loop);
Resolver(EventLoop *loop, const InetAddress &nameServer);
~Resolver();
void start();
bool resolve(const StringPiece &hostname, const Callback &cb);
// ...
};
其中第一个构造函数会使用系统默认的DNS服务器地址,第二个构造函数由用户指明DNS服务器的IP地址。用户最关心的是resolve()函数,它会回调用户的Callback。
在介绍Resolver的实现之前,先看它的用法(dns.cc),下面这段代码同时解析三个域名,并在stdout输出结果。注意回调函数只提供解析后的地址,因此resolveCallback需要自己设法记住域名,这里作者用的是boost::bind。
void resolveCallback(const string &host, const InetAddress &addr)
{
LOG_INFO << "resolved " << host << " -> " << addr.toIp();
}
void resolve(Resolver *res, const string &host)
{
res->resolve(host, boost::bind(&resolveCallback, host, _1));
}
int main(int argc, char *argv[])
{
EventLoop loop;
Resolver resolver(&loop);
resolver.start();
resolve(&resolver, "chenshuo.com");
resolve(&resolver, "www.example.com");
resolve(&resolver, "www.google.com");
loop.loop(); // 开始事件循环
}
由于是异步解析,因此输出结果的顺序和提交请求的顺序不一定一致,例如:

UDNS与muduo Resolver的交互过程如下:
1.初始化dns_ctx*之后,Resolver::start()调用dns_open()获得UDNS使用的文件描述符,并通过muduo Channel观察其可读事件。由于UDNS始终只用一个socket fd,只观察一个事件,因此特别容易和现有的event loop集成。
2.在解析域名时(Resolver::resolve()),调用dns_submit_a4()(UDNS库函数,用于向DNS服务器提交IPv4地址记录(A记录)的异步查询请求)发起解析,并通过dns_timeouts()(UDNS库函数,用于设置DNS查询的超时参数)获得超时的秒数,使用EventLoop::runAfter()(在一段时间后执行某个回调函数)注册单次定时器回调,以处理超时。
3.在fd可读时(Resolver::onRead()),调用dns_ioevent()(UDNS库函数,用于在异步环境中处理DNS查询的结果)。如果DNS解析成功,会回调Resolver::dns_query_a4()通知解析的结果,继而调用Resolver::onQueryResult(),后者会回调用户Callback。
4.在超时后(Resolver::onTimer()),调用dns_timeouts(),必要时继续注册下一次定时器回调。
可见UDNS是一个设计良好的库,可与现有的event loop很好地结合。UDNS使用定时器的原因是UDP可能丢包,因此程序必须自己处理超时重传。
Resolve class不是线程安全的,客户代码只能在EventLoop所属的线程调用它的Resolver::resolve()成员函数,解析结果也是由这个线程回调客户代码。这个函数通过loop_->assertInLoopThread();来确保不被误用。
C++程序与C语言函数库交互的一个难点在于资源管理,muduo-udns不得已使用了手工new/delete的做法,每次解析会在堆上创建QueryData对象(其中包含异步操作完成后,确定哪个用户发起的异步操作的信息),这样在UDNS回调Resolver::dns_query_a4()时才知道该回调哪个用户Callback。
7.15.2 c-ares DNS
c-ares DNS(http://c-ares.haxx.se)是一款常用的异步DNS解析库,第六章中介绍了它的安装方法,本节简要介绍它与muduo的集成。示例代码位于examples/cdns,代码结构与7.15.1的UDNS非常相似。Resolver.{h,cc}是c-ares DNS与muduo的配接器(adapter),即udns::Resolver class;dns.cc是简单的测试,展示Resolver的使用。c-ares DNS的选项非常多(功能也比UDNS强大,例如可以读取/etc/hosts。udns::Resolver的构造函数有选项可禁用此功能(udns不是没有这个功能吗?)),本节只是展示其与muduo EventLoop集成的基本做法,cdns::Resolver并没有暴露其全部功能。
cdns::Resolver的接口和用法与前面UDNS Resolver相同,只是少了start()函数,此处不再重复举例。
cdns::Resolver的实现与前面UDNS Resolver很相似:
1.Resolver::resolve()调用ares_gethostbyname()发起解析,并通过ares_timeout()获得超时的秒数,注册定时器。
2.在fd可读时(Resolver::onRead()),调用ares_process_fd()(c-ares库函数,用于在异步环境中处理文件描述符上的 I/O 事件,以便触发或处理DNS解析的异步操作)。如果DNS解析成功,会回调Resolver::ares_host_callback()(相当于前面UDNS的Resolver::dns_query_a4()回调)通知解析的结果,继而调用Resolver::onQueryResult(),后者会回调用户Callback。
3.在超时后(Resolver::onTimer()),调用ares_process_fd()处理这一事件,并再次调用dns_timeouts()获得下一次超时的间隔,必要时继续注册下一次定时器回调。
cdns::Resolver的线程安全性和UDNS Resolver相同。
与UDNS不同,c-ares DNS会用到不止一个socket文件描述符(因为DNS解析时,如果UDP响应发生消息截断,会改用TCP重发请求),而且既会用到fd可读事件,又会用到fd可写事件,因此cdns::Resolver的代码比UDNS要复杂一些。Resolver::ares_sock_create_callback()是新建socket fd的回调函数,其中会调用Resolver::onSockCreate()来创建Channel对象,这正是Resolver没有start()成员函数的原因。Resolver::ares_sock_state_callback()是变更socket fd状态的回调函数,会通知观察哪些IO事件(可读and/or可写)。
7.15.3 curl
libcurl是一个常用的HTTP客户端库(也可以访问FTP服务器),可以方便地下载HTTP和HTTPS数据。libcurl有两套接口,easy和multi,本节介绍的是使用其multi接口(https://curl.haxx.se/libcurl/c/libcurl-multi.html)以达到单线程并发访问多个URL的效果。muduo与libcurl搭配的例子见examples/curl,其中包含单线程多连接并发下载同一文件的示例,即单线程实现的“多线程下载器”。
libcurl融入muduo EventLoop的复杂度比前面两个DNS库都更高,一方面因为它本身的功能丰富,另一方面也因为它的接口设计更偏重传统阻塞IO(它原本是从curl(1)这个命令行工具剥离出来的),在事件驱动方面的调用、回调、传参都比较繁琐。这里不去详细解释每一个函数的作用,想必读者在读过前两节之后已经对Channel的用法有了基本的了解,对照libcurl文档和muduo代码就能搞明白。
第1章我们探讨了多线程程序中的对象生命期管理技术。在单线程事件驱动的程序中,对象的生命期管理有时也不简单。比方说下图展示的例子,对方断开TCP连接,这个IO事件会触发Channel::handleEvent()调用,后者会回调用户提供的CloseCallback,而用户代码在onClose()中有可能析构Channel对象,这就造成了灾难。等于说Channel::handleEvent()执行到一半的时候,其所属的Channel对象本身被销毁了。这是程序立刻core dump就是最好的结果了。
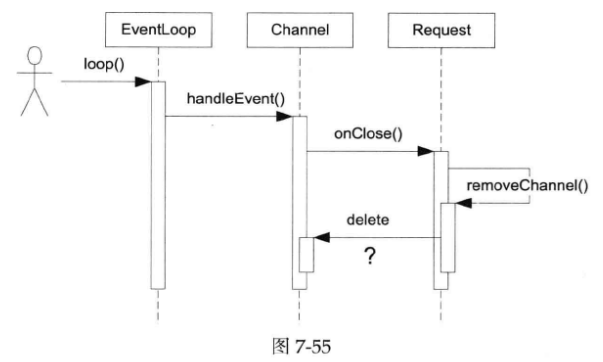
muduo的解决办法是提供Channel::tie(const boost::shared_ptr<void> &)这个函数,用于延长某些对象(可以是Channel对象,也可以是其owner对象)的生命期,使之长过Channel::handleEvent()函数。这也是muduo TcpConnection采用shared_ptr管理对象生命期的原因之一;否则的话,Channel::handleEvent()有可能引发TcpConnection的析构,继而把当前Channel对象也析构了,引起程序崩溃。
第三方库与muduo集成的另一个问题是对IO事件变化的理解可能不一致。拿libcurl来说,它会在某个文件描述符需要关注的IO事件变化的时候通知外围的event loop库,比方说原来关注POLLIN,现在关注(POLLIN | POLLOUT),muduo在Curl::socketCallback回调函数中会相应地调用Channel::enableWriting(),能正确处理这种变化。
不幸的是,libcurl在与c-ares DNS配合(这两个库是同一个作者,libcurl默认会用gethostbyname()执行同步DNS解析,在有c-ares DNS的时候用它执行异步DNS解析)的时候会出现与muduo不兼容的现象。libcurl在访问URL的时候先要解析其中的域名,然后再对那个Web服务器发起TCP连接。在与c-ares DNS搭配时会出现一种情况:c-ares DNS解析域名用到的与DNS服务器通信的socket fd 1 _{1} 1和libcurl对Web服务器发起TCP连接的fd 2 _{2} 2恰好相等,即fd 1 _{1} 1==fd 2 _{2} 2。原因是POSIX操作系统总是选用当前最小可用的文件描述符,当DNS解析完成后,libcurl内部使用的c-ares DNS会关闭fd 1 _{1} 1,libcurl随后再立刻新建一个TCP socket fd 2 _{2} 2,它有可能恰好复用了fd 1 _{1} 1的值。
但这时libcurl不会认为文件描述符或其关注的IO事件发生了变化,也就不会通知muduo去销毁并新建Channel对象。这种做法与传统的基于select(2)和poll(2)的event loop配合不会有问题,因为select(2)和poll(2)是上下文无关的,每次都从输入重建要关注的文件描述符列表。但是在与epoll(4)配合的时候就有问题了,关闭fd 1 _{1} 1会使得epoll从关注列表(watch list)中移除fd 1 _{1} 1的条目,新建的同名fd 2 _{2} 2却没有机会加入IO事件watch list,也就不会收到任何IO事件通知。这个问题无法在muduo内部修复,只能修改上游程序库。
另外一个问题是libcurl在通知muduo取消关注某个fd的时候已经事先关闭了它,这将造成muduo调用::epoll_ctl(epollfd_, EPOLL_CTL_DEL, fd, NULL)时会返回错误,因为关闭文件描述符就已经把它从epoll watch list中除掉了。为了应对这种情况,作者不得已更改了EPollPoller::update()的错误处理,放宽检查。
7.15.4 更多
除了前面举的几个例子,muduo当然还可以将其他涉及网络IO的库融入其EventLoop/Channel框架,作者能想到的有:
1.libmicrohttpd:可嵌入的HTTP服务器(即可嵌入到其他应用程序或项目中的HTTP服务器)。
2.libpg:PostgreSQL的官方客户端库。
3.libdrizzle:MySQL的非官方客户端库。
4.QuickFIX:常用的FIX消息库(FIX是一种用于电子交易的协议,广泛应用于金融领域,特别是在证券交易中)。
在有具体应用场景的时候,作者多半会为之提供muduo adapter,也欢迎用户贡献有关补丁。
另外一个扩展思路是,对每个TCP连接创建一个lua state(指Lua编程语言的执行环境,在Lua中,一个state就是Lua解释器的一个实例),用muduo为lua提供通信机制。然后用lua来编写业务逻辑,这样可以做到在线更改逻辑而不重启进程。就像OpenResty(http://openresty.org)(它是基于NGINX服务器的全功能的Web应用服务器,它扩展了NGINX使其能够执行类似于Lua的脚本语言,从而提供了更灵活、高性能的Web服务解决方案)和云风的skynet(https://github.com/cloudwu/skynet)(一个轻量级、高性能、可扩展的开源分布式框架,主要用于构建游戏服务器和其他实时应用系统)那样。这种做法还可以利用coroutine来简化业务逻辑的实现。